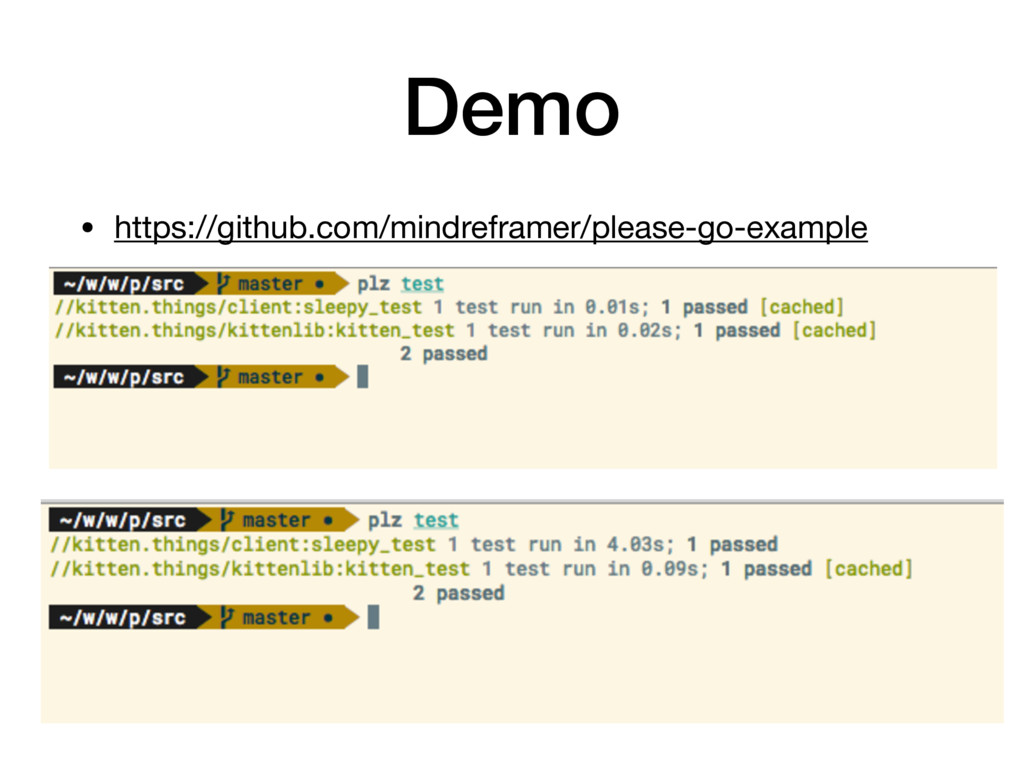
Introductory presentation about tooling around monorepos presented at the Elixir Meetup Berlin. Rough overview about Bazel build, Buck build, Pants and Please build.
the field • Usually it looks reasonable to stick with 1 service -> 1 repo approach • This is familiar and we know how to deal with basic requirements for simple projects
the road • It becomes hard / impossible to test applications end-2- end • Running the “application” locally is very hard, when you have to work against a pinned versions of other services
like herding cats • Impossible to tell whether something is used or not • So we just keep adding them, because we are afraid to break something… • Onboarding of new colleagues takes a lot of time • Many other non-trivial problems…
CI - pipelines • Sometimes you might have a diagram of the overall architecture that is updated occasionally and is just a MAP, but not the real thing (might be incorrect without noticing it)
Most of Google’s code is stored in a single unified source- code repository, and is accessible to all software engineers at Google • Exception: some high-value or security-critical pieces of code for which read access is locked down more tightly
contained a billion files, including over 9 million source code files containing a total of 2 billion lines of source code, with a history of 35 million commits and a change rate of 40 thousand commits per work day
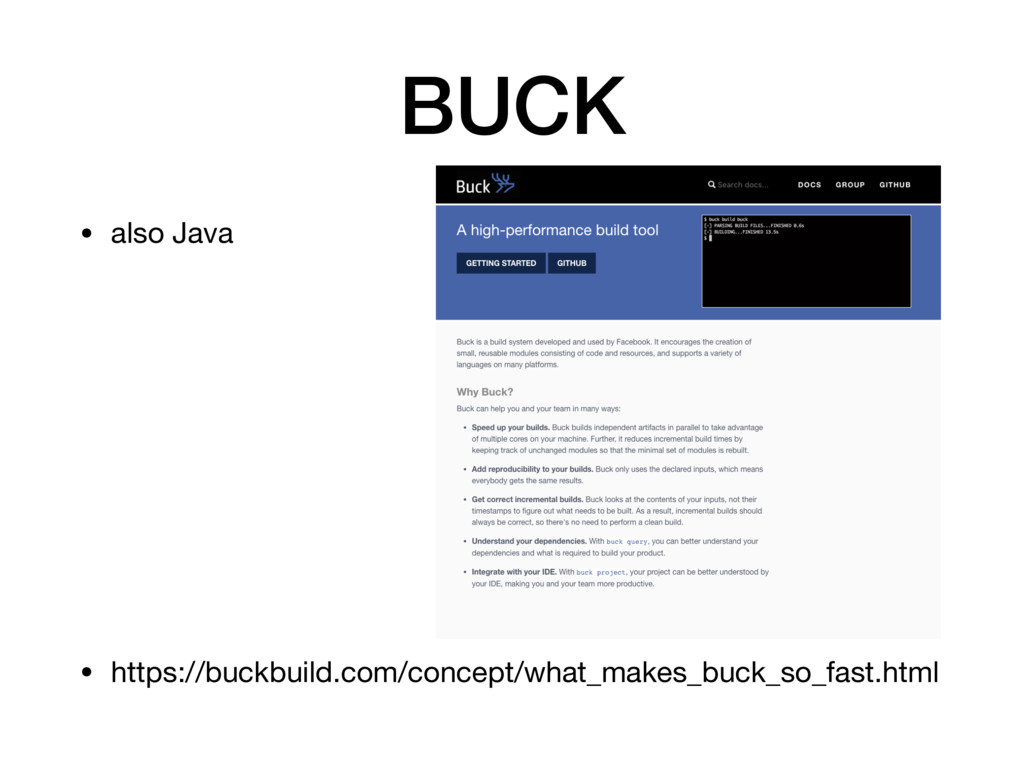
All four of these systems are quite closely related in the scheme of things, being inspired by (or in Bazel's case, a direct open sourcing of) Google's Blaze. • Several of us had worked at Google and used Blaze extensively there; we were excited about it being open sourced as Bazel but by then we were already using Please internally. It's a great system but we have slightly different goals, specifically we're aiming Please at being lighter weight and pushing the boundaries of what can be done within the BUILD language. Since Please is written in Go there's no runtime dependency on the JVM.
base wise • You probably won't find any hard blockers here, since it was proven to work for companies like Facebook / Twitter / Google • It is easier to contribute across teams because you work on the same physical codebase • Predictable fast builds, high team morale
quite some tooling to become productive • Some operations for daily work (GIT / DVCS) might be slower than with smaller codebases • Not much experience in real life if you did not work for the couple bigger companies using it
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}