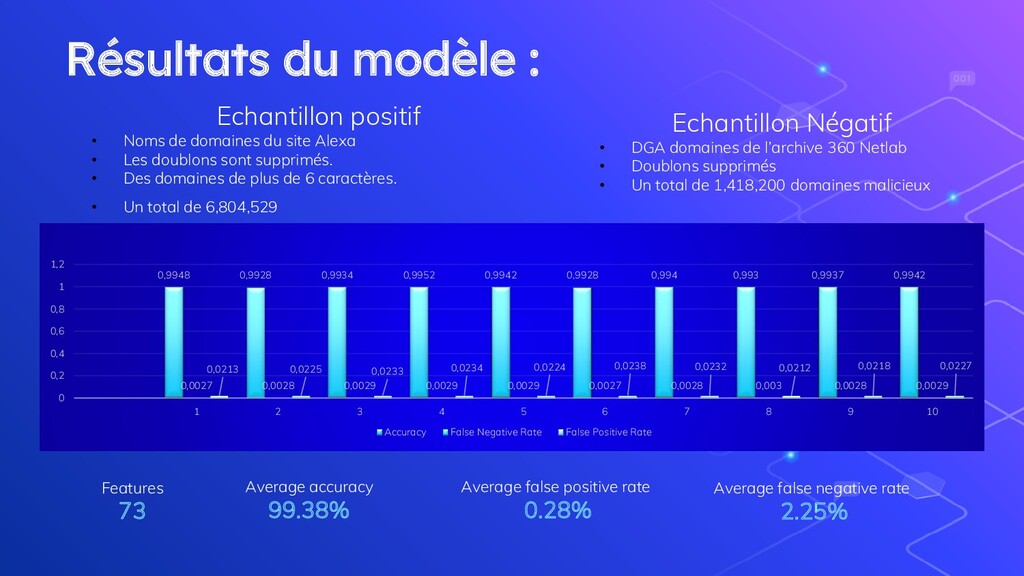
0,994 0,993 0,9937 0,9942 0,0027 0,0028 0,0029 0,0029 0,0029 0,0027 0,0028 0,003 0,0028 0,0029 0,0213 0,0225 0,0233 0,0234 0,0224 0,0238 0,0232 0,0212 0,0218 0,0227 0 0,2 0,4 0,6 0,8 1 1,2 1 2 3 4 5 6 7 8 9 10 Accuracy False Negative Rate False Positive Rate Echantillon positif • Noms de domaines du site Alexa • Les doublons sont supprimés. • Des domaines de plus de 6 caractères. • Un total de 6,804,529 Echantillon Négatif • DGA domaines de l’archive 360 Netlab • Doublons supprimés • Un total de 1,418,200 domaines malicieux Features 73 Average accuracy 99.38% Average false positive rate 0.28% Average false negative rate 2.25%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}