Part 2: ... function loadChartbeat() { // insert script tag } window.onload = loadChartbeat; </body> (highly simplified) Ping is standard beacon logic, i.e. loading a 1x1 image.
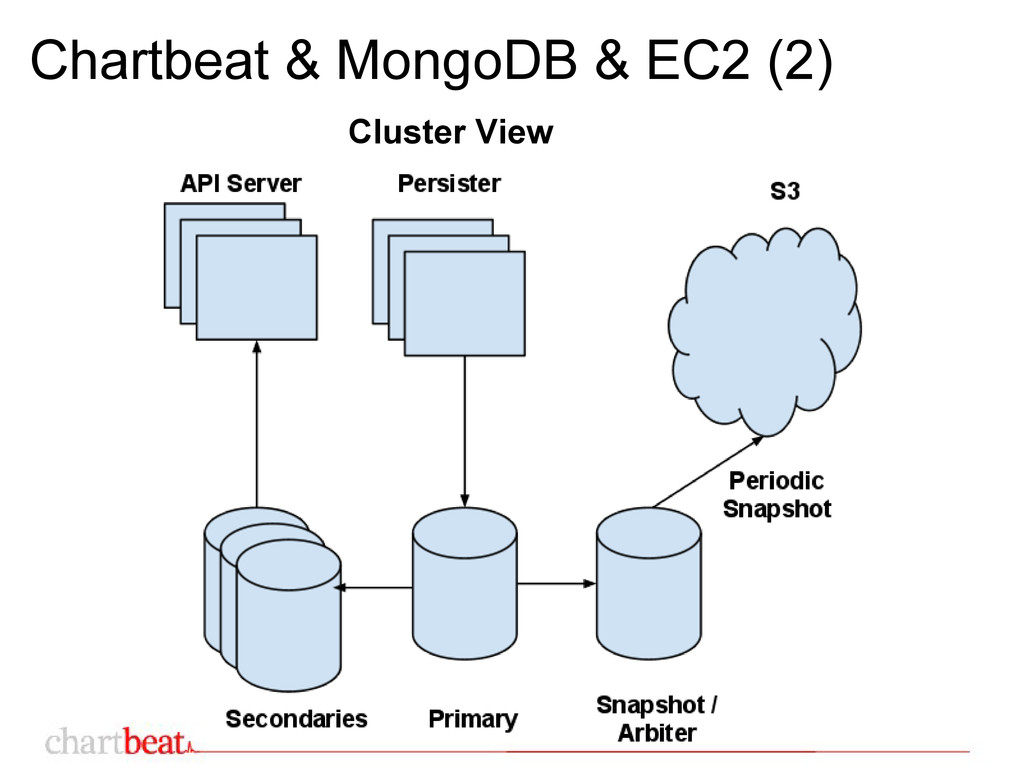
1 for each product ◦ 1 as a caching layer ◦ 2 - 4 instance/cluster • m2-2xlarge ◦ 34.2 GB merory ◦ Ubuntu 10.04 ◦ RAID0 x 4 - 1 TB volumes • Dedicated Snapshot Server ◦ Shared among clusters ◦ Serves as an arbiter as well
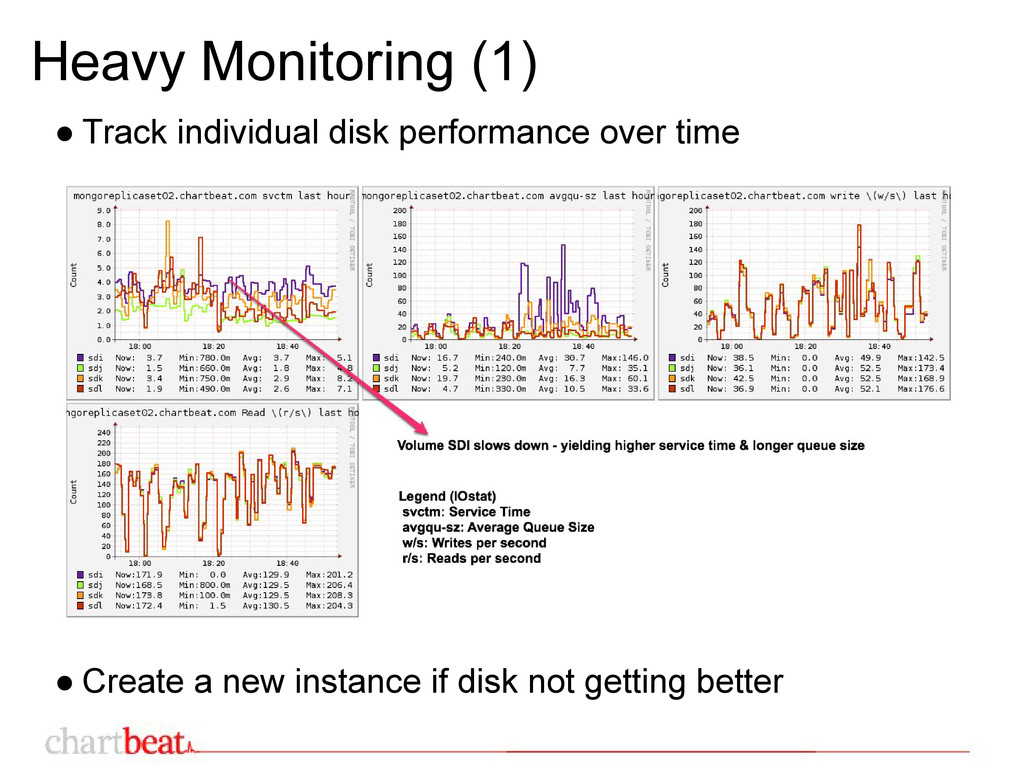
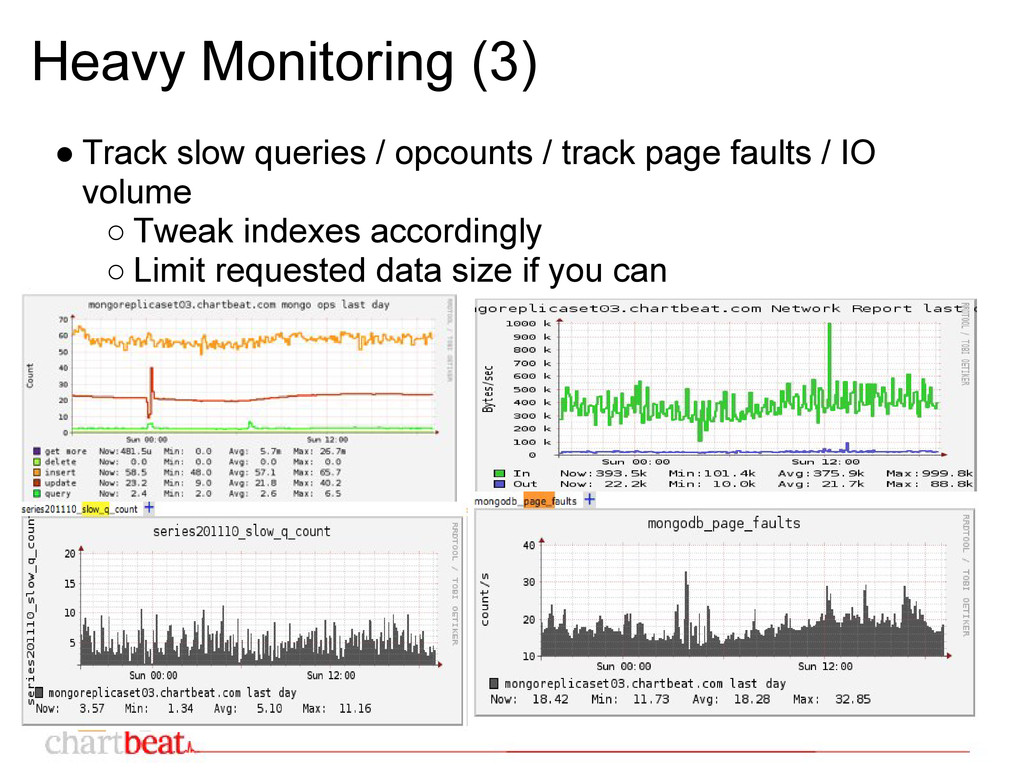
have long recovery operations ◦ MongoDB is (was) not ACID compliant. Unclean shutdown could corrupt your data. • Poor IO performance on EBS ◦ MongoDB has global read/write lock • Variable IO performance on EBS ◦ Could cause replication issues
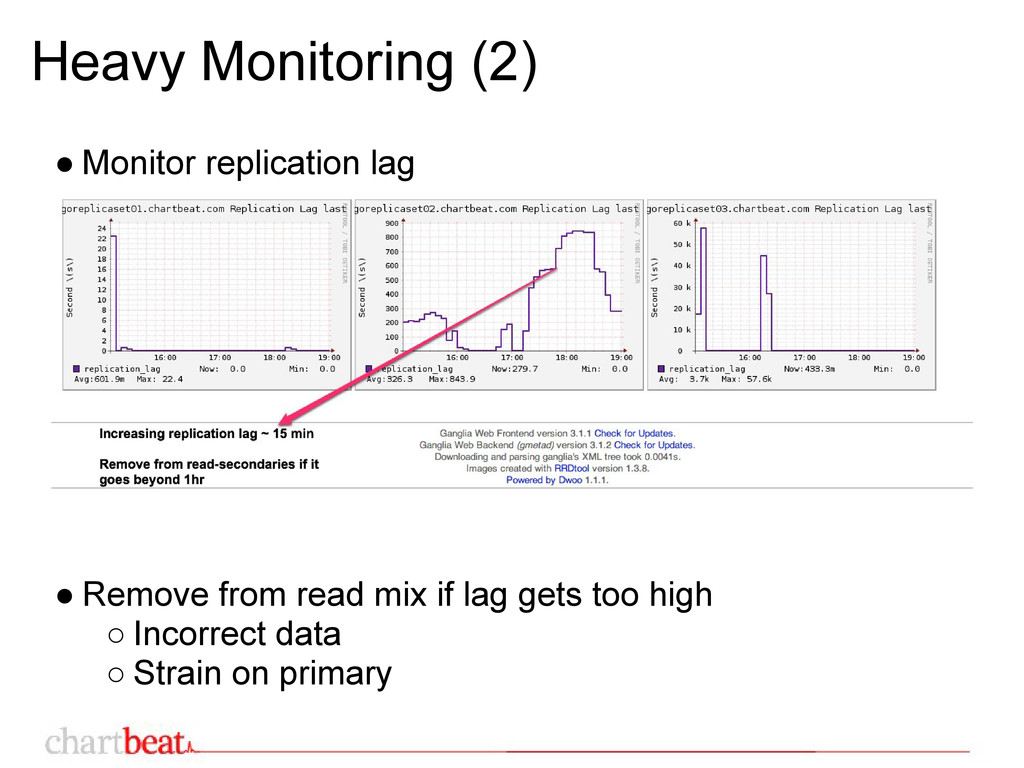
from primary ◦ pymongo 2.1 will fix this • chartbeat pymongo driver ◦ based on MasterSlaveConnection ◦ writes to primary ◦ distribute reads among secondaries ◦ automatic failover ◦ eventual read re-distribution
of life • Always snapshot ◦ Dedicated snapshot server ◦ Hidden, i.e. no reads • Automate everything ◦ puppet ▪ New instance from scratch within a minute ◦ python-boto ▪ Script all EC2 interaction ▪ new_instance.py ▪ mount_volumes_from_snap.py -o iid -n iid ▪ snapshot_mongo.py
EBS loads blocks lazily • Warm up EBS & File Cache before use ◦ Options ▪ Slowly direct the reads (app by app) ▪ Run cache warm-up scripts ◦ Not automated currently
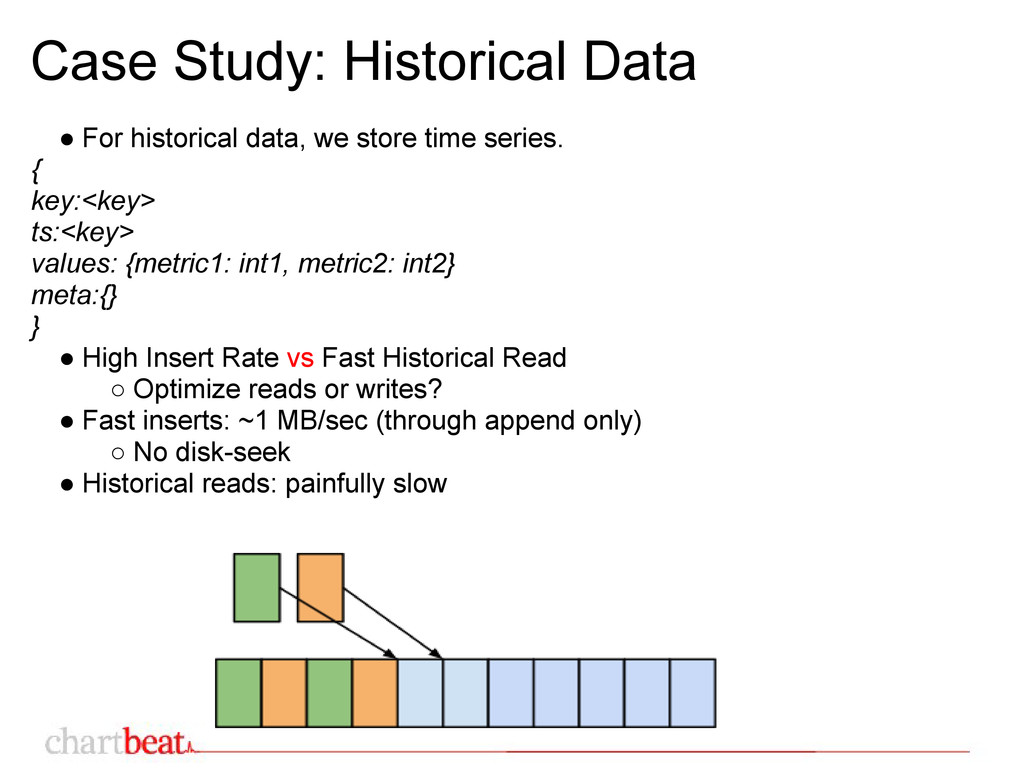
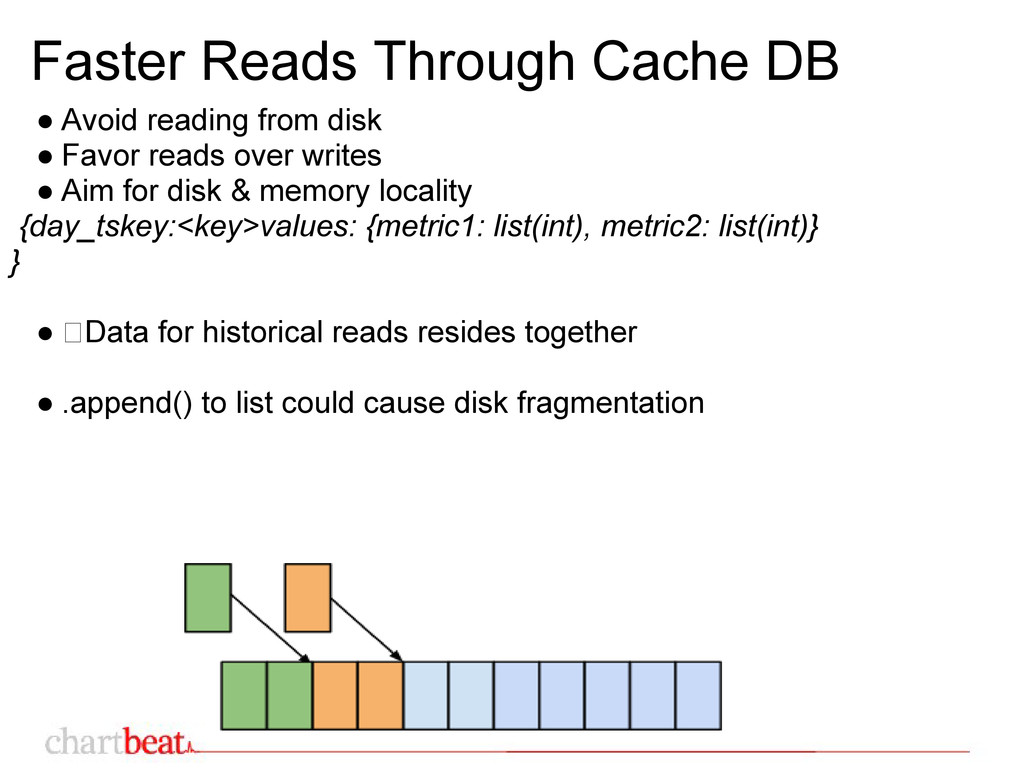
• Favor reads over writes • Aim for disk & memory locality {day_tskey:<key>values: {metric1: list(int), metric2: list(int)} } • Data for historical reads resides together • .append() to list could cause disk fragmentation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}