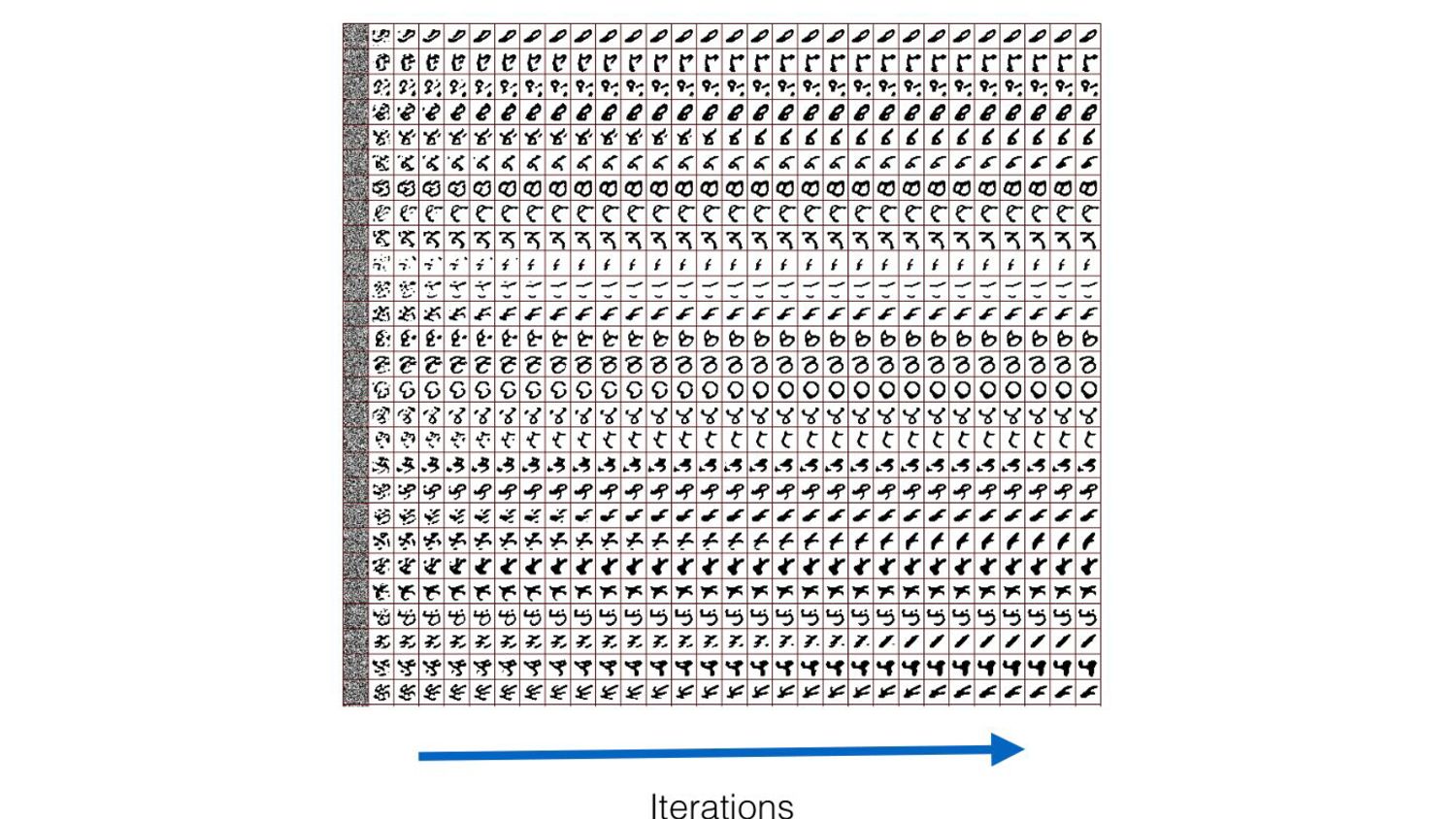
models seem to struggle on this setup - A simple test for out-of-distribution capabilities and compositionality - If you fine-tune (e.g., LoRa, or full fine-tuning) a stable diffusion model on MNIST with text describing the digit categories => models struggle to generate new categories
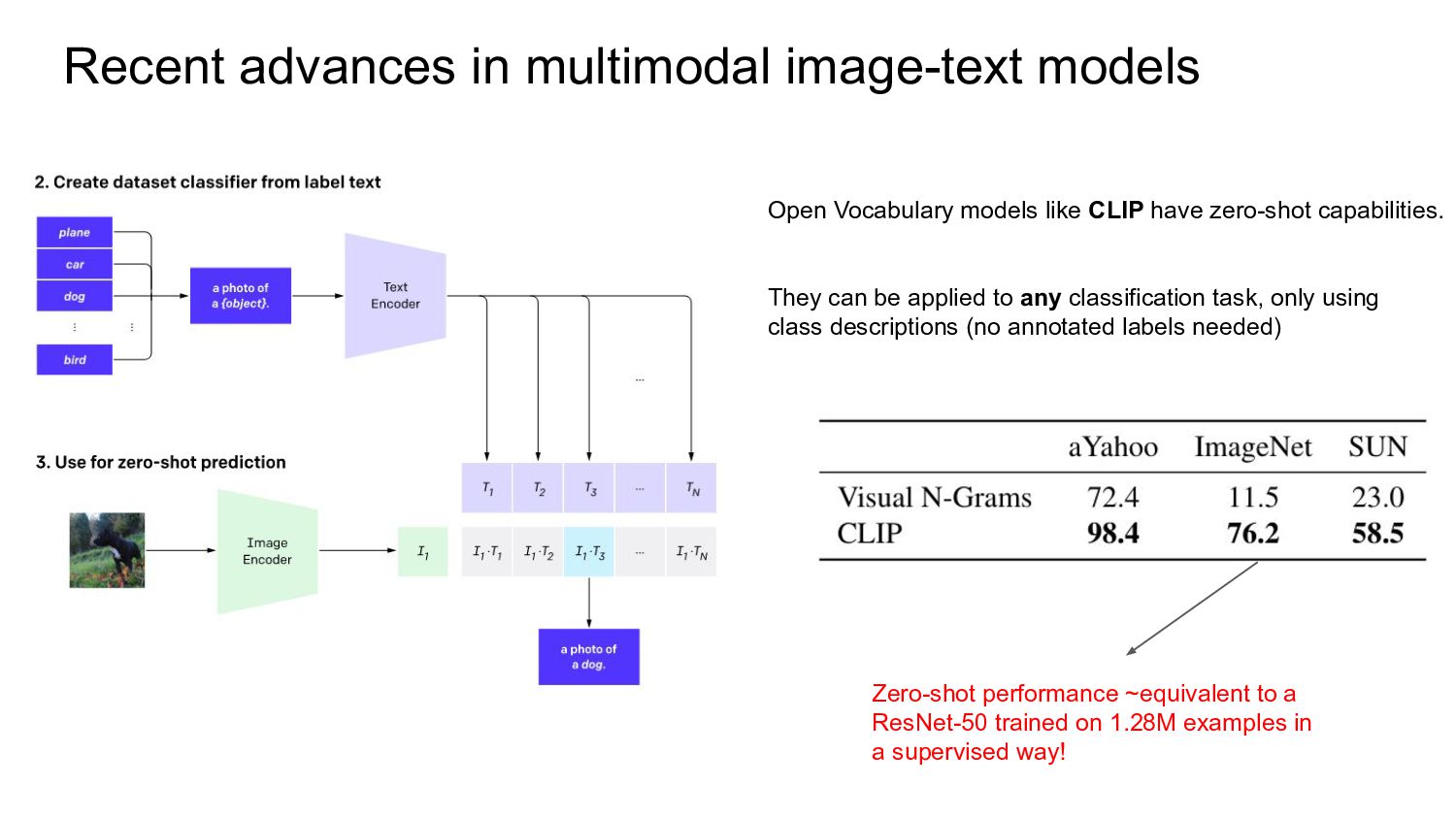
CLIP have zero-shot capabilities. They can be applied to any classification task, only using class descriptions (no annotated labels needed) Zero-shot performance ~equivalent to a ResNet-50 trained on 1.28M examples in a supervised way!
with relations and attributes - Handling long and detailed prompts - Attribute based prompts / description, in general how to to handling of new categories/concepts (VL-Taboo from Vogel et. al)
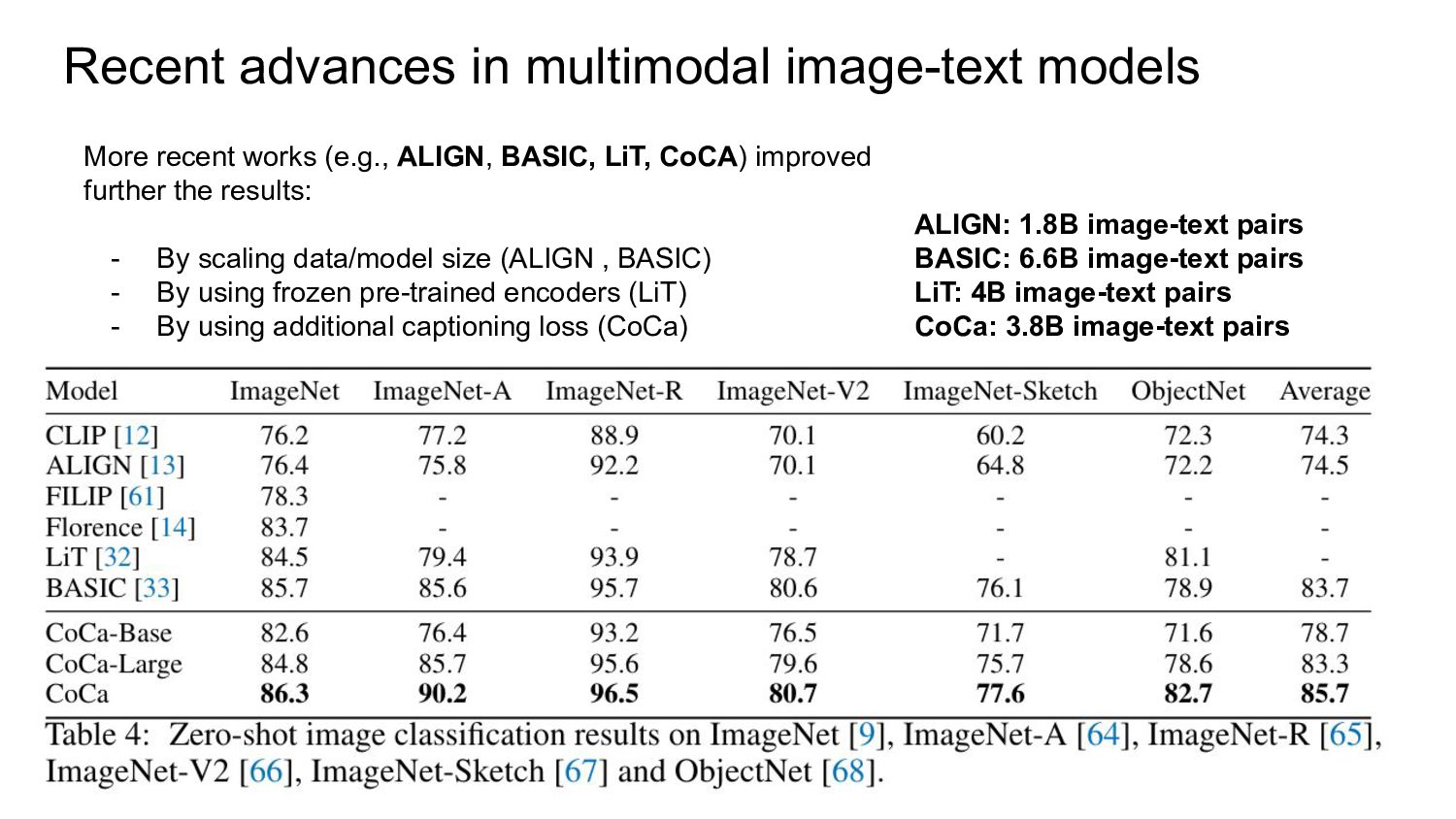
- MT5-XXL (text encoder), ~7B - ViT-G/14 (image encoder) ~2.5B - MT5-XXL (text decoder) ~7B - Unfreeze partly few layers, find the best unfreezing schedule to optimize compute - Training on higher resolution - Using better filtered datasets such as DataComp 1.4B - Challenge: too many moving parts/choices, small scale experiments that can predict large scale ones
- Image to text - Self-consistency loss : im -> text -> im, text -> im -> text - Unimodal losses? - Generating hard negatives adversarially? CLIP extensions
- As a research aid, e.g. to deal with huge number of papers - Help on understanding, writing, or summarizing papers - Make new connections between subjects
18.3M figure-caption pairs (XML based metadata provided in PubMed), similar to “Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing”
a eukaryote. (a) Human; (b) E. coli. Reproduced with permission from [43] One of Two BottlenoseDolphins That Passed the Mark Test, Thus Demonstrating Mirror Self-Recognition(Photo credit: Diana Reiss, Wildlife Conservation Society) PFV IN active site in committed and drug-bound statesViews without drug (a) and with MK0518 (b) or GS9137 (c) bound. Protein and DNA in upper panels are cartoons, with A17, DNA bases and the side chains of indicated amino acids as sticks. Drug atoms are colored: yellow, C; blue, N; red, O; orange, P; gray, F; green, Cl. The complex is shown as a solvent accessible surface in lower panels, colored by atoms (light gray, C; red, O; blue, N). Gray spheres are Mn2+ (a, labeled A and B) or Mg2+ (b, c) ions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}