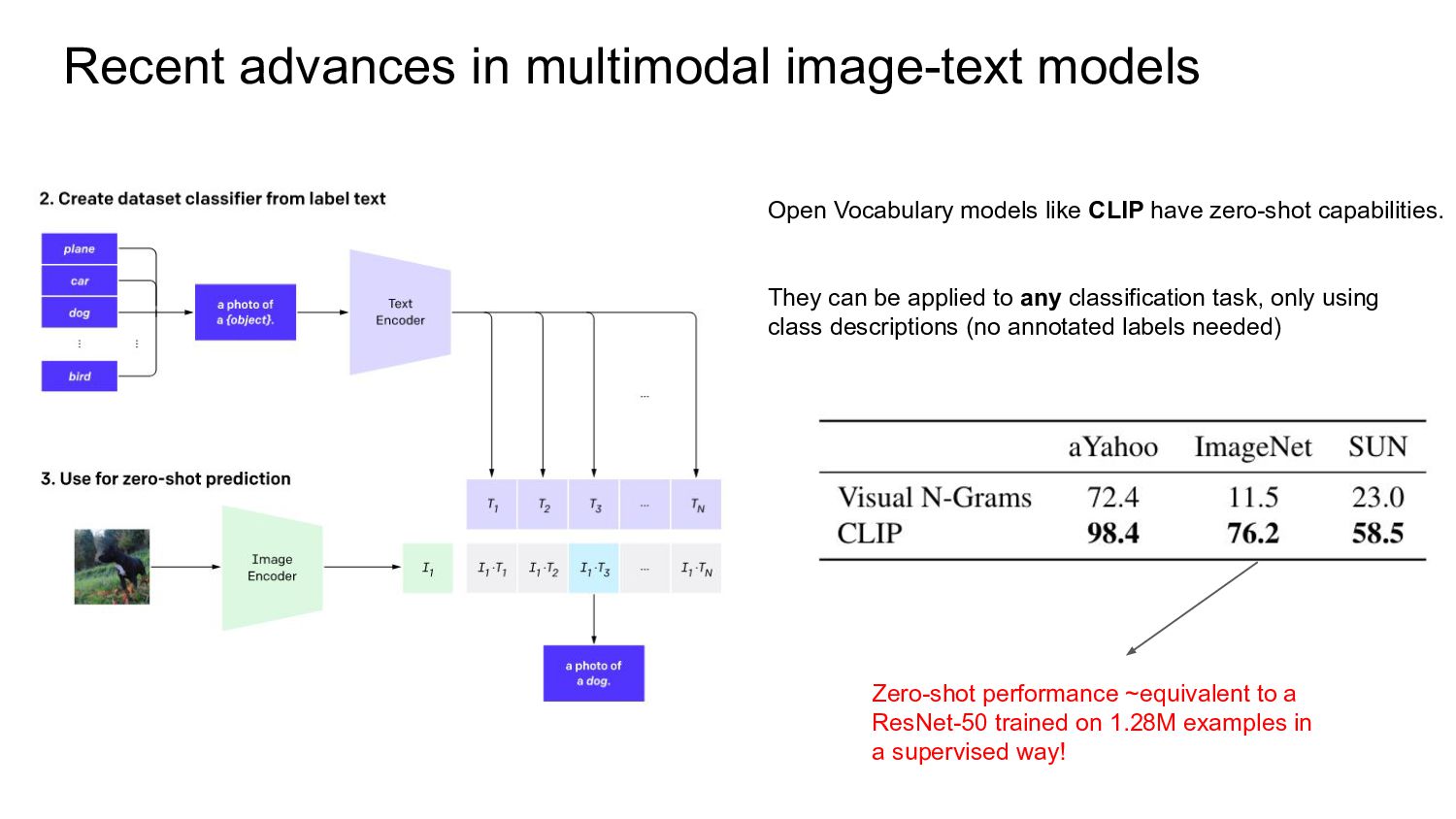
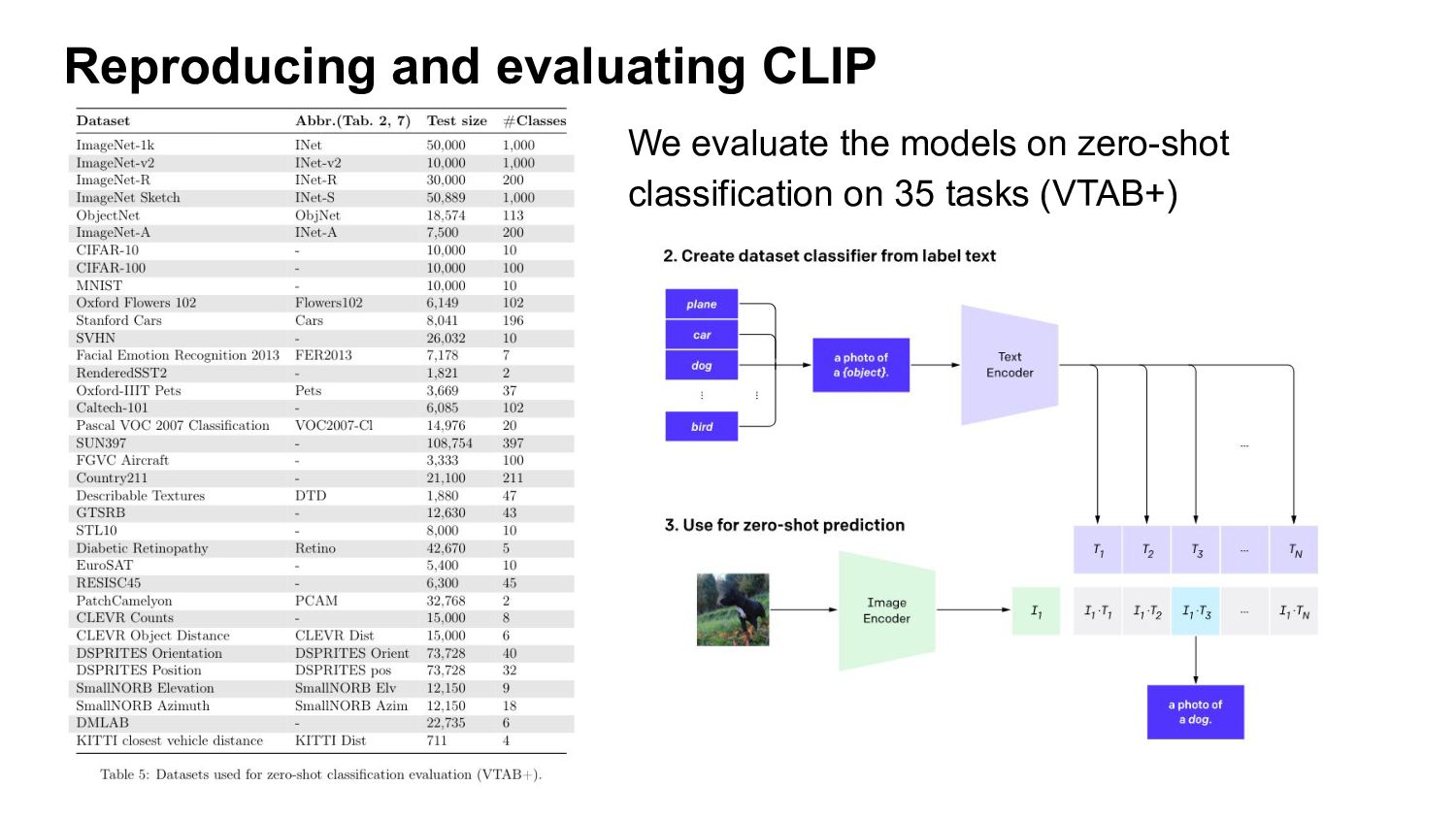
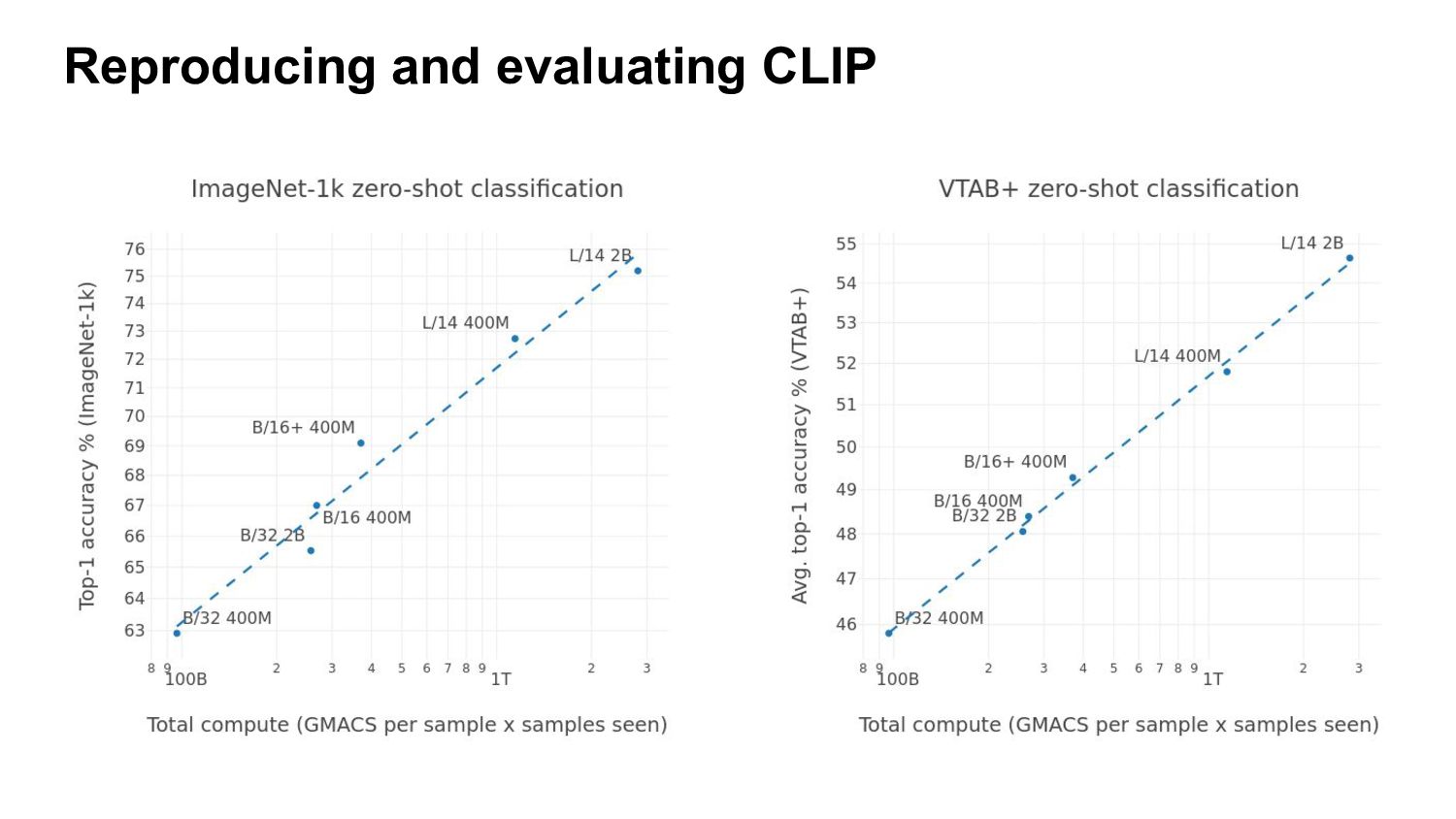
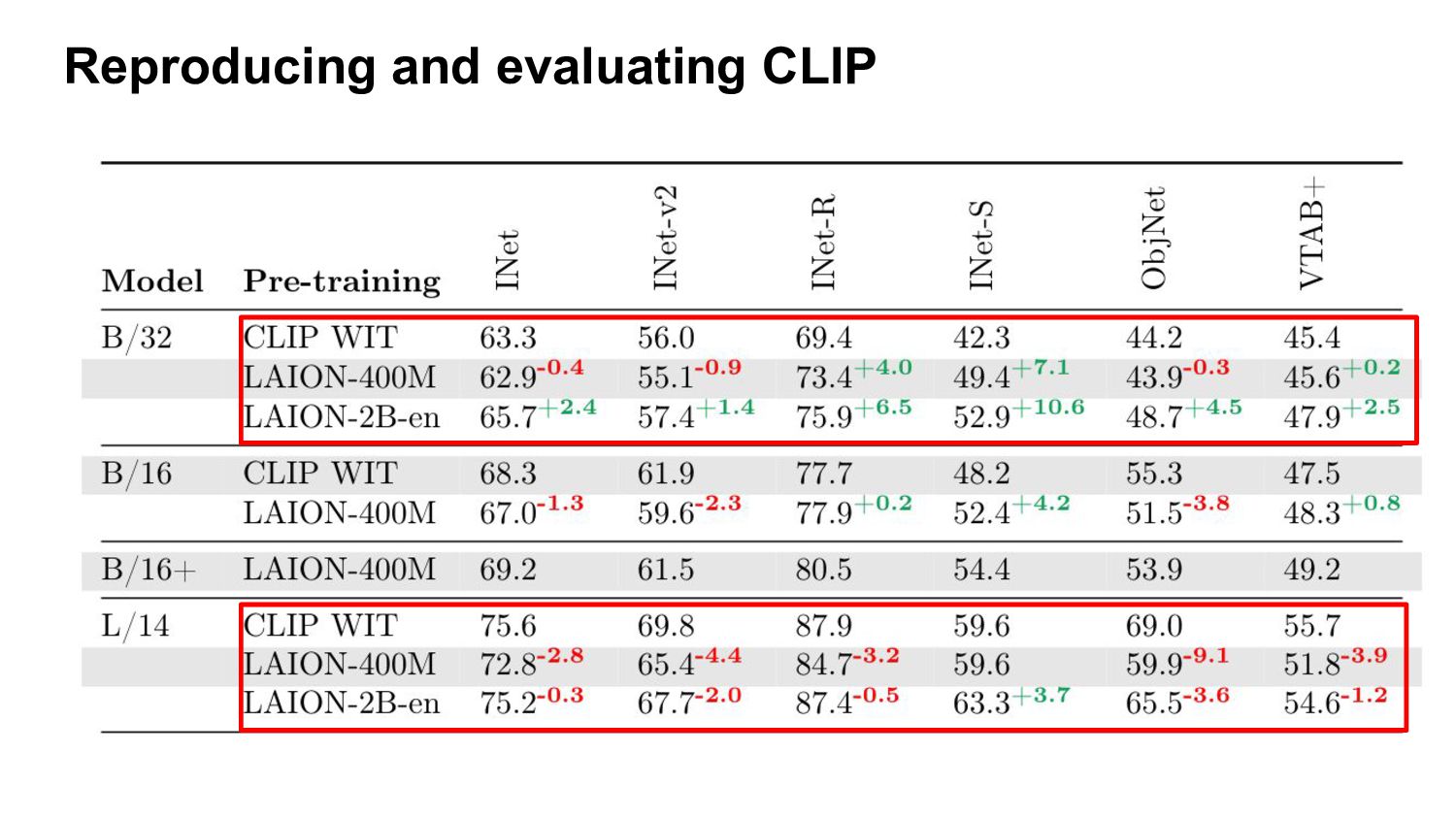
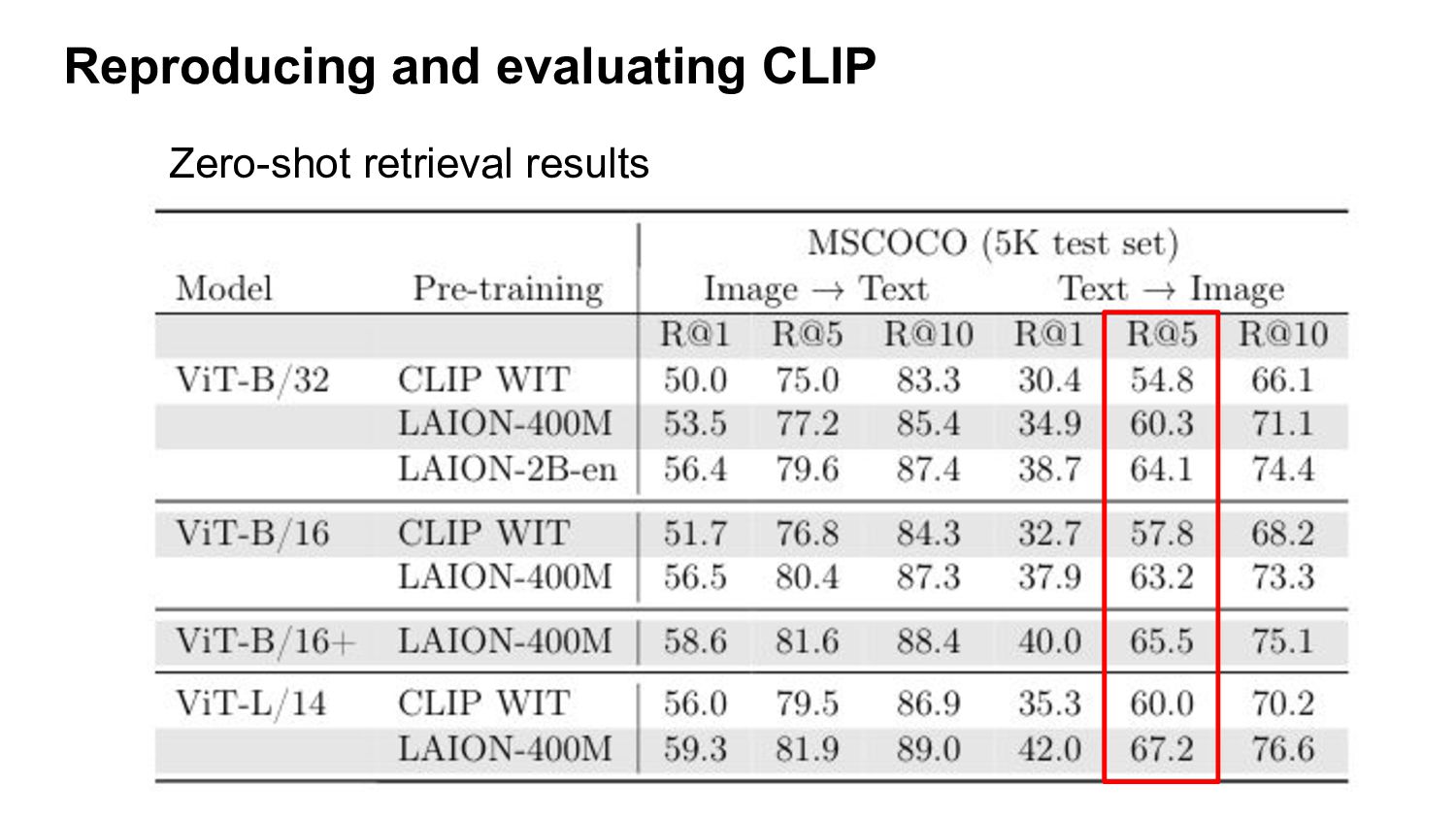
CLIP have zero-shot capabilities. They can be applied to any classification task, only using class descriptions (no annotated labels needed) Zero-shot performance ~equivalent to a ResNet-50 trained on 1.28M examples in a supervised way!
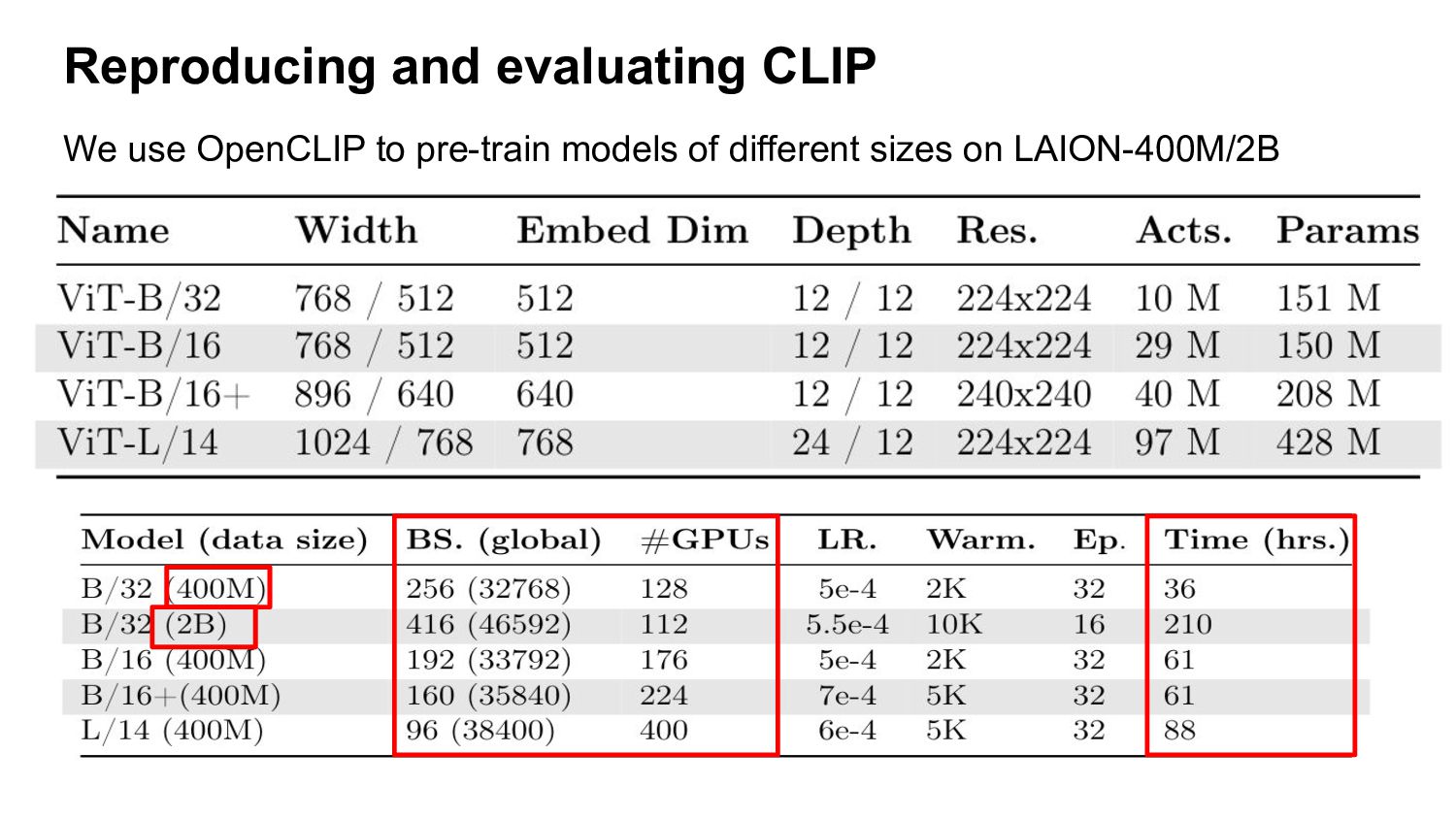
are available publicly - Datasets only available to a small number of industrial labs - Difficult to study training of text-image models at large scale and improve them We propose LAION-5B, an open dataset of 5.85 billion image-text pairs filtered from CommonCrawl
a subset of it. - ~220 TB of storage needed for the full dataset (2.65 TB for the metadata). - In the metadata, we provide: - Url of the image - Caption - CLIP cosine similarity between image and caption - NSFW score - Watermark score
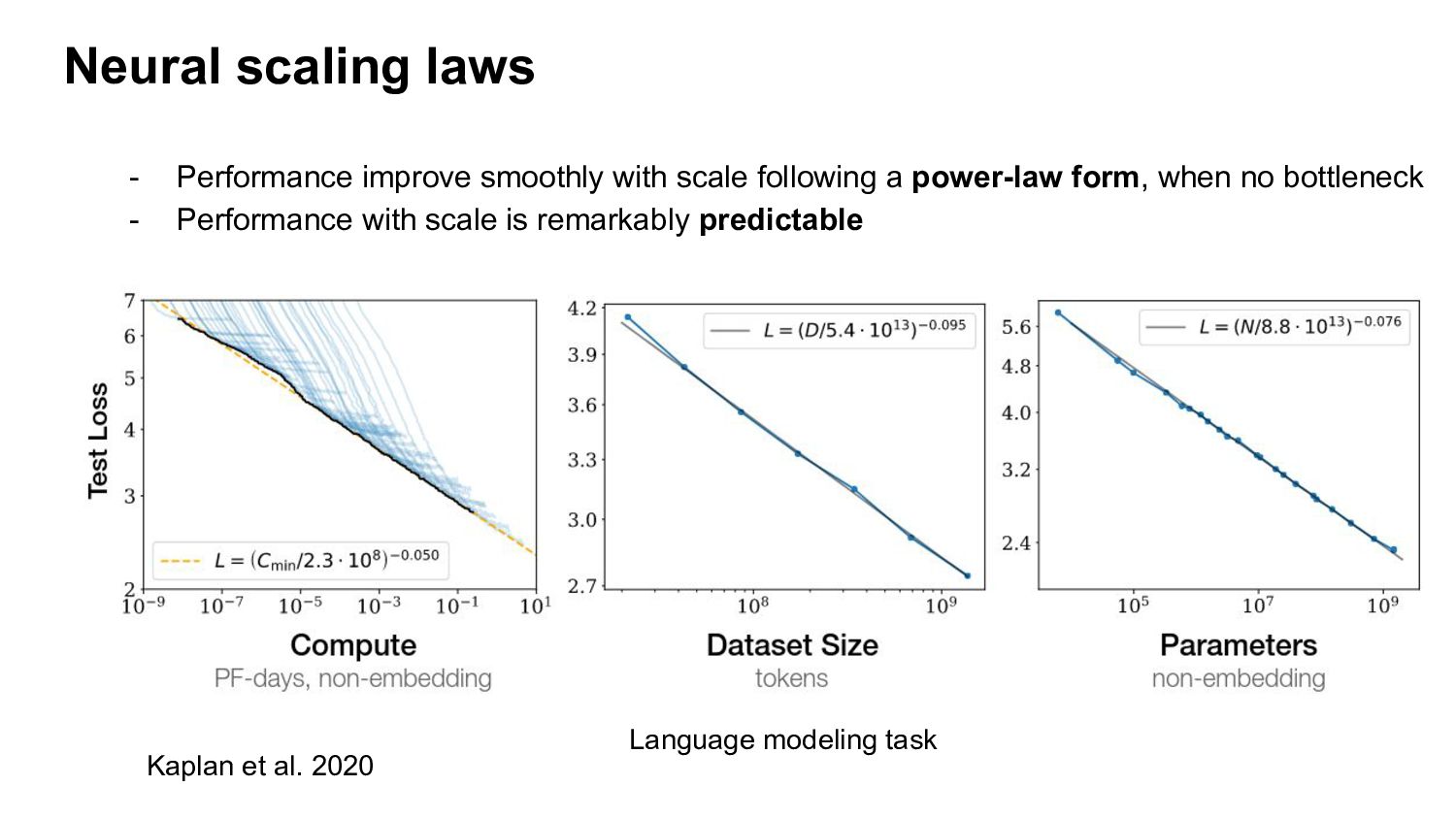
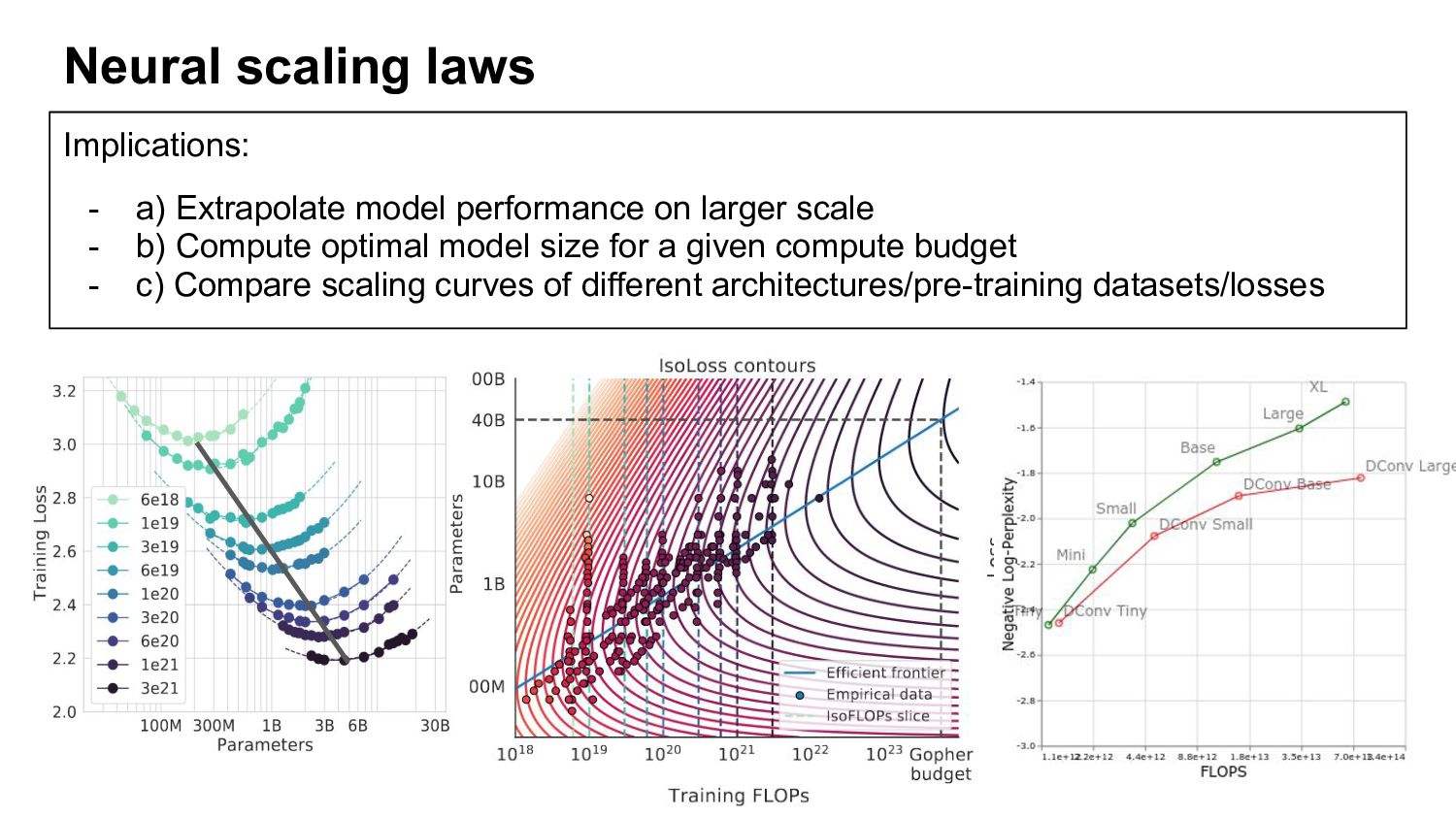
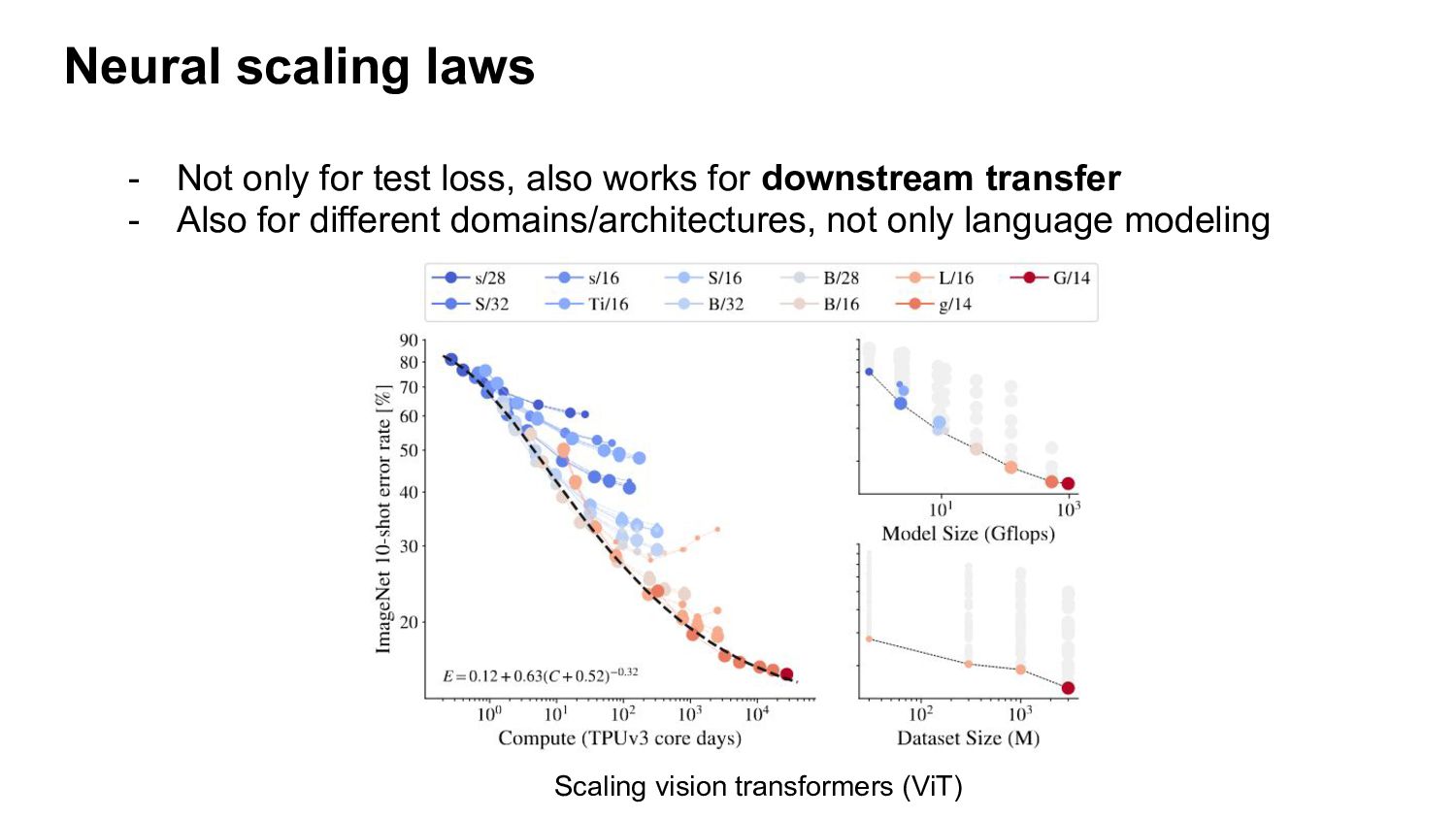
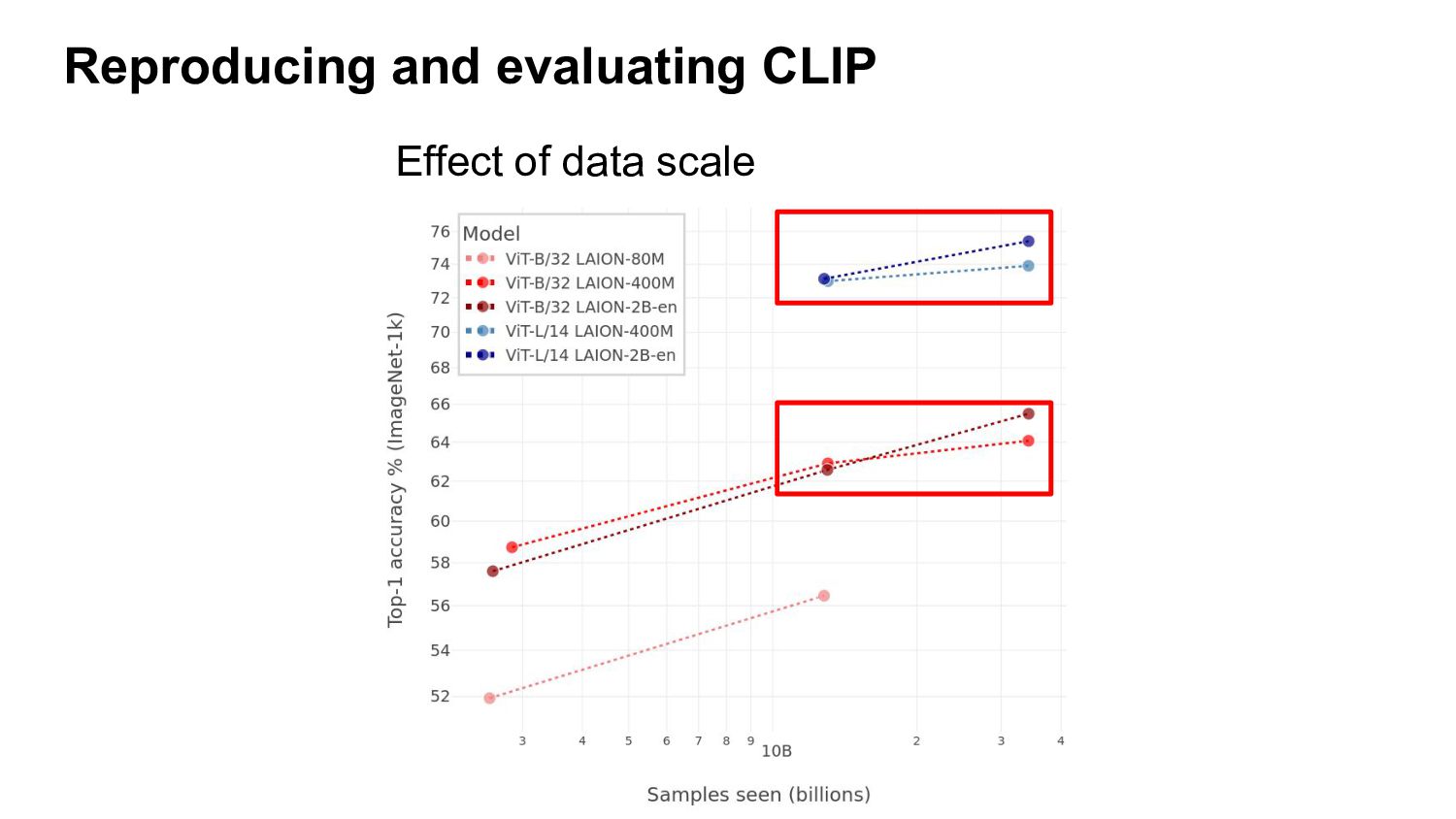
b) Compute optimal model size for a given compute budget - c) Compare scaling curves of different architectures/pre-training datasets/losses Neural scaling laws
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}