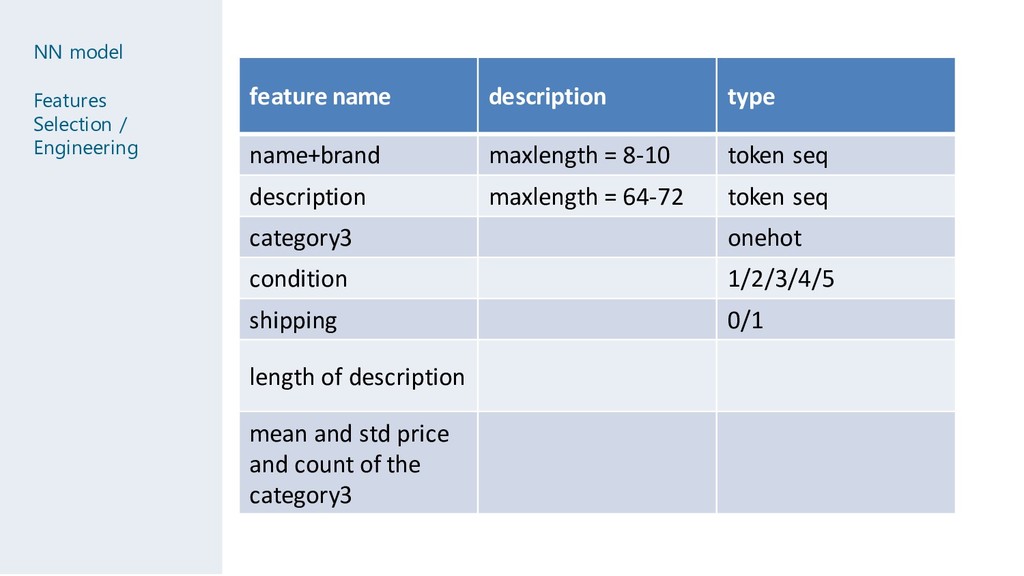
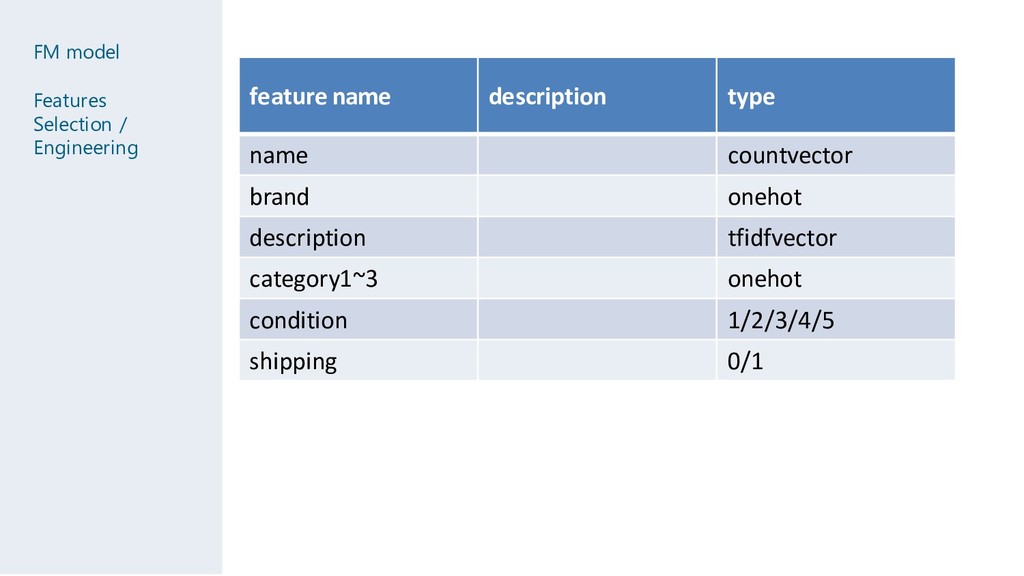
name+brand maxlength = 8-10 token seq description maxlength = 64-72 token seq category3 onehot condition 1/2/3/4/5 shipping 0/1 length of description mean and std price and count of the category3
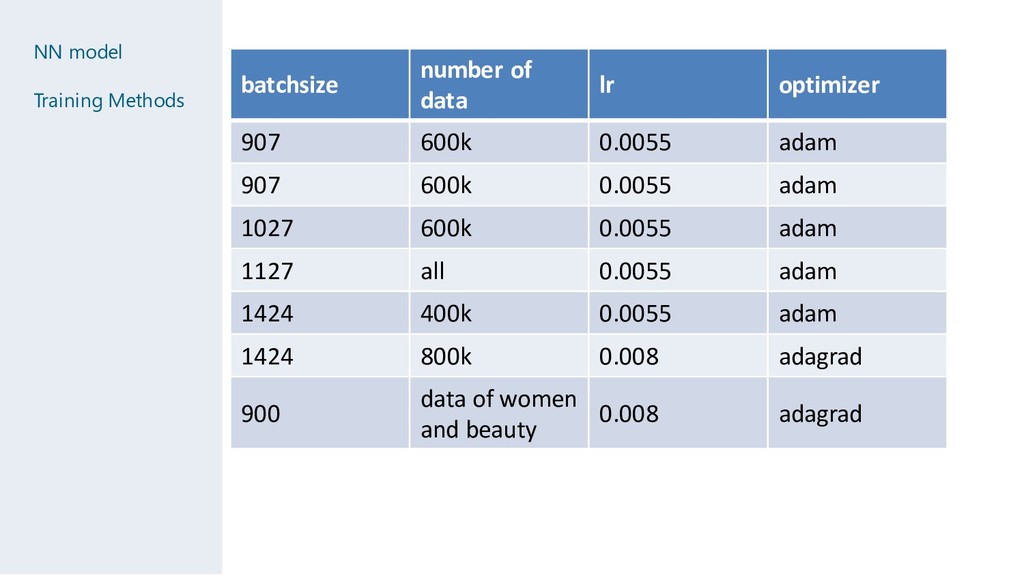
907 600k 0.0055 adam 907 600k 0.0055 adam 1027 600k 0.0055 adam 1127 all 0.0055 adam 1424 400k 0.0055 adam 1424 800k 0.008 adagrad 900 data of women and beauty 0.008 adagrad
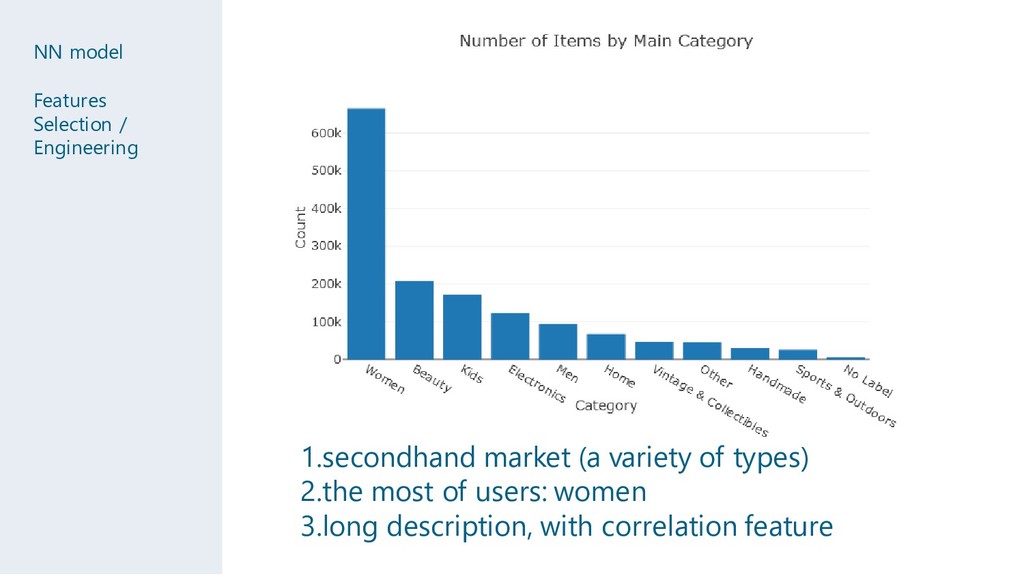
rise when you spent more time on the manual work: Franch letter Cellphone name ...... • Make model to find the gradient more easily than others in the same time by manual the training process.
large. Be caution about the memory. • FM's overfits easily cause it has too many params. Set the epochs below 10. • Ensembled with the NN model by sum. FinalRes = 0.6 * nnres + 0.4 * fmres
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}