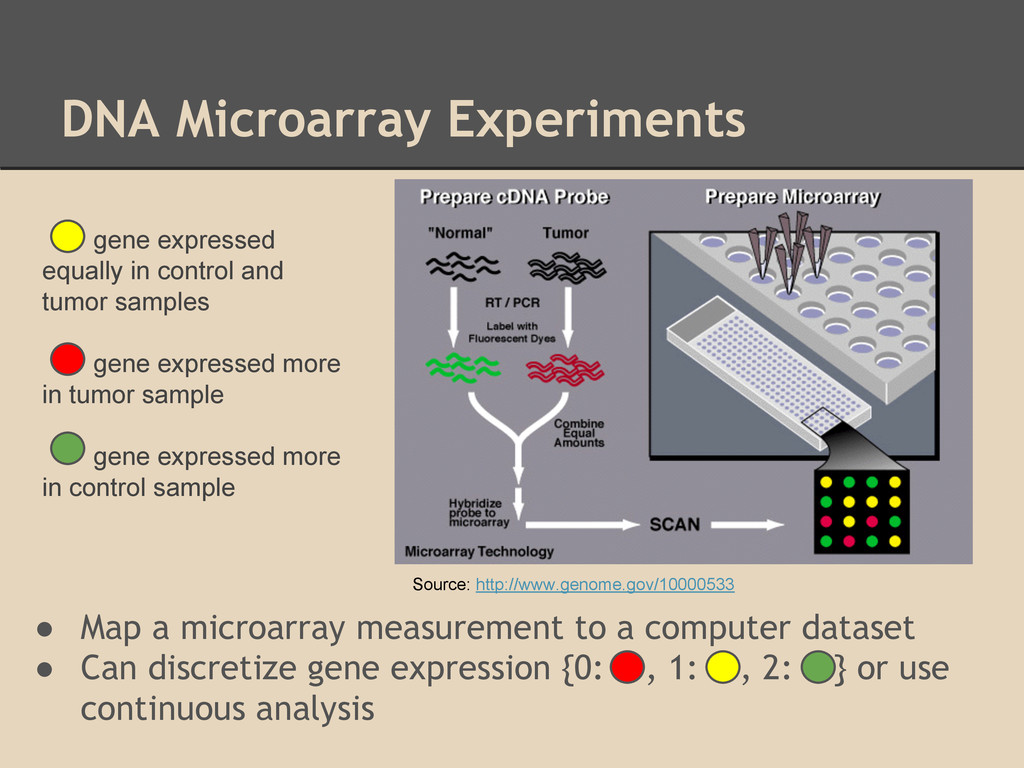
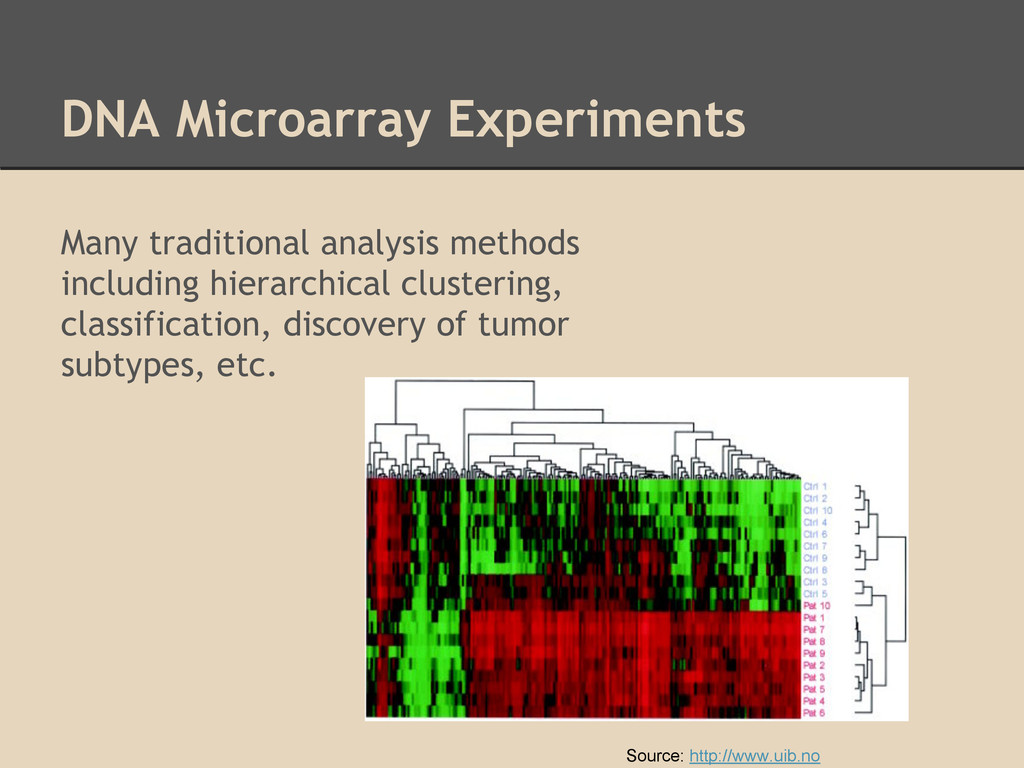
available Rise of quantitative applications means increased use of computational analysis Access to datasets from DNA microarray measurements are one example
computer dataset • Can discretize gene expression {0: , 1: , 2: } or use continuous analysis gene expressed equally in control and tumor samples gene expressed more in tumor sample gene expressed more in control sample Source: http://www.genome.gov/10000533
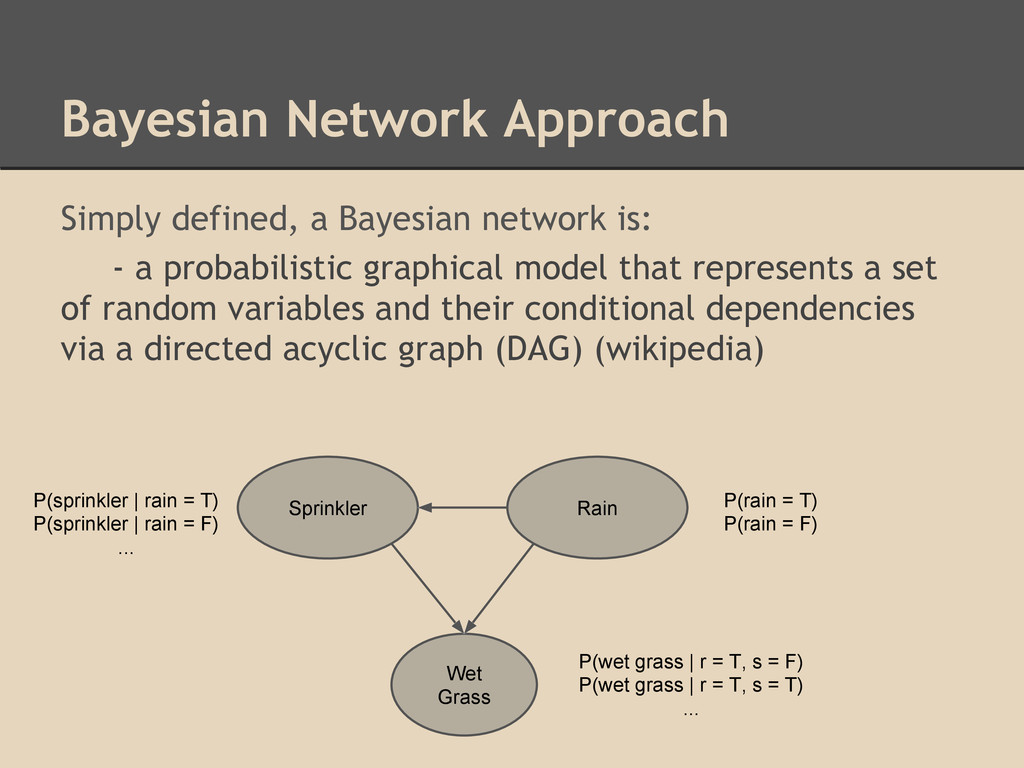
a probabilistic graphical model that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG) (wikipedia) Sprinkler Rain Wet Grass P(rain = T) P(rain = F) P(wet grass | r = T, s = F) P(wet grass | r = T, s = T) ... P(sprinkler | rain = T) P(sprinkler | rain = F) ...
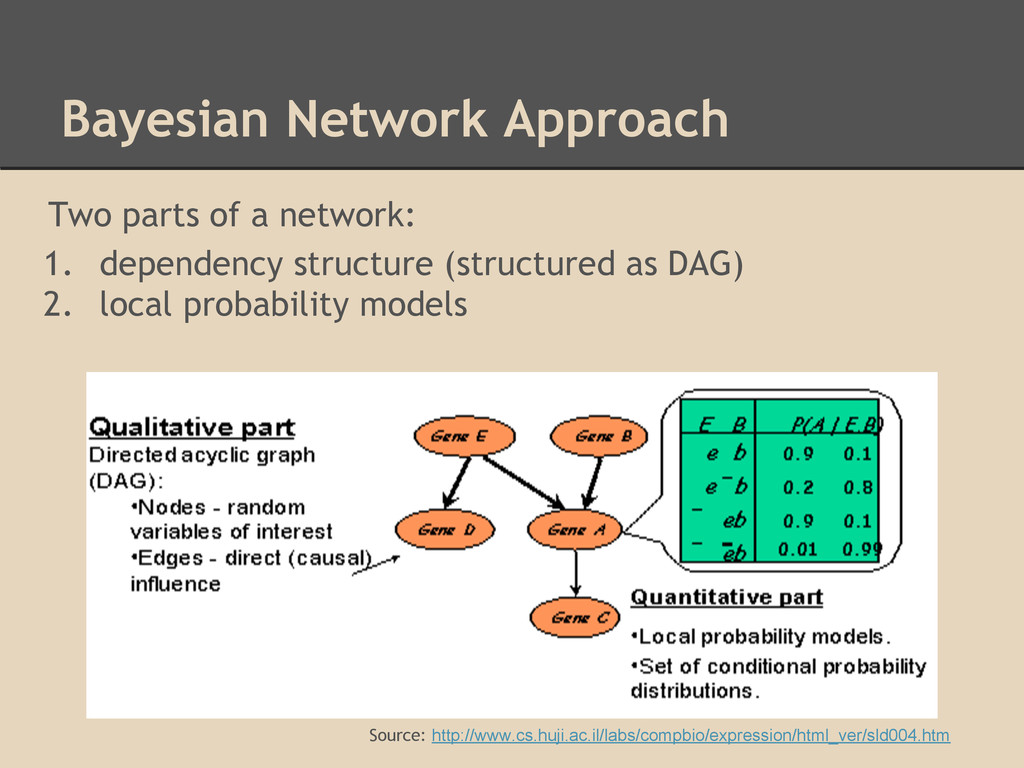
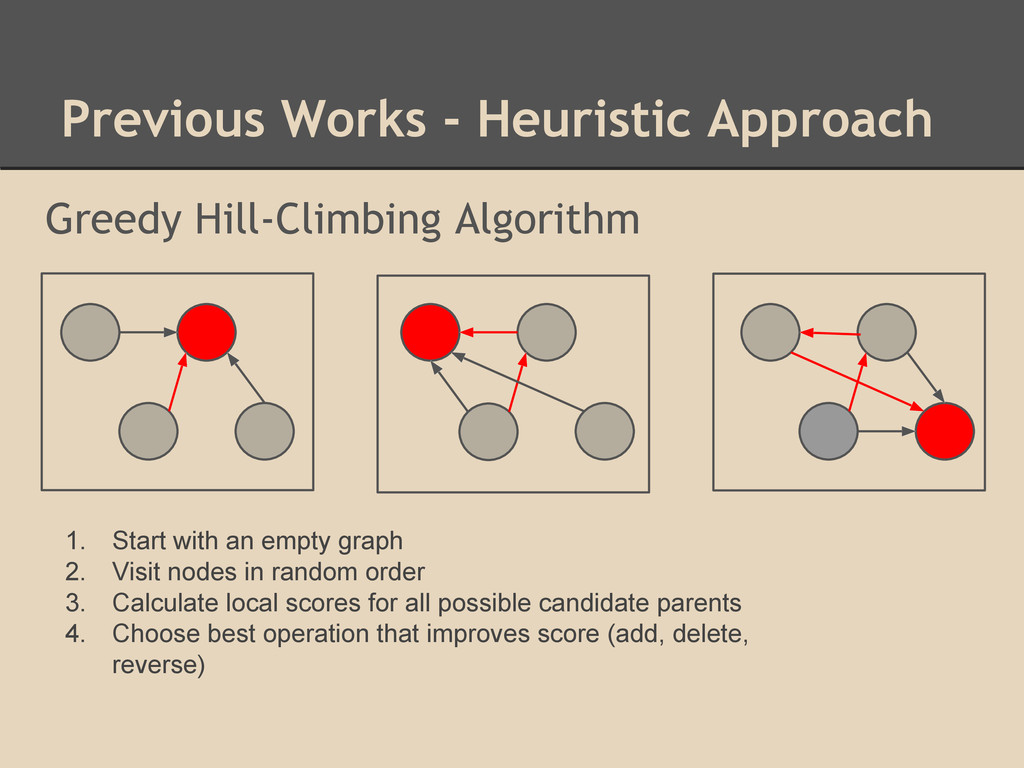
(can be empty), search candidate parents for each node, score the subgraph of the {child, parentset} candidate and choose the set that maximizes the score of the network The score is a measure of the probability that the data given was generated by a graph
Current parallel large scale methods can only find optimal network for ~30 genes • Dynamic programming and caching can be used to alleviate some redundant score calculation • Heuristic methods must be employed to evaluate large scale networks
with an empty graph 2. Visit nodes in random order 3. Calculate local scores for all possible candidate parents 4. Choose best operation that improves score (add, delete, reverse)
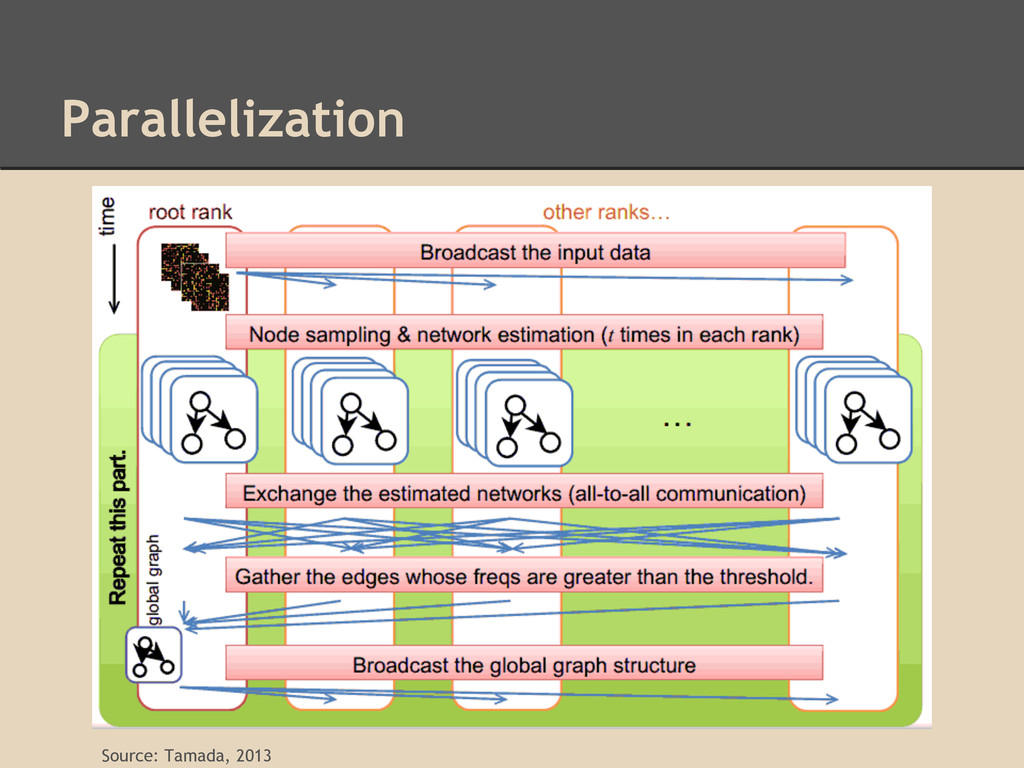
Estimate randomly selected subnetworks repeatedly (can be done independently) a. Subnetwork estimated using hill-climbing algorithm 2. Final network can be chosen based on most frequently selected edges
1. Estimate initial network using RSR 2. Run NNSR and select subnetwork by choosing nodes close to each other on the initial network a. Randomly pick up genes with probabilities proportional to the network score b. Perform subnetwork estimation using HC 3. Final network can be chosen based on most frequently selected edges
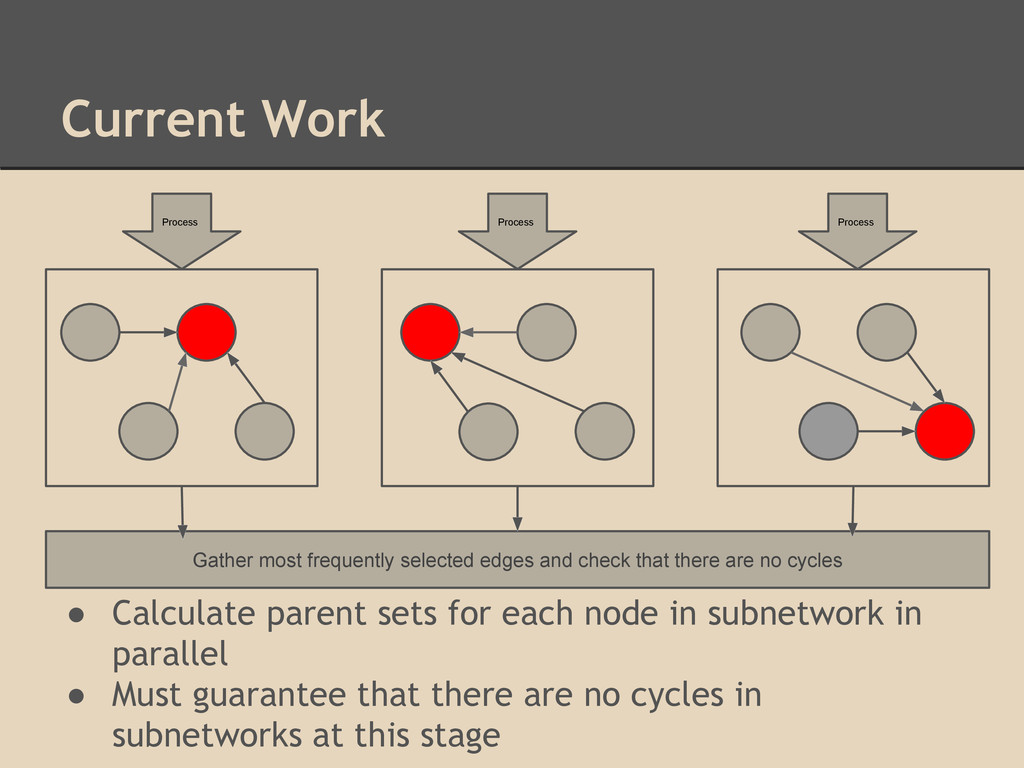
bottleneck of HC instances running in each subprocess ▪ must keep track and synchronize edge changes and dependencies ◦ utilize Xeon Phi, etc. • Guaranteeing no cycles (DAG construction) ◦ parallel topological sort ▪ bottom up parent search BFS (2011, Beamer, et. al. )
subnetwork in parallel • Must guarantee that there are no cycles in subnetworks at this stage Process Process Process Gather most frequently selected edges and check that there are no cycles
• This method finds many local optimum networks and combines them - how does this compare to global network? • (Parallelize method that finds optimal bayesian network structure) ◦ Utilize memory more efficiently to avoid communication
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}