reliable way of modeling schemas. ▸ Central facts table centered around the User ▸ Joined with other tables to do analytical queries ▸ Number of hits, Number of conversions and so on
+ CSS data capture and visualization ▸ Record an entire user session on site and then replay it later. ▸ “Send an HTTP call when the user moves the mouse.” ▸ Considerable increase in volume
▸ Database locking ▸ “When any process wants to write, it must lock the entire database file for the duration of its update.” ▸ This results in direct data loss. RIP
sqlite DB files instead of one. ▸ Divide them up based on customer_id ▸ Divide them up even further based on time ▸ Daily is too frequent, monthly too infrequent. ▸ account_id/week_{week_number}.db looks good
“My code takes n seconds to run” ▸ Kinda sorta right: ▸ “My code takes n seconds to run on a 4 core CPU, 12Gig RAM machine which has no other processes running, and has an SSD capable of reaching 4k maximum IOPS. I can optimize it to insert k messages per second.” ▸ TL;DR: It’s complicated.
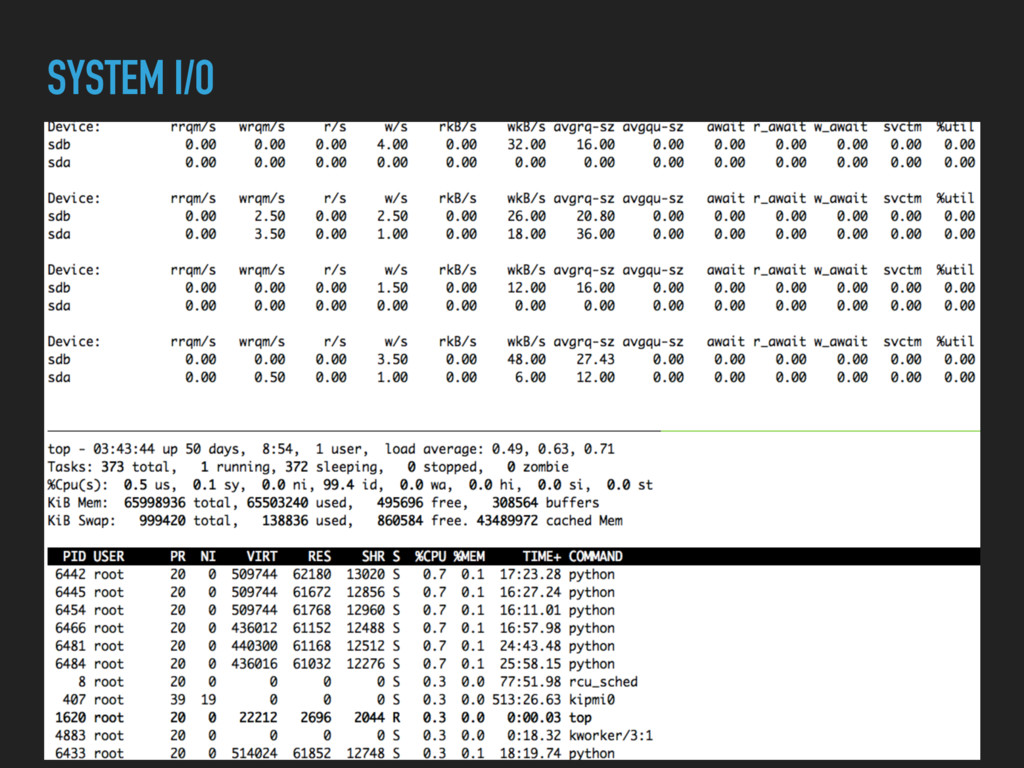
case if you can. ▸ Utilities like iostat, iotop, htop, ftop are your friends. ▸ Tweak a config and see the impact. ▸ Don’t use resource-heavy monitoring tools. ▸ Don’t believe blog posts! Do your own benchmarking.
simple!” ▸ Nope. SQL is just one part of the equation. Different systems work differently. ▸ Still easier than re-writing for a NoSQL system from scratch.
in a few days or weeks. ▸ Or even hours during your load testing. ▸ Huge tables with hundreds of millions of rows. ▸ Worse: Large indexes on these tables.
Suck for WRITE operations. 1 Write = 1 table write + 1 index update. ▸ On disk in PG if can’t store in its shared buffers. ▸ We’ll end up with higher disk I/O.
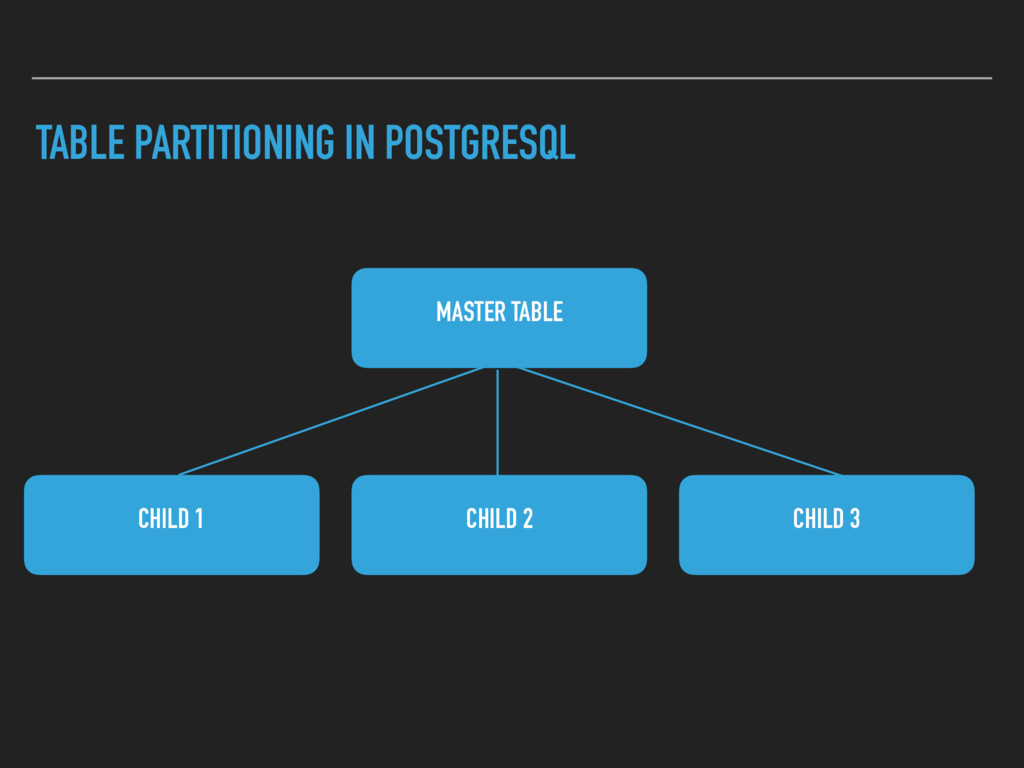
beginning. ▸ Partition one huge table into many smaller tables. PG offers partitioning based on inheritance. ▸ Divide up your data - ▸ random(data) ▸ my_custom_algorithm(data)
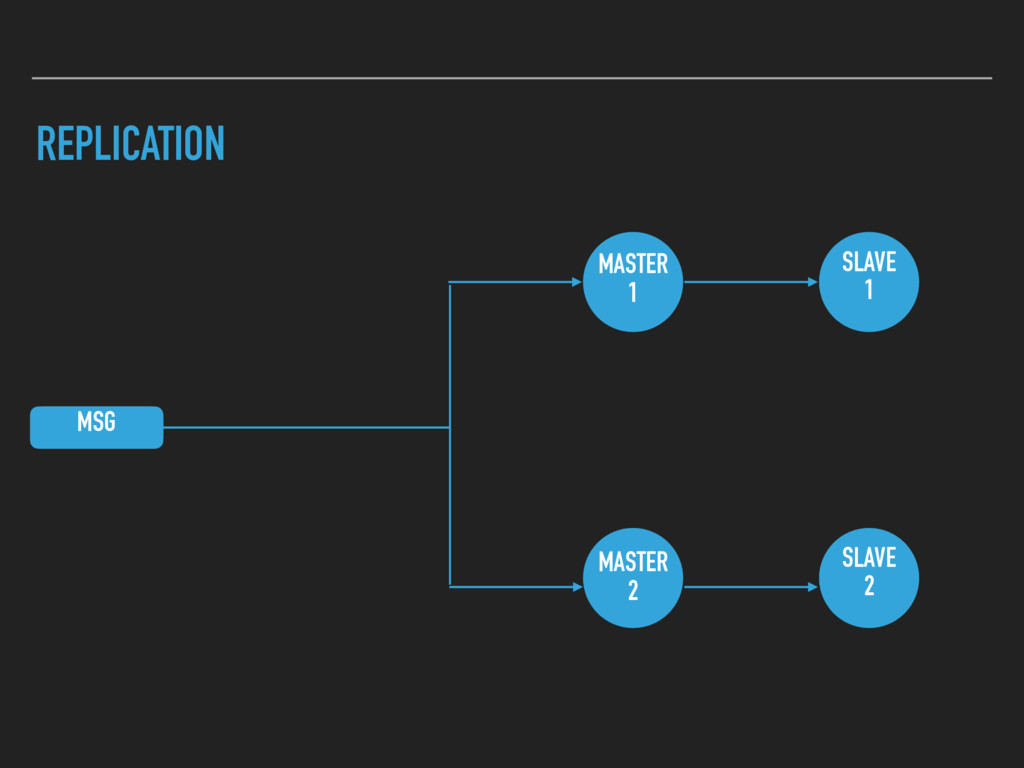
running with it. ▸ The slave becomes master when the old master dies. ▸ Question: What happens when the old master comes back to life? We now have 2 masters and no slaves!
BENCHMARKING 3. USE QUEUES AND PARTITION YOUR DATA 4. SHARDING IS UNAVOIDABLE AT SCALE 5. USE REPLICATION 6. BACKUPS ARE GOING TO SAVE YOU LESSONS IN SCALABILITY
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}