[ASPLOS '19] [2] Spectre Attacks: Exploiting Speculative Execution [arXiv Jan 2018] [3] Secure program execution via dynamic information flow tracking [ASPLOS ‘04] [4] Mobilizing the Micro-Ops: Exploiting Context Sensitive Decoding for Security and Energy Efficiency [ISCA ‘18] 3
Side-Channel Attack [USENIX Security Symposium ‘14] [6] A Systematic Evaluation of Transient Execution Attacks and Defenses [arXiv May 2019] [7] SafeSpec: Banishing the Spectre of a Meltdown with Leakage-Free Speculation [arXiv Jun 2018] [8] Data Oblivious ISA Extensions for Side Channel-Resistant and High Performance Computing [NDSS ‘19] 4
{kind=link}
![はじめに 文献[1]をサーベイした 背景知識の補充などに他の参考文献も利用しています. 文献[2, 3, 4] が基礎となっている Spectre[2] に対して, DIFT[3]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_1.jpg){kind=link}
![参考文献 [1] Context-Sensitive Fencing: Securing Speculative Execution via Microcode Customization](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_2.jpg){kind=link}
![参考文献 [5] FLUSH+RELOAD: A High Resolution, Low Noise, L3 Cache](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
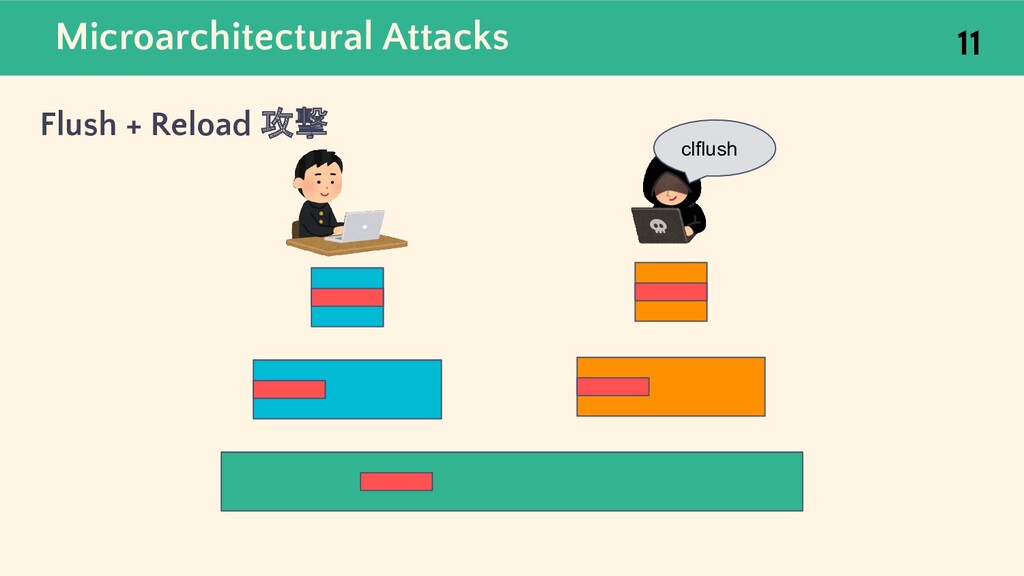
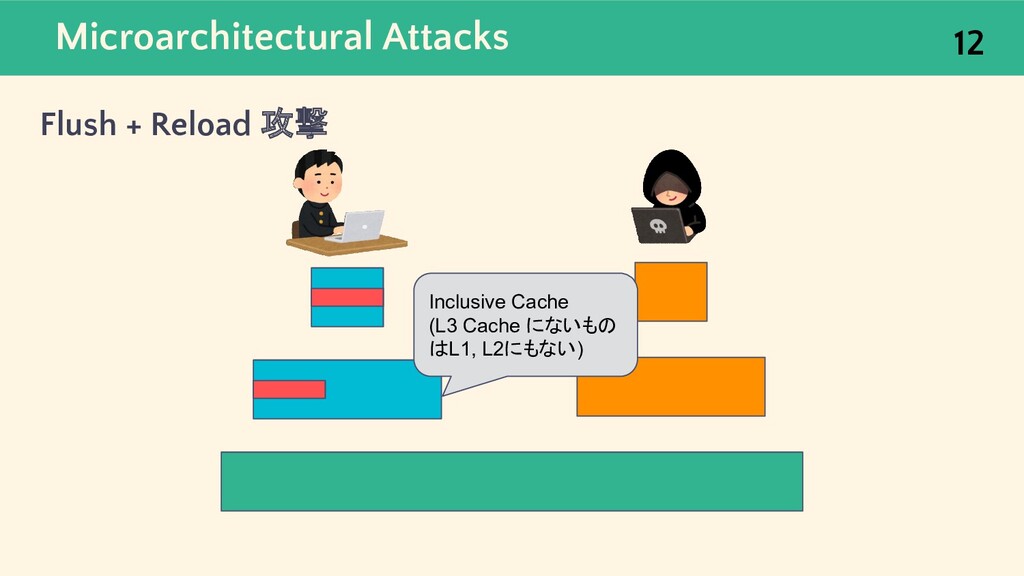
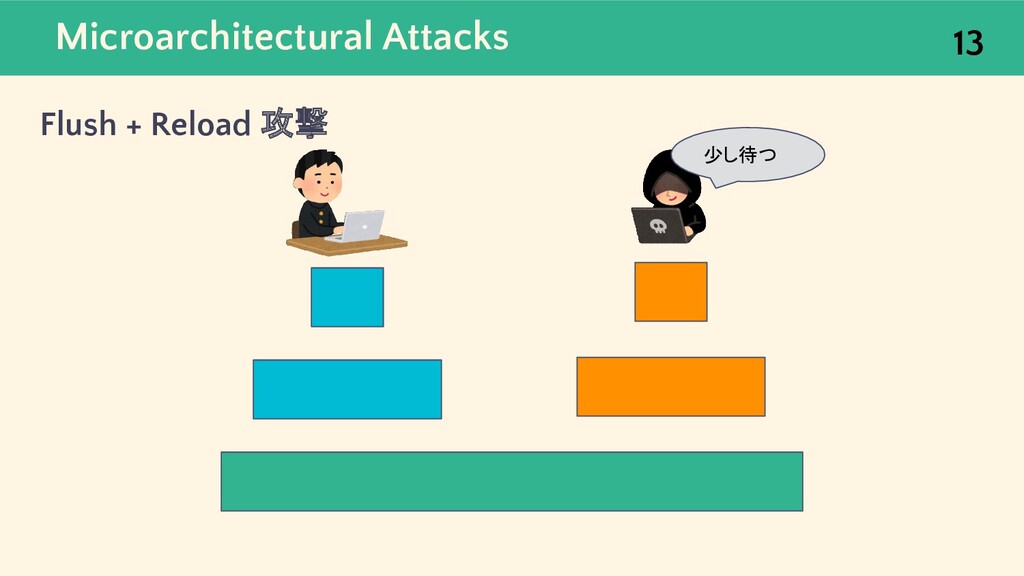
![Microarchitectural Attacks 9 Flush + Reload 攻撃 [5] キャッシュに対するマイクロアーキテクチャ攻撃のひとつで, メモリアクセスのレイテンシの差から](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_8.jpg){kind=link}
![Microarchitectural Attacks Flush + Reload 攻撃 [5] 10 L1 Cache](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Microarchitectural Attacks Flush + Reload 攻撃 14 a = data[0xf000]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_13.jpg){kind=link}
![Microarchitectural Attacks Flush + Reload 攻撃 15 a = data[0xe000]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_14.jpg){kind=link}
![Microarchitectural Attacks Flush + Reload 攻撃 16 a = data[0xf000]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_15.jpg){kind=link}
![Microarchitectural Attacks Flush + Reload 攻撃 17 a = data[0xf000]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
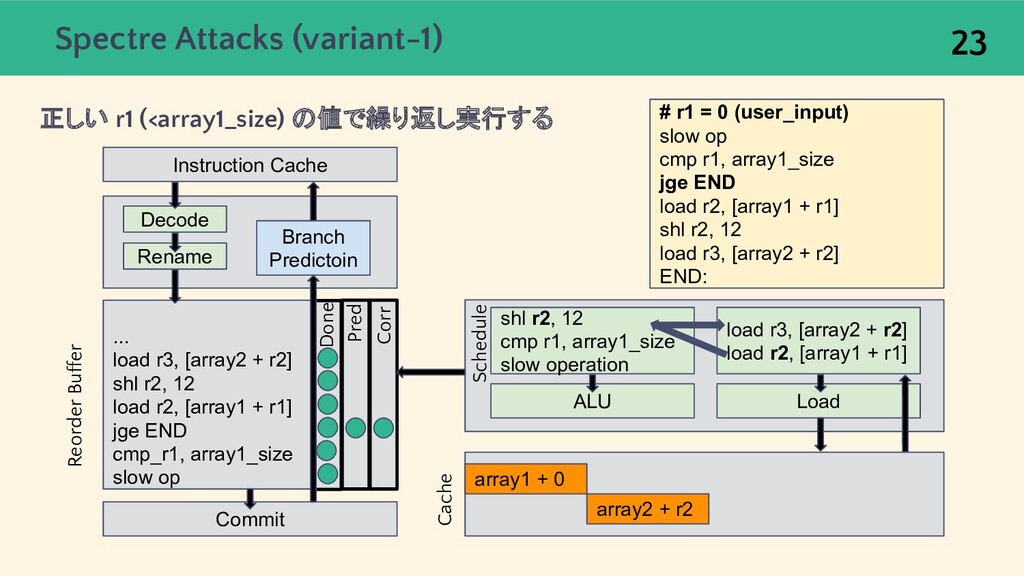
![Transient Execution Attacks [6] 攻撃の手順 1. 攻撃者がマイクロアーキテクチャの状態を望む状態にする • 攻撃者が分岐予測器を誤学習させる •](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_20.jpg){kind=link}
![Spectre Attacks (variant-1) Spectre gadget 22 uint8_t array1[array1_size]; uint8_t array2[];](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
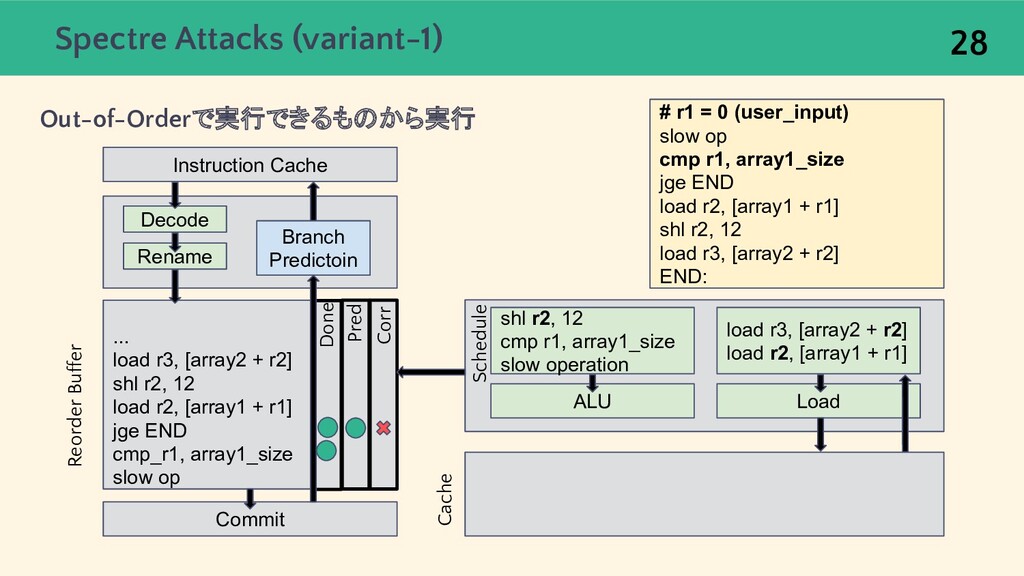{kind=link}
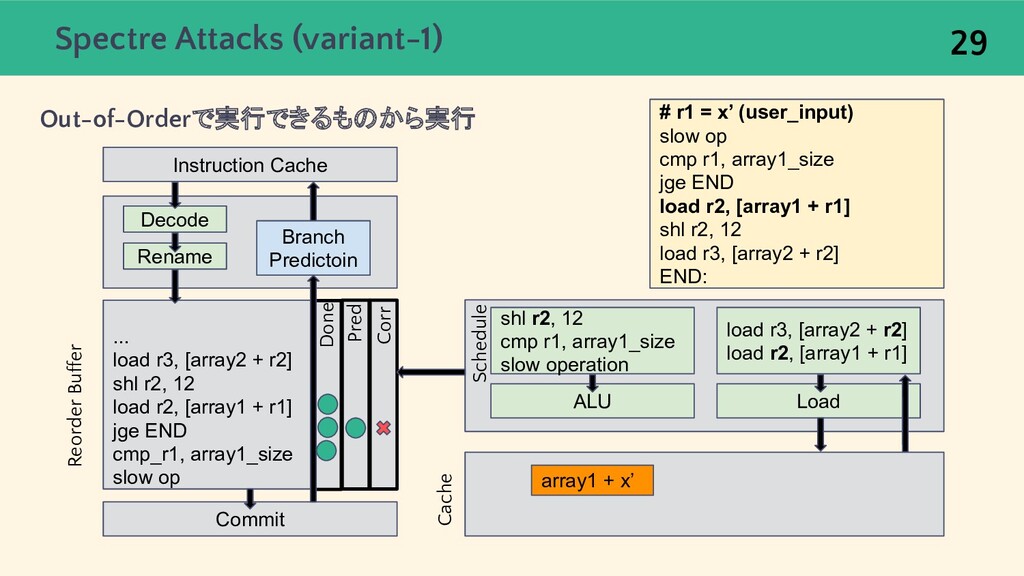{kind=link}
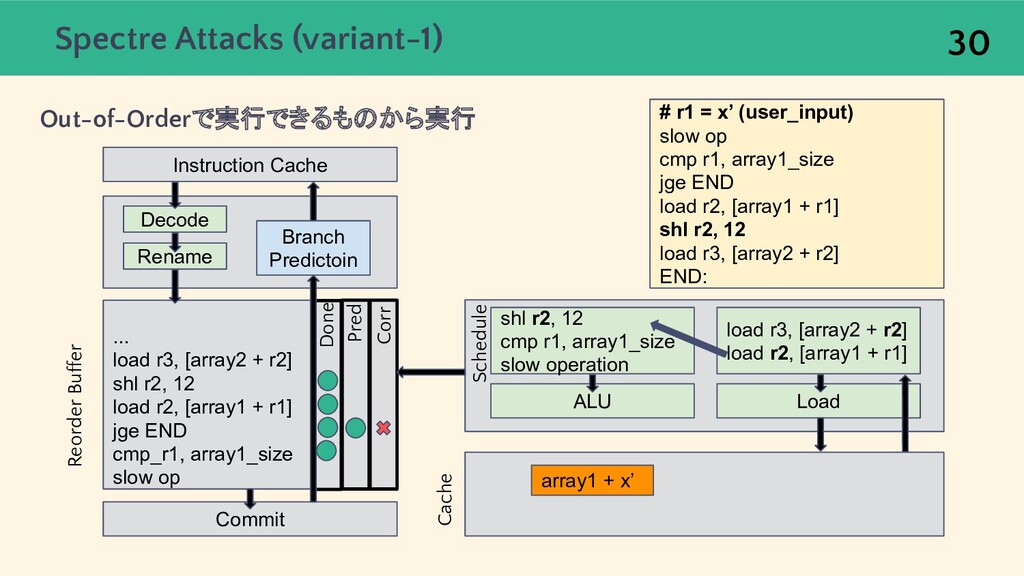{kind=link}
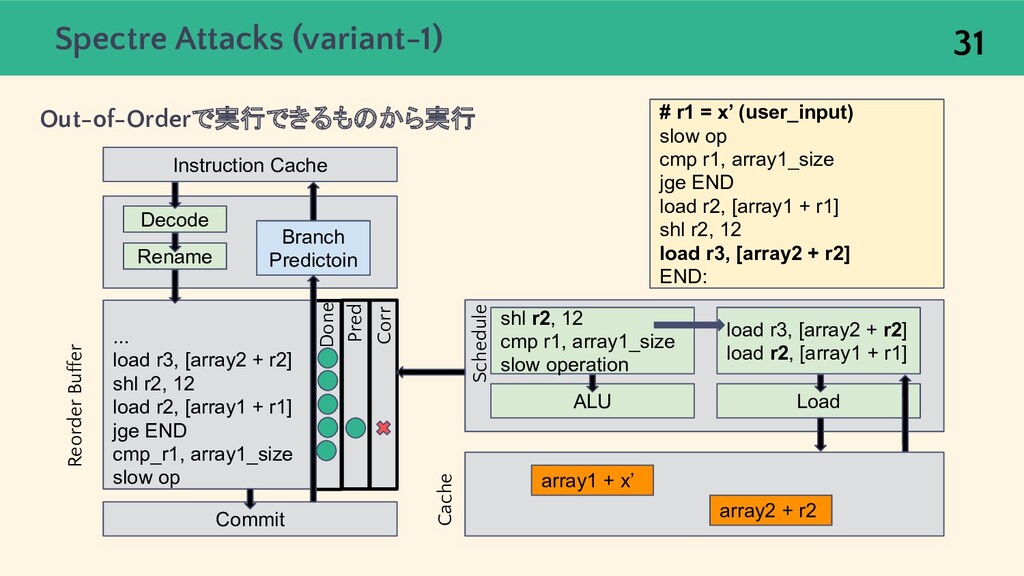{kind=link}
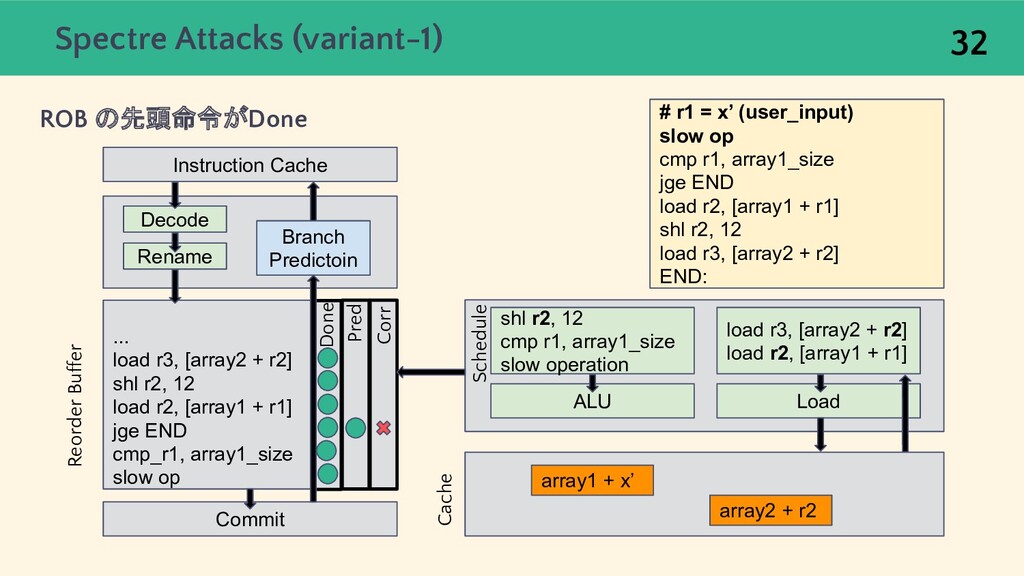{kind=link}
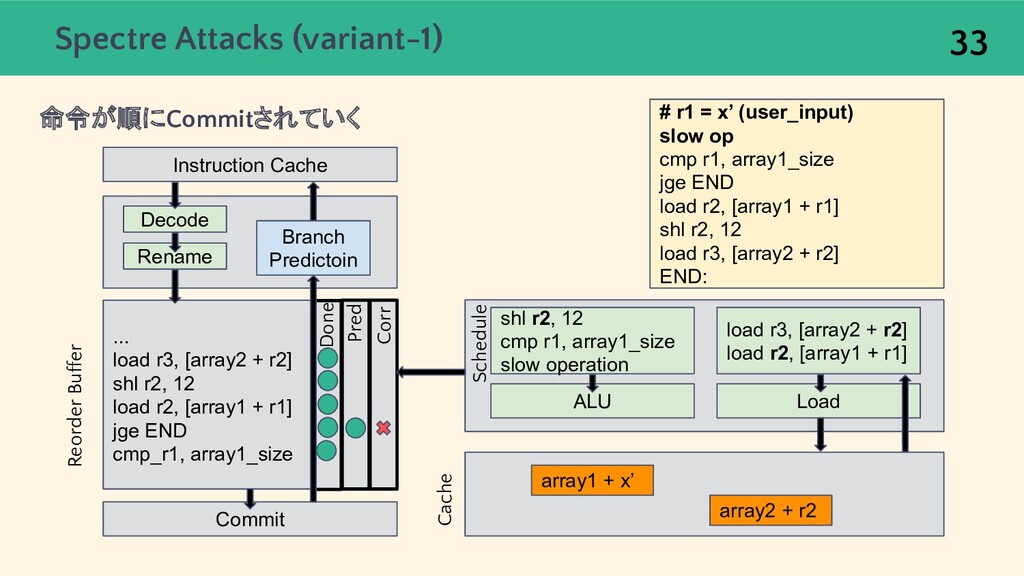{kind=link}
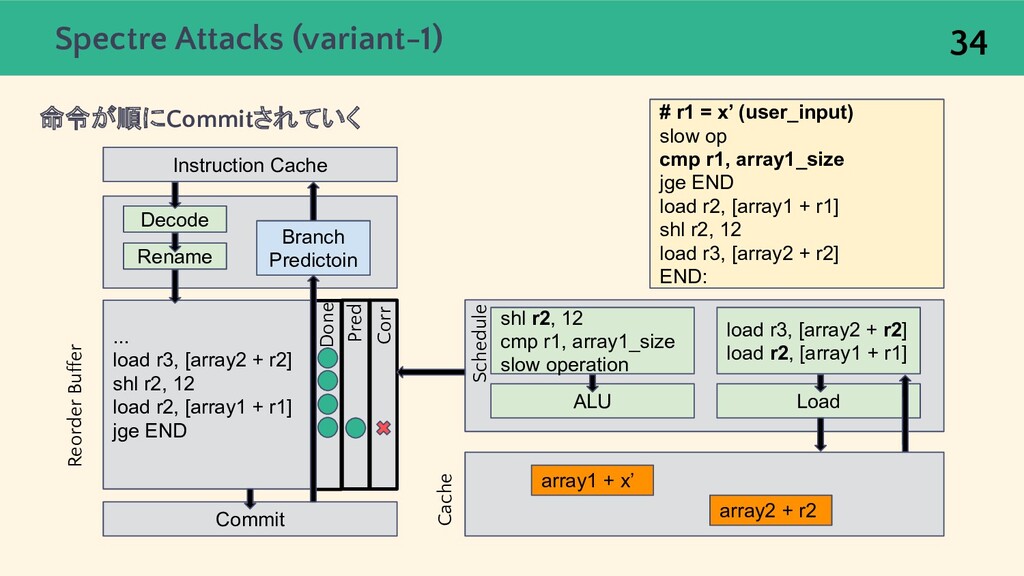{kind=link}
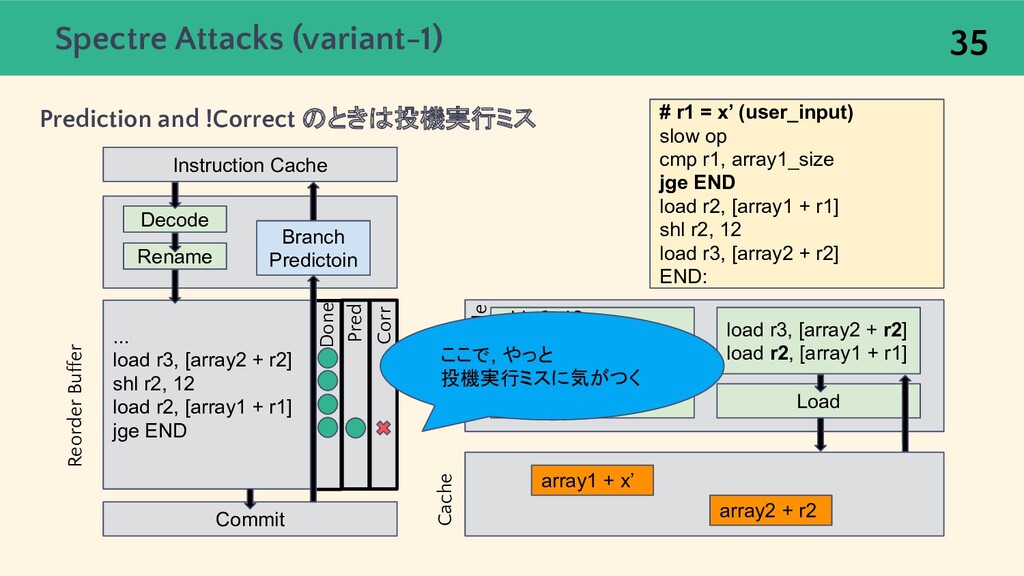{kind=link}
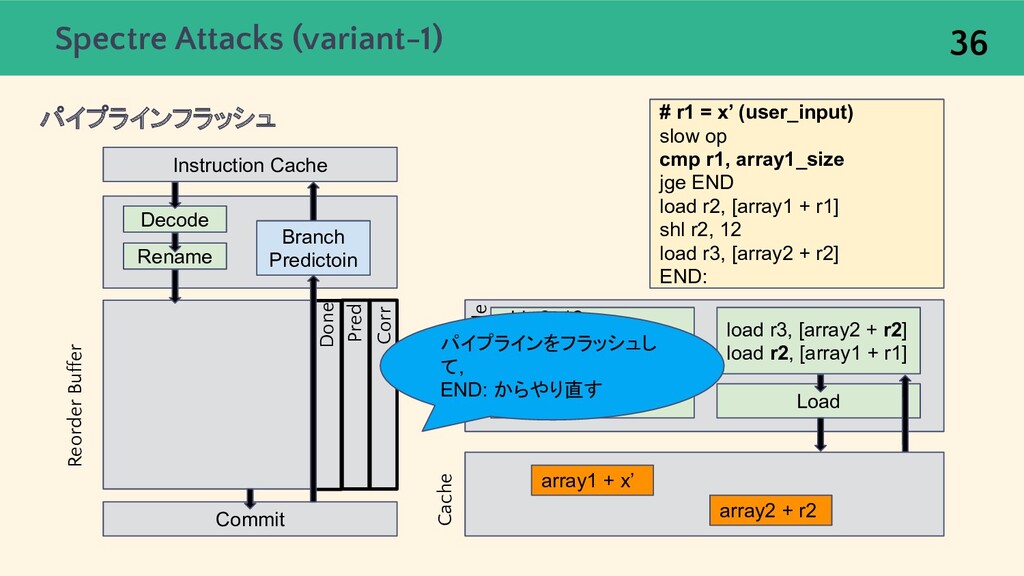{kind=link}
![Spectre Attacks (variant-1) Flush + Reload で [array1 + r1]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_36.jpg){kind=link}
![Spectre Attacks (variant-1) Flush + Reload で [array1 + r1]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_37.jpg){kind=link}
![Spectre Attacks (variant-1) Flush + Reload で [array1 + r1]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_38.jpg){kind=link}
![Spectre Attacks (variant-1) Flush + Reload で [array1 + r1]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_39.jpg){kind=link}
![Spectre Attacks (variant-1) Flush + Reload で [array1 + r1]](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_40.jpg){kind=link}
{kind=link}
![Spectre Mitigation ハードウェアによる対策 • マイクロアーキテクチャ状態も復元する ◦ SafeSpec [7] ▪ Cache](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_42.jpg){kind=link}
{kind=link}
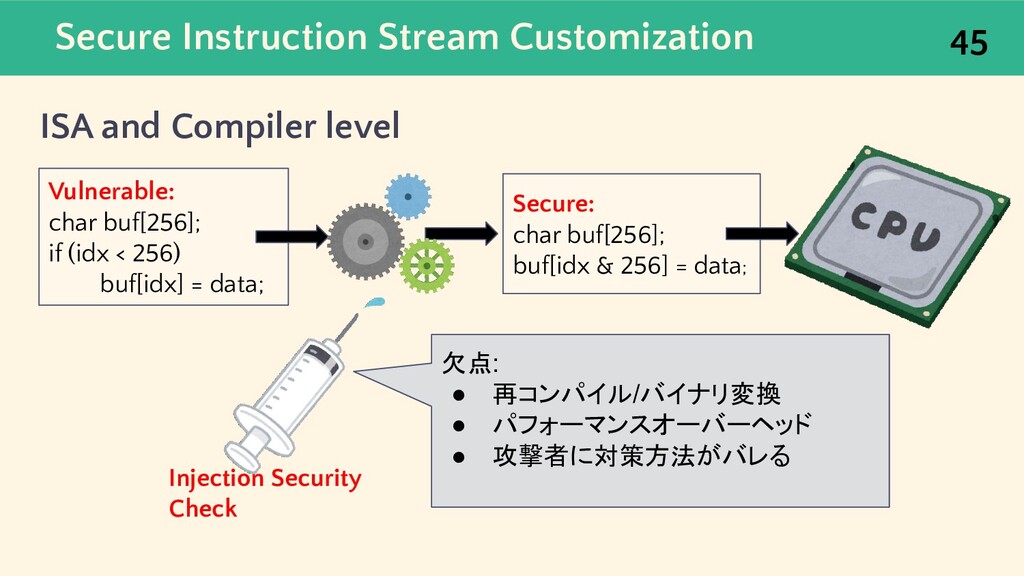{kind=link}
![Secure Instruction Stream Customization microcode level 46 Vulnerable: char buf[256];](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_45.jpg){kind=link}
{kind=link}
![Context Sensitive Decoding (CSD) micro-ops への変換方法 (inc [0xbeef] が Fetch](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_47.jpg){kind=link}
![Context Sensitive Decoding (CSD) micro-ops への変換方法 (inc [0xbeef] が Fetch](https://files.speakerdeck.com/presentations/9eaa01ceb5964069899514e066146ceb/slide_48.jpg){kind=link}
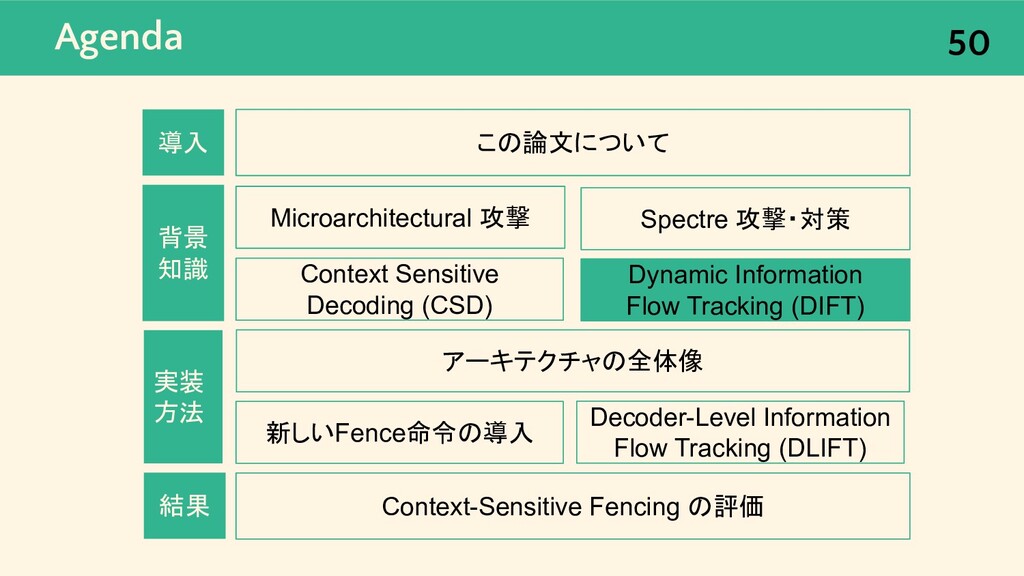{kind=link}
{kind=link}
{kind=link}
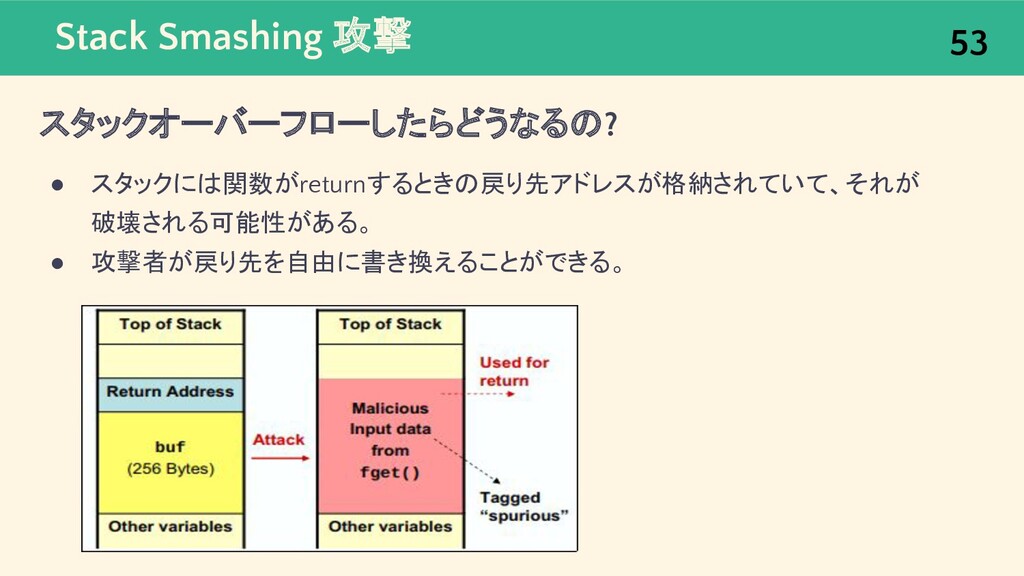{kind=link}
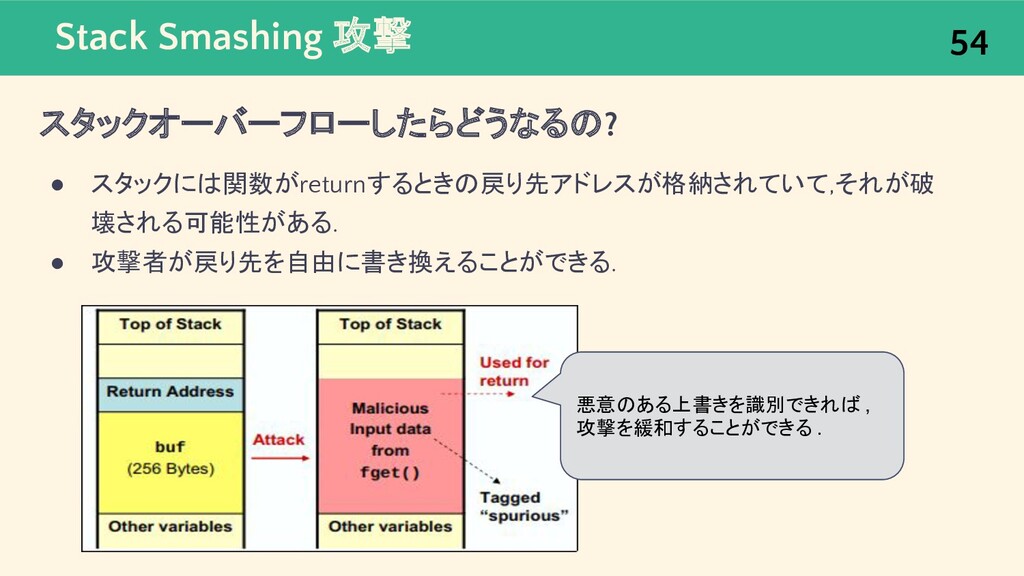{kind=link}
{kind=link}
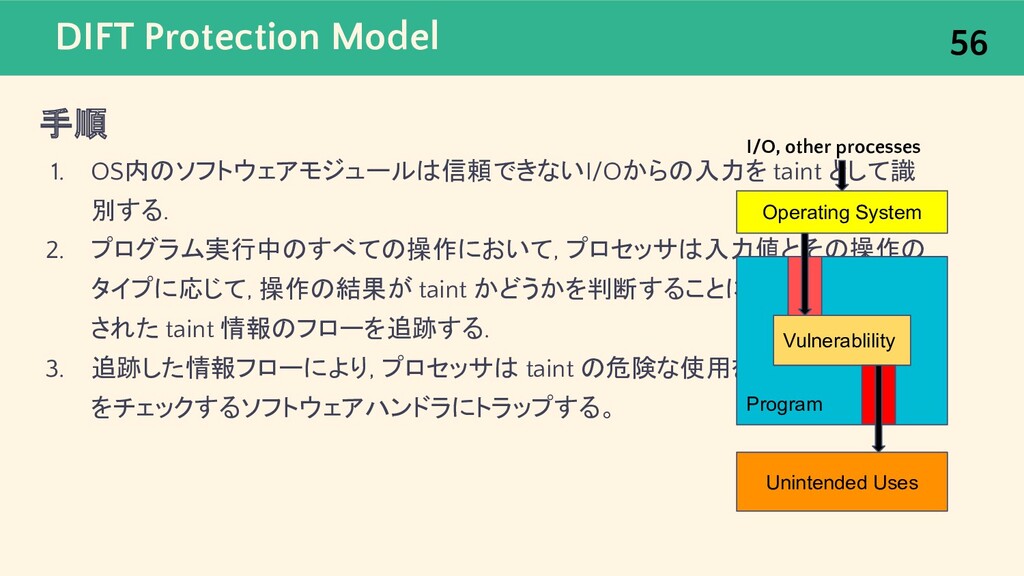{kind=link}
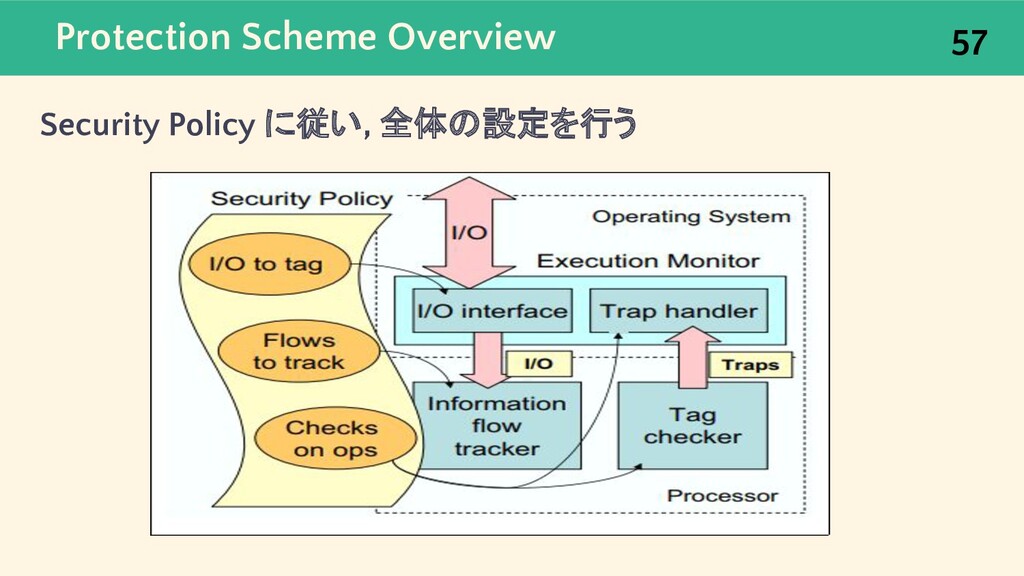{kind=link}
{kind=link}
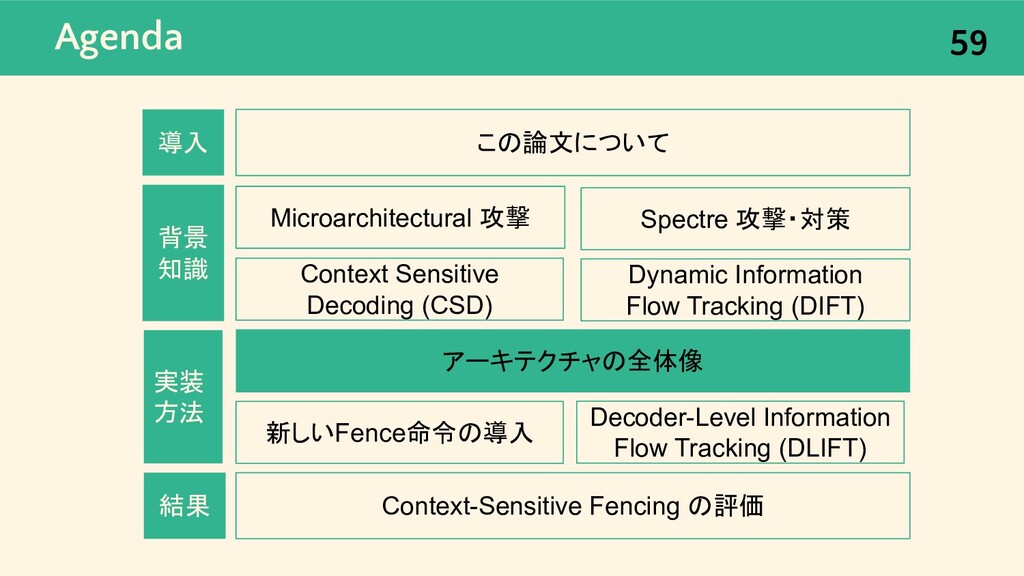{kind=link}
{kind=link}
{kind=link}
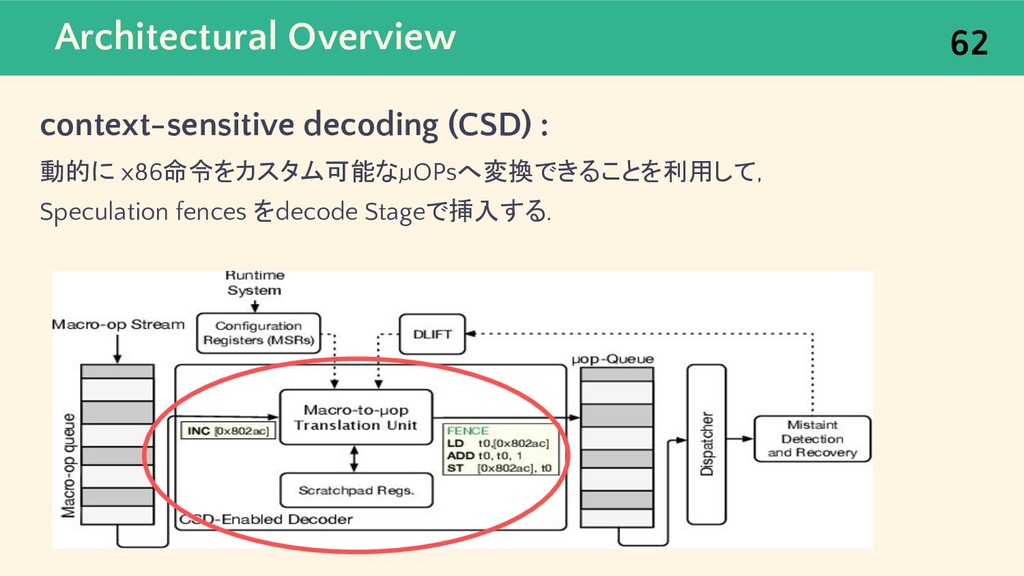{kind=link}
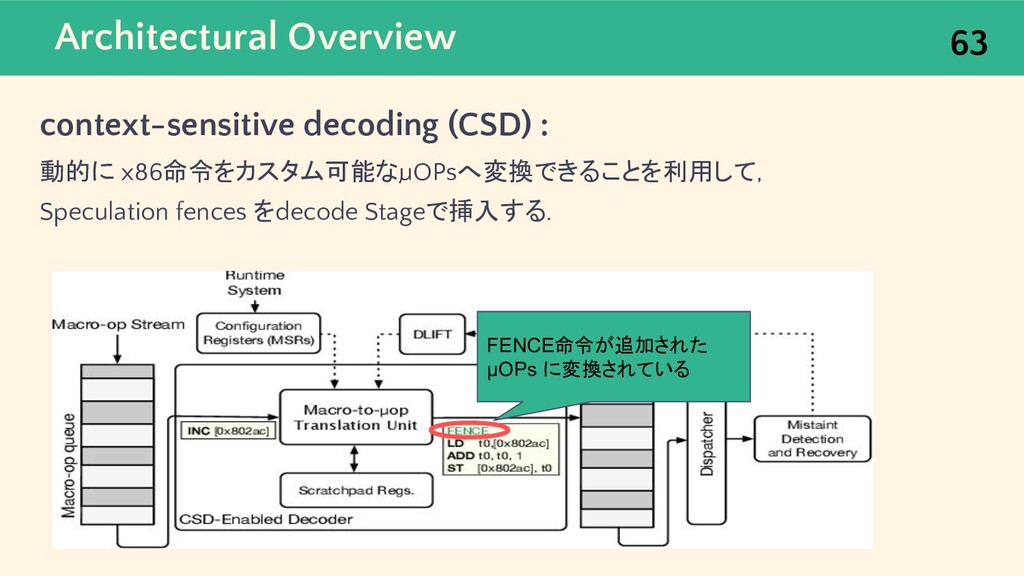{kind=link}
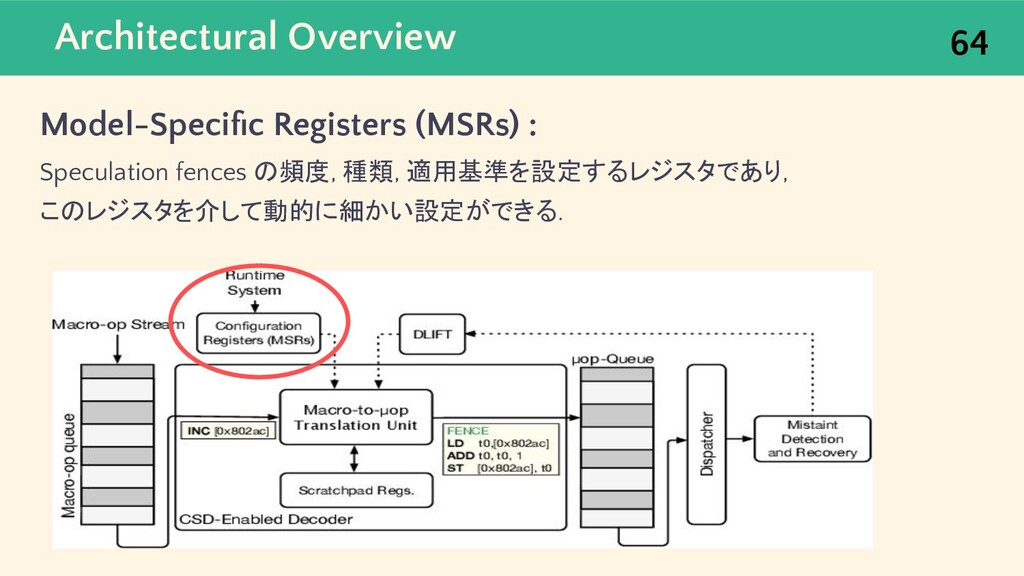{kind=link}
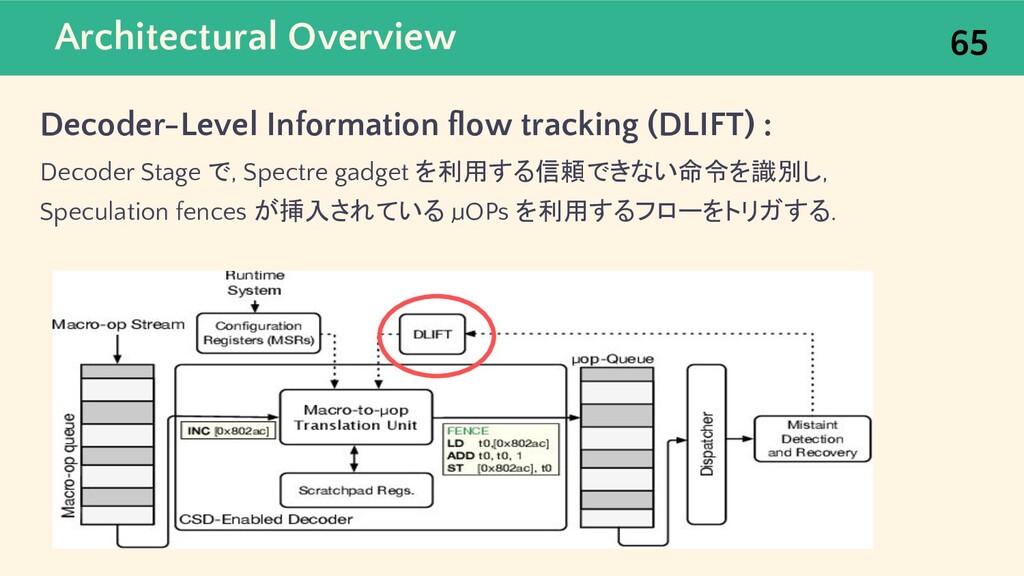{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
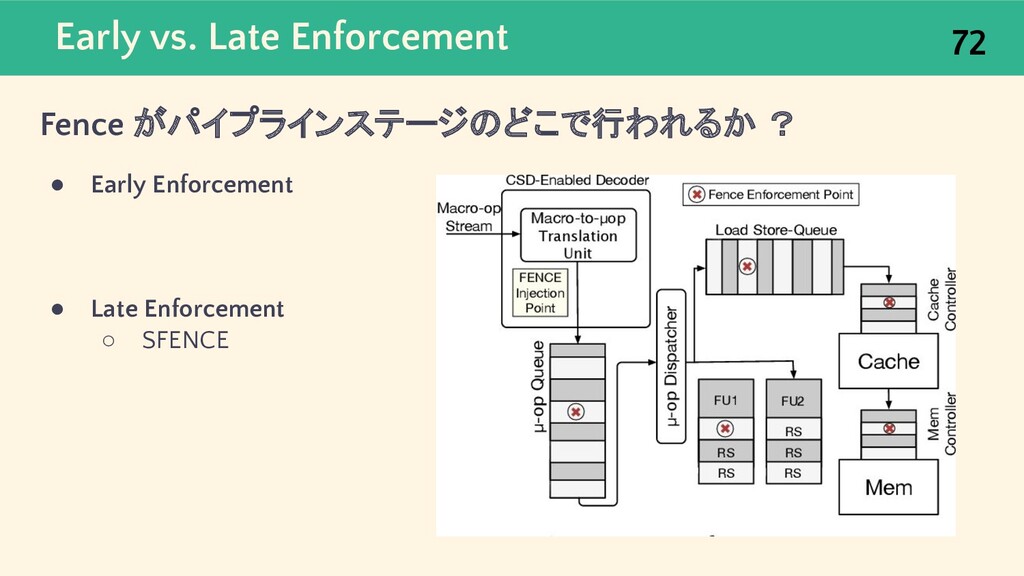{kind=link}
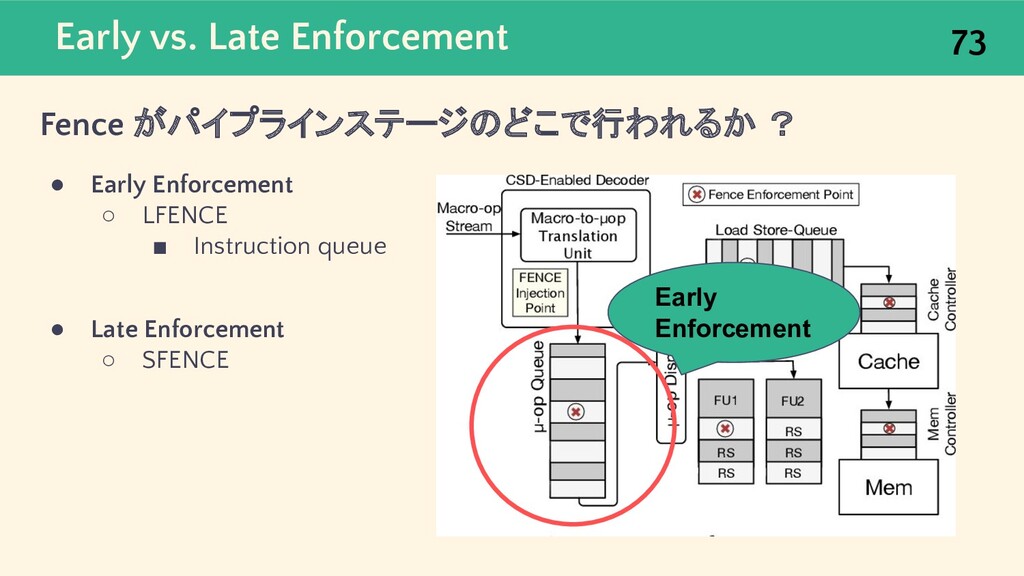{kind=link}
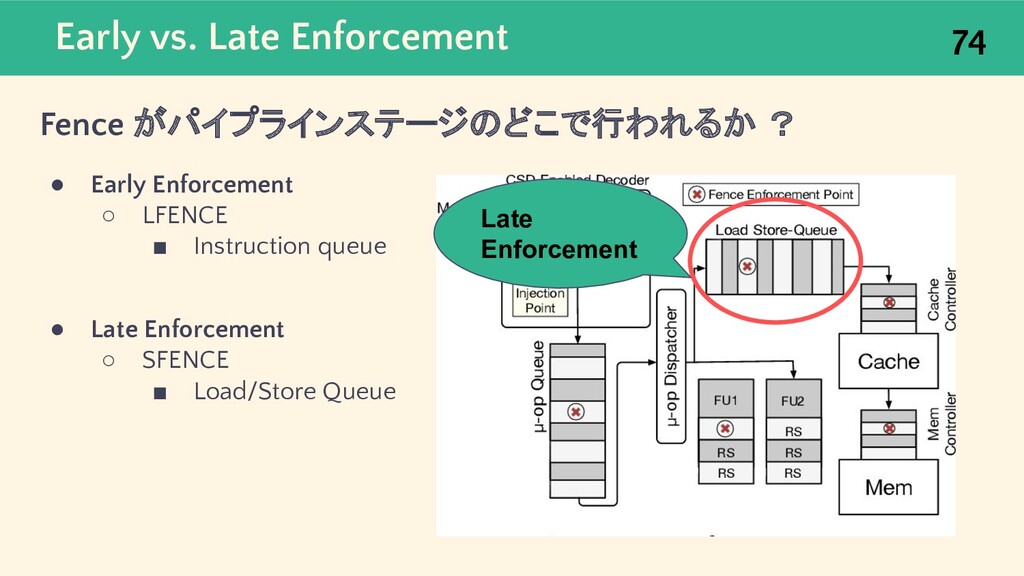{kind=link}
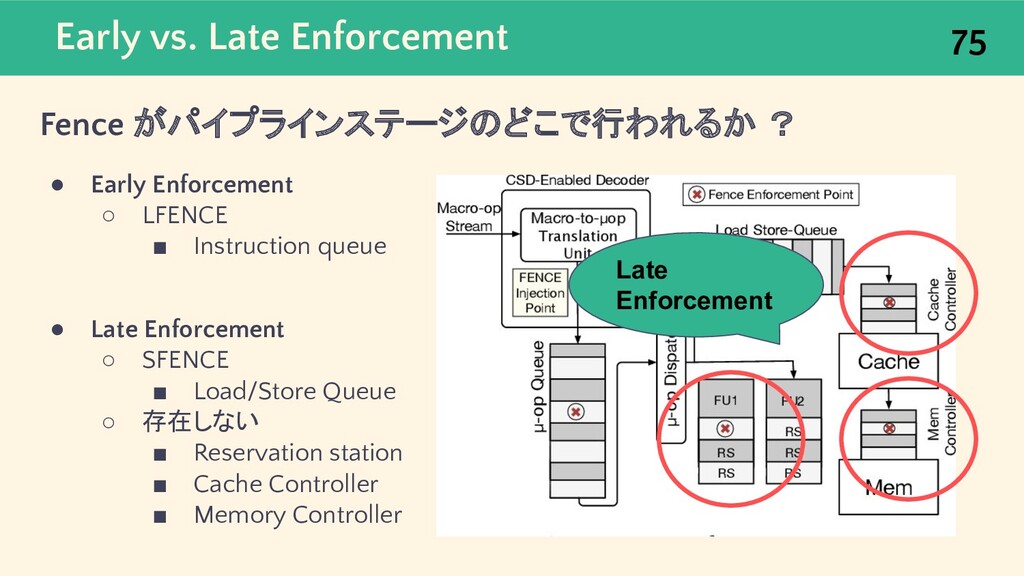{kind=link}
{kind=link}
{kind=link}
{kind=link}
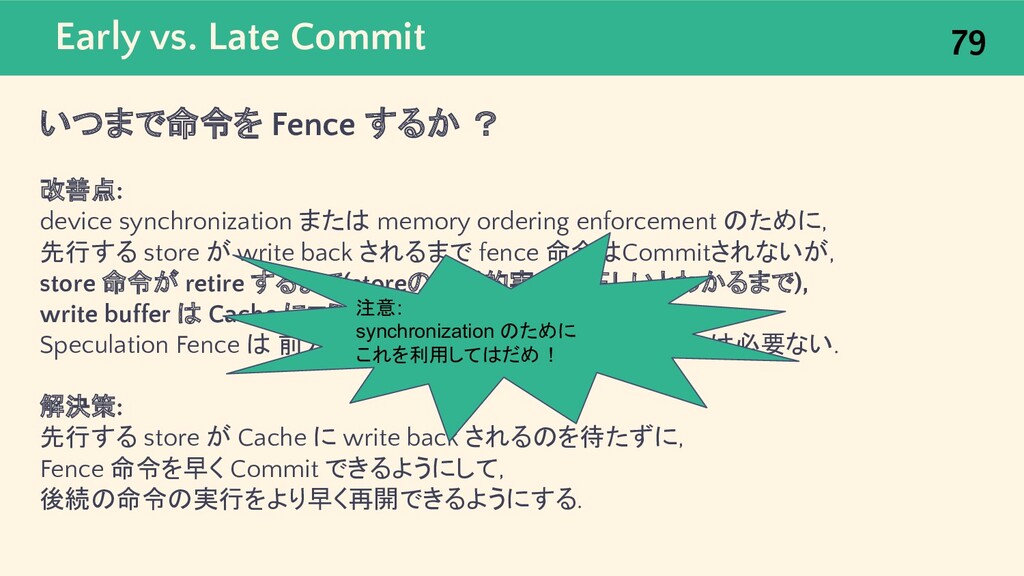{kind=link}
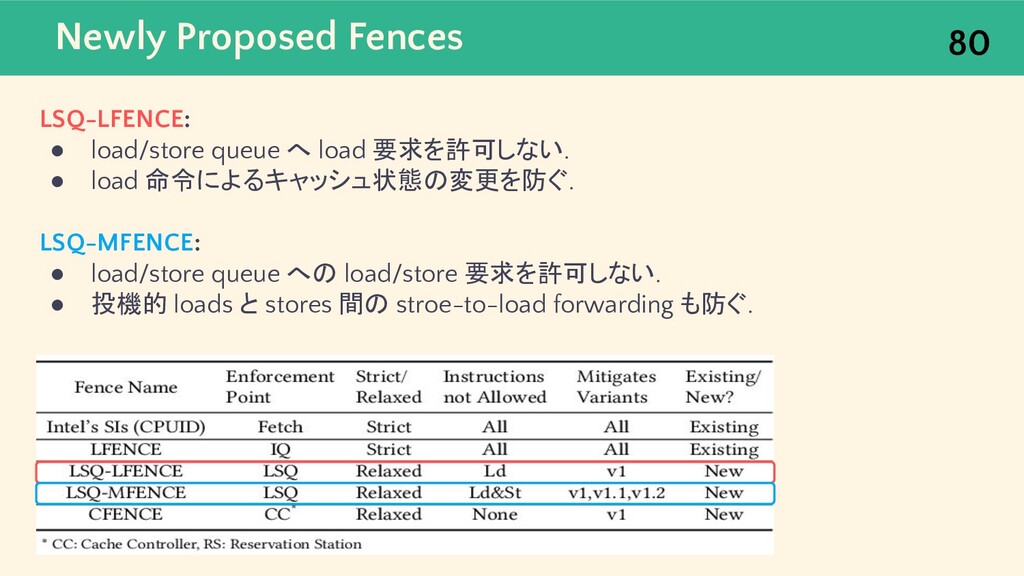{kind=link}
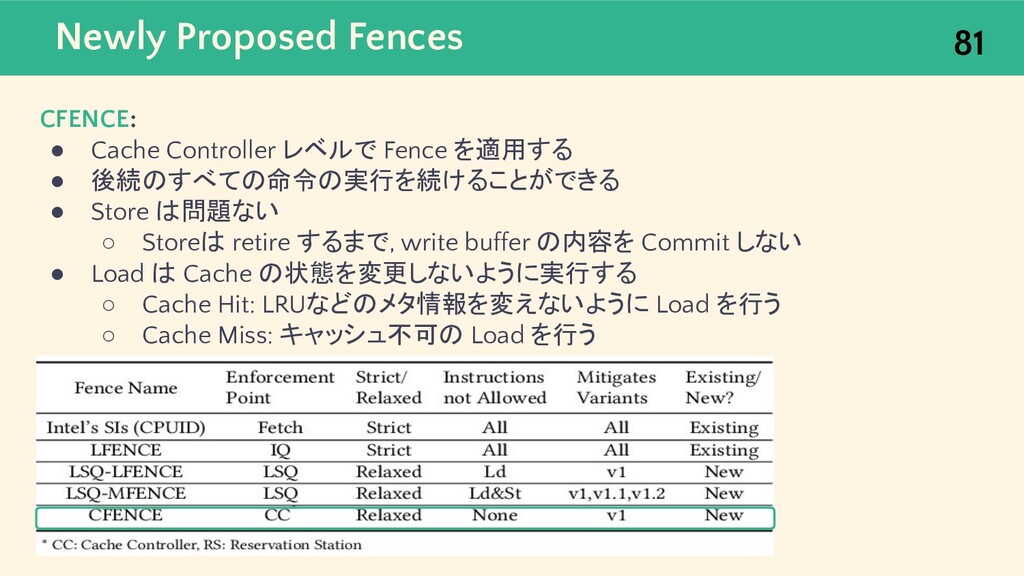{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
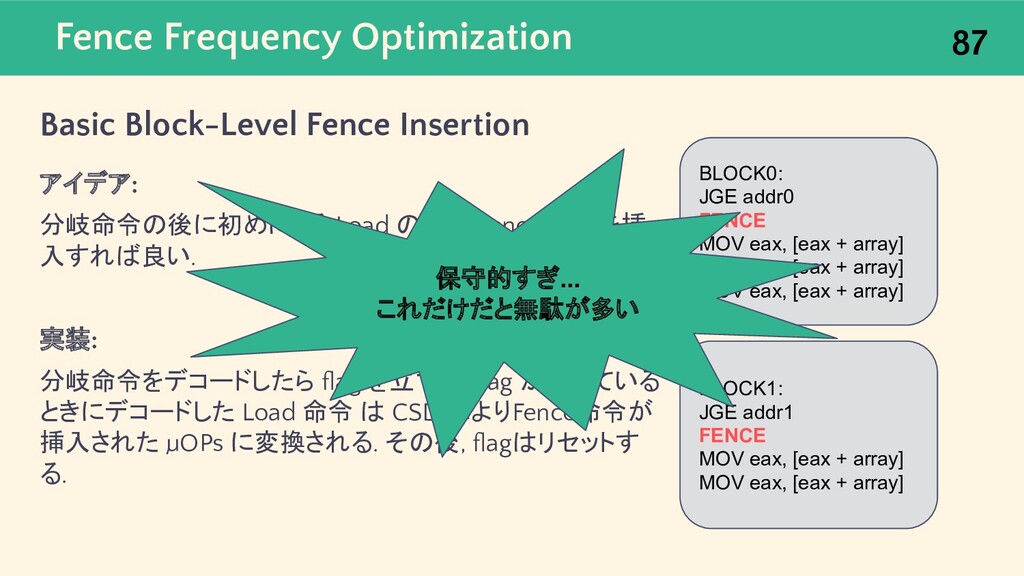{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
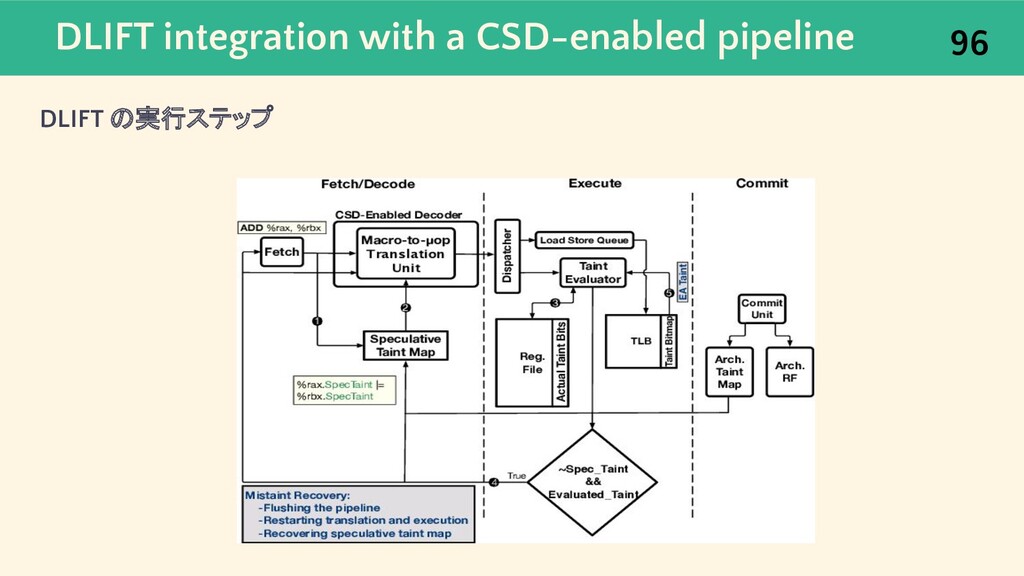{kind=link}
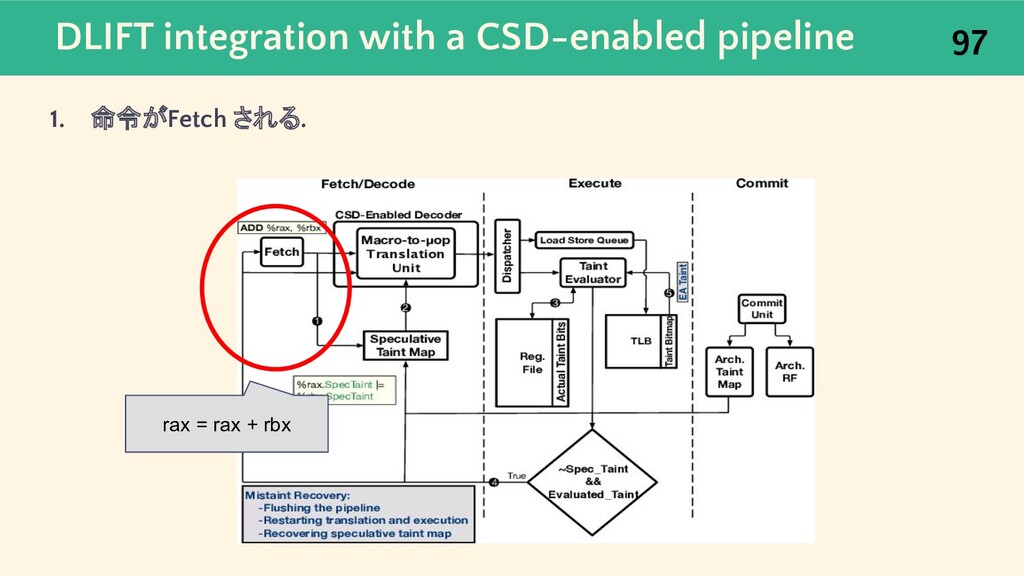{kind=link}
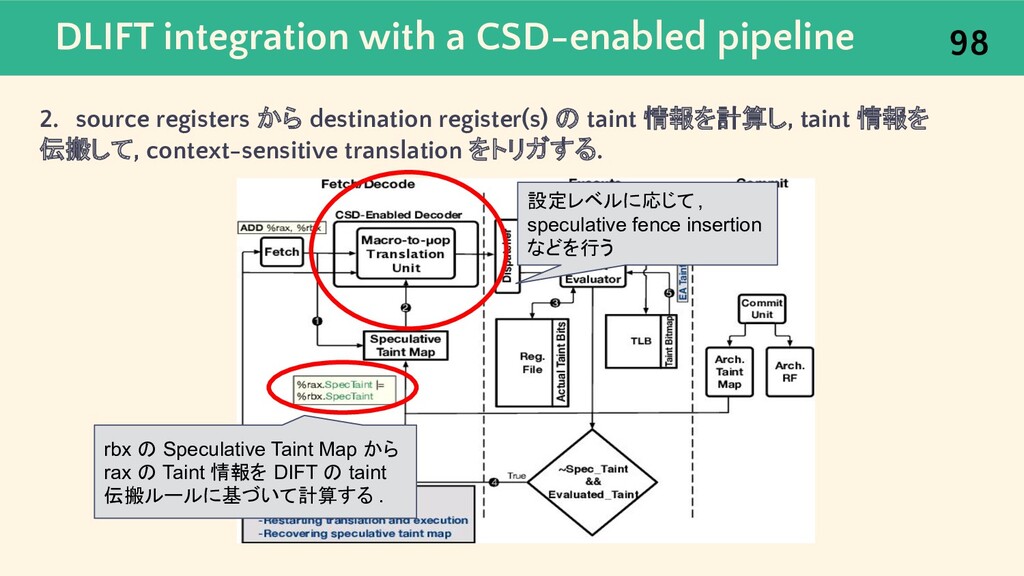{kind=link}
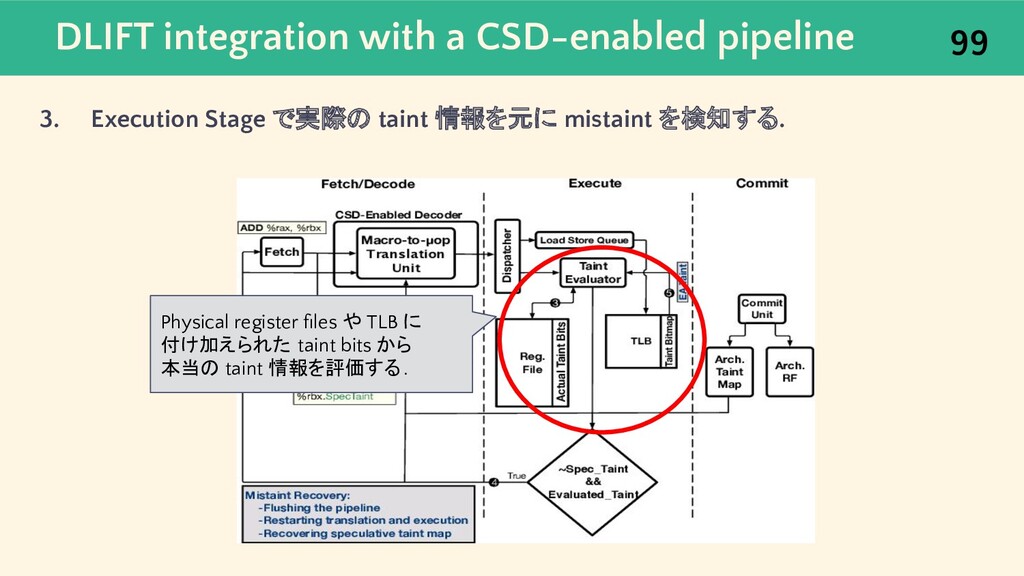{kind=link}
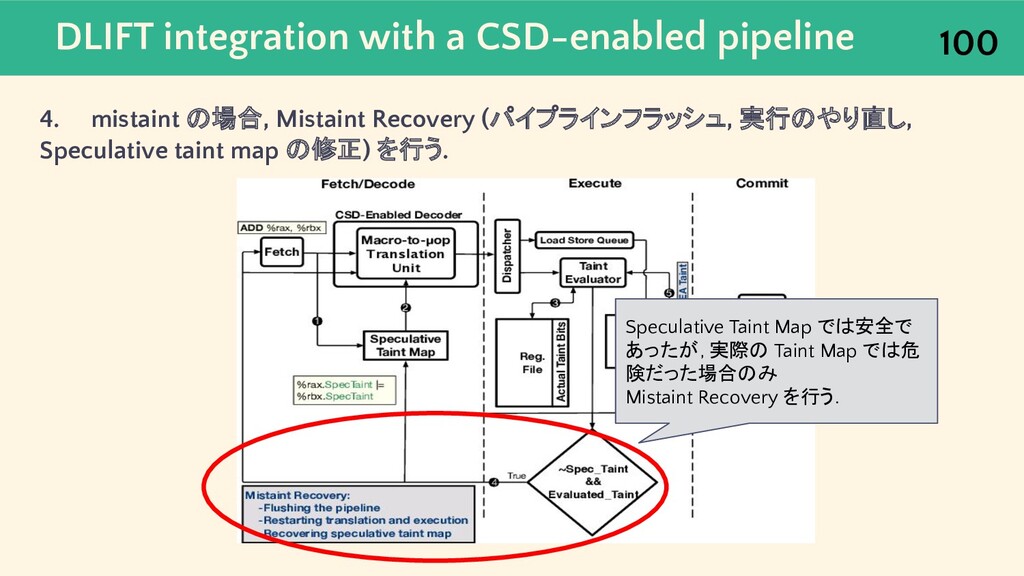{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
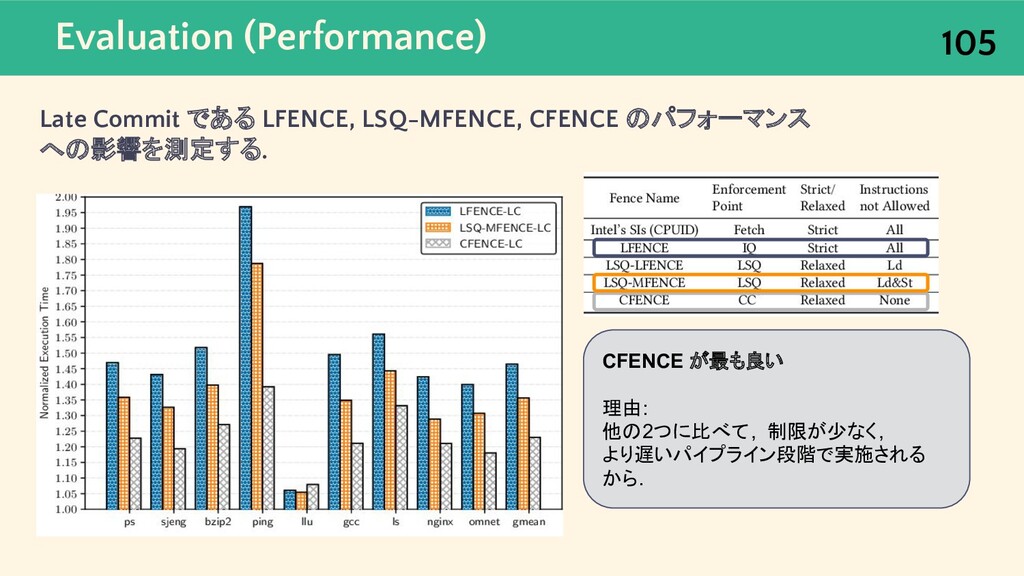{kind=link}
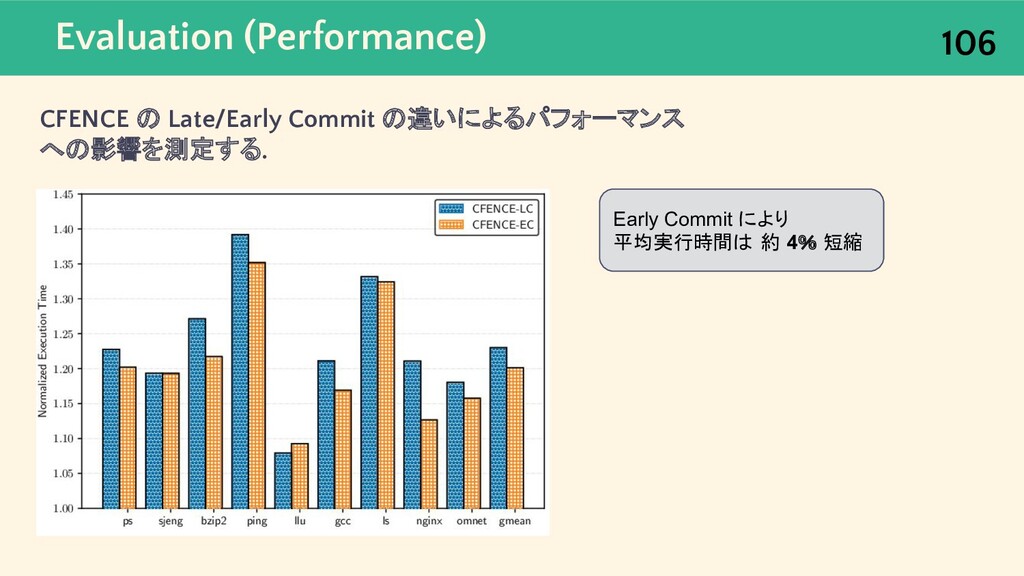{kind=link}
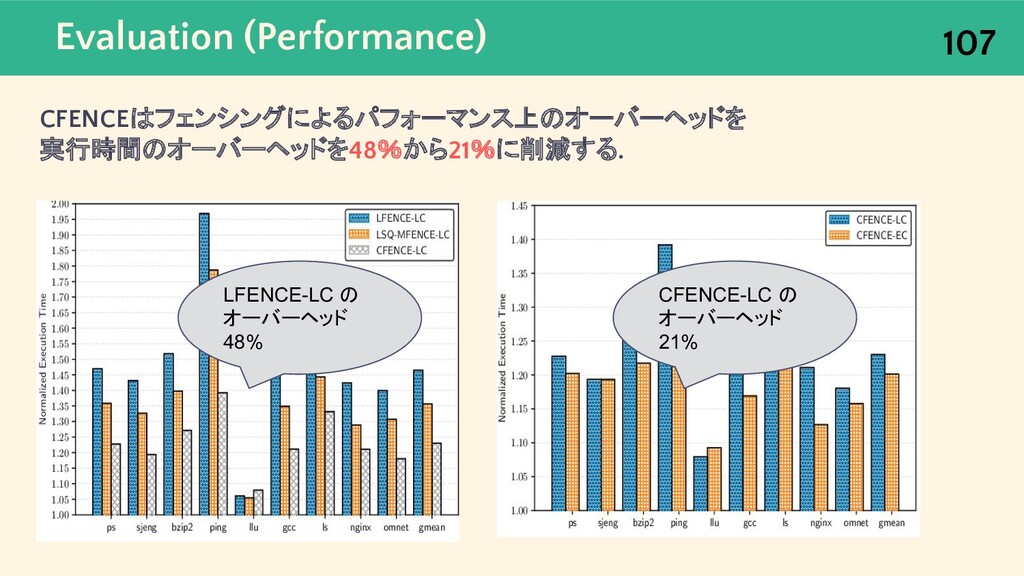{kind=link}
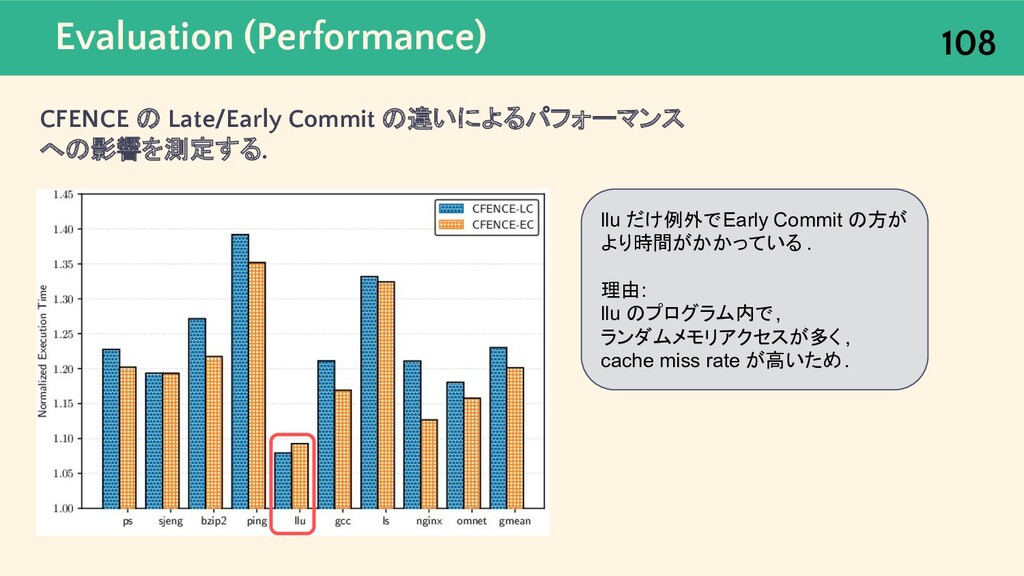{kind=link}
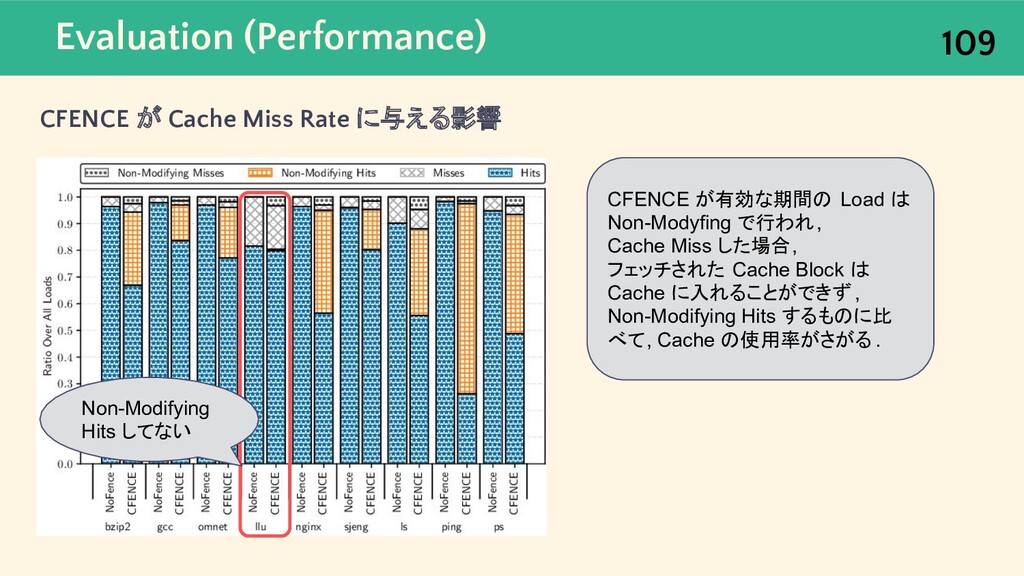{kind=link}
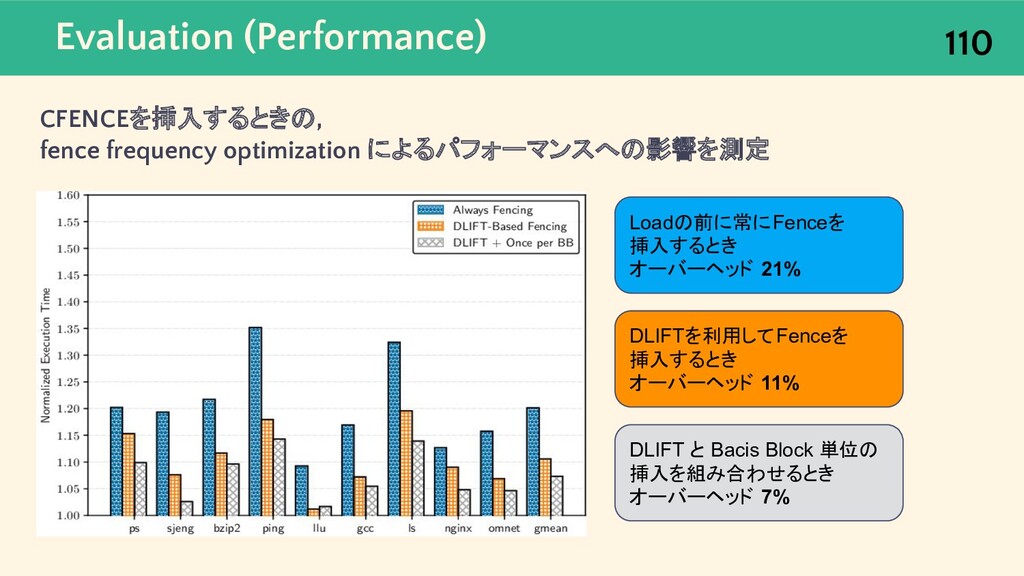{kind=link}
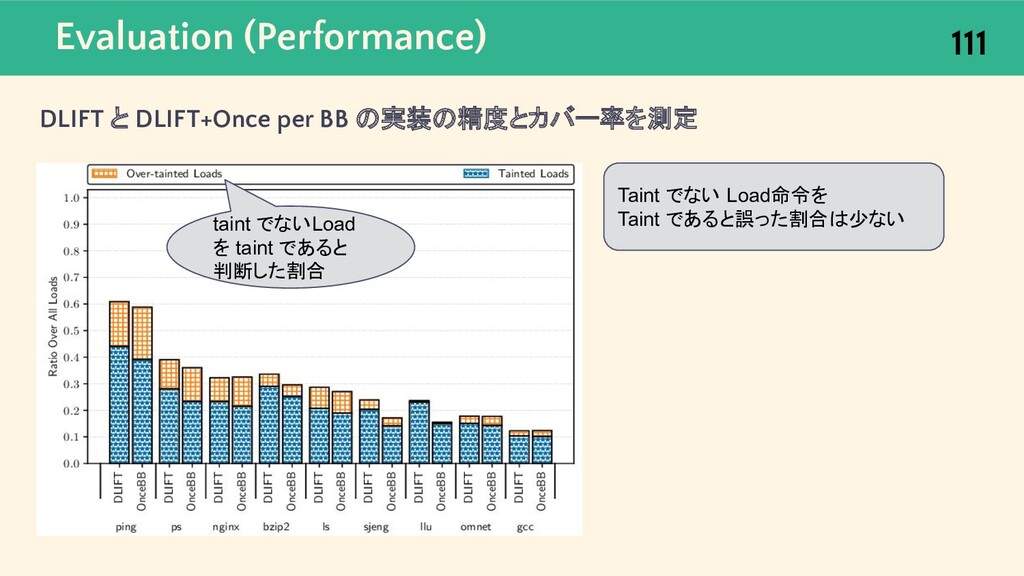{kind=link}
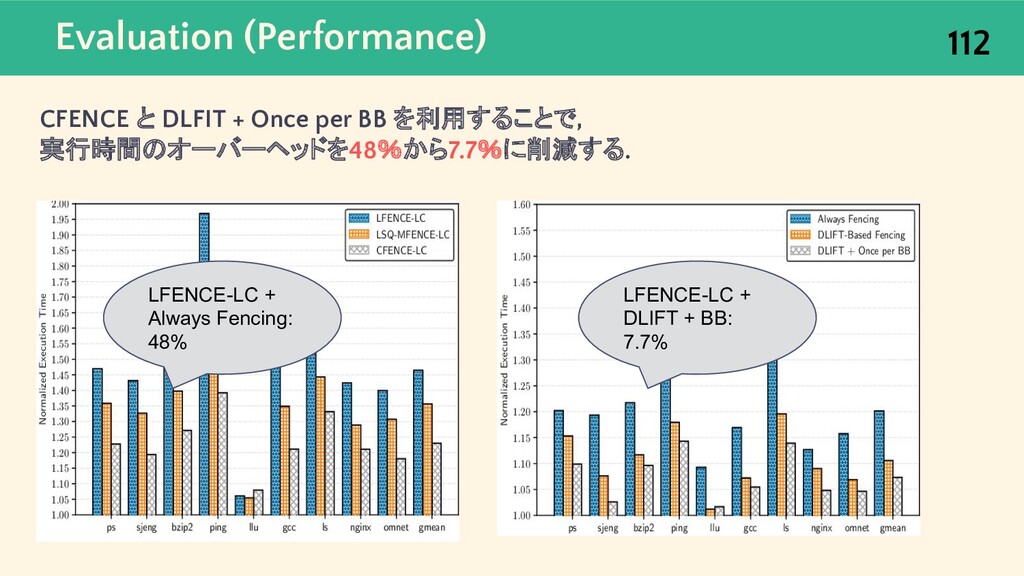{kind=link}
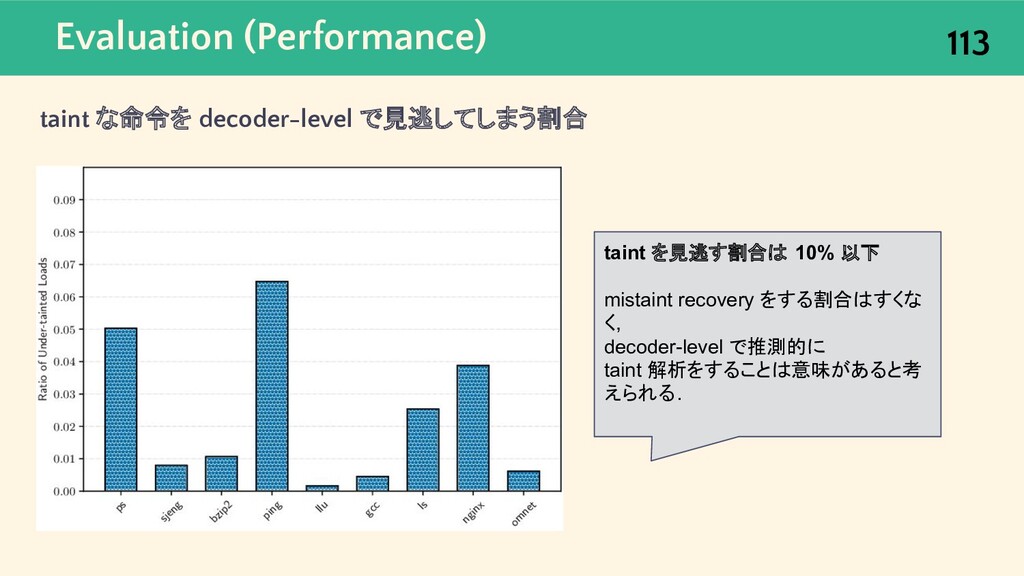{kind=link}
{kind=link}