In recent years, significant advances made in deep neural networks enabled the creation
of groundbreaking technologies such as self-driving cars and voice-enabled
personal assistants. Almost all successes of deep neural networks are about prediction,
whereas the initial breakthroughs came from generative models. Today,
although we have very powerful deep generative modeling techniques, these techniques
are essentially being used for prediction or for generating known objects
(i.e., good quality images of known classes): any generated object that is a priori
unknown is considered as a failure mode (Salimans et al., 2016) or as spurious
(Bengio et al., 2013b). In other words, when prediction seems to be the only
possible objective, novelty is seen as an error that researchers have been trying hard
to eliminate. This thesis defends the point of view that, instead of trying to eliminate
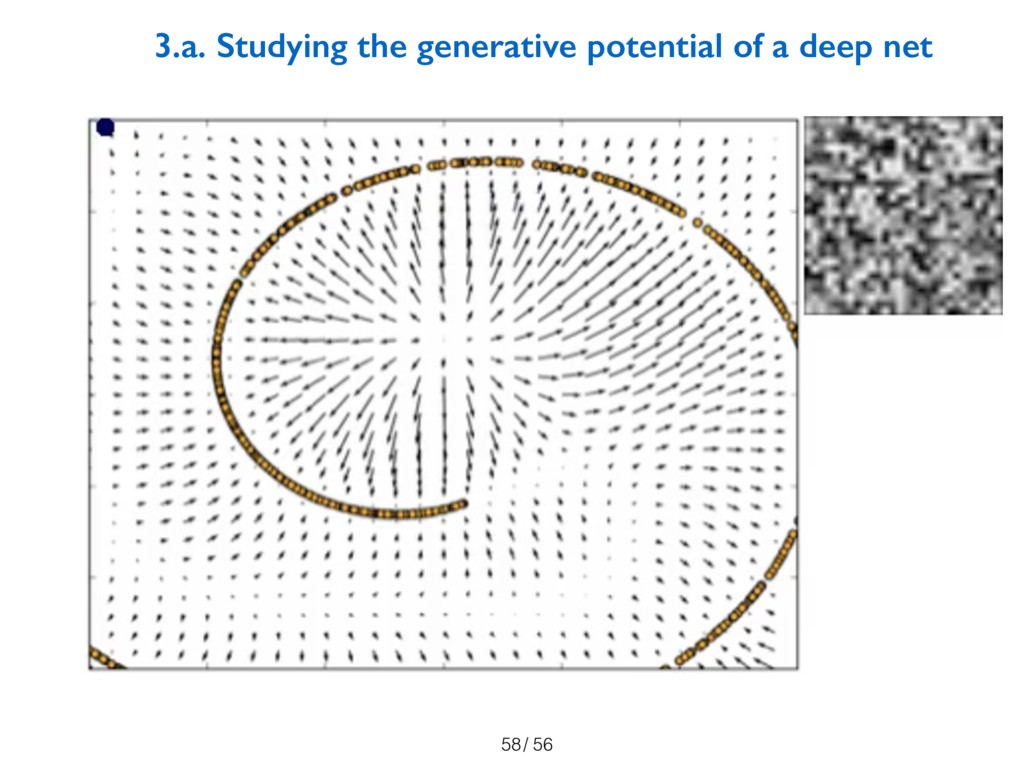
these novelties, we should study them and the generative potential of deep nets
to create useful novelty, especially given the economic and societal importance of
creating new objects in contemporary societies. The thesis sets out to study novelty
generation in relationship with data-driven knowledge models produced by
deep generative neural networks. Our first key contribution is the clarification of
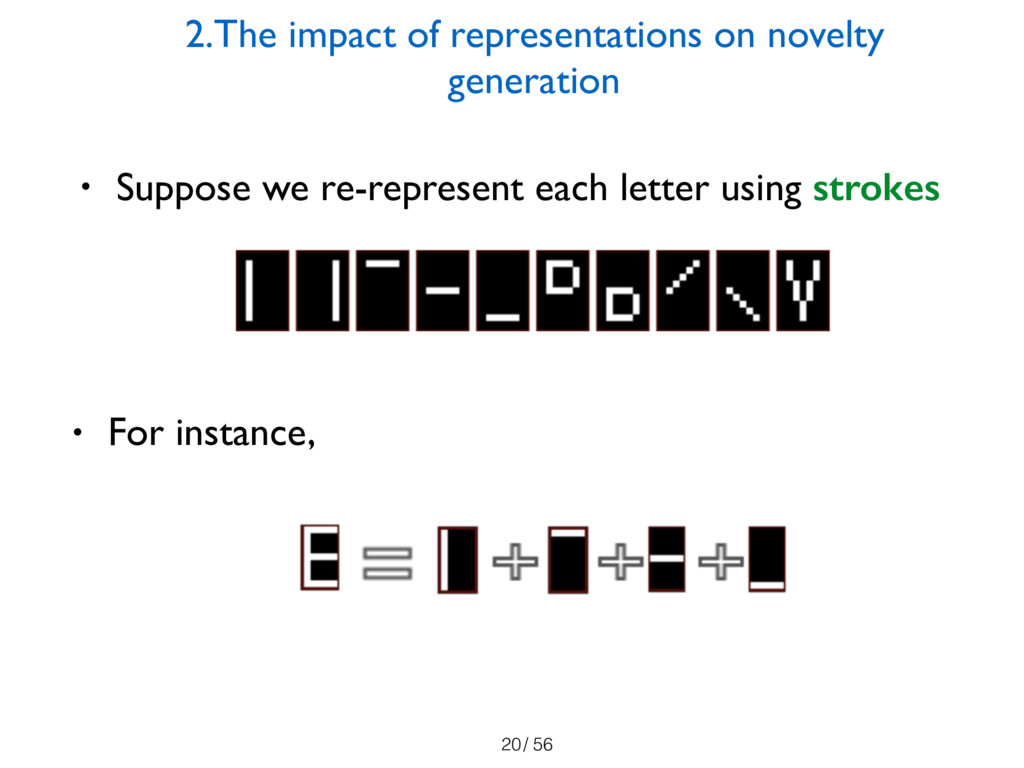
the importance of representations and their impact on the kind of novelties that
can be generated: a key consequence is that a creative agent might need to rerepresent
known objects to access various kinds of novelty. We then demonstrate
that traditional objective functions of statistical learning theory, such as maximum
likelihood, are not necessarily the best theoretical framework for studying novelty
generation. We propose several other alternatives at the conceptual level. A second
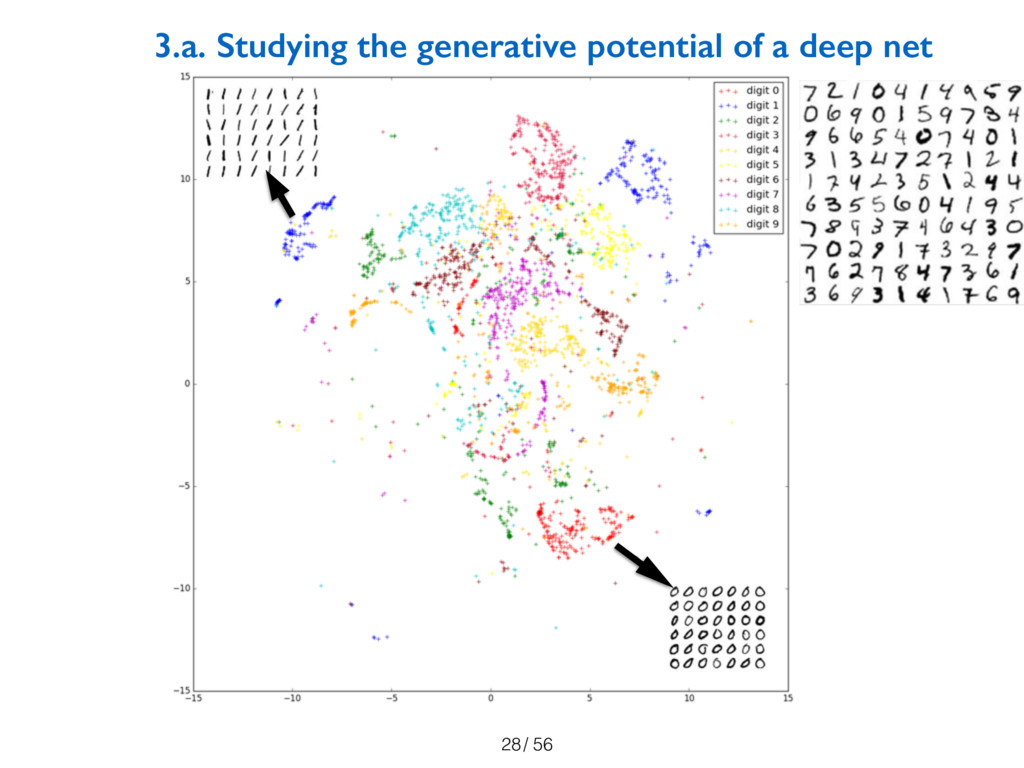
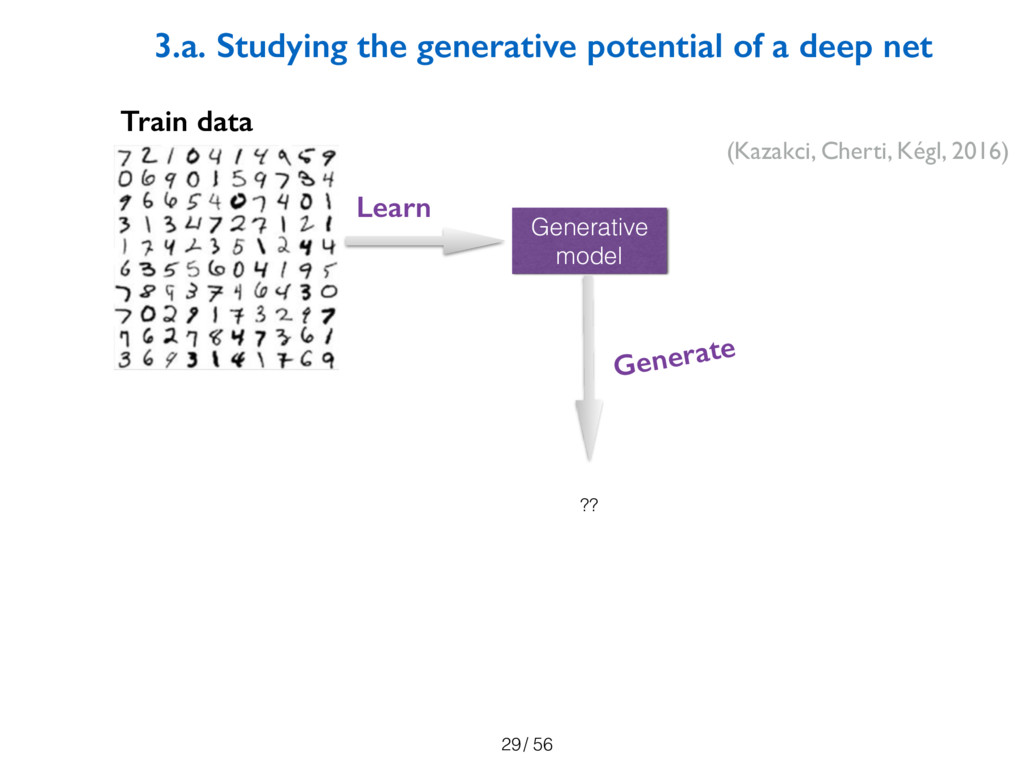
key result is the confirmation that current models, with traditional objective
functions, can indeed generate unknown objects. This also shows that even though
objectives like maximum likelihood are designed to eliminate novelty, practical
implementations do generate novelty. Through a series of experiments, we study
the behavior of these models and the novelty they generate. In particular, we propose
a new task setup and metrics for selecting good generative models. Finally,
the thesis concludes with a series of experiments clarifying the characteristics of
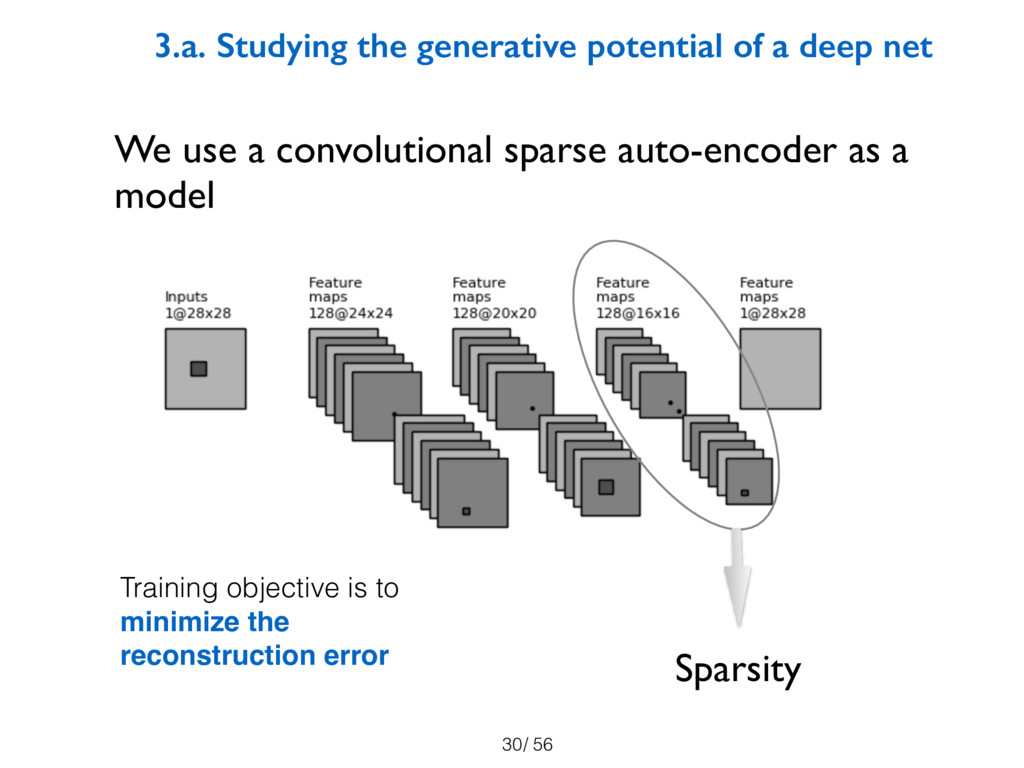
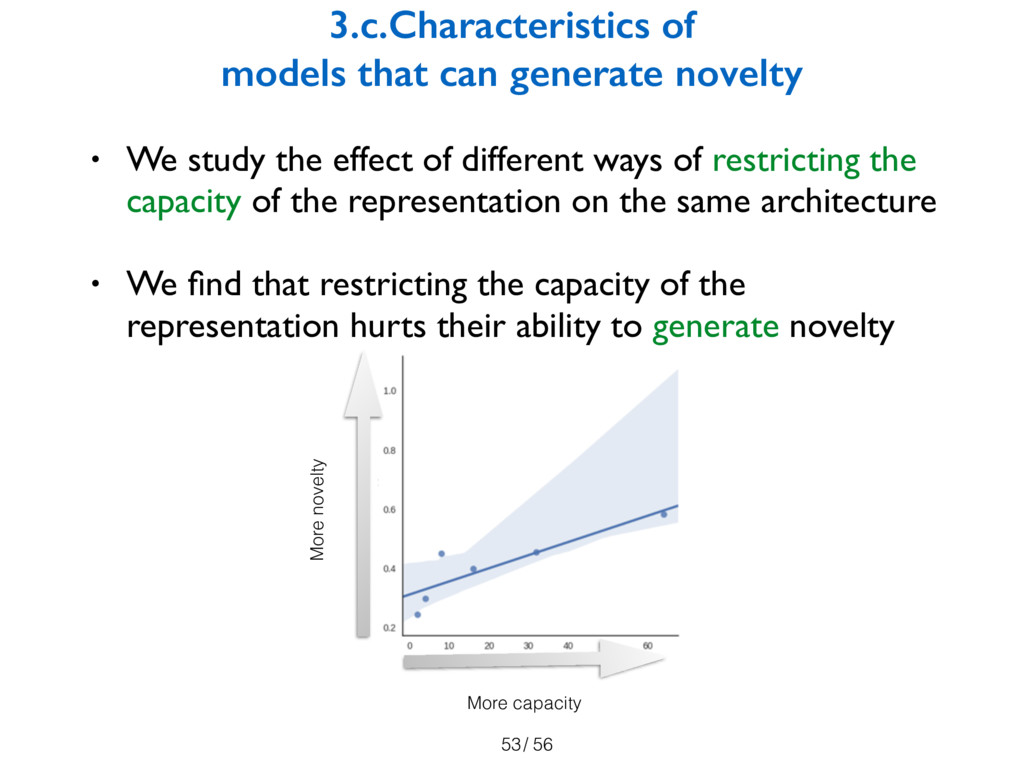
models that can exhibit novelty. Experiments show that sparsity, noise level, and
restricting the capacity of the net eliminates novelty and that models that are better
at recognizing novelty are also good at generating novelty
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}