-std=c11 -pthread -mfma -mf16c -mavx -mavx2 -c ggml.c -o ggml.o g++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o g++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp ggml.o whisper.o -o main ./main -h usage: ./main [options] file0.wav file1.wav ... options: -h, --help show this help message and exit -s SEED, --seed SEED RNG seed (default: -1) -t N, --threads N number of threads to use during computation (default: 4) -p N, --processors N number of processors to use during computation (default: 1) -ot N, --offset-t N time offset in milliseconds (default: 0) -on N, --offset-n N segment index offset (default: 0) -d N, --duration N duration of audio to process in milliseconds (default: 0) -mc N, --max-context N maximum number of text context tokens to store (default: max) -ml N, --max-len N maximum segment length in characters (default: 0) -wt N, --word-thold N word timestamp probability threshold (default: 0.010000) -su, --speed-up speed up audio by factor of 2 (faster processing, reduced accuracy -v, --verbose verbose output --translate translate from source language to english -otxt, --output-txt output result in a text file -ovtt, --output-vtt output result in a vtt file -osrt, --output-srt output result in a srt file -owts, --output-words output script for generating karaoke video -ps, --print_special print special tokens -pc, --print_colors print colors -nt, --no_timestamps do not print timestamps -l LANG, --language LANG spoken language (default: en) -m FNAME, --model FNAME model path (default: models/ggml-base.en.bin) -f FNAME, --file FNAME input WAV file path 31
![OpenAIのWhisper でオフライン文字 起こし(STT) Kenichiro Matohara(matoken) <[email protected]> 1](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![usage $ whisper usage: whisper [-h] [--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large}] [--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,f](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
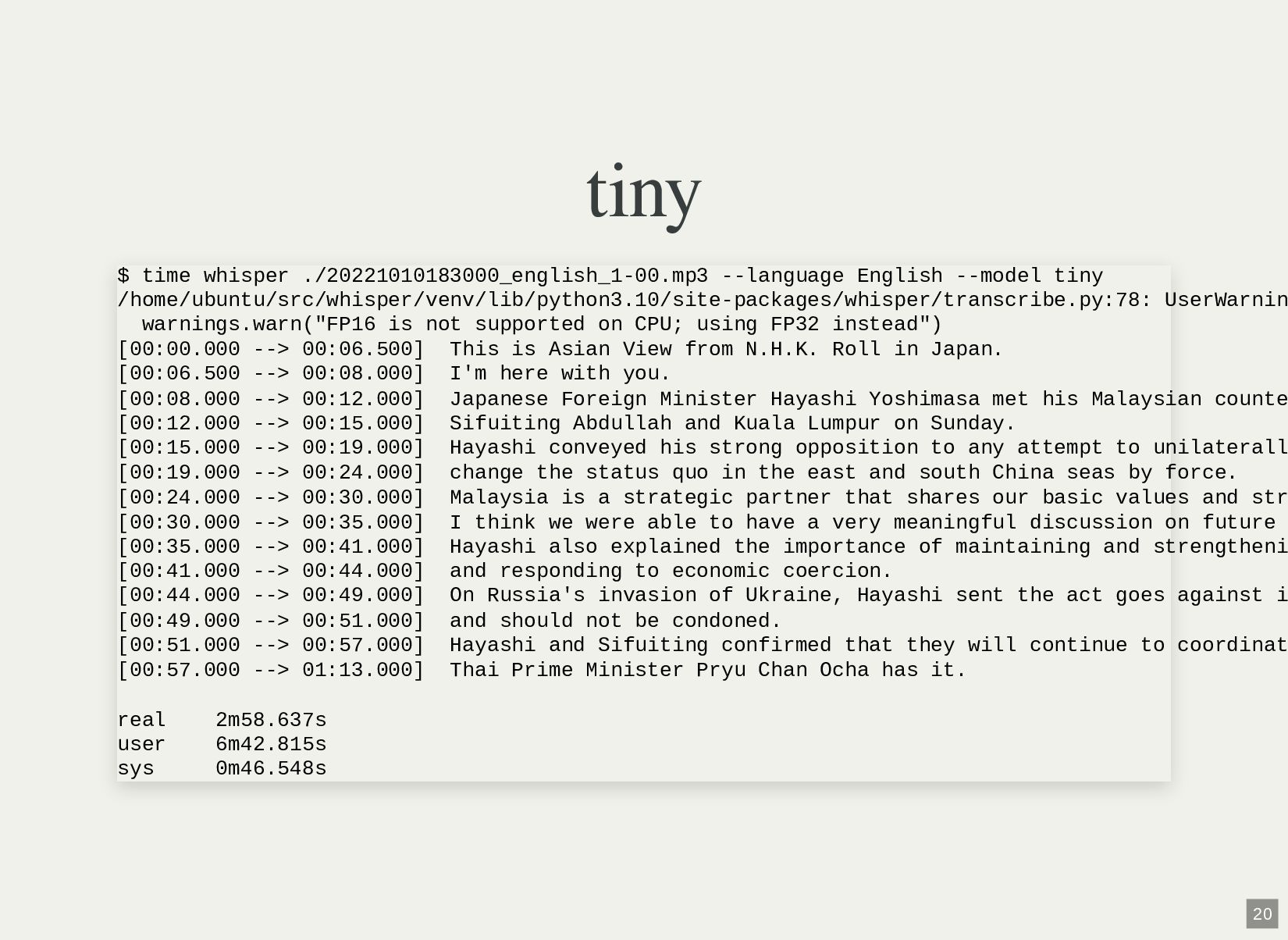
![tiny $ time whisper ./大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm --language /home/ubuntu/src/whisper/venv/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarnin warnings.warn("FP16](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_9.jpg){kind=link}
![base $ time whisper ./大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm --language /home/ubuntu/src/whisper/venv/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarnin warnings.warn("FP16](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_10.jpg){kind=link}
![small $ time whisper ./大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm --language /home/ubuntu/src/whisper/venv/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarnin warnings.warn("FP16](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_11.jpg){kind=link}
![medium $ time whisper ./大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm --language /home/ubuntu/src/whisper/venv/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarnin warnings.warn("FP16](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_12.jpg){kind=link}
![large $ time whisper ./大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm --language /home/ubuntu/src/whisper/venv/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarnin warnings.warn("FP16](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![翻訳結果とsubtitle file $ ls -1 大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし\ \[GiglWCcVi5o\].webm.* '大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし [GiglWCcVi5o].webm.srt' '大隅半島東方沖で地震 宮崎県で震度5弱 津波の心配なし](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![Whisper.cpp Python製のWhisperをC++で再実装したもの 少リソースかつ高速にWhisperが利用できる GPU非対応 ( で知る ) https://github.com/ggerganov/whisper.cpp [Galene] Whisper](https://files.speakerdeck.com/presentations/e76503c6f3394f9b92d74af490e7df08/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
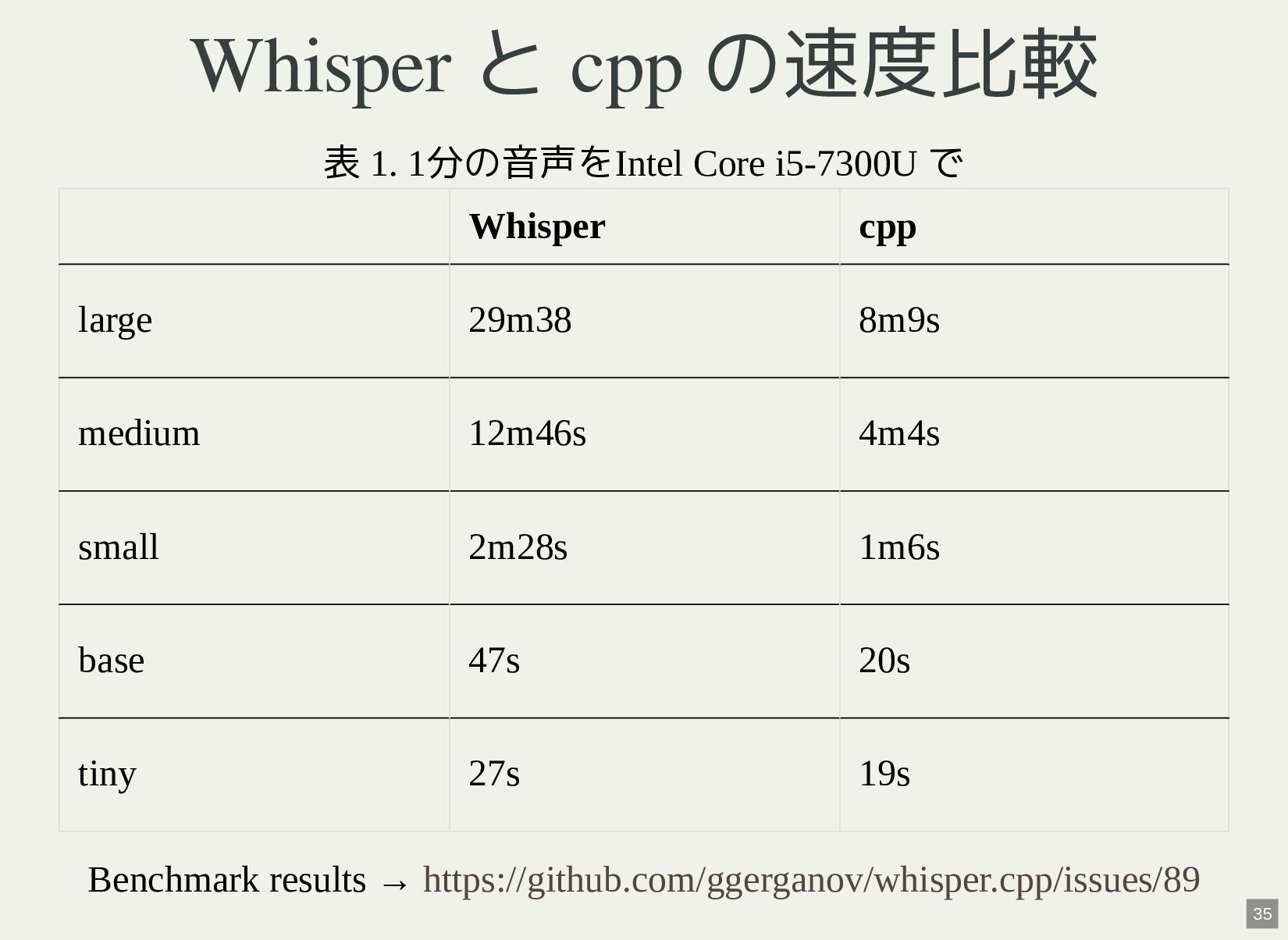{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}