This talk will begin by describing what makes it hard to use GPUs from containers. Then it will go into a bit of history of GPU support in Kubernetes. Then it will describe what you need to do as a user and as an administrator to use GPUs in Kubernetes. Finally, it will talk about what's missing and where we are going next.
https://www.youtube.com/watch?v=KplFFvj3XRk
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
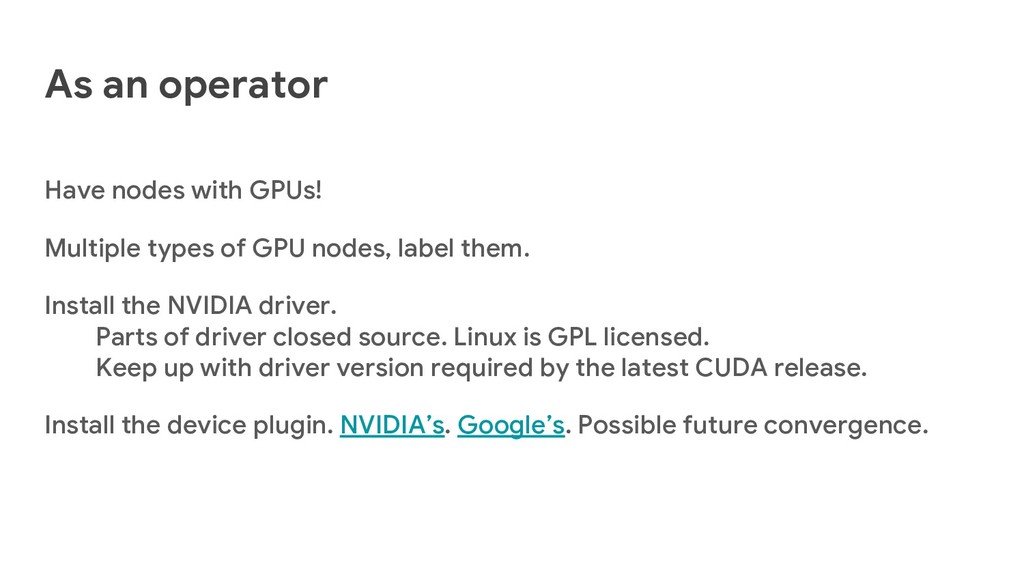{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}