number of samples) Two keys: 1 Incomplete Cholesky Factorization - reduced row-rank approximate factorization of kernel matrix 2 Interior Point Method - parallelizable quadratic programming solver Reduces memory use from O(n2) to O(np/m) where p/m n (p is reduced column dimension of factorized matrix, m is number of machines) Computation time from O(n2) (decomposition method) to O(np2/m) (bottleneck on IPM step in matrix inversion)
the elements for each training vector Convert the training vectors array into GPU compatible format Allocate memory on the GPU for the training vectors array Load the training vectors array to the GPU memory FOR (each training vector) DO Load the training vector to the GPU (because the version on the GPU is in a translated format) Perform the matrix-vector multiplication, i.e. calculate the dot products, using CUBLAS Retrieve the dot products vector from the GPU Calculate the line of the KM by adding the training vector squares, then calculating Φ(x, y) according to Equation 1 END DO De-allocate memory from GPU
∗ ∗ n) PSVM O(np/m) O(np2/m) #ITER empirically shows that it scales more than linearly with number of samples l is the nubmer of operations needed for the kernel function
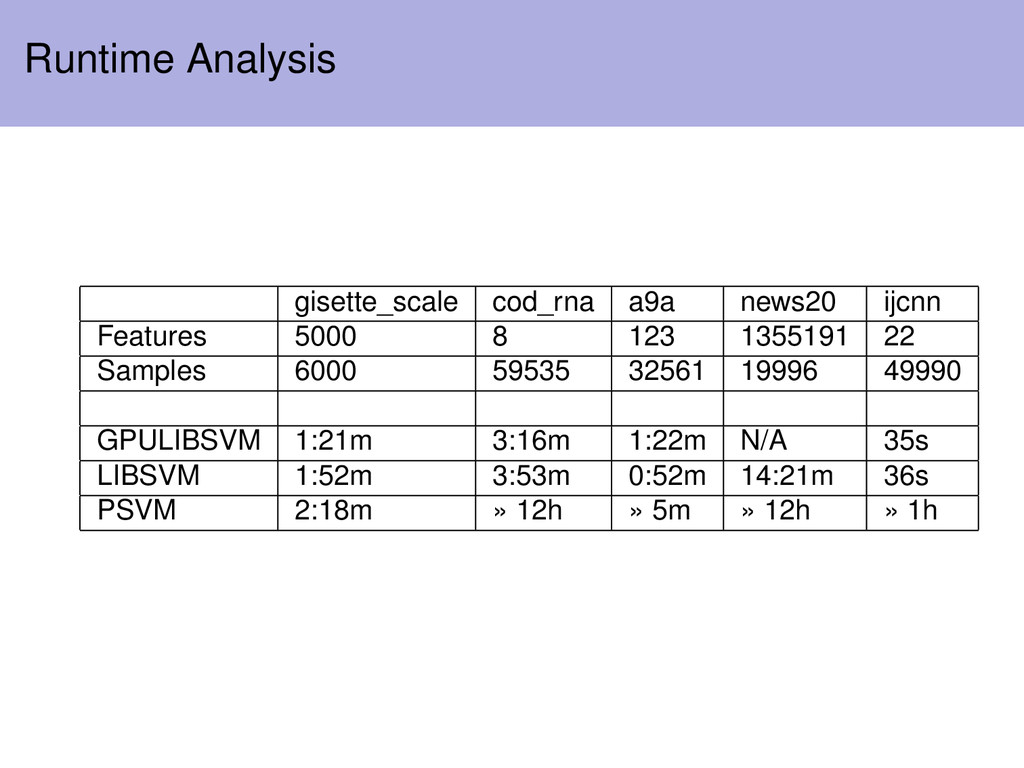
In this analysis I used a single machine (4 hardware cores) pSVM highly dependent on number of samples LIBSVM should depend highly on the number of samples Number of kernel matrix elements is equal to the square of the number of training vectors (contains all possible inner products)
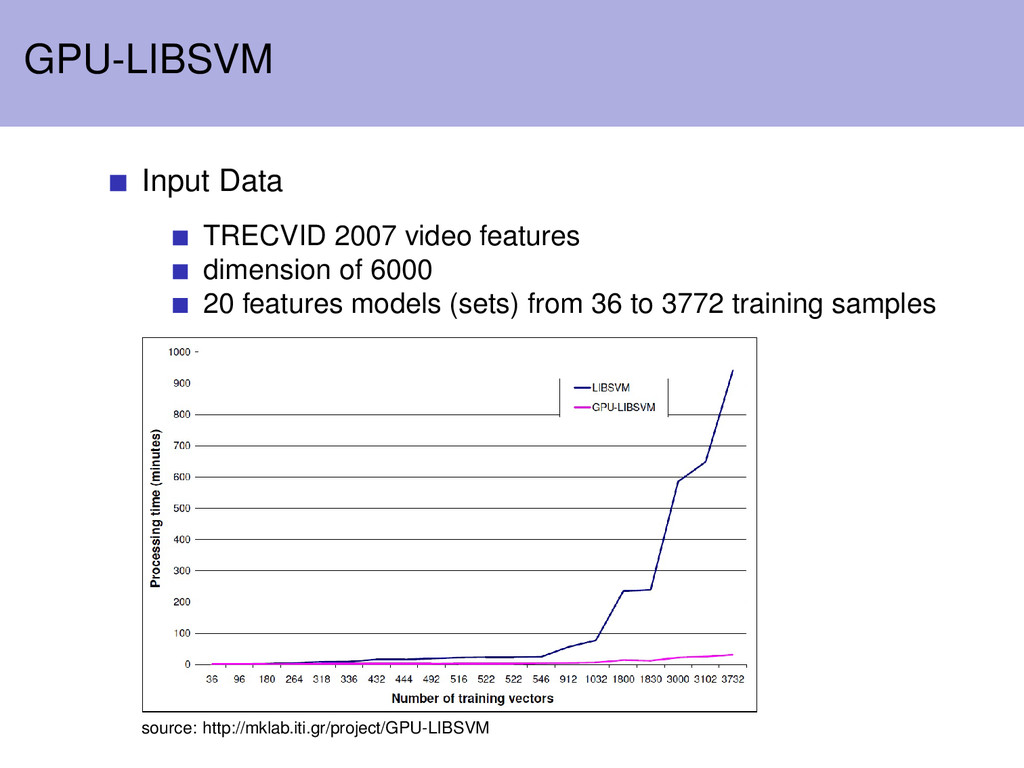
the following hardware: quad-core Intel Q6600 nvidia 8800GTS 3.5GB DDR2 RAM WindowsXP 32-bit This study performed parameter optimization through cross-validation of the data Used automated script to accomplish this, but did not publish nature of cross-validation Increased speedup will be noticable here as parameter optimization repeatedly recalculates the kernel matrix Cross-validation will also repeat the calculation of the kernel matrix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}