Про то, как структурировать метрики прометея в коде, выстроить удобные абстракции. Как меняется парадигма при переходе со statsd на прометей. Подводные камни при работе с прометеем.
Видео: https://moscowpython.ru/meetup/88/statsd-to-prometheus/
Moscow Python: http://moscowpython.ru
Курсы Learn Python: http://learn.python.ru
Moscow Python Podcast: http://podcast.python.ru
Заявки на доклады: https://bit.ly/mp-speaker
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
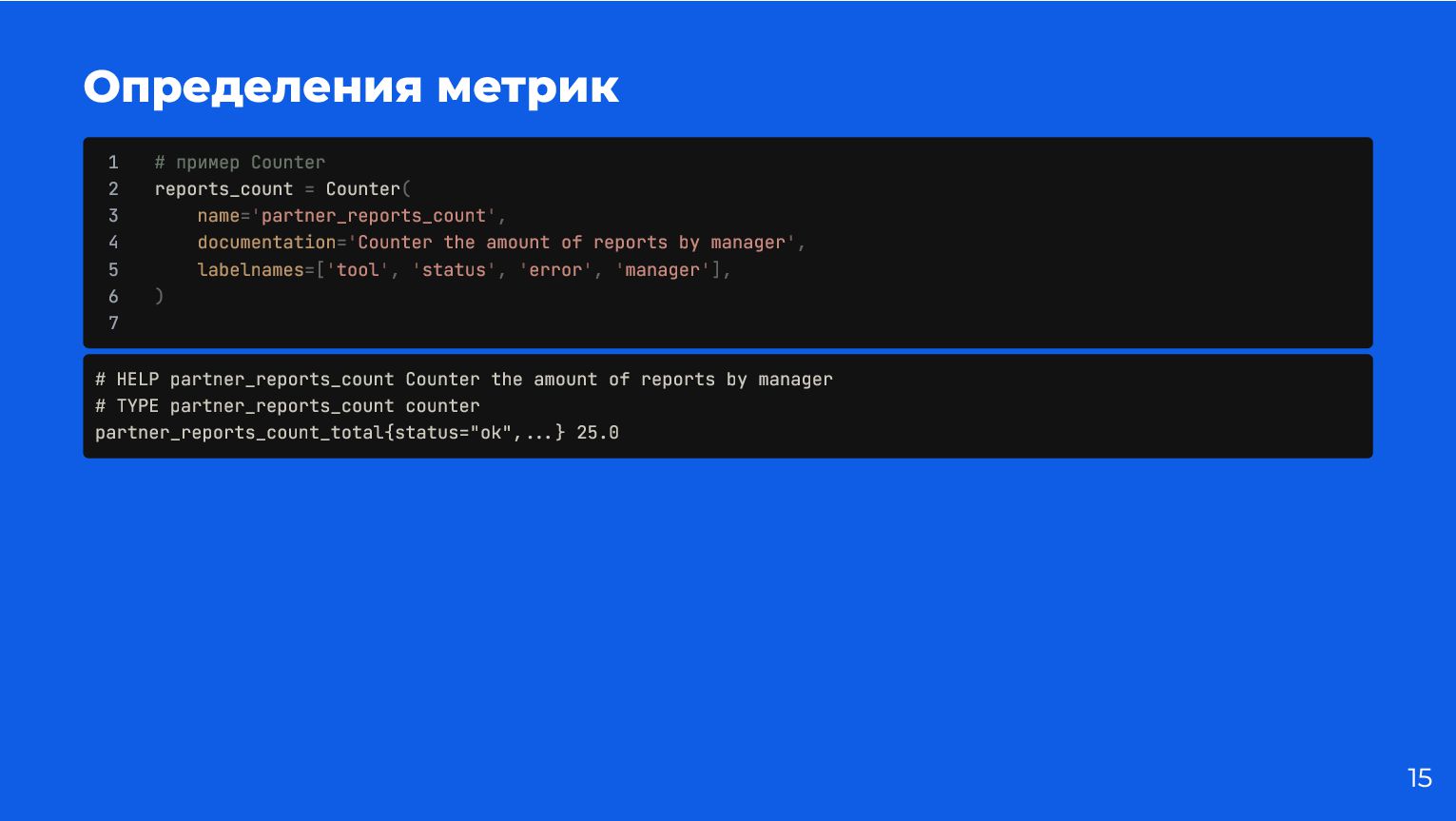{kind=link}
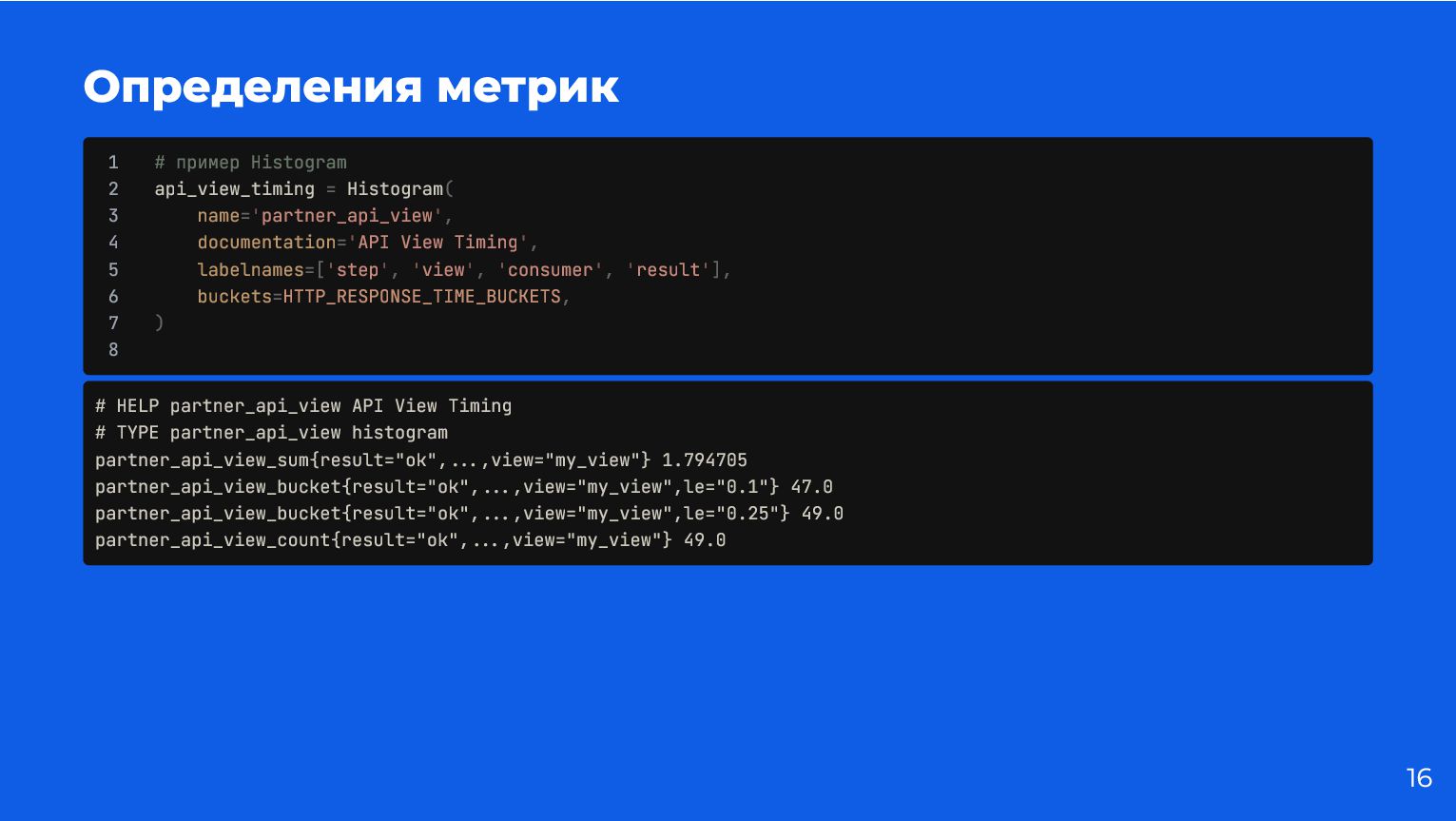{kind=link}
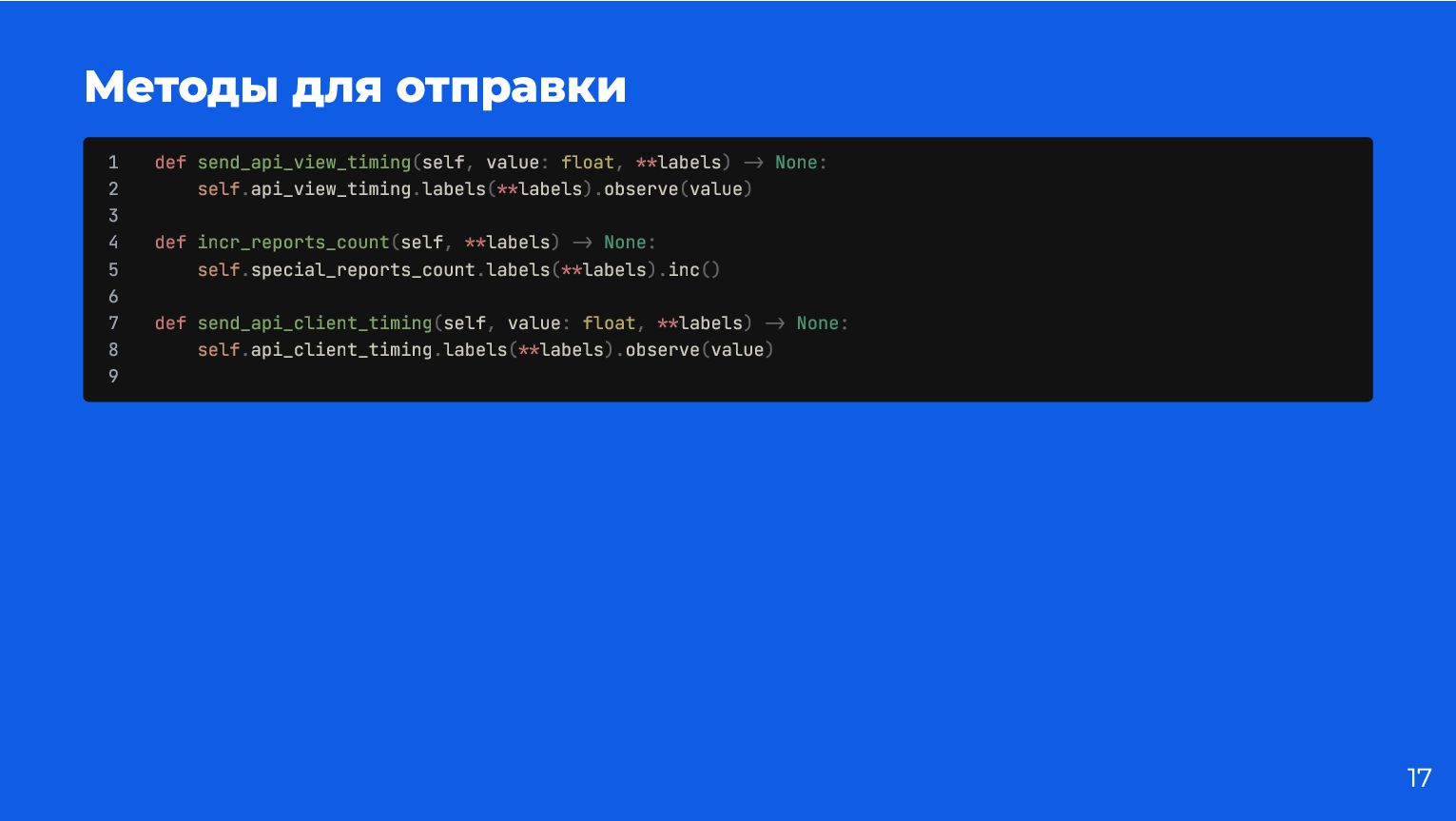{kind=link}
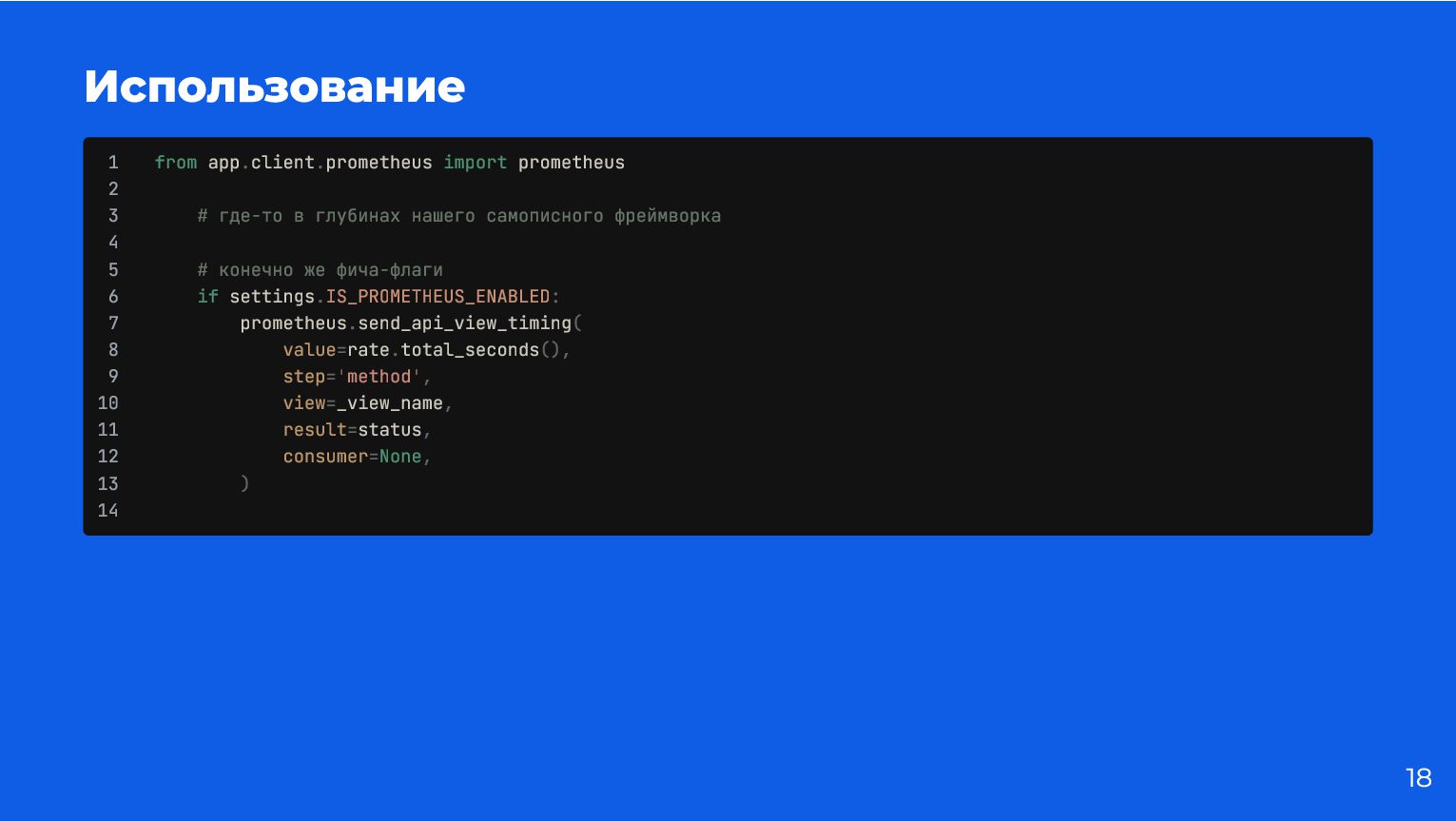{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}