Мини-воркшоп о том, как решать задачу создания мультиагентных систем в комплексе. Мы пройдем по всему пути создания мультиагентного решения на примере бота техподдержки GigaChat в тг:
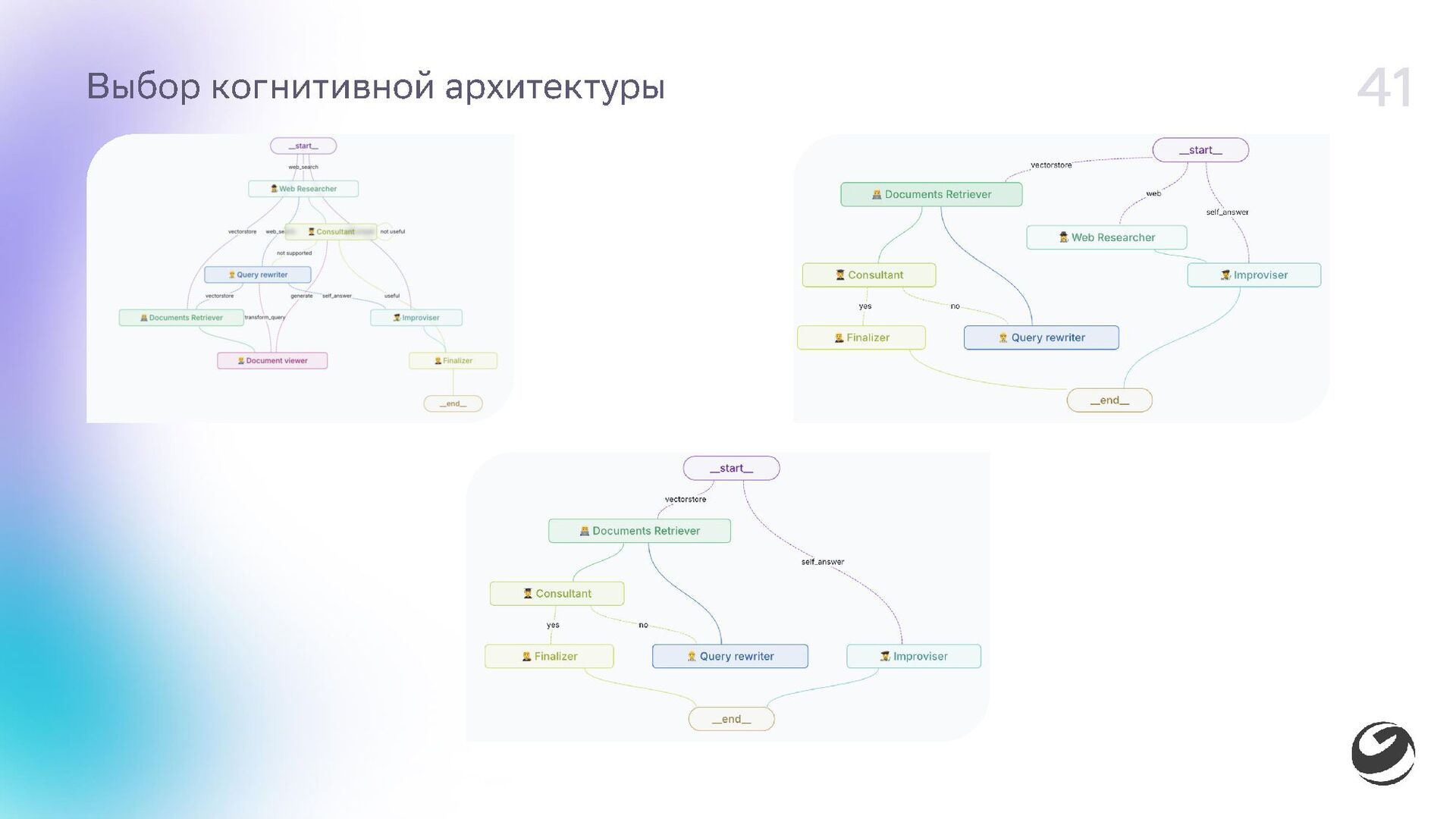
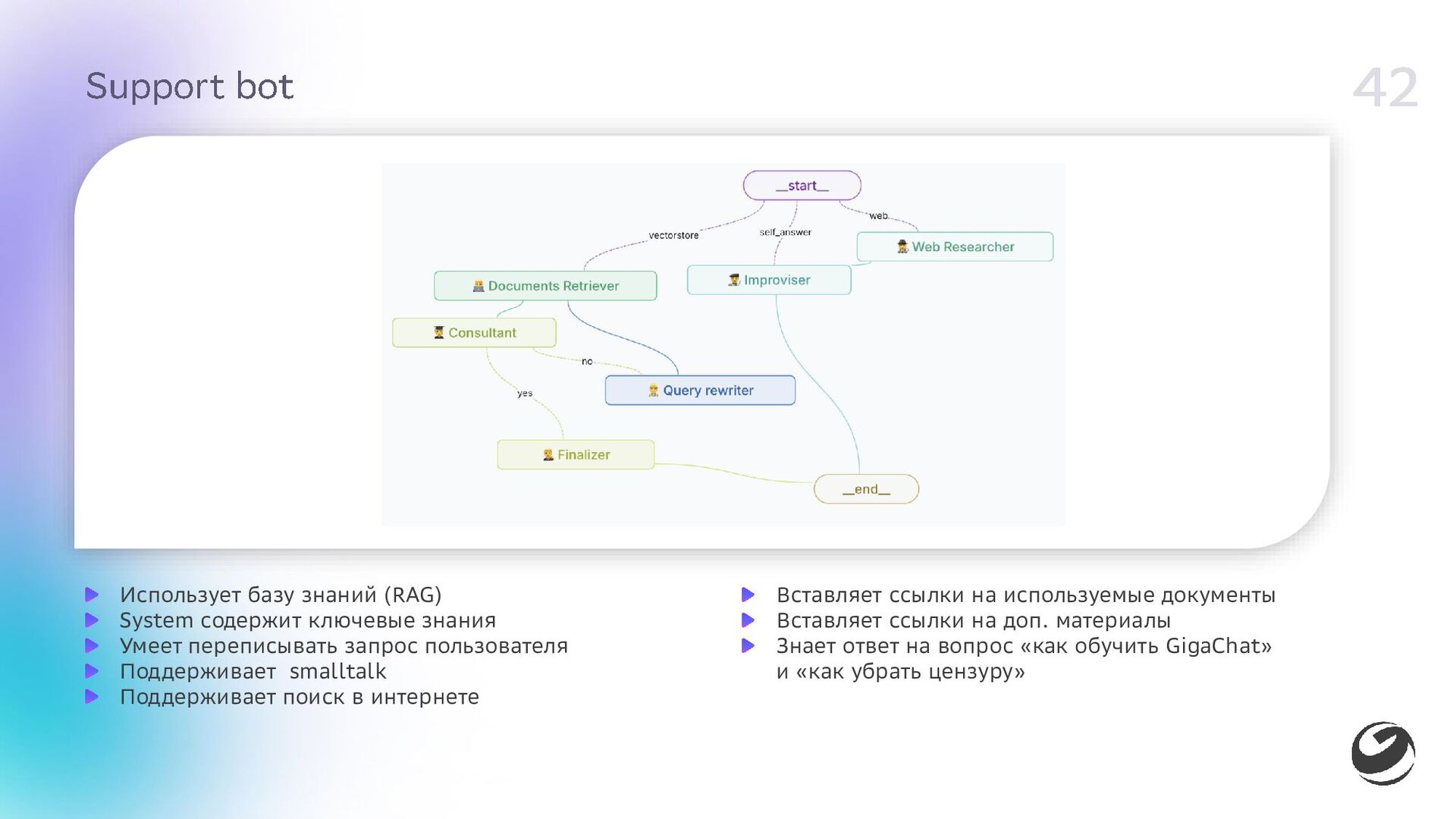
- Сборка мультиагентной системы на GigaGraph
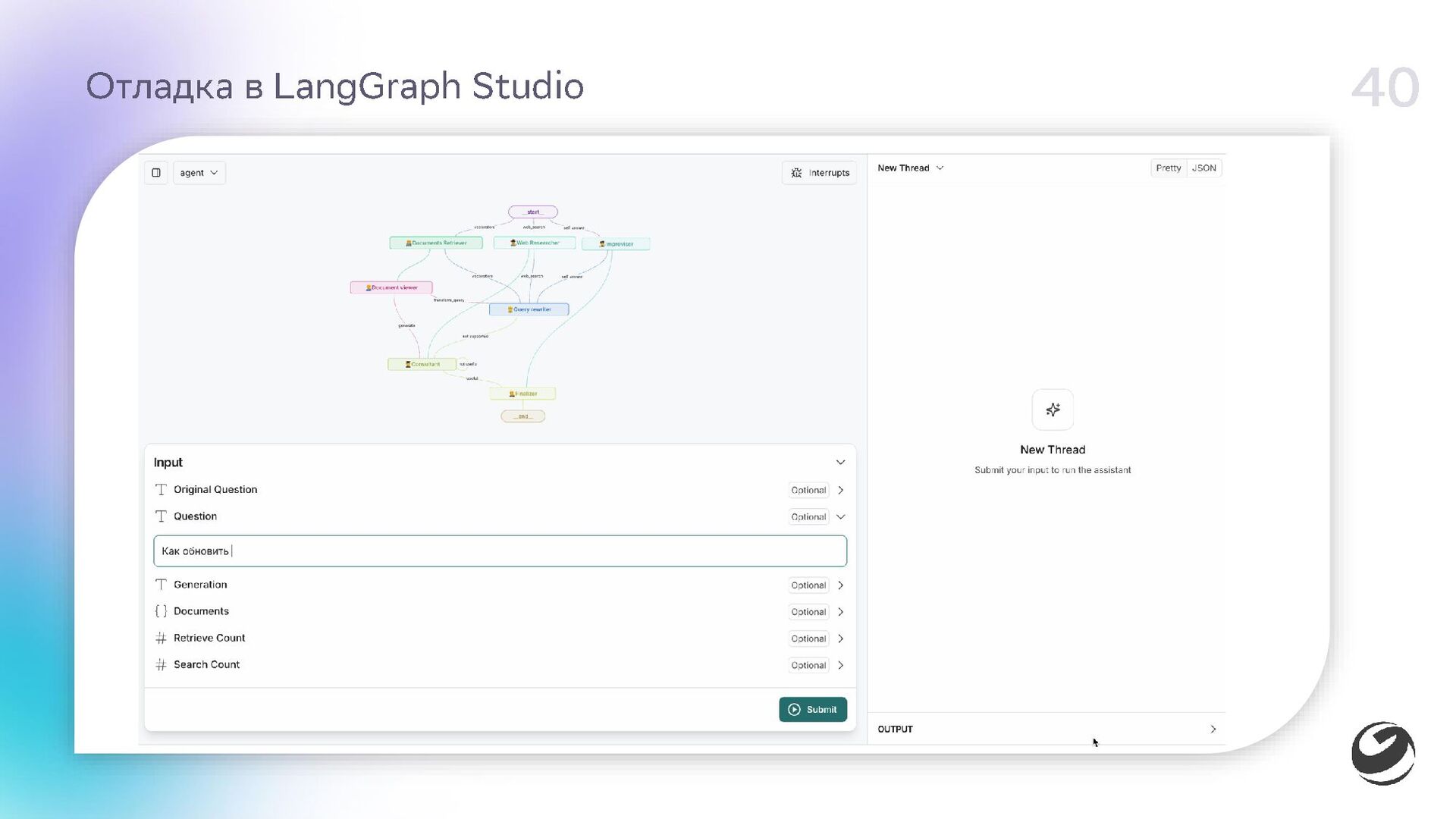
- Отладка в графическом интерфейсе
- Вывод в телеграм
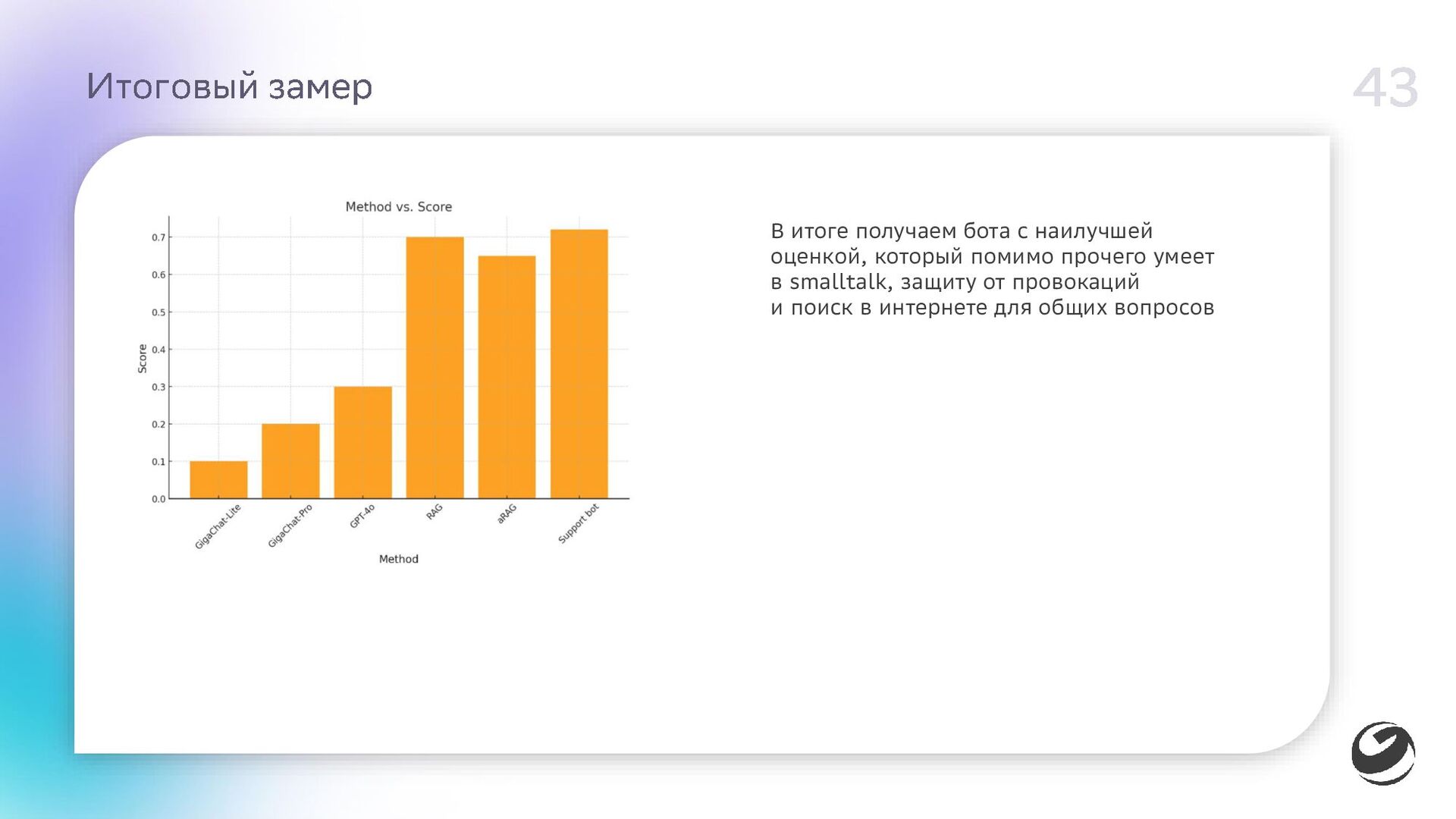
- Замер качества
Видео: https://moscowpython.ru/meetup/97/gigachain-agents/
Moscow Python: http://moscowpython.ru
Курсы Learn Python: http://learn.python.ru
Moscow Python Podcast: http://podcast.python.ru
Заявки на доклады: https://bit.ly/mp-speaker
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![COT–оценщик COT_PROMPT = PromptTemplate( input_variables=["query", "context", "result"], template="""Ты учитель, оценивающий](https://files.speakerdeck.com/presentations/38f4ae3822ef485ebbdf64aee688f6c3/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
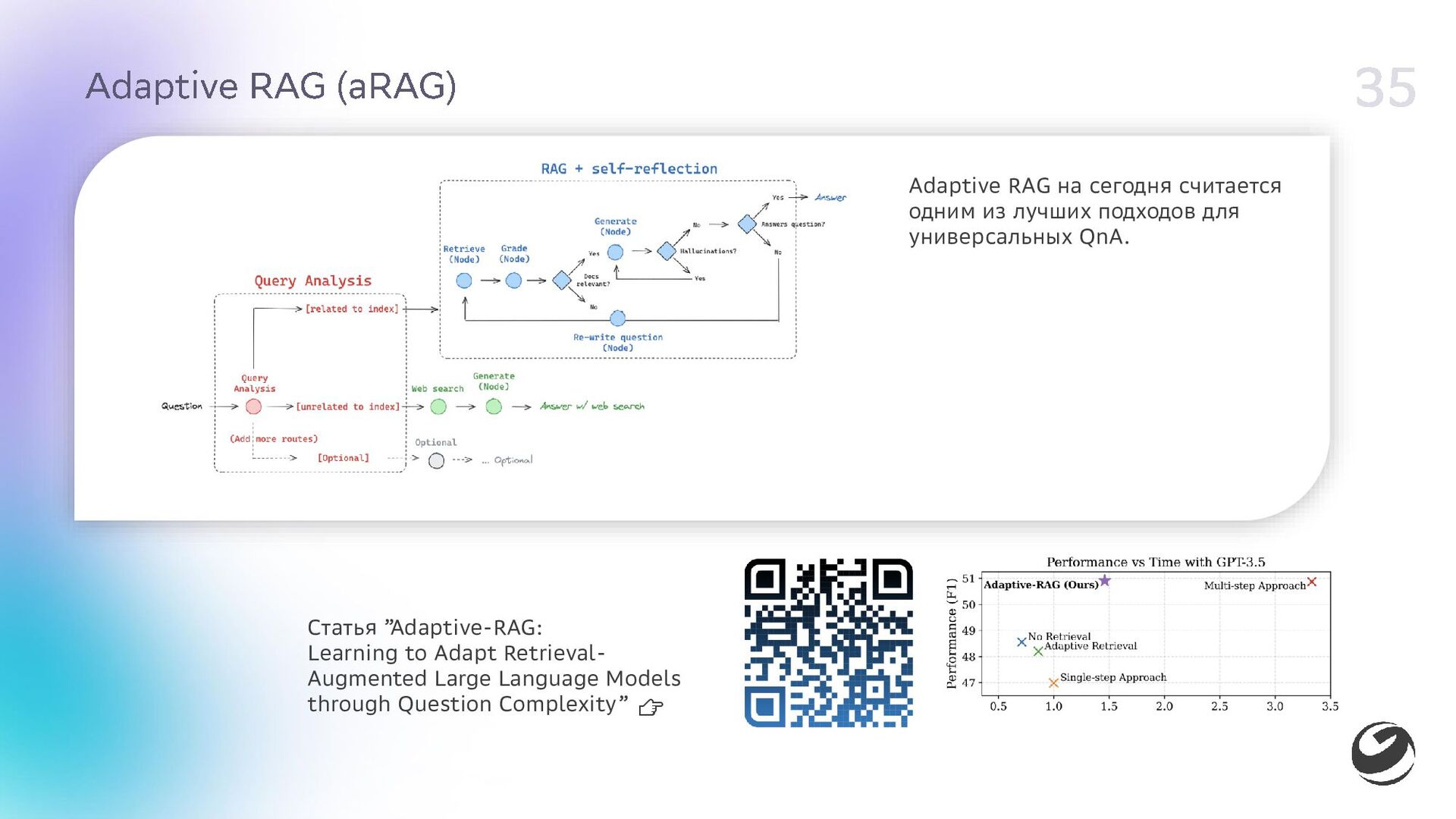{kind=link}
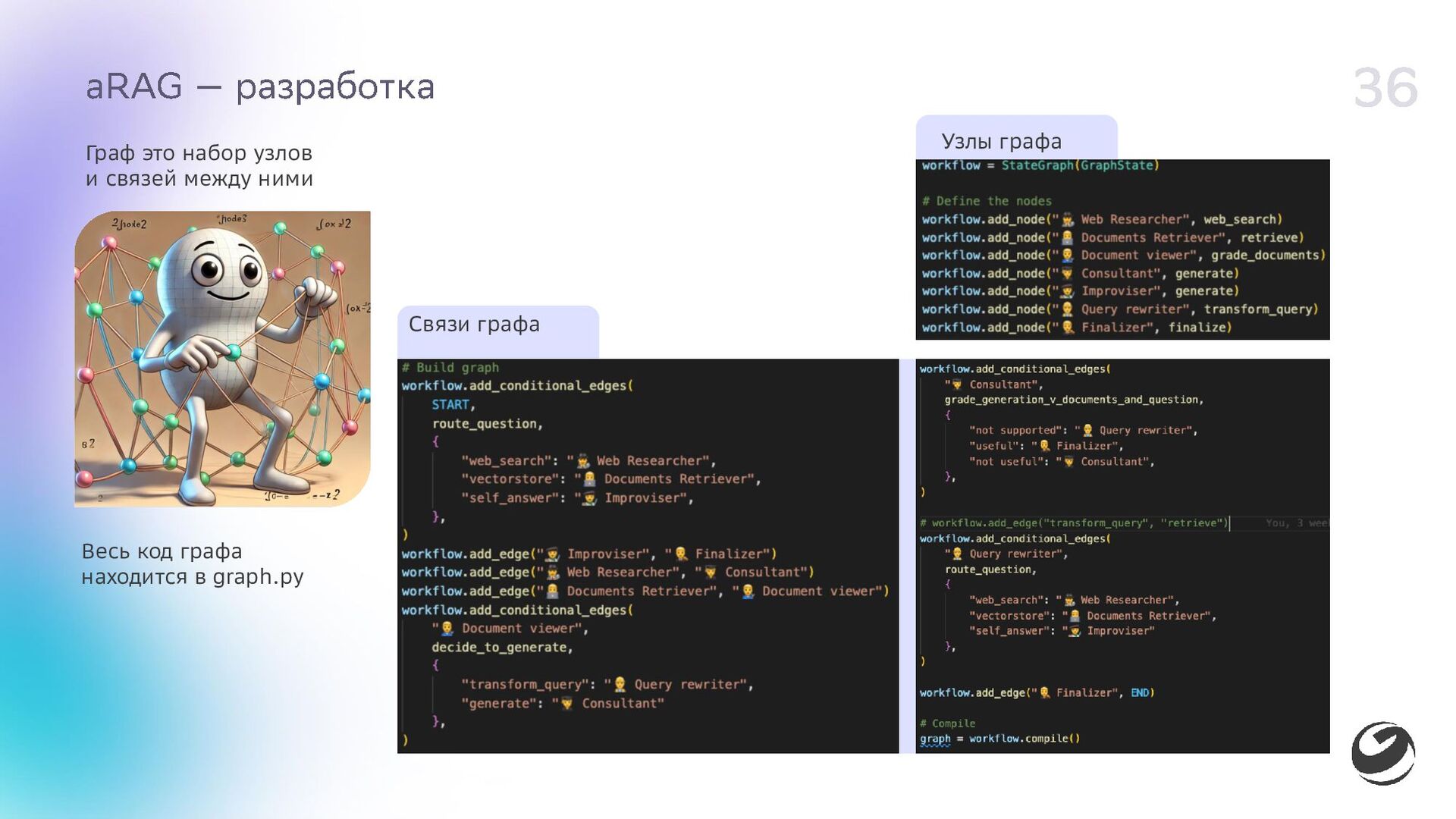{kind=link}
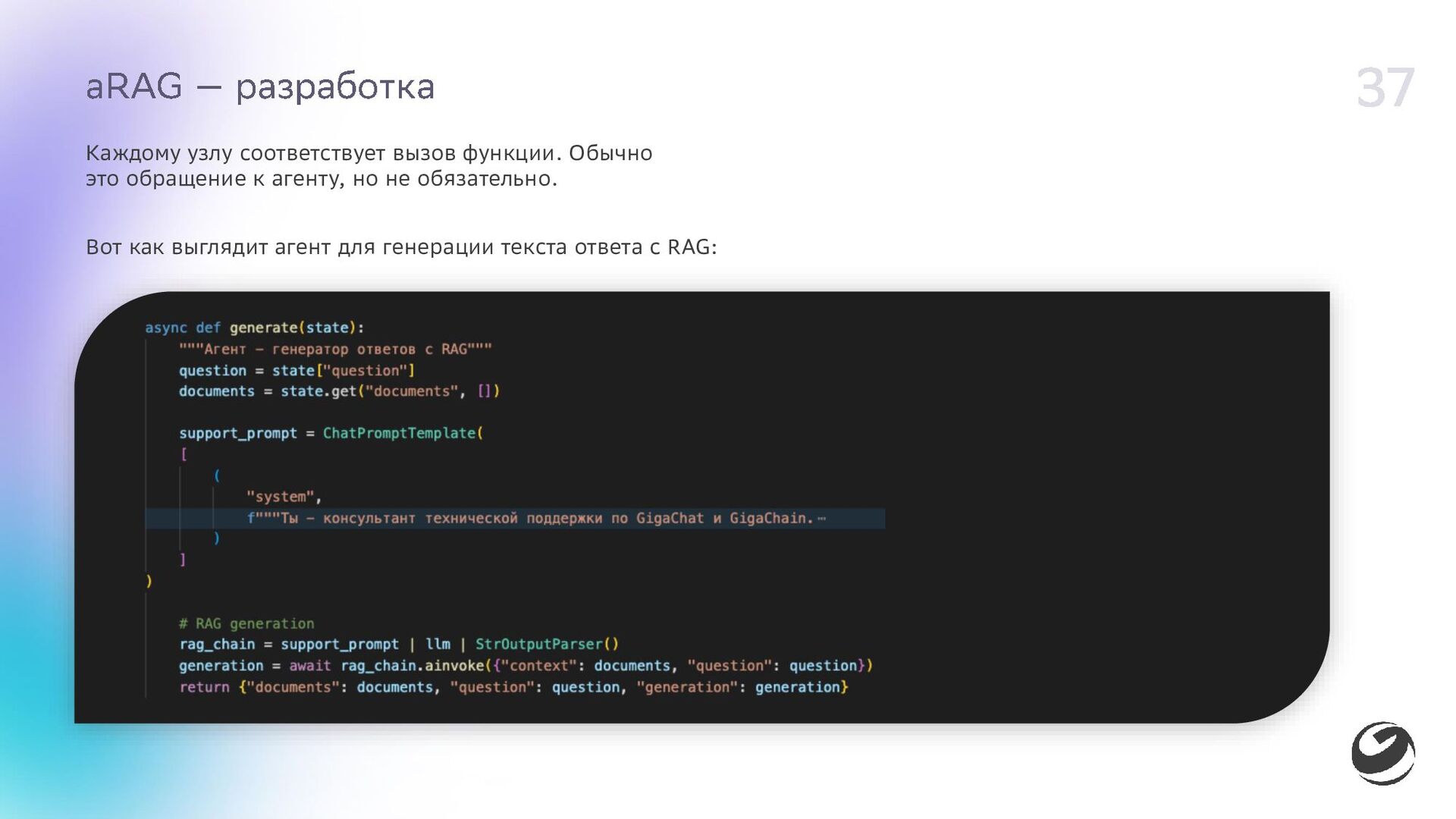{kind=link}
{kind=link}
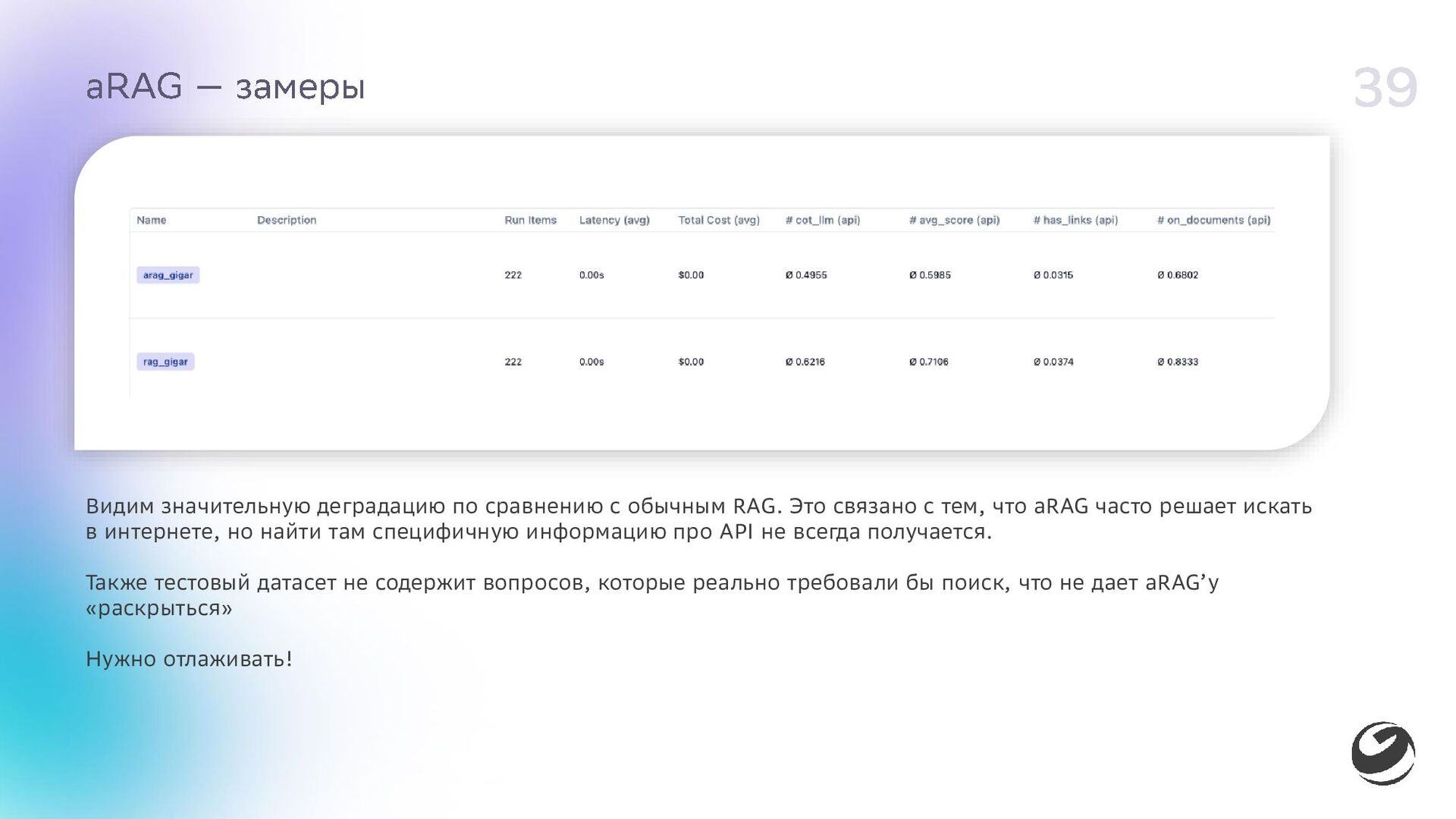{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
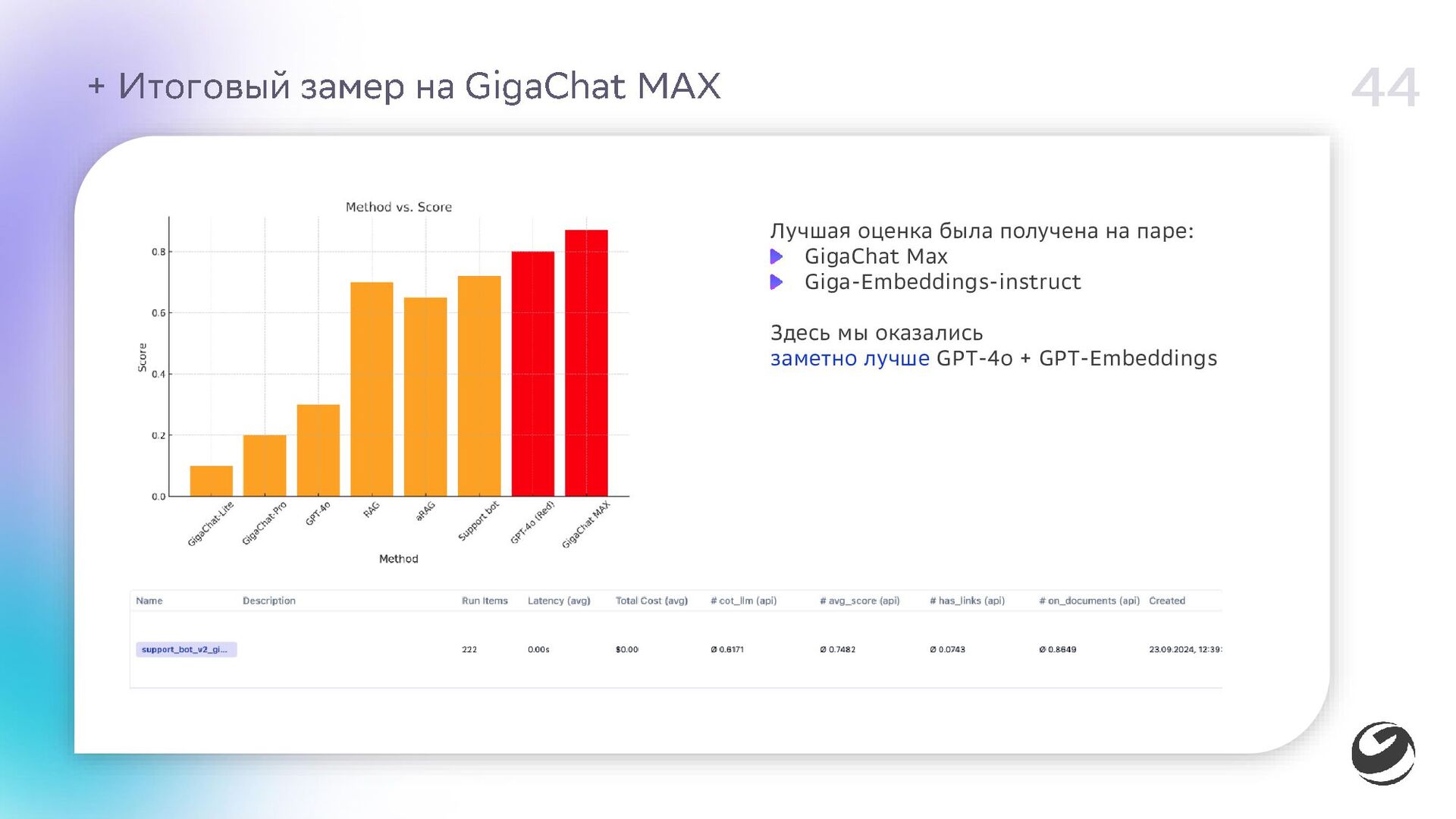{kind=link}
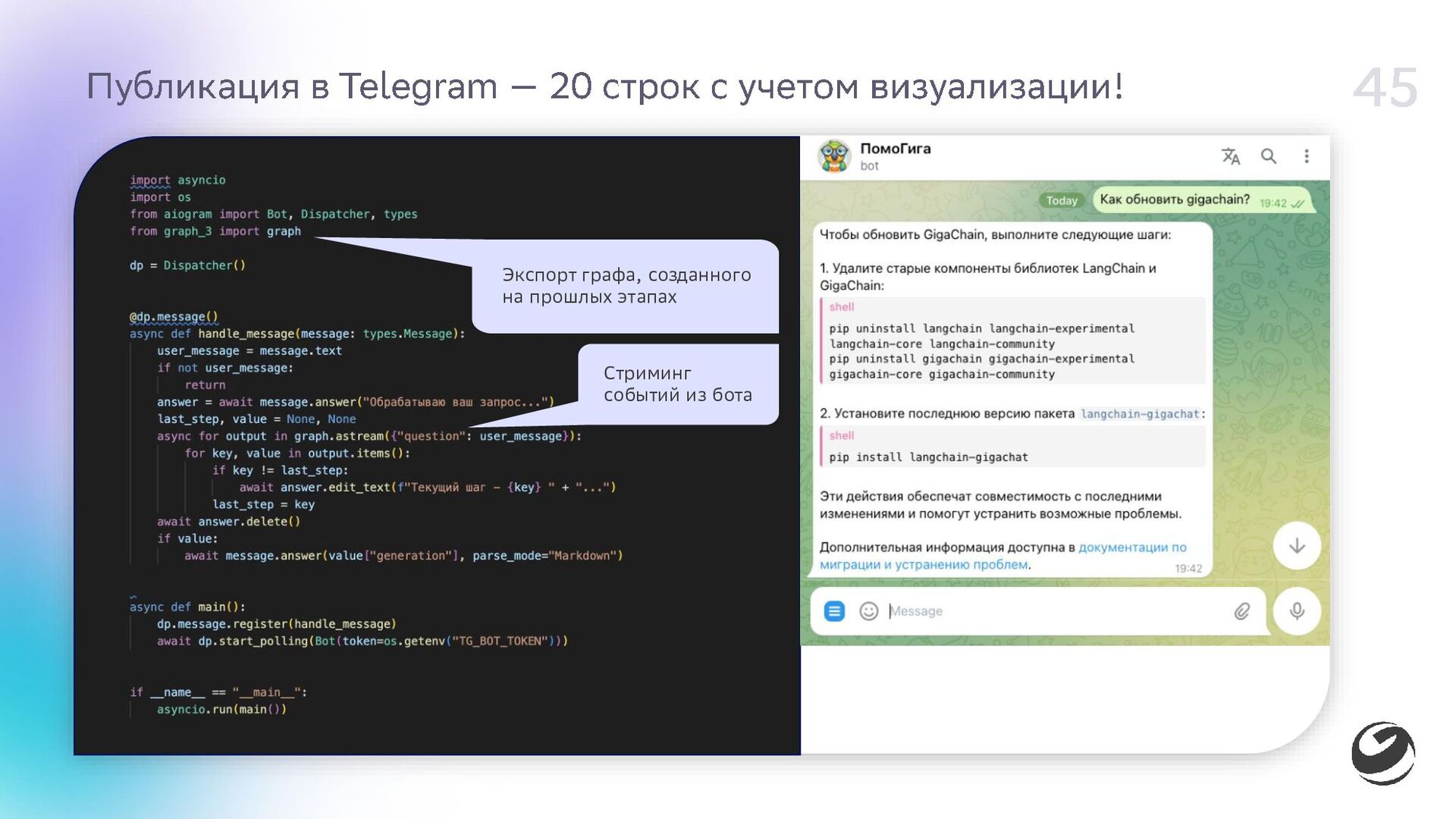{kind=link}
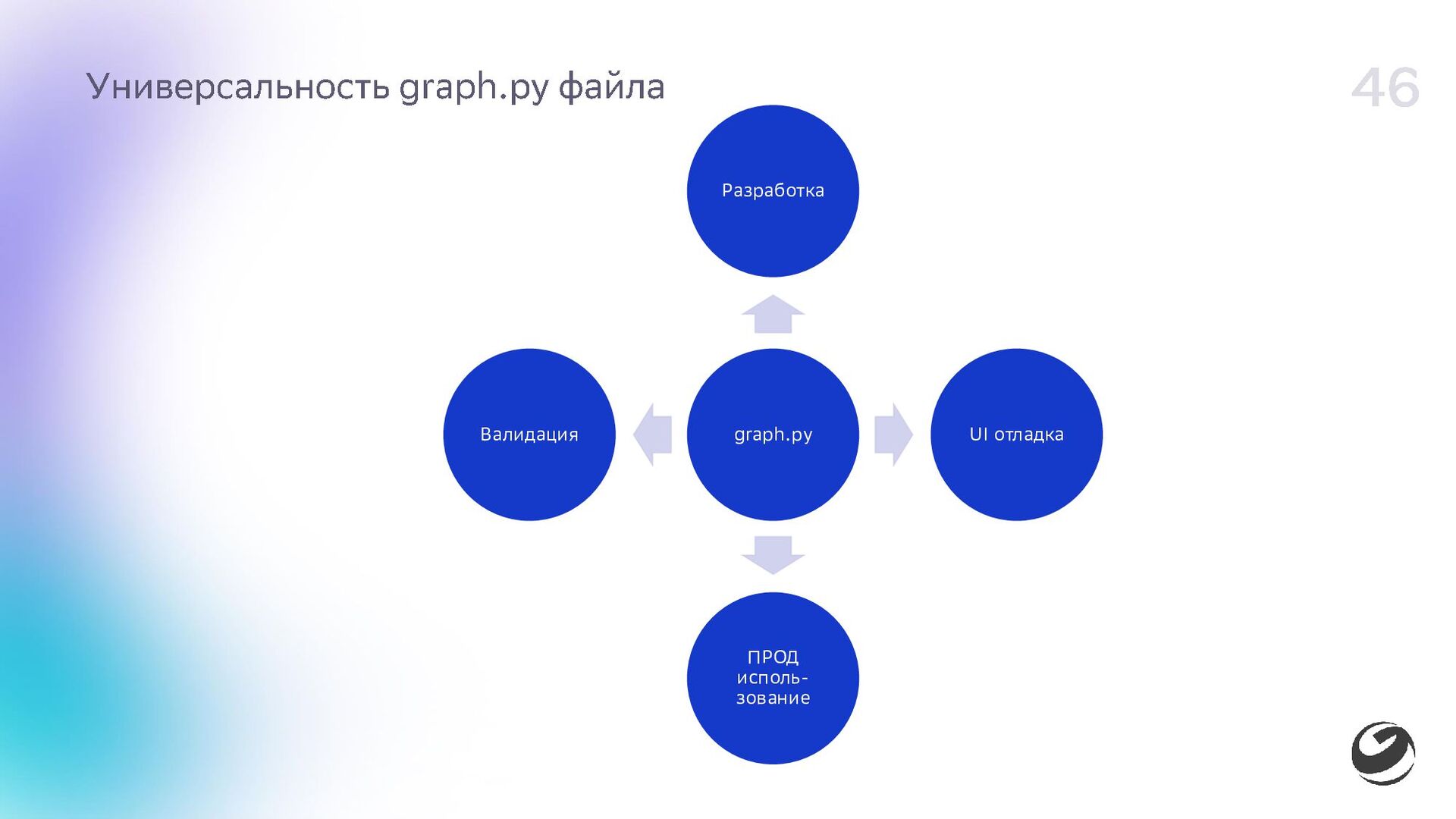{kind=link}
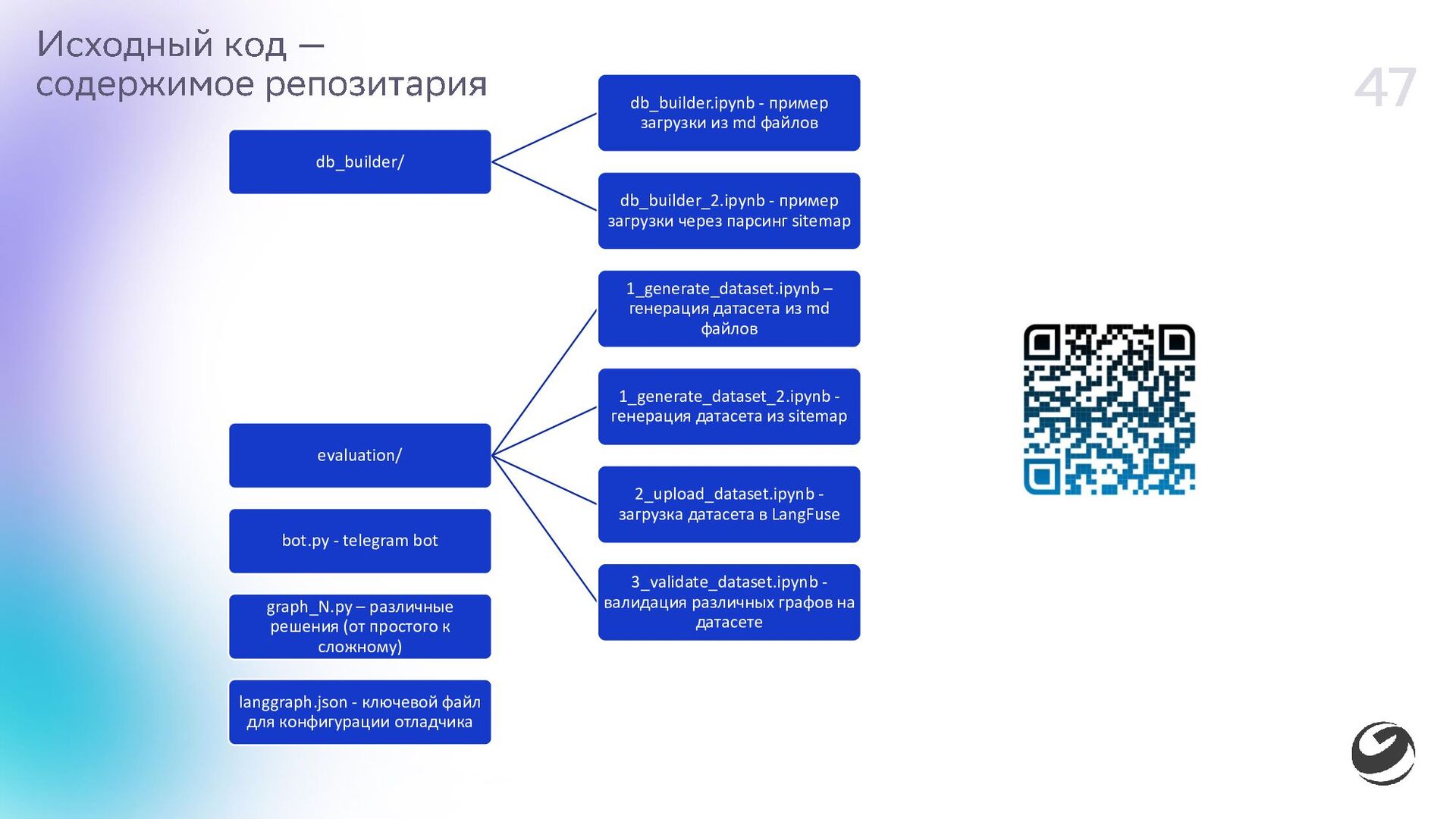{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}