Asya Kamsky, 10gen
Welcome and Kickoff!
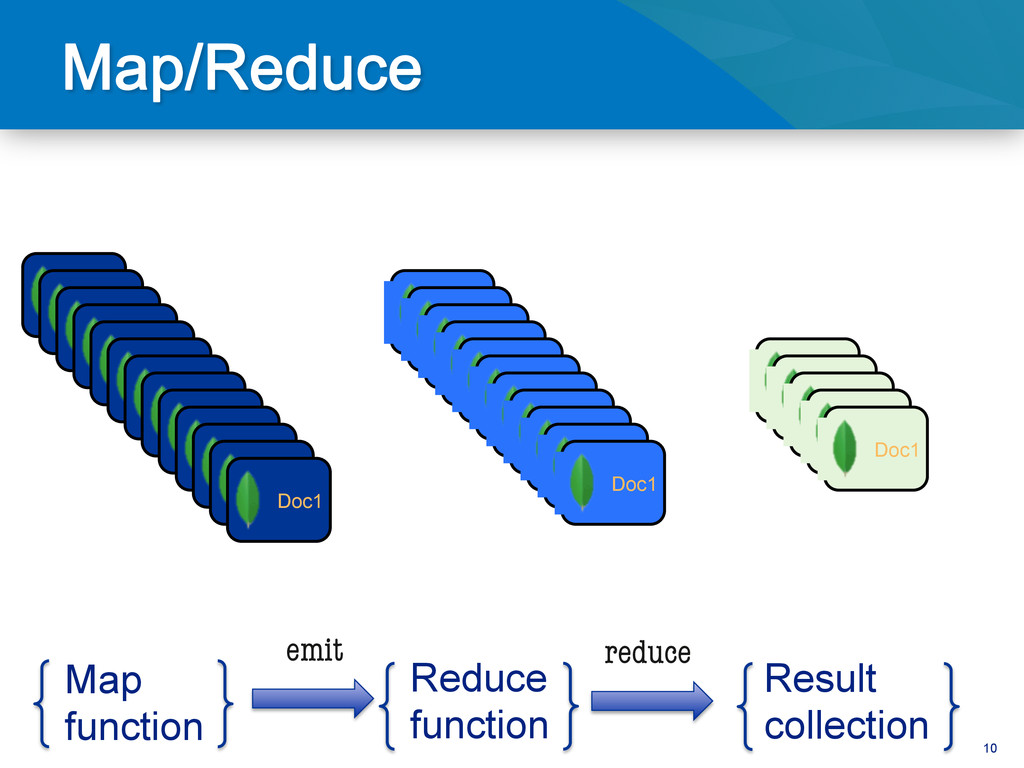
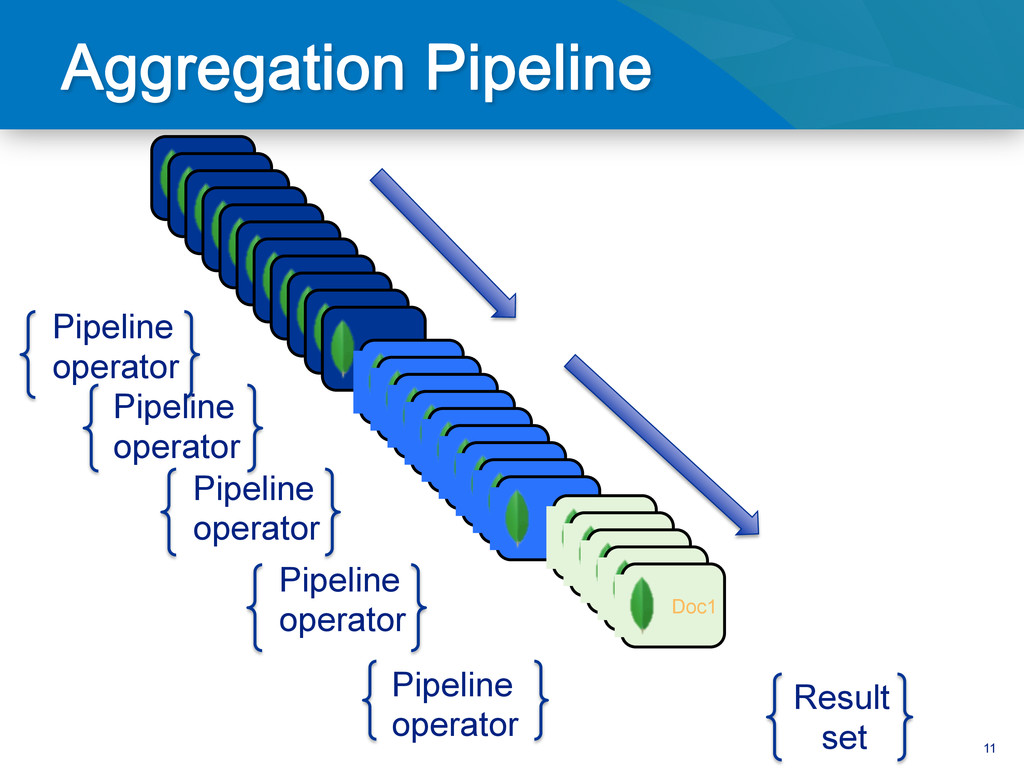
We're working on a new aggregation framework for MongoDB that will introduce a new aggregation system that will make it a lot easier to do simple tasks like counting, averaging, and finding minima or maxima while grouping by keys in a collection. The new aggregation features are not a replacement for map-reduce, but will make it possible to do a number of things much more easily, without having to resort to the big hammer that is map-reduce. After introducing the syntax and usage patterns for the new aggregation system, we will give some demonstrations of aggregation using the new system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}