doc2 doc1 collection2 db-1 doc2 doc1 collection1 doc2 doc1 collection2 mysqld db-n doc2 doc1 table1 doc2 doc1 table2 db-1 doc2 doc1 table1 doc2 doc1 table2 VS. DB Process Lock VS. Row Lock single global write lock for the entire server (process) Monday, April 2, 2012
•SERVER-1240 : Collection level locking https://jira.mongodb.org/browse/SERVER-1240 Planning Bucket A Vote (154) •SERVER-1241 : Intra collection locking (maybe extent) https://jira.mongodb.org/browse/SERVER-1241 Planning Bucket A Vote (25) •SERVER-2563 : When hitting disk, yield lock - phase 1 https://jira.mongodb.org/browse/SERVER-2563 Fixed in 1.9.1 Vote (25) • any time we actually have to hit disk. so if a memory mapped page is not in ram, then we should yield update by _id, remove, long cursor iteration •SERVER-1169 : Record level locking https://jira.mongodb.org/browse/SERVER-1169 Rejected Vote (1) and more ... Monday, April 2, 2012
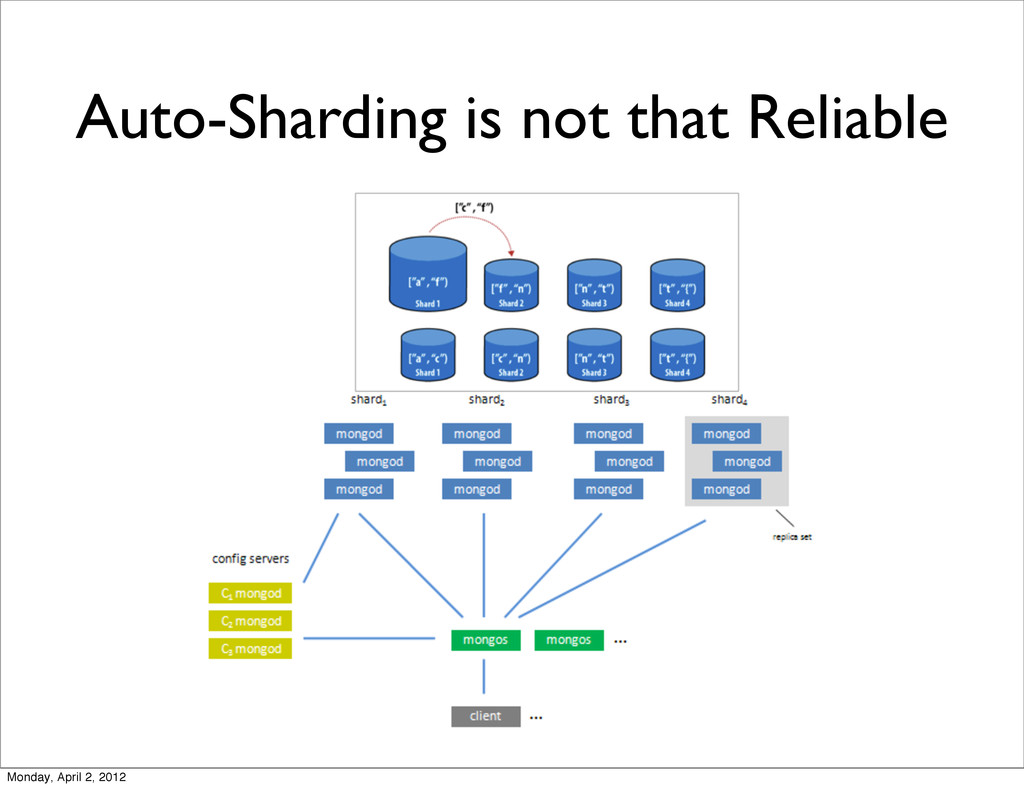
docs in a collection after sharding • Balancer dead lock [Balancer] skipping balancing round during ongoing split or move activity.) [Balancer] dist_lock lock failed because taken by.... [Balancer] Assertion failure cm s/balance.cpp... • Uneven shard load distribution • ... (Note: I did the experiment before 2.0. So some of the issues might be fixed or improved in new versions of MongoDB coz it’s evolving very fast) Monday, April 2, 2012
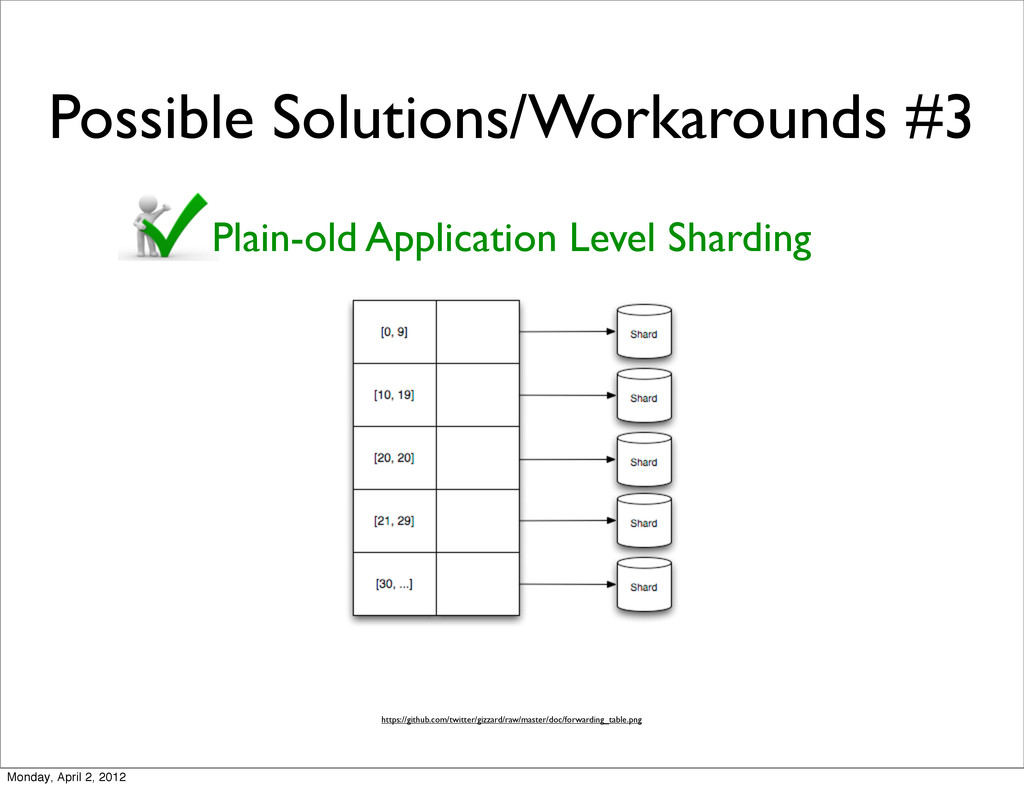
key https://jira.mongodb.org/browse/SERVER-2001 Unresolved Fix Version/s: 2.1.1 Vote (27) “The lack of hashing based read/write distribution amongst available shards is a huge issue for us now. We're actually considering implementing an app-side layer to do this but that obviously has a number of serious drawbacks.” - Remon van Vliet “Seems like a good idea : we implemented hashed shard key on client-side : operation rate sky rocked ( x3 and less variability). Balancing is moreover quicker and done during our very heavy insertion process : perfect !” - Grégoire Seux Monday, April 2, 2012
planned but not scheduled Vote (66) “Most collections, even if they don’t contain the same structure , they contain similar. So it would make a lot of sense and save a lot of space to tokenize the field names.” “The overall benefit as mentioned by other users is that you reduce the amount of storage/RAM taken up by redundant data in each document (so you can use less resources per request, hence gain more throughput and capacity), while importantly also freeing the developer from having to pick short and hard to read field names as a workaround for a technical limitation.” - Andrew Armstrong Monday, April 2, 2012
https://jira.mongodb.org/browse/SERVER-164 planned but not scheduled Vote (126) “The way oracle handles this is transparent to the database server at the block engine level. They compress the blocks similar to how SAN store's handle it rather than at a record level. They use zlib type compression and the overhead is less than 5 percent. Due to the IO access reduction in both number of blocks touched, and amount of data transferred, the overall effect is a cumulative speed increase. Should MongoDB do it this way? Maybe? But at the end of the day, the architecture must make Mongo more scalable, as well as increase the ability limit the storage footprint.” - Michael D. Joy Monday, April 2, 2012
the NoSQL world. Wish more effort invested in fixing the Hard Problems : locking, sharding, storage engine... http://www.mongodb.org/display/DOCS/SQL+to+Mongo+Mapping+Chart Monday, April 2, 2012
Scala, Java, Ruby, Clojure) • Data Mining Engineer • DevOps Engineer • Front End Engineer We are doing bigdata analytics [email protected] Monday, April 2, 2012
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact • Email : [email protected] [email protected] • Twitter: @stonegao Monday,](https://files.speakerdeck.com/presentations/4f7f2ced2807e6001f00cf3b/slide_29.jpg){kind=link}
{kind=link}