Автоматизация контент-фильтрации на pythondigest.ru
Решим задачу классификации в приложении к материалам о языке Python: научимся отличать пригодный к публикации контент от плохого с помощью методов машинного обучения.
как можно выше • learning_rate - вклад каждого отдельного дерева • понижаем при повышении n_estimators • max_depth - глубина дерева • Чем выше - тем более нелинейные отношения можем смоделировать
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
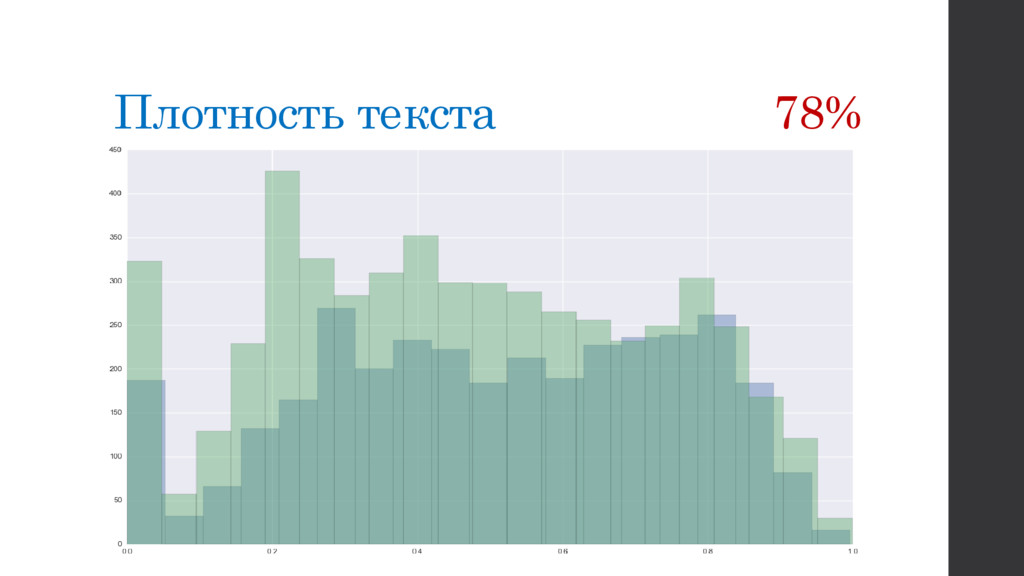{kind=link}
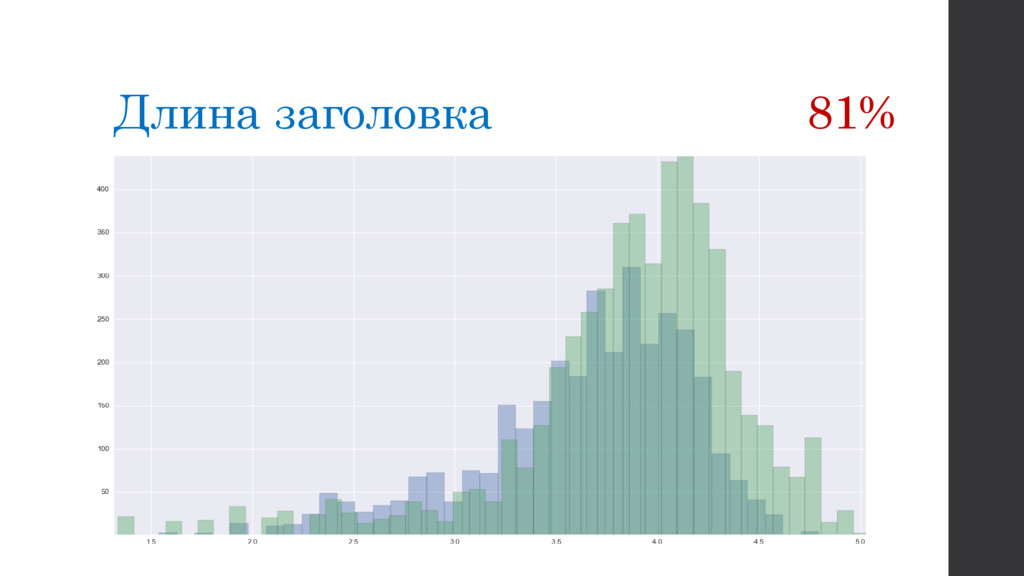{kind=link}
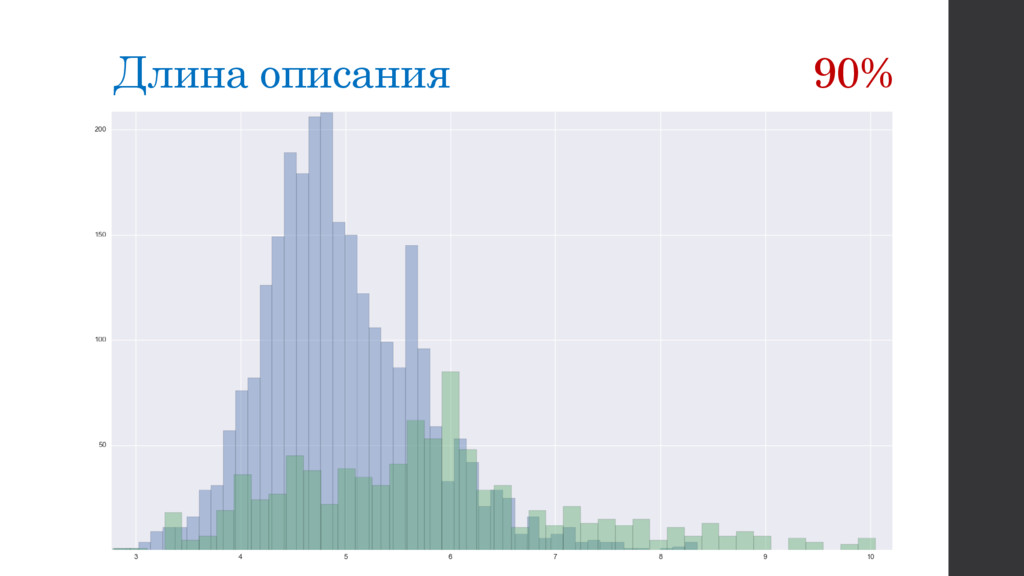{kind=link}
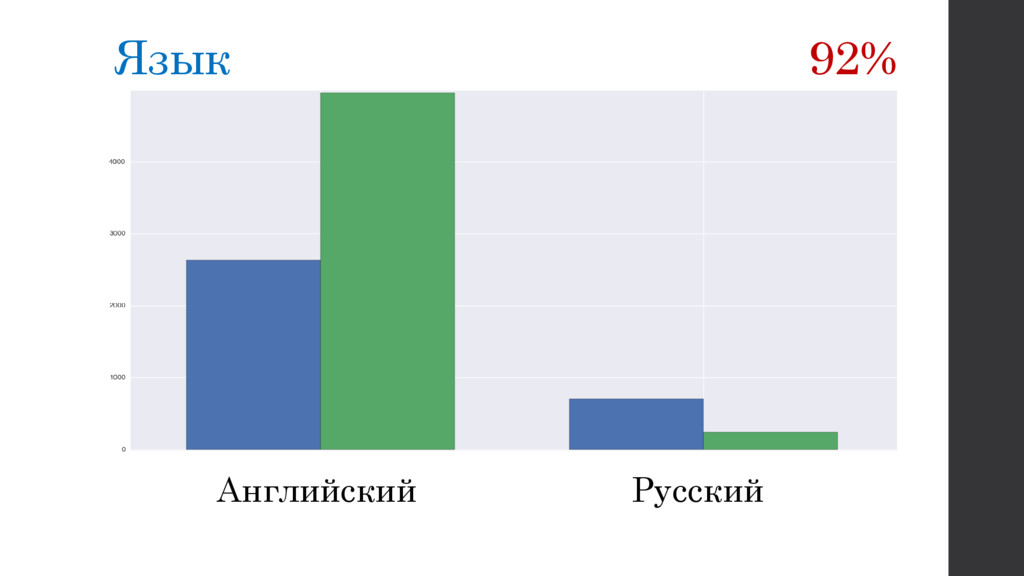{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Андрей Киселев [email protected] github.com/kiselev1189/pydigest-classifier](https://files.speakerdeck.com/presentations/bc20ed3fc7494a3292091200ad479e54/slide_34.jpg){kind=link}