Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kaggle-Vesuvius-Challenge-Ink-Detection-2nd-Sol...
Search
Wataru Takahara
November 26, 2023
Programming
3.6k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kaggle-Vesuvius-Challenge-Ink-Detection-2nd-Solution
2023/11/26(日):Kaggle Tokyo Meetup 2023 招待講演1「火山コンペ準優勝ソリューション」
#kaggle_tokyo
Wataru Takahara
November 26, 2023
More Decks by Wataru Takahara
See All by Wataru Takahara
【第4回】関東Kaggler会「Kaggleは執筆に役立つ」
mipypf
0
2.3k
Other Decks in Programming
See All in Programming
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
180
為什麼你並不需要ViewModel / No, you don't need a ViewModel
lovee
0
160
Foundation Models frameworkで画像分析
ryodeveloper
1
130
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
160
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
620
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
210
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
530
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
500
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
540
共通化で考えるべきは、実装より公開する型だった
codeegg
0
270
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
6.7k
Featured
See All Featured
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
WCS-LA-2024
lcolladotor
0
750
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Why Our Code Smells
bkeepers
PRO
340
58k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Transcript
火山コンペ準優勝ソリューション team RTX23090 @tattaka @mipypf @yukke42
2 Our Team
3 Our Team ▪今年頭に転職してコンピュータビジョンやってます ◦ 前職は映像制作会社のエンジニア ▪火山コンペ開始時点では金メダル1枚だったはずが気づけばGMリーチ ▪平日は一日一本モンスターエナジーを飲んでいます ▪ハンドルネーム tattaka
▪X(Twitter) @tattaka_sun
4 Our Team ▪ハンドルネーム ろん ▪X(Twitter) @mipypf ▪パパ社会人博士Kagglerです ◦ 専門は材料分野へのデータサイエンス活用(Materials
Informatics) ▪仕事では、データ分析したりコンサルしたりしています ▪追い込み時期はレッドブルとチルアウトを交互に飲んでいます
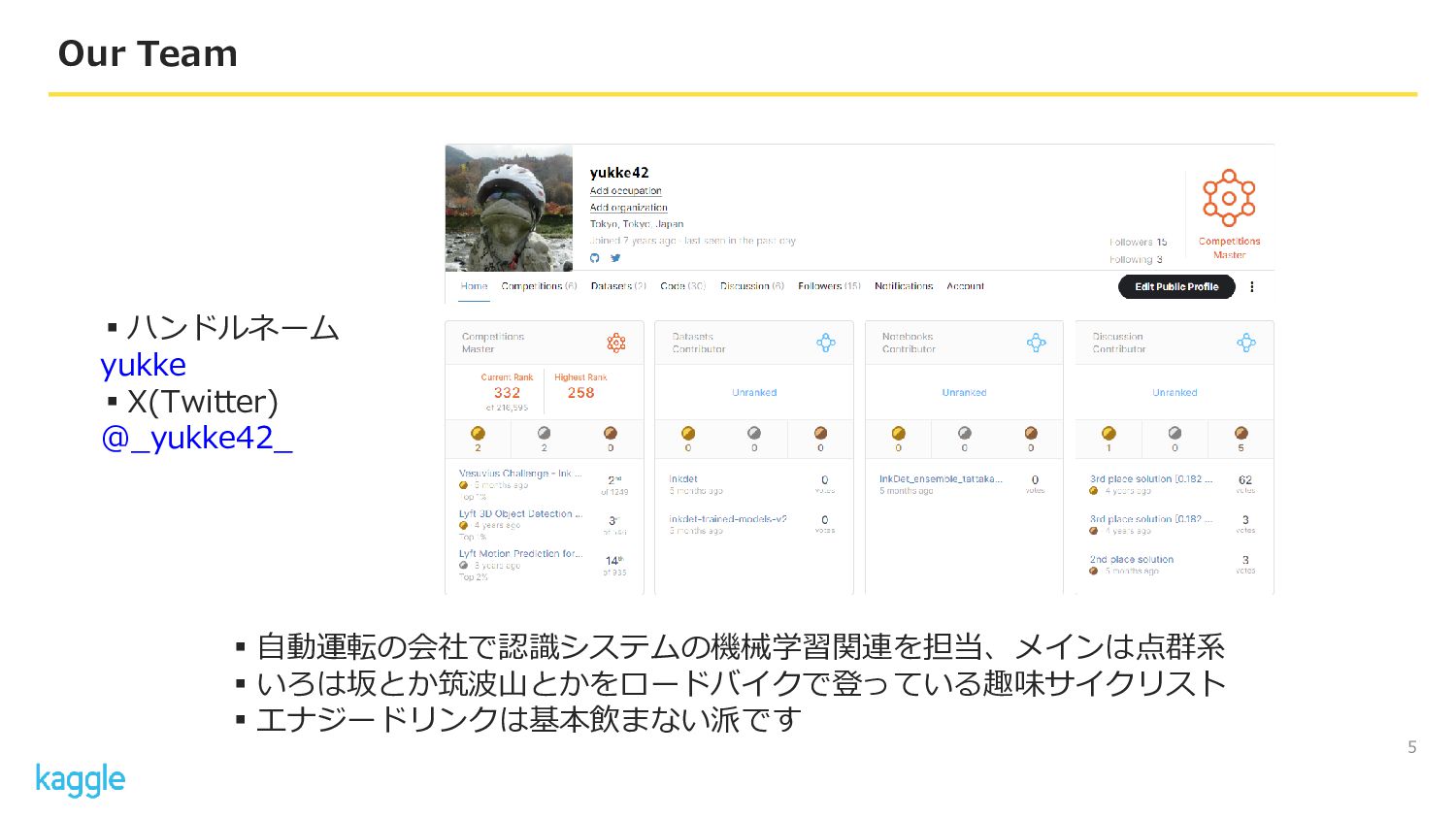
5 Our Team ▪自動運転の会社で認識システムの機械学習関連を担当、メインは点群系 ▪いろは坂とか筑波山とかをロードバイクで登っている趣味サイクリスト ▪エナジードリンクは基本飲まない派です ▪ハンドルネーム yukke ▪X(Twitter) @_yukke42_
1. コンペの概要 2. ソリューションの概要 3. tattaka & ron パート 4.
yukke パート 5. 最終sub、進め方パート (チームでの進め方、実験管理など) 6. 試行錯誤パート(Not works) 7. まとめ 6 Agenda
7 コンペの背景 • 約 2000 年前のVesuvius山の噴火により、埋もれた図書館 (ジュリアス・シーザーの義父の別荘の一部)にある炭化した パピルスの巻物の内容を読み解きたい • 炭化しており脆く開くことが
できないため、非破壊的に内部 の文章を読み解く必要がある https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection https://unsplash.com/photos/aerial-photography-of-brown-mountain-6v3b-b6ZOI4
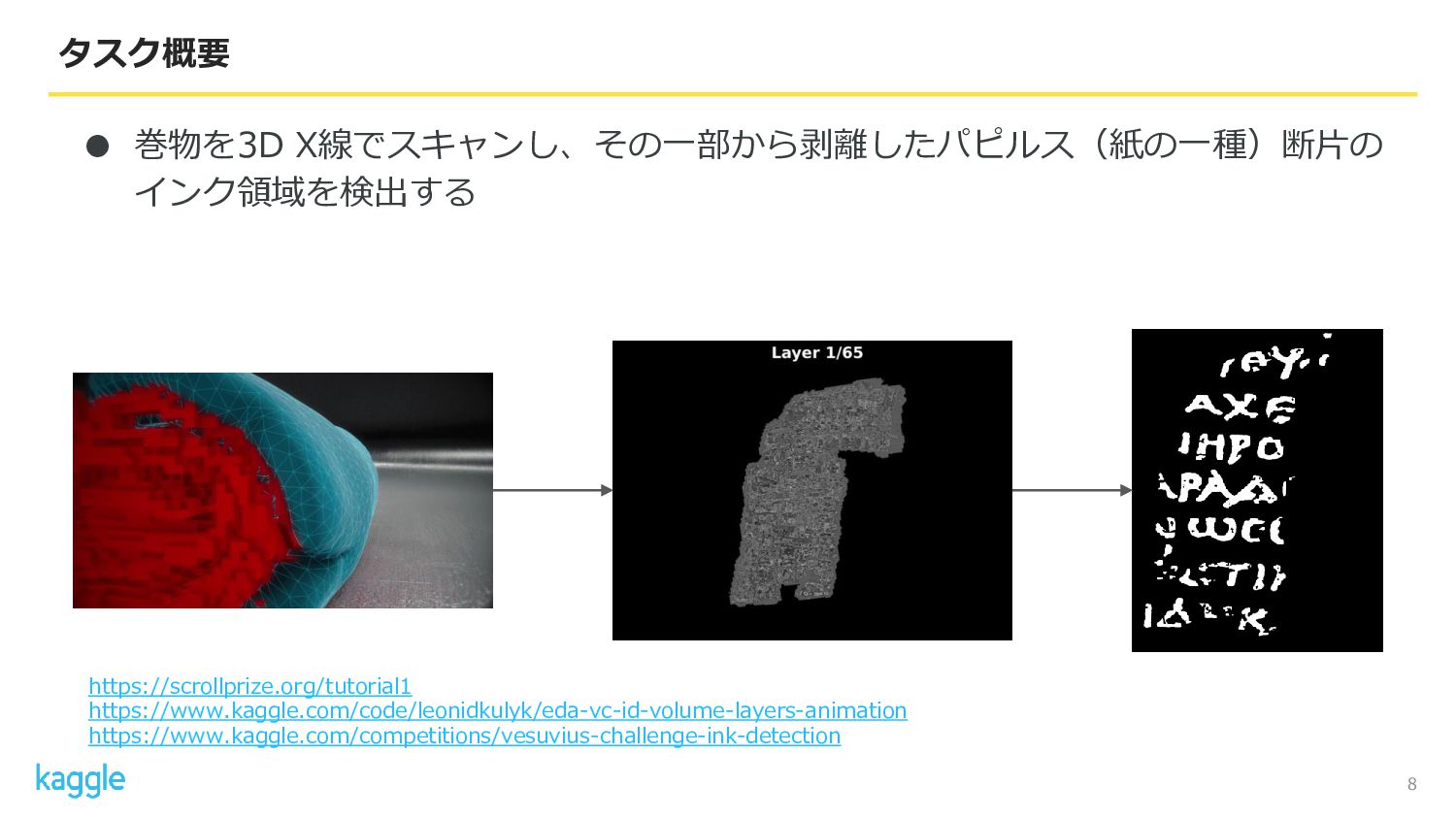
8 タスク概要 https://scrollprize.org/tutorial1 • 巻物を3D X線でスキャンし、その一部から剥離したパピルス(紙の一種)断片の インク領域を検出する https://www.kaggle.com/code/leonidkulyk/eda-vc-id-volume-layers-animation https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
9 https://www.kaggle.com/code/jpposma/vesuvius-challenge-ink-detection-tutorial 主催者のベースライン 1pixelごとのclassificationをしている
10 データ • train ◦ tiff形式の3Dスキャンデータ(65 slices x Height x
Width) ▪ 全て一辺5000~10000pix単位でかなり大きい ▪ 3種類の断片 ◦ 画像の中での巻物領域の白黒マスク画像 ◦ 教師データのバイナリマスク ◦ バイナリマスクを作成する時に使った赤外線画像 • test ◦ 3Dスキャンデータ ▪ 1種類の断片(publicとprivateで分割) ◦ 領域マスク画像 https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
11 コンペの条件など • 評価指標: 断片ごとのF0.5 scoreの平均 • コンペ開始時はDice(F1) scoreだったが 後にprecisionを重視するためにF0.5
scoreに変更 • 開催期間: 2023/03/15~2023/06/14 の約3ヶ月間 • Code Competition https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
12 Summary [tattaka & mipypf’s part] private scrore: 0.6824 (2nd
place相当) • 2.5D and 3D encoder + upsamplingを用いないdecoder • フル解像度をNNから出力するのではなく、1/32解像度を出力しupsampling する • 強い正則化 [yukke42’s part] private score 0.6478 (10th place相当) • 3D encoder and 2D encoder • 1/2 or 1/4解像度を出力し、upsampling • simpleなdecoder 最終的にEnsembleしようと思ったがうまくいかず......
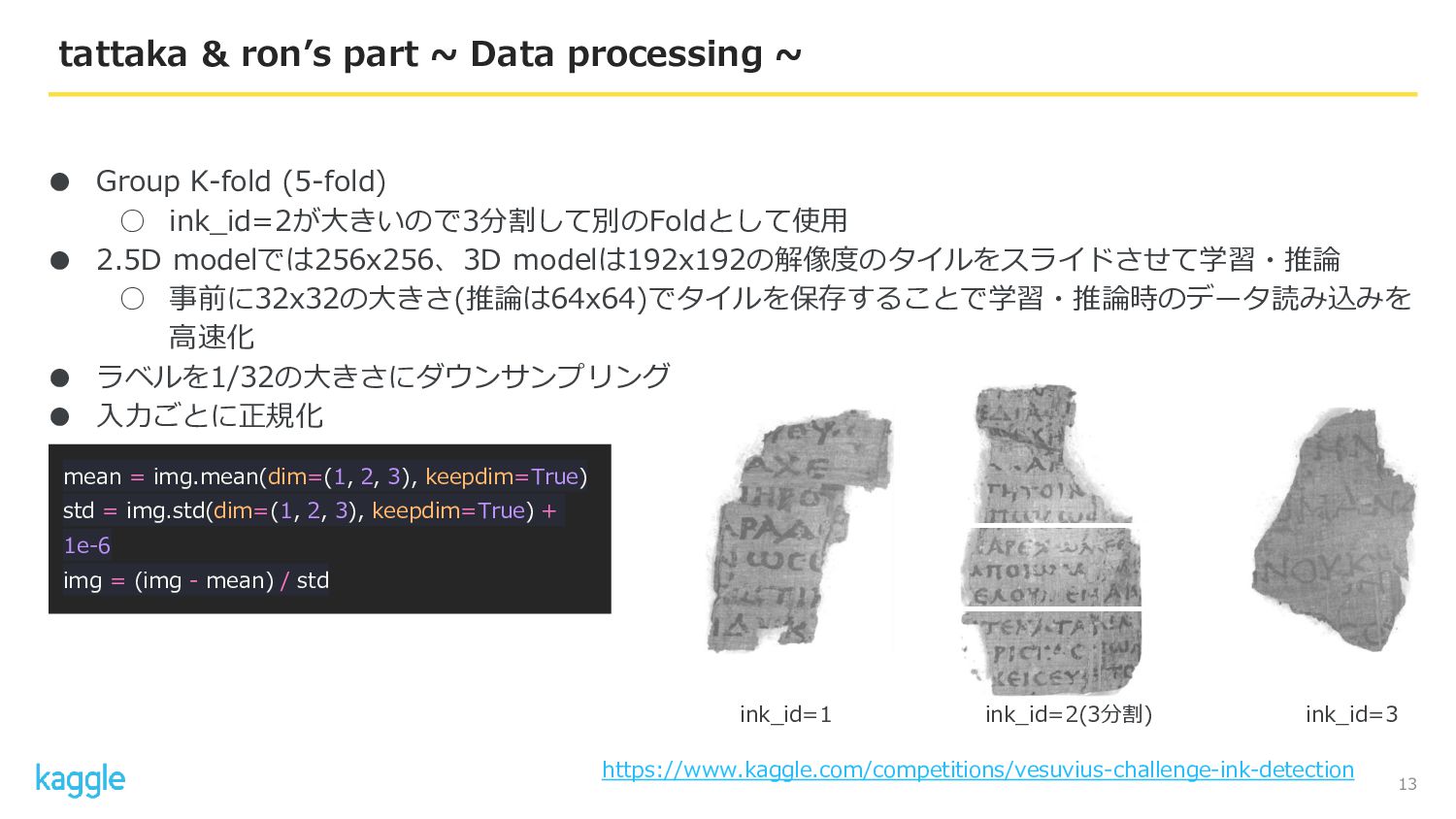
• Group K-fold (5-fold) ◦ ink_id=2が大きいので3分割して別のFoldとして使用 • 2.5D modelでは256x256、3D modelは192x192の解像度のタイルをスライドさせて学習・推論
◦ 事前に32x32の大きさ(推論は64x64)でタイルを保存することで学習・推論時のデータ読み込みを 高速化 • ラベルを1/32の大きさにダウンサンプリング • 入力ごとに正規化 13 tattaka & ron’s part ~ Data processing ~ mean = img.mean(dim=(1, 2, 3), keepdim=True) std = img.std(dim=(1, 2, 3), keepdim=True) + 1e-6 img = (img - mean) / std ink_id=1 ink_id=2(3分割) ink_id=3 https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
14 tattaka & ron’s part ~ 各foldの概要 ~ fold0 fold1
fold2 fold3 fold4 train valid ink_id=1 ink_id=1 ink_id=2 (all part) ink_id=2(2b,2c part) ink_id=2(2a part) ink_id=3 ink_id=3 ink_id=1 ink_id=2 (all part) ink_id=2(2b part) ink_id=3 ink_id=1 ink_id=3 ink_id=2 (2a,2c part) ink_id=2(2c part) ink_id=1 ink_id=3 ink_id=2 (2a,2b part) https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
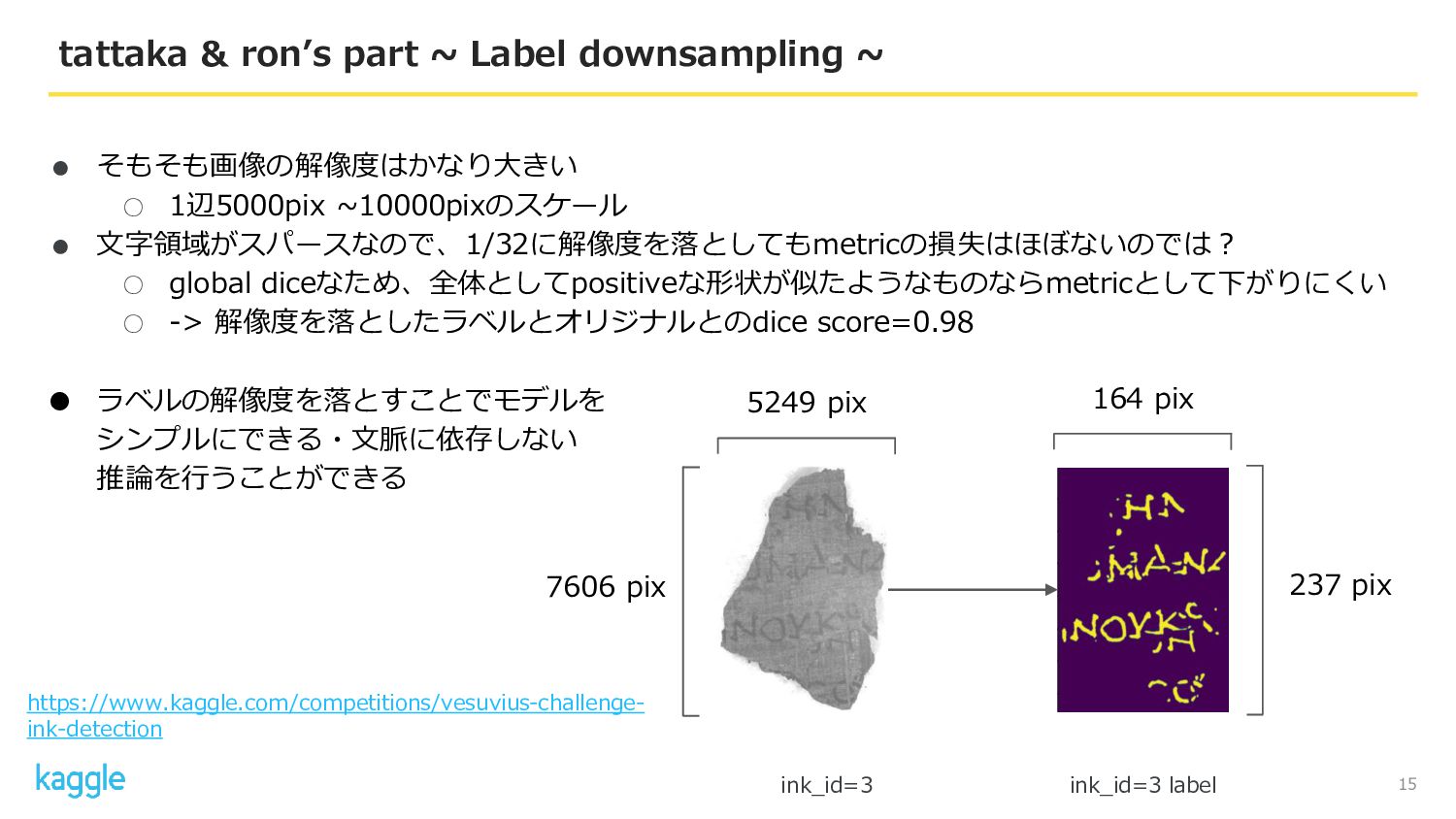
• そもそも画像の解像度はかなり大きい ◦ 1辺5000pix ~10000pixのスケール • 文字領域がスパースなので、1/32に解像度を落としてもmetricの損失はほぼないのでは? ◦ global diceなため、全体としてpositiveな形状が似たようなものならmetricとして下がりにくい
◦ -> 解像度を落としたラベルとオリジナルとのdice score=0.98 • ラベルの解像度を落とすことでモデルを シンプルにできる・文脈に依存しない 推論を行うことができる 15 tattaka & ron’s part ~ Label downsampling ~ ink_id=3 ink_id=3 label 5249 pix 7606 pix 164 pix 237 pix https://www.kaggle.com/competitions/vesuvius-challenge- ink-detection
• images(batch_size x channel x group x height x width)
-> 2dcnn backbone -> pointwise conv2d neck -> 3dcnn(ResBlockCSN like, 3 or 6 blocks) -> avg + max pooling(z axis) -> pointwise conv2d ◦ 2dcnn backbone: ▪ resnetrs50 ▪ convnext_tiny ▪ swinv2_tiny ▪ resnext50 ◦ 入力としては中央の35または27スライスを用いるが、それぞれ5ch x 7, 3ch x 9に分割してbackboneに入力する ◦ z方向をいくつかのグループに分けて、グループごとに2DCNNを適用した結果を3DCNNで処理する • images(batch_size x 1 x layers x height x width) -> 3dcnn backbone -> max pooling(z axis) -> pointwise conv2d ◦ 3DCNN backbone: ▪ resnet50-irCSN(slices: 32) ▪ resnet152-irCSN(slices: 24) • loss: bce + global fbeta loss(サンプルごとではなくbatch内でfbeta scoreを計算) 16 tattaka & ron’s part ~ Model details ~
17 tattaka & ron’s part ~ Model details (2.5D model)
~ 2D CNN (ResNet etc...) + 1x1 conv 3D CNN avg+max pooling 1x1 conv bilinear interpolation x32 learnable function un-learnable function tensor https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
• データの種類が少ない(3 fragment)ので過学習を防ぐために 多様な正則化を使用 • fp16 mixed precision training •
Exponential Moving Average (decay=0.99) • label smoothing (smooth = 0.1) • stochastic depth (rate=0.2) • cutmix + mixup + manifold mixup • heavy augmentation ◦ cutout ▪ 1/32解像度に対応するように変更 ◦ channel shuffle ▪ 入力の各グループ内でshuffle ◦ 0.5の確率でz方向に最大+-2ずらす ◦ other transforms 18 tattaka & ron’s part ~ Training methods ~ training code: https://github.com/mipypf/Vesuvius-Challenge/tree/winner_call/tattaka_ron albu.Compose( [ albu.Flip(p=0.5), albu.RandomRotate90(p=0.9), albu.ShiftScaleRotate( shift_limit=0.0625, scale_limit=0.2, rotate_limit=15, p=0.9, ), albu.OneOf( [ albu.ElasticTransform(p=0.3), albu.GaussianBlur(p=0.3), albu.GaussNoise(p=0.3), albu.OpticalDistortion(p=0.3), albu.GridDistortion(p=0.1), albu.PiecewiseAffine(p=0.3), # IAAPiecewiseAffine ], p=0.9, ), albu.RandomBrightnessContrast( brightness_limit=0.3, contrast_limit=0.3, p=0.3 ), ToTensorV2(), ] ) https://arxiv.org/abs/1905.04899v2
• fp16 inference • stride=32 (256x256をoverlapさせながら推論) • fold0(train_ink_id = (2a,2b,2c,3),
val_ink_id=1), fold1(train_ink_id = (1,2b,2c,3), val_ink_id=2a)の重みを使用 • TTA ◦ h/v flip ※rotationのTTAは挙動が不安定だったため不採用 ◦ strideごとに適用するTTAを変えることで高速化 • @philippsinger proposed percentile threshold ◦ 常に同じ量の陽性を予測するため、モデルの性能に依存せず、 Ground Truthの陽性/陰性比に依存 ◦ マスクの外側の領域を除くすべてのピクセルに 対して計算される ◦ 0.9、0.93を使用 ◦ プライベートでは0.90の方が良いスコアになると 予想していたが、最終的には0.93の方が良かった(後述) 19 tattaka & ron’s part ~ Inference methods ~ inference code: https://www.kaggle.com/code/mipypf/ink-segmentation-2-5d- 3dcnn-resnet3dcsn-fp16fold01?scriptVersionId=132226669 def func_percentile(y_true: np.ndarray, y_pred: np.ndarray, t: List[float]): score = fbeta_score( y_true, (y_pred > np.quantile(y_pred, np.clip(t[0], 0, 1))).astype(int), beta=0.5, ) return -score def find_threshold_percentile(y_true: np.ndarray, y_pred: np.ndarray): x0 = [0.5] threshold = minimize( partial( func_percentile, y_true, y_pred, ), x0, method="nelder-mead", ).x[0] return np.clip(threshold, 0, 1)
• ink_id=2を縦に分割した Group 4-folds • サイズが大きいデータなので patch_size=224 stride=112 で小さいデータに分割 •
65スライスあるうち 中間の16スライス使うことを実験で決めた ◦ 入力データの各チャンネルを確認してもインク領域との相関は全くわからない … 20 yukke’s part ~ Data Processing ~ ink_id=1 ink_id=2 ink_id=3 https://www.kaggle.com/code/leonidkulyk/eda-vc-id-volume-layers-animation https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
• UNet-based 3D Encoder / 2D Decoder のモデル ◦ Encoderからの3D特徴量に対してチャンネル方向のmax-poolingで2Dの特徴量に変換
◦ 2パターン ▪ Encoder: 3DResNet, Decoder: CNN ▪ Encoder: MViTv2-s, Decoder: Linear • Training Method ◦ Automatic Mixed Precision (fp16) と torch.compile (PyTorch 2.0) でなるべく学習を高速化 ◦ 一人のときはシンプルなData Augmentationの組み合わせ、チームマージ後は tattaka & ron のs 正則化多めのものを参考に取り入れる ◦ 学習済みモデルのほうが性能が良かったのでそれが公開されているモデルを選択 • 実装 ◦ segmentation_models_pytorch を import する形で最初は進め、モデルを追加していく ◦ 今回使ったのがAction Recognitionのような動画分類向けのモデルなので、中間特徴量をとってこ れるように実装をいじる 21 yukke’s part ~ Model & Training Method ~ training code: https://github.com/yukke42/kaggle-vesuvius-challenge-ink-detection
• 学習時とパッチサイズとストライドの数値を変更 ◦ パッチサイズ: train=224, inference=336 ◦ ストライド: train=112, inference=75
◦ ストライドは小さいほうが良かったが、推論時間とのトレードオフなので良さそうな値に決めた • CNN-basedのモデルのときは、推論結果の縁付近は使わない • percentile thresholdを採用 22 yukke’s part ~ Inference Method ~ 内側の領域のみ 使う https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
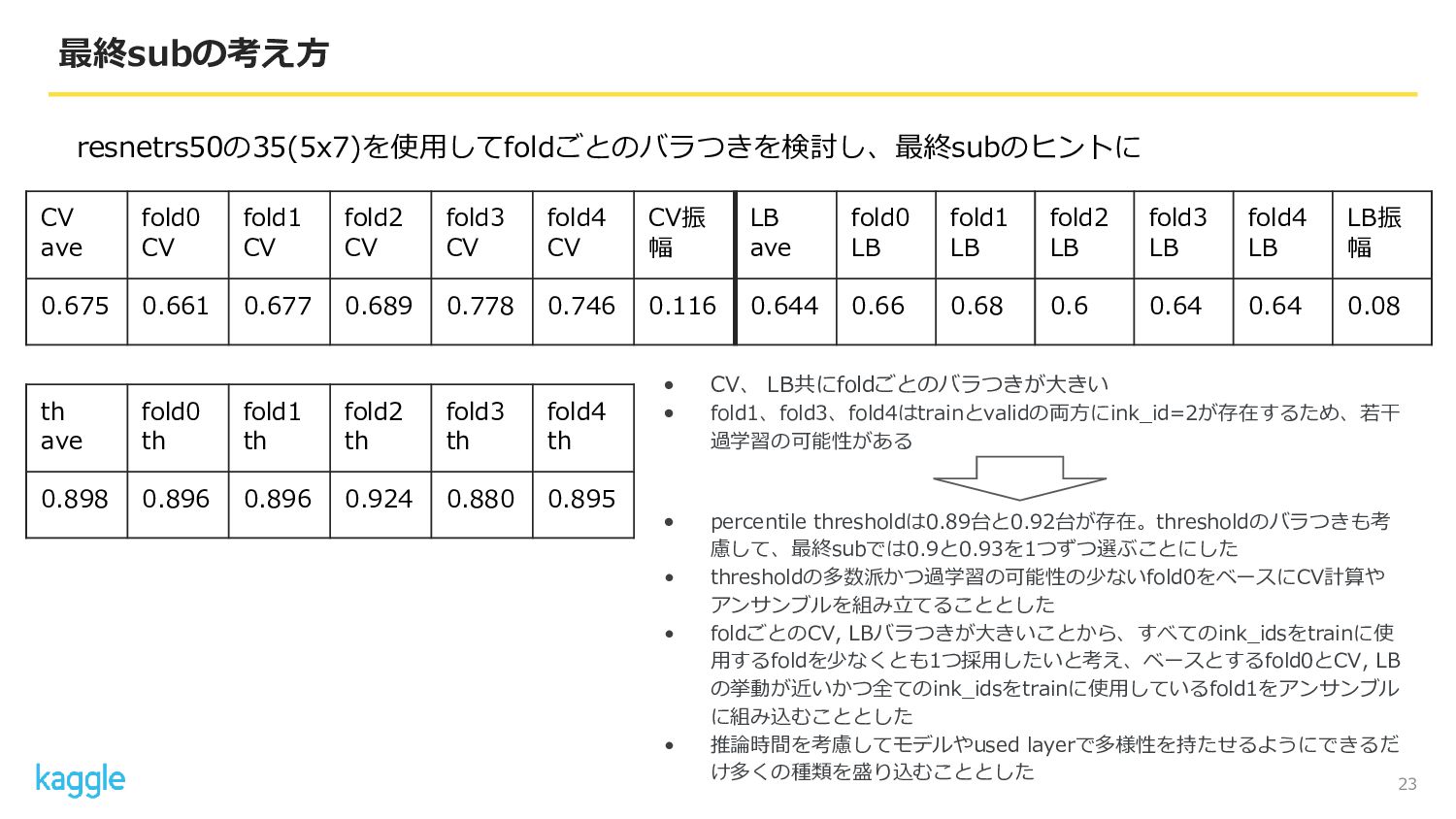
23 最終subの考え方 CV ave fold0 CV fold1 CV fold2 CV
fold3 CV fold4 CV CV振 幅 LB ave fold0 LB fold1 LB fold2 LB fold3 LB fold4 LB LB振 幅 0.675 0.661 0.677 0.689 0.778 0.746 0.116 0.644 0.66 0.68 0.6 0.64 0.64 0.08 th ave fold0 th fold1 th fold2 th fold3 th fold4 th 0.898 0.896 0.896 0.924 0.880 0.895 • CV、 LB共にfoldごとのバラつきが大きい • fold1、fold3、fold4はtrainとvalidの両方にink_id=2が存在するため、若干 過学習の可能性がある • percentile thresholdは0.89台と0.92台が存在。thresholdのバラつきも考 慮して、最終subでは0.9と0.93を1つずつ選ぶことにした • thresholdの多数派かつ過学習の可能性の少ないfold0をベースにCV計算や アンサンブルを組み立てることとした • foldごとのCV, LBバラつきが大きいことから、すべてのink_idsをtrainに使 用するfoldを少なくとも1つ採用したいと考え、ベースとするfold0とCV, LB の挙動が近いかつ全てのink_idsをtrainに使用しているfold1をアンサンブル に組み込むこととした • 推論時間を考慮してモデルやused layerで多様性を持たせるようにできるだ け多くの種類を盛り込むこととした resnetrs50の35(5x7)を使用してfoldごとのバラつきを検討し、最終subのヒントに
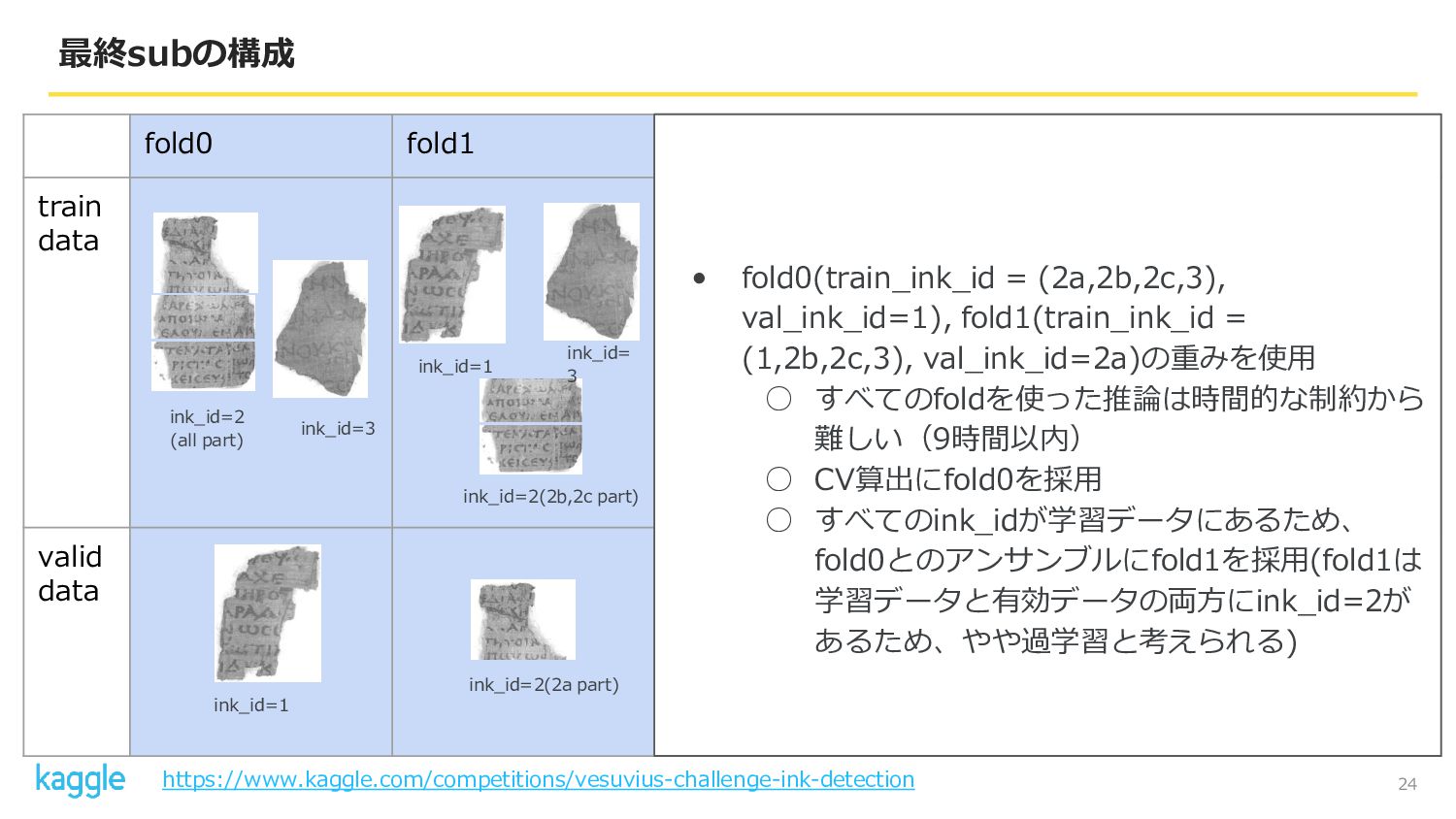
24 最終subの構成 fold0 fold1 fold2 fold3 fold4 train data valid
data ink_id=1 ink_id=1 ink_id=2 (all part) ink_id=3 ink_id= 3 ink_id= 1 ink_id= 2(all part) ink_id=2(2 part) ink_id= 1 ink_id= 3 ink_id=2 (1,3 part) ink_id=2(3 part) ink_id= 1 ink_id= 3 ink_id=2 (1,2 part) • fold0(train_ink_id = (2a,2b,2c,3), val_ink_id=1), fold1(train_ink_id = (1,2b,2c,3), val_ink_id=2a)の重みを使用 ◦ すべてのfoldを使った推論は時間的な制約から 難しい(9時間以内) ◦ CV算出にfold0を採用 ◦ すべてのink_idが学習データにあるため、 fold0とのアンサンブルにfold1を採用(fold1は 学習データと有効データの両方にink_id=2が あるため、やや過学習と考えられる) ink_id=2(2b,2c part) ink_id=2(2a part) https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
25 最終subの構成 fold0 fold1 fold2 fold3 fold4 train data valid
data ink_id= 1 ink_id=2(2,3 part) ink_id=2(1 part) ink_id= 3 ink_id= 3 ink_id= 1 ink_id= 2(all part) ink_id=2(2 part) ink_id= 1 ink_id= 3 ink_id=2 (1,3 part) ink_id=2(3 part) ink_id= 1 ink_id= 3 ink_id=2 (1,2 part) backbone used layers CV find_thresh old_percenti leの値 Public LB resnetrs50 35(5x7) 0.6616 0.8962 0.66 resnetrs50 27(3x9) 0.6473 0.8941 - convnext_tiny 35(5x7) 0.648 0.8995 - convnext_tiny 27(3x9) 0.6609 0.8945 - swinv2_tiny 35(5x7) 0.6595 0.8948 - swinv2_tiny 27(3x9) 0.6494 0.9015 - resnext50 27(3x9) 0.6721 0.8864 - resnet50-irCSN (layers: 32) 32 0.6524 0.8853 - resnet152-irCSN (layers: 24) 24 0.6475 0.9095 - 各モデルごとのCV と平均アンサンブ ルとして混ぜた際 のCVを見ながら最 終subに盛り込む モデルを選定 ink_id=1 ink_id=2 (all part) ink_id=3 https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
26 最終subの構成 fold1 fold1 fold2 fold3 fold4 train data valid
data ink_id= 1 ink_id=2(2,3 part) ink_id=2(1 part) ink_id= 3 ink_id= 3 ink_id= 1 ink_id= 2(all part) ink_id=2(2 part) ink_id= 1 ink_id= 3 ink_id=2 (1,3 part) ink_id=2(3 part) ink_id= 1 ink_id= 3 ink_id=2 (1,2 part) backbone used layers CV find_thresh old_percent ileの値 Public LB resnetrs50 35(5x7) 0.6767 0.8964 0.68 resnetrs50 27(3x9) 0.7227 0.897 - convnext_tiny 35(5x7) 0.7349 0.9013 - convnext_tiny 27(3x9) 0.7103 0.8946 - swinv2_tiny 35(5x7) 0.7202 0.8997 - swinv2_tiny 27(3x9) 0.7385 0.9022 - resnext50 27(3x9) 0.6745 0.8867 - resnet50-irCSN (layers: 32) 32 0.7004 0.915 - resnet152-irCSN (layers: 24) 24 0.723 0.892 - ink_id=1 ink_id=3 ink_id=2(2b,2c part) ink_id=2(2a part) 各モデルごとのCV と平均アンサンブ ルとして混ぜた際 のCVを見ながら最 終subに盛り込む モデルを選定 https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
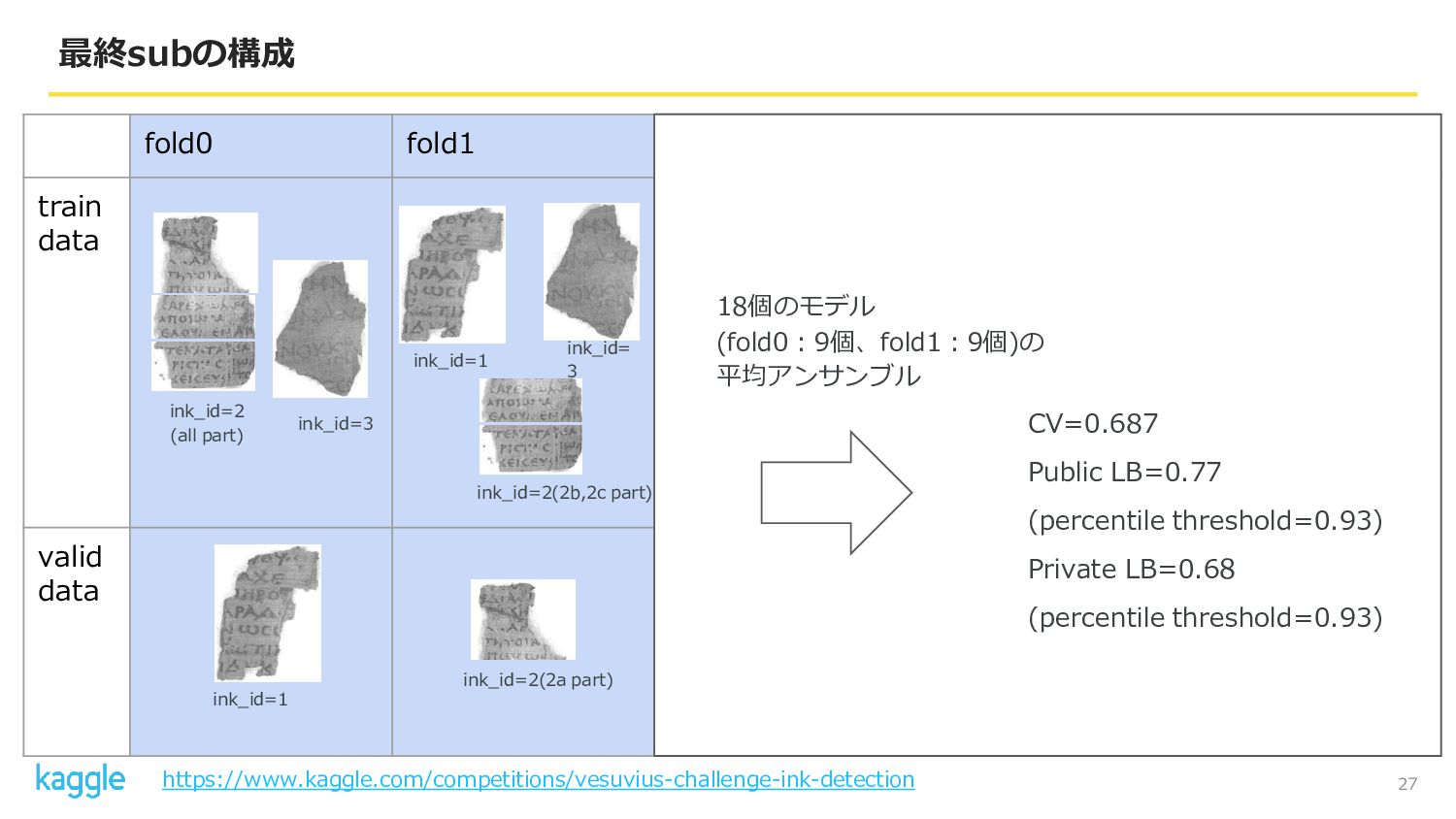
27 最終subの構成 fold0 fold1 fold2 fold3 fold4 train data valid
data ink_id=1 ink_id=1 ink_id=2 (all part) ink_id=3 ink_id= 3 ink_id= 1 ink_id= 2(all part) ink_id=2(2 part) ink_id= 1 ink_id= 3 ink_id=2 (1,3 part) ink_id=2(3 part) ink_id= 1 ink_id= 3 ink_id=2 (1,2 part) ink_id=2(2b,2c part) ink_id=2(2a part) CV=0.687 Public LB=0.77 (percentile threshold=0.93) Private LB=0.68 (percentile threshold=0.93) 18個のモデル (fold0:9個、fold1:9個)の 平均アンサンブル https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
28 コミュニケーション 基本はSlackでコミュニケーションをとり、週1でWebミーティングをして進めた https://scrollprize.org/tutorial1
29 実験管理 スプレッドシートを使用して、チームで実験管理を可視化してコンペを進めていった 例:fold0でCVや推論時間、Kaggle Notebookのメモリにのるかを確認して18modelが限界(20modelでは out of memory)だった→fold0のmodel9個、fold1のmodel9個の18個のモデルを推論に使用
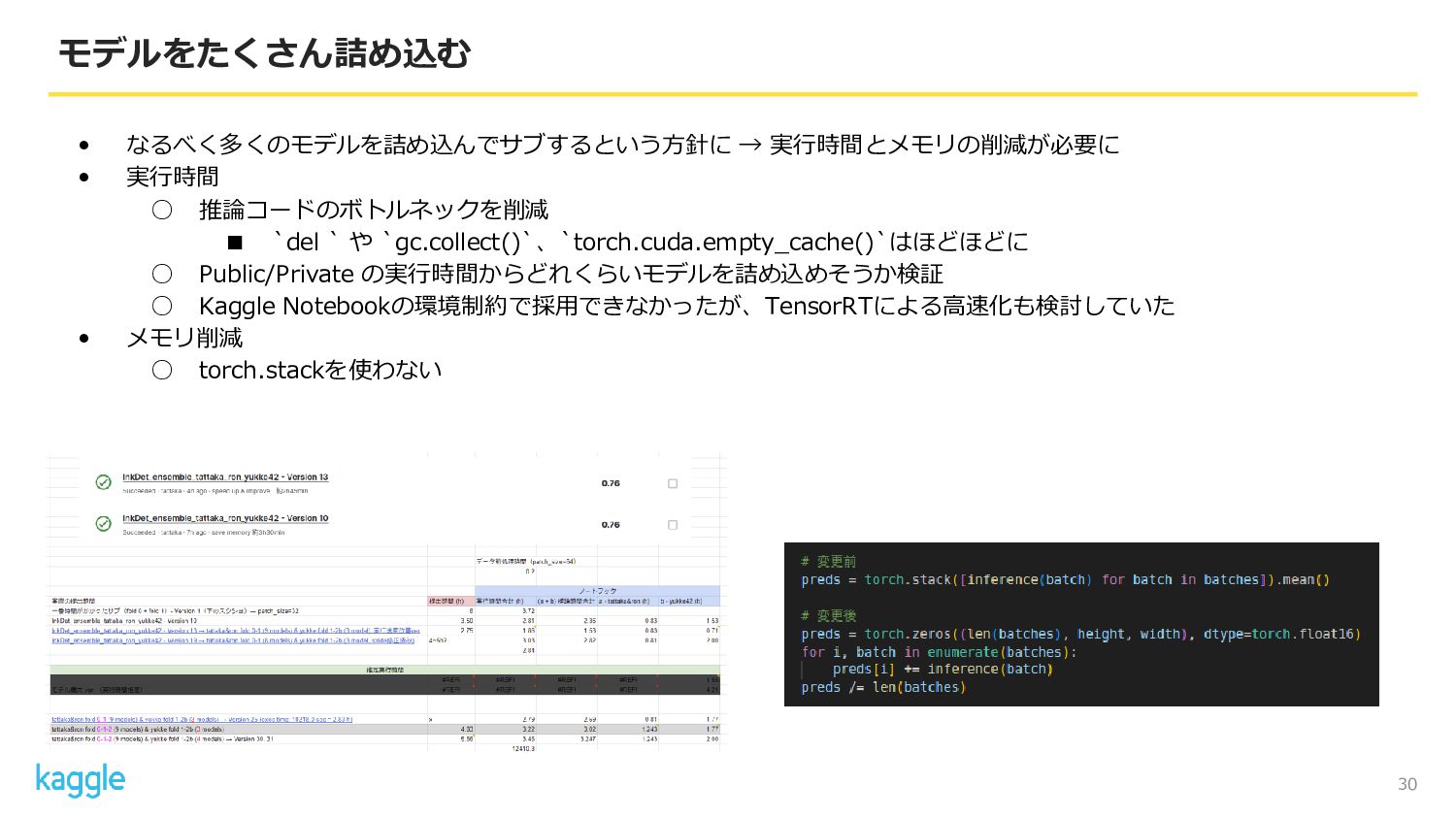
30 モデルをたくさん詰め込む • なるべく多くのモデルを詰め込んでサブするという方針に → 実行時間とメモリの削減が必要に • 実行時間 ◦ 推論コードのボトルネックを削減
▪ `del ` や `gc.collect()`、`torch.cuda.empty_cache()`はほどほどに ◦ Public/Private の実行時間からどれくらいモデルを詰め込めそうか検証 ◦ Kaggle Notebookの環境制約で採用できなかったが、TensorRTによる高速化も検討していた • メモリ削減 ◦ torch.stackを使わない
31 情報共有 W&B( https://www.wandb.jp/ )も活用して、チームでモデルの挙動を共有し つつ実験方針を考えていった
32 Not work • Other normalization method • Other backbone
(EfficientNet, maxvit, repvgg, etc…) • Other optimizer (SGD, Lion) • Layer sampling • Classification Head • Binary classification model before our method • Large crop size • Noisy Labels の手法 • Stochastic Weight Averaging
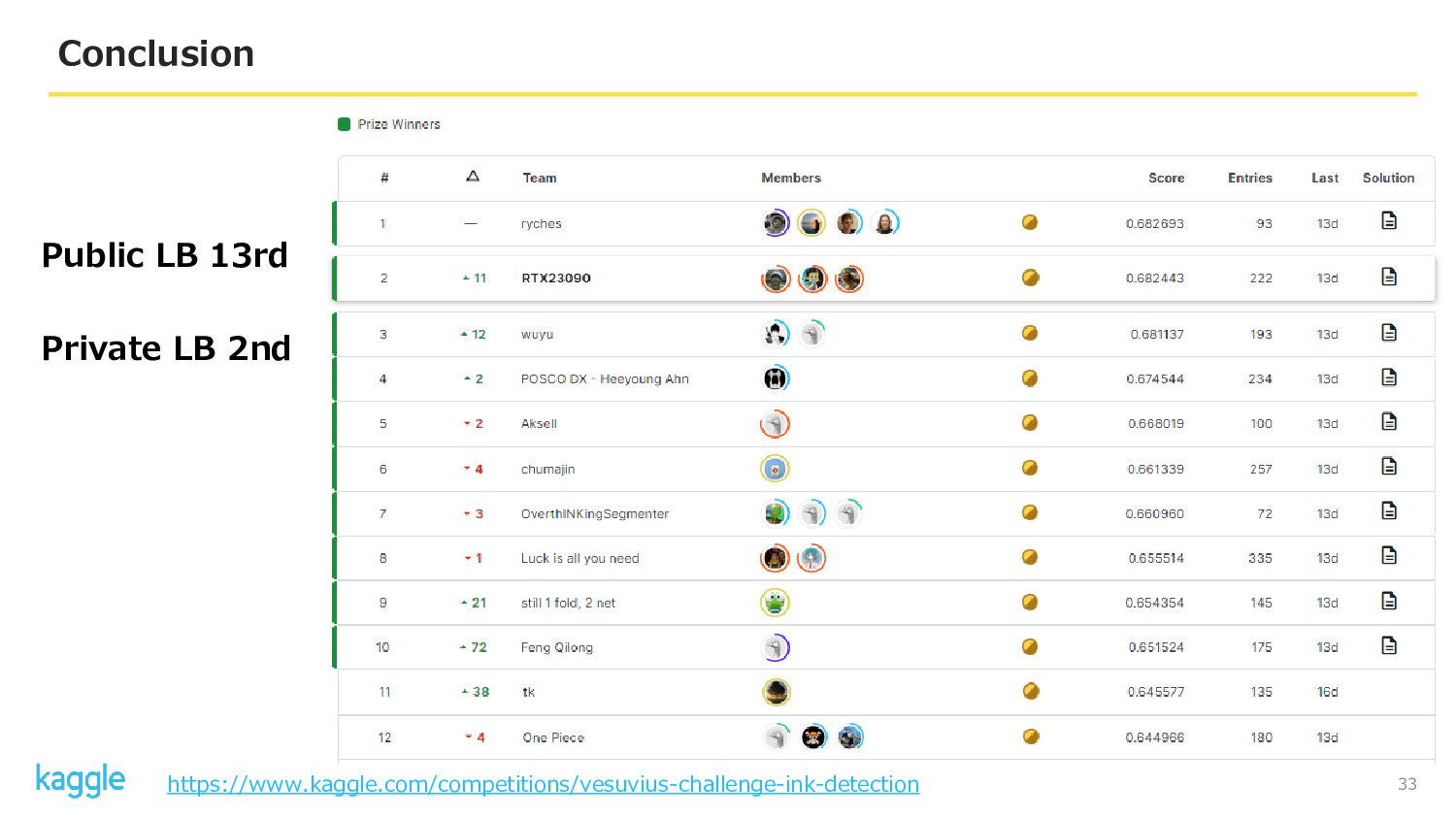
33 Conclusion Public LB 13rd Private LB 2nd https://www.kaggle.com/competitions/vesuvius-challenge-ink-detection
34 余談 • なぜtest画像が90度回転していたかは謎 ◦ 自分たちは学習中にrot90のaugmentationを入れることで対処した (推論に入れるには確信が持てなかった) ▪ 上位陣は学習中にrot90のaugmentationをするか 推論時に回転させるかどちらかはやっていた模様
• test画像がリークしていたが、幸いにも誰も悪用していなかった • ホストが出したpreprint(https://arxiv.org/abs/2304.02084 )に どうデータセットを作ったかが詳細に記載されていて興味深かった
35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![12 Summary [tattaka & mipypf’s part] private scrore: 0.6824 (2nd](https://files.speakerdeck.com/presentations/20cf03c2a69c4ca384ce1a7d659dd586/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}