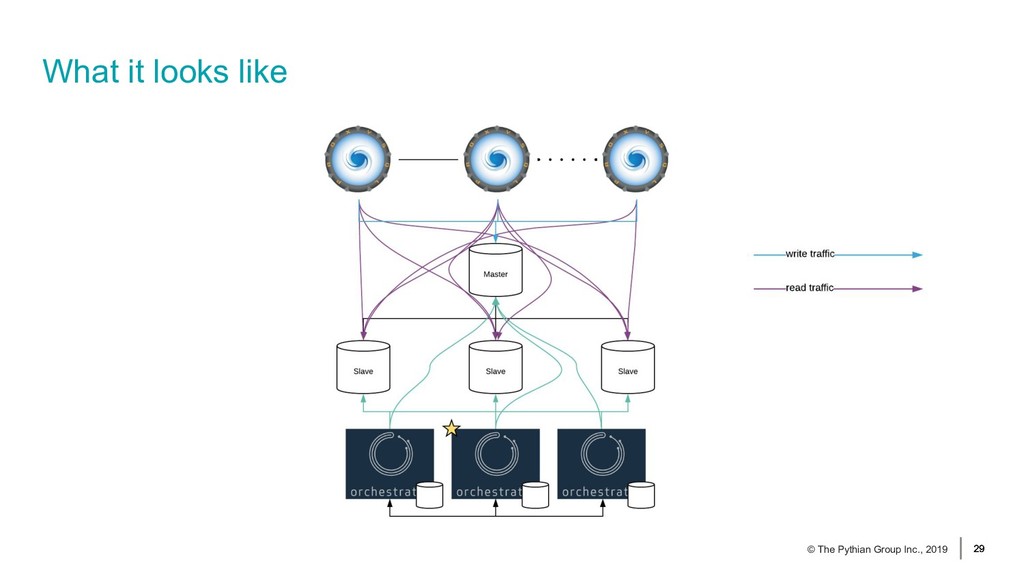
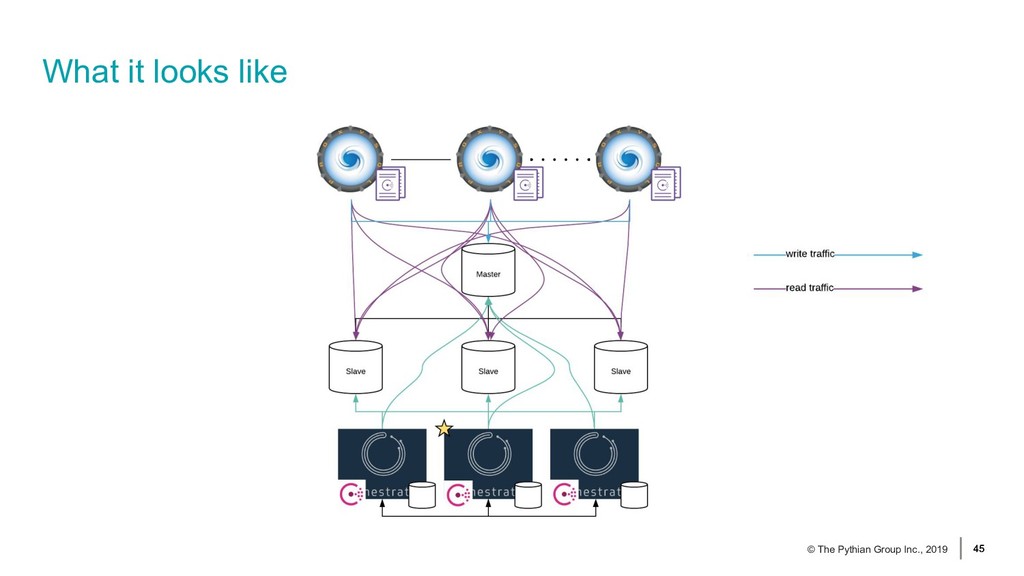
In this session we will be considering a standard asynchronous MySQL replication technology. We'll go and analyse how we can eliminate single points of failure in the technology stack and how we can avoid network partitioning issues. We will use Orchestrator to help us achieve master high availability and we will use ProxySQL to redirect application traffic to the appropriate MySQL servers.
I will show how we can make each component on its own highly available, how we can prepare for a full datacenter outage and even up to a full scale regional outage when leveraging a public cloud provider.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
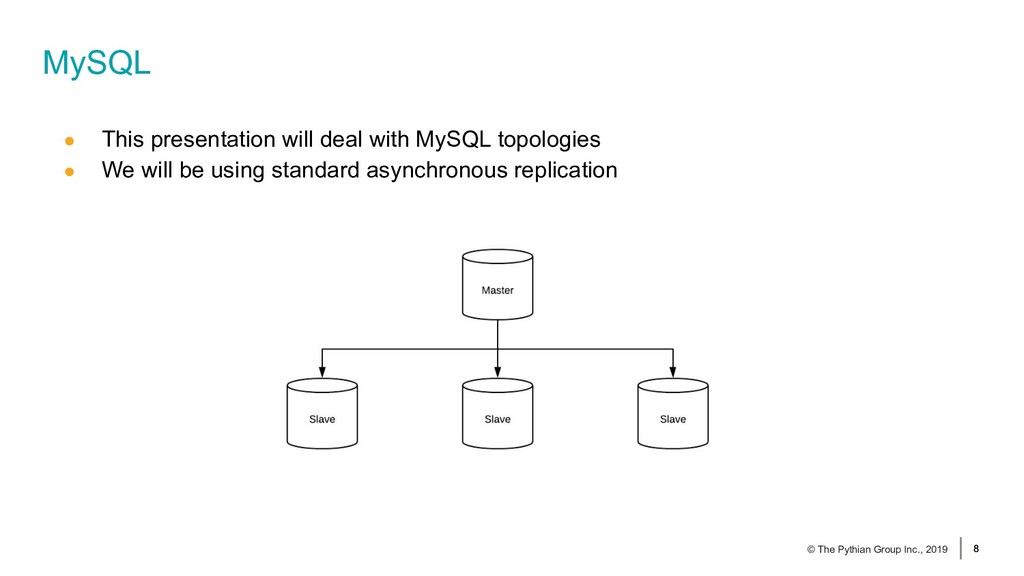{kind=link}
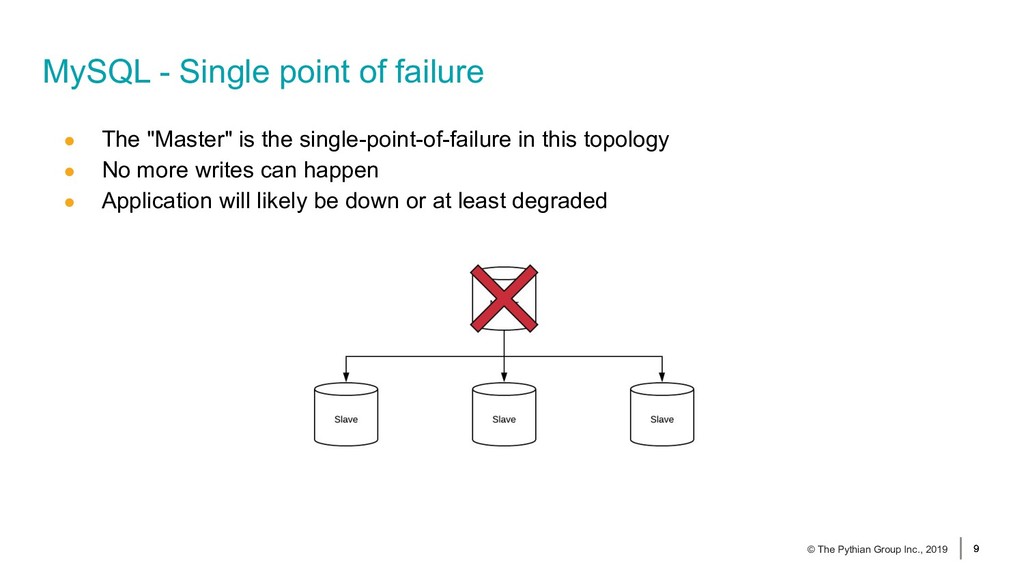{kind=link}
{kind=link}
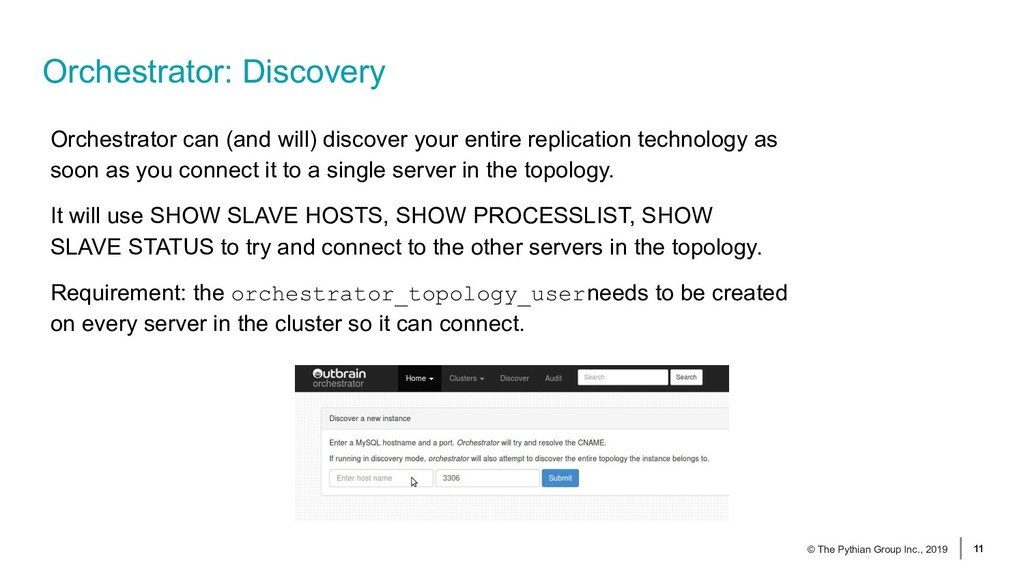{kind=link}
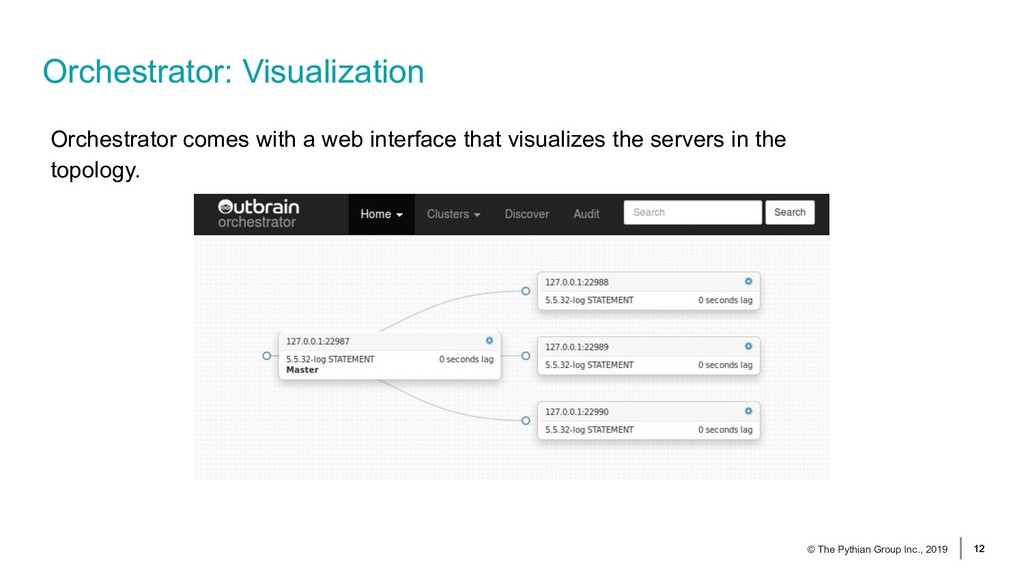{kind=link}
{kind=link}
{kind=link}
{kind=link}
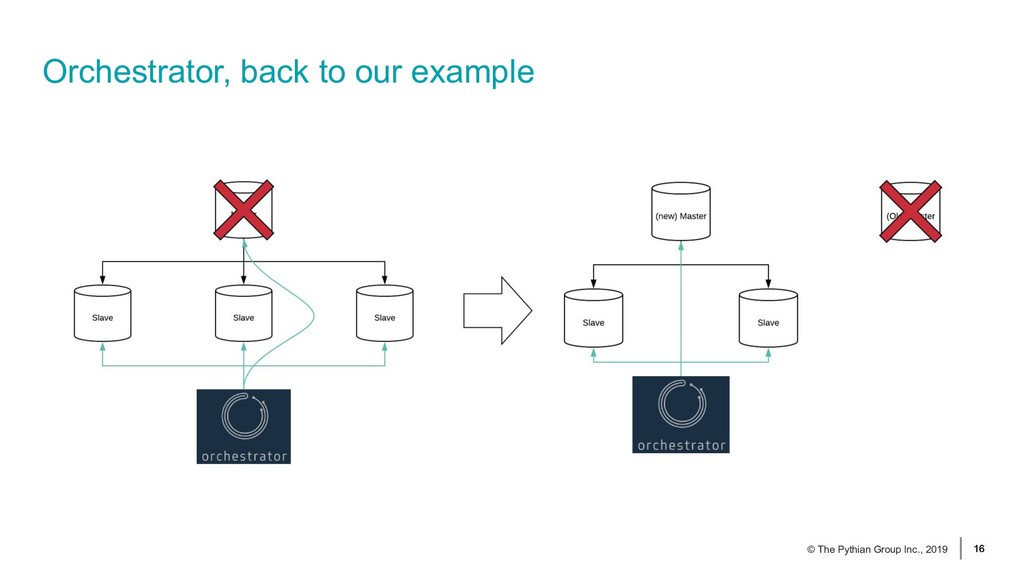{kind=link}
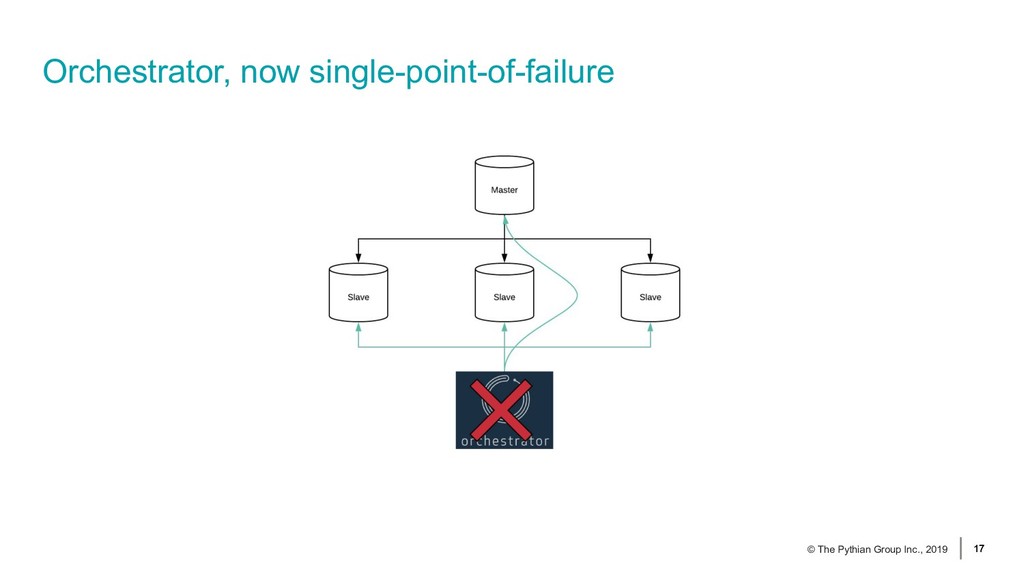{kind=link}
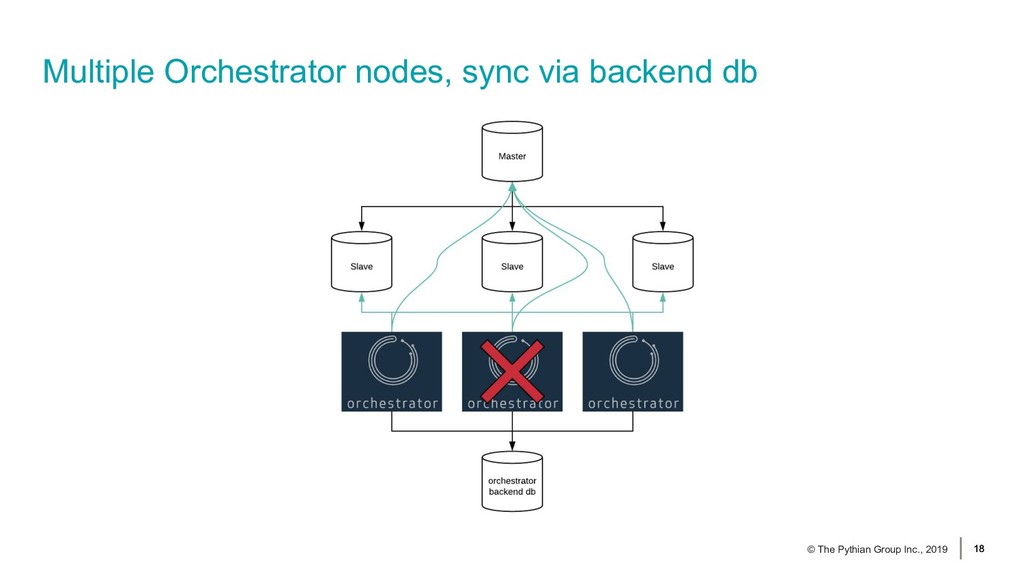{kind=link}
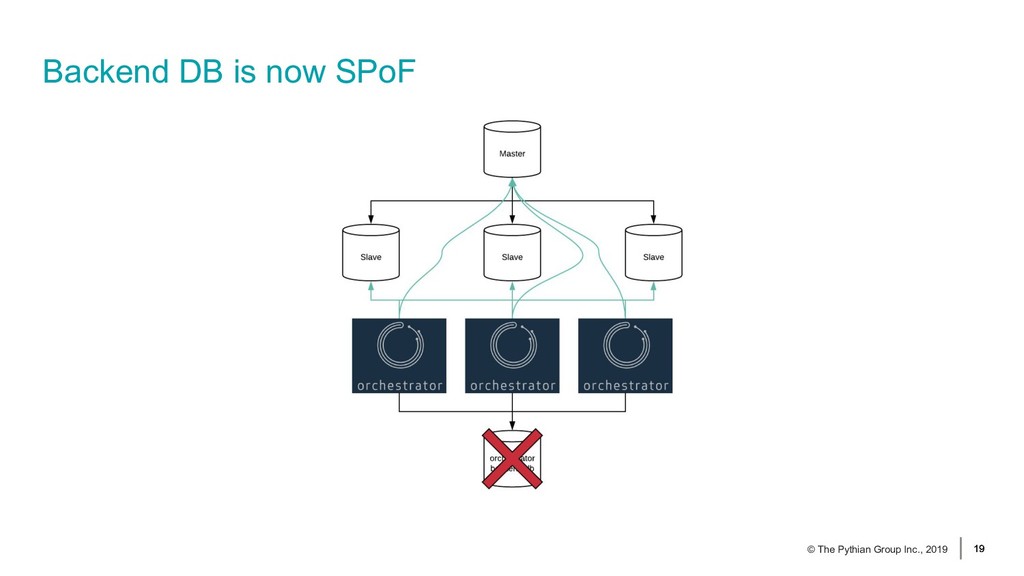{kind=link}
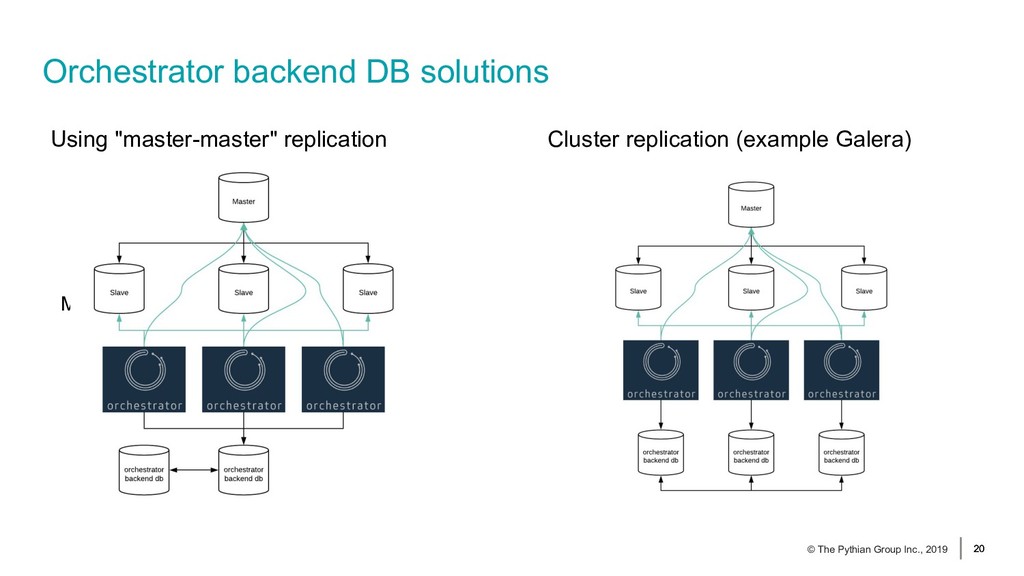{kind=link}
{kind=link}
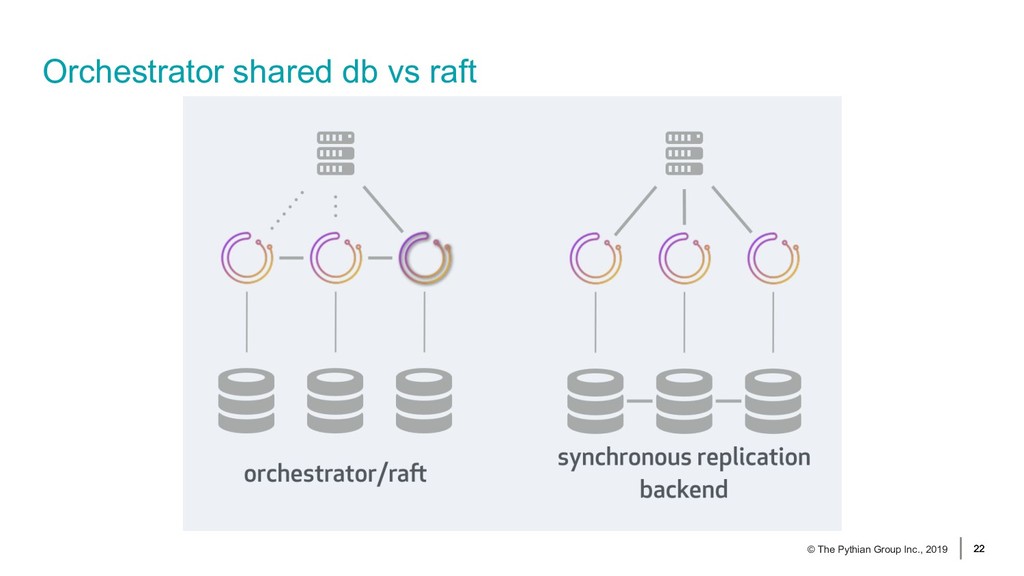{kind=link}
{kind=link}
{kind=link}
{kind=link}
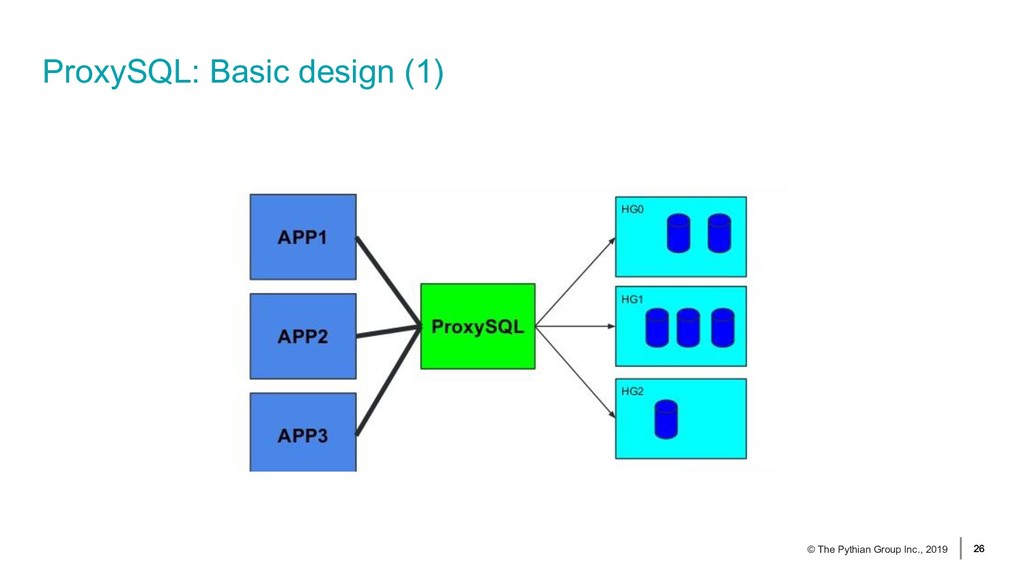{kind=link}
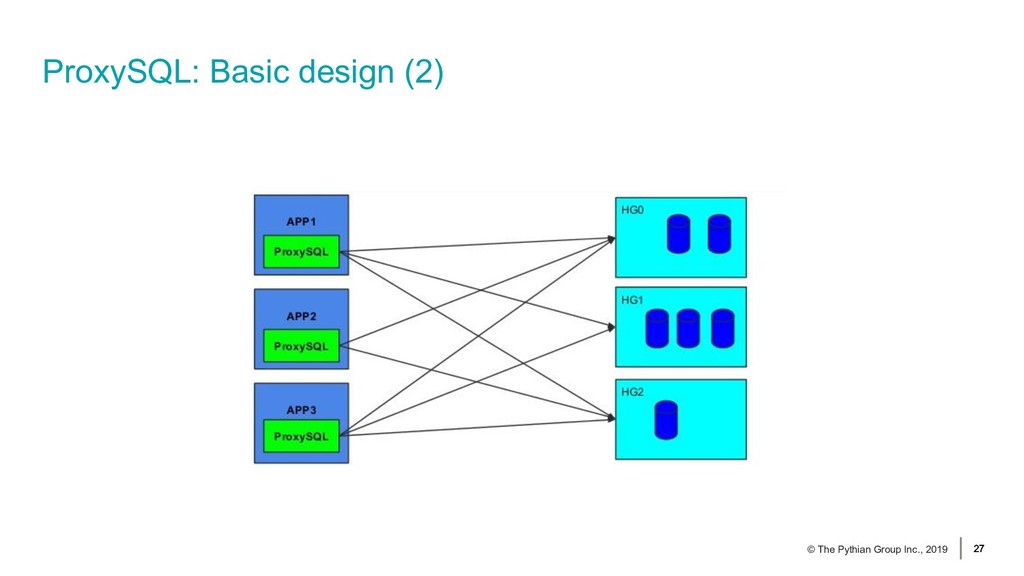{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}