[CHISEL] Introduction to zero-downtime schema evolution in SQL databases.
Presentation on zero-downtime schema evolution in SQL databases. A short introduction, current tools, research, and approach to deal with this problem.
Rolling back failures. • Complex and mostly manual task. • Mostly tools only support MySQL. • Switching to alternative database can be costly. What could go wrong?
2. Profile commonly used SQL databases. 3. Prototype solution to deal with schema changes. 4. Verify prototype shows no blocking behaviour with said profiling tool. 5. Test in production environments / case studies. Run away if that fails
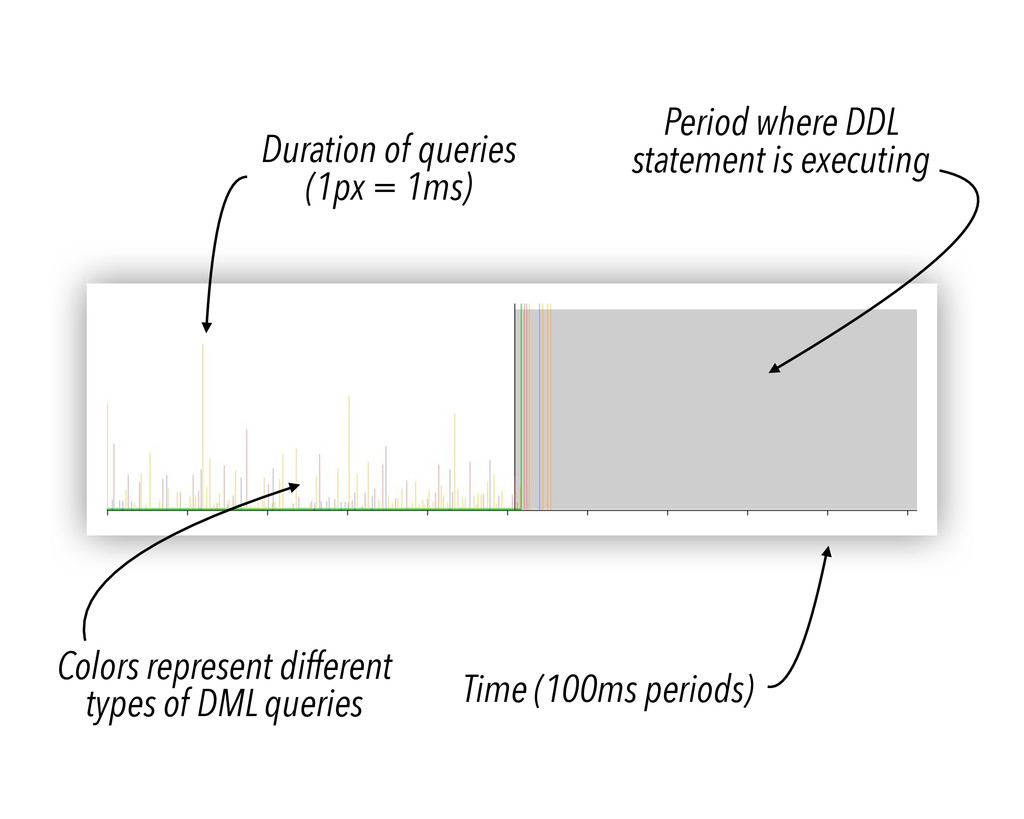
“Simulate load” by barraging the database with SELECT, UPDATE, INSERT, and DELETE queries. 3. Execute a DDL query to modify the table’s structure. 4. Record all start and end times for every query. 5. Plot the results.
non-nullable column Drop nullable column Drop non-nullable column Create index Rename index Drop index ! Make column nullable Make column non-nullable Set default on nullable column Set default on non-nullable column Modify type on nullable column Modify type on non-nullable column Modify type from int to text Add non-nullable foreign key Add nullable foreign key ! Non-blocking Semi-blocking Blocking Too fast to profile
non-nullable column Drop nullable column Drop non-nullable column Create index Rename index Drop index ! Make column nullable Make column non-nullable Set default on nullable column Set default on non-nullable column Modify type on nullable column Modify type on non-nullable column Modify type from int to text Add non-nullable foreign key Add nullable foreign key ! Non-blocking Semi-blocking Blocking Too fast to profile
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
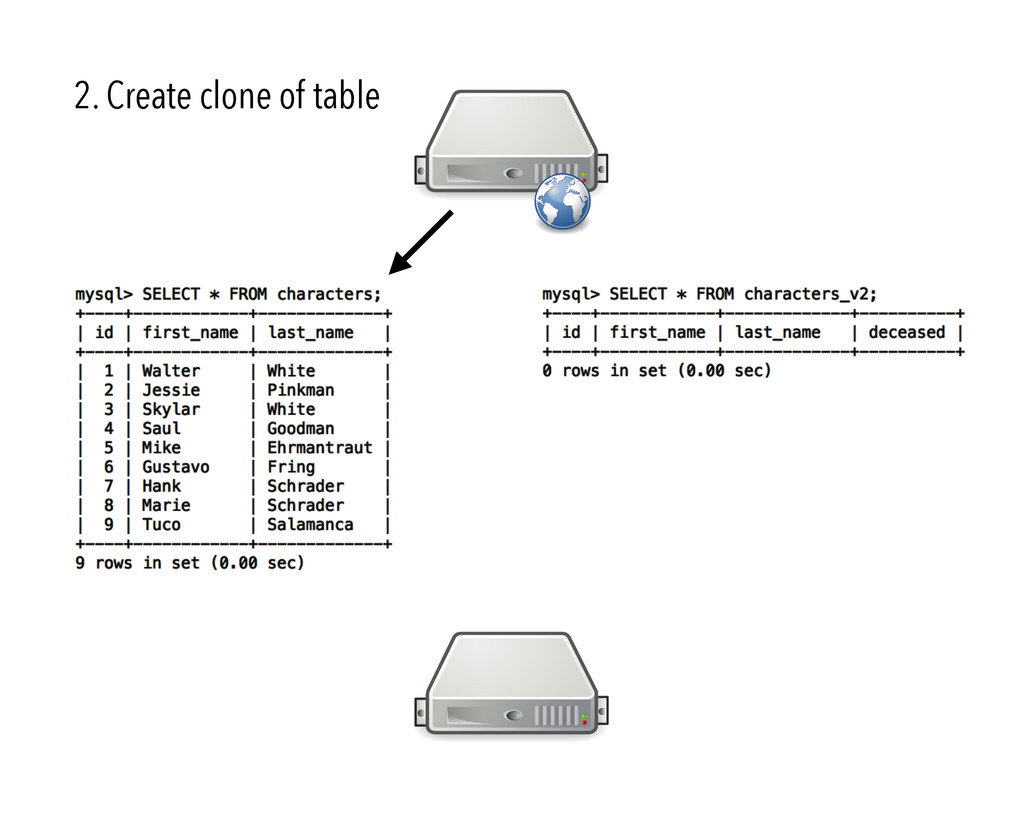{kind=link}
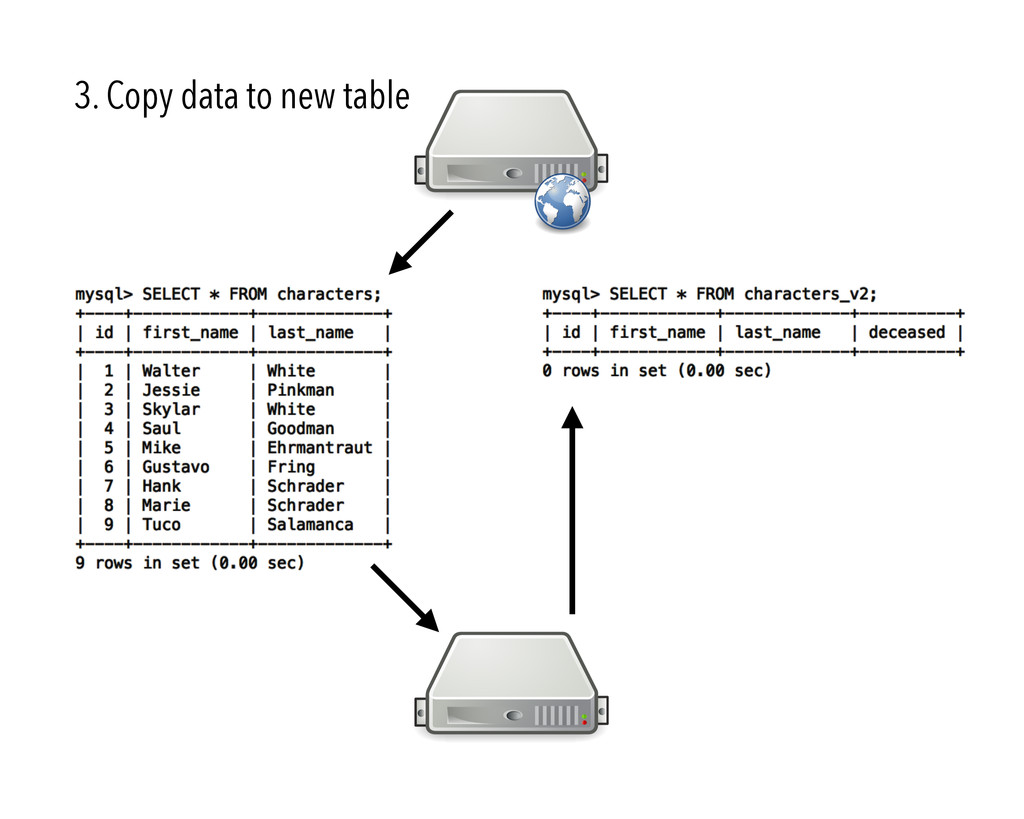{kind=link}
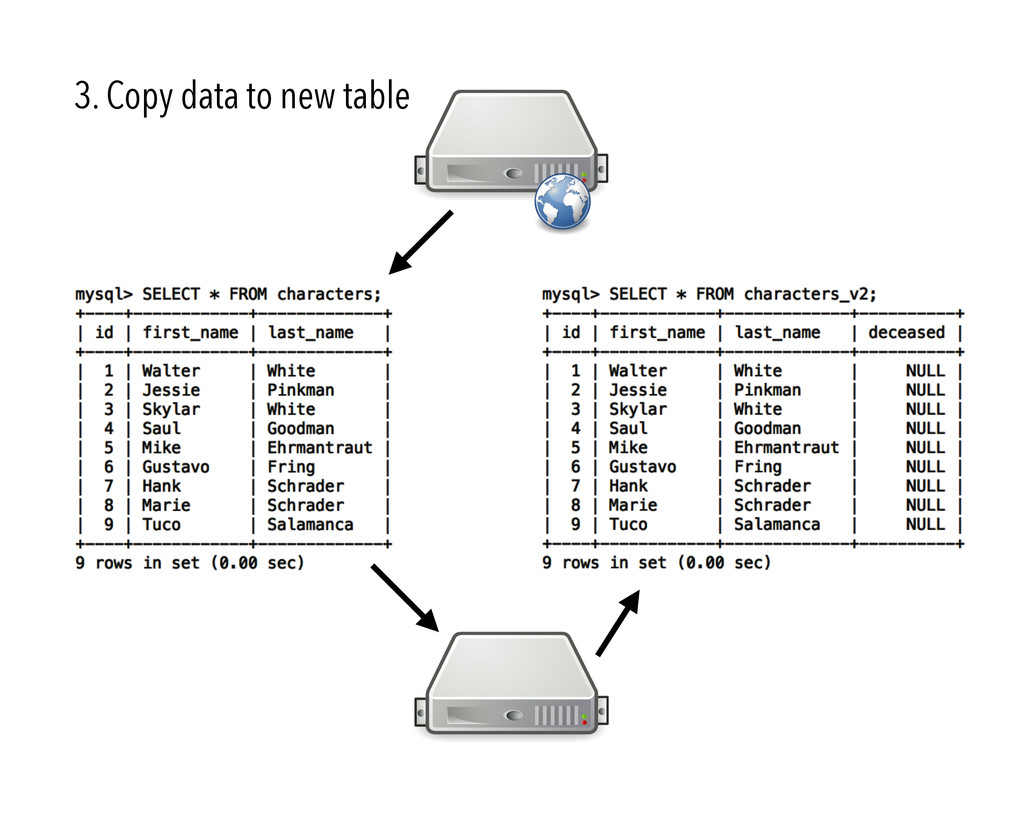{kind=link}
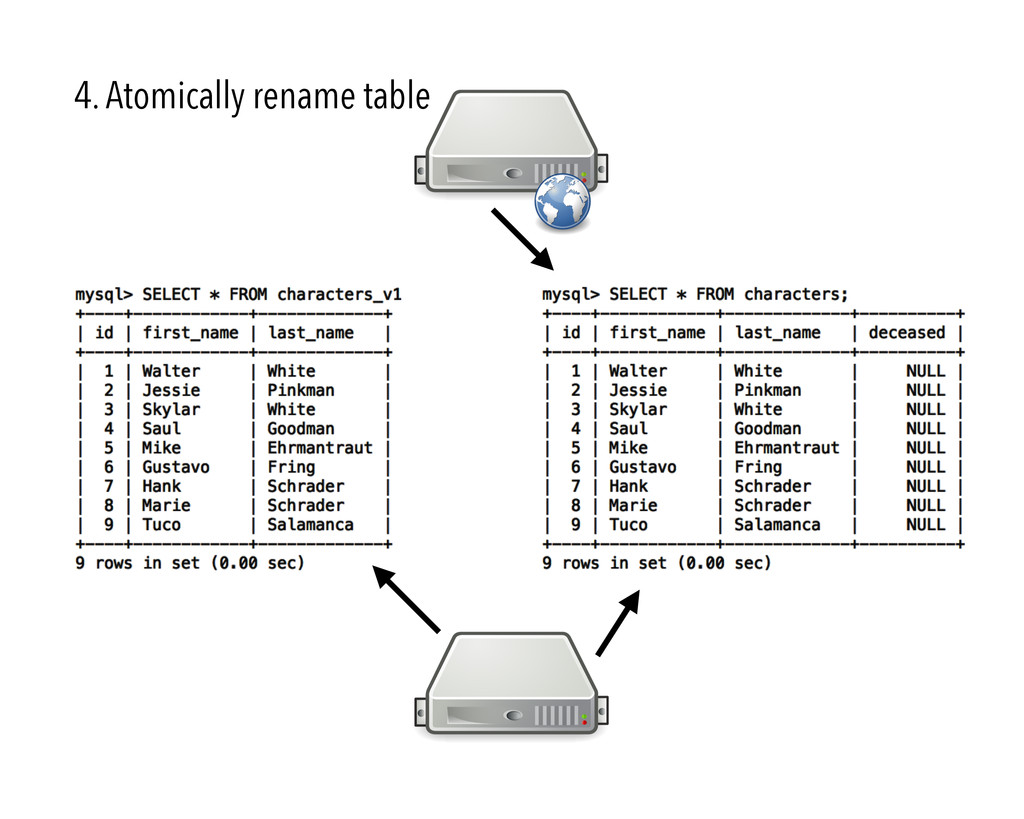{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}