本資料はGO のデータ基盤の全容と実践的なデータ活用事例を紹介しています。
具体的には、以下の7つの工夫点を紹介しています。
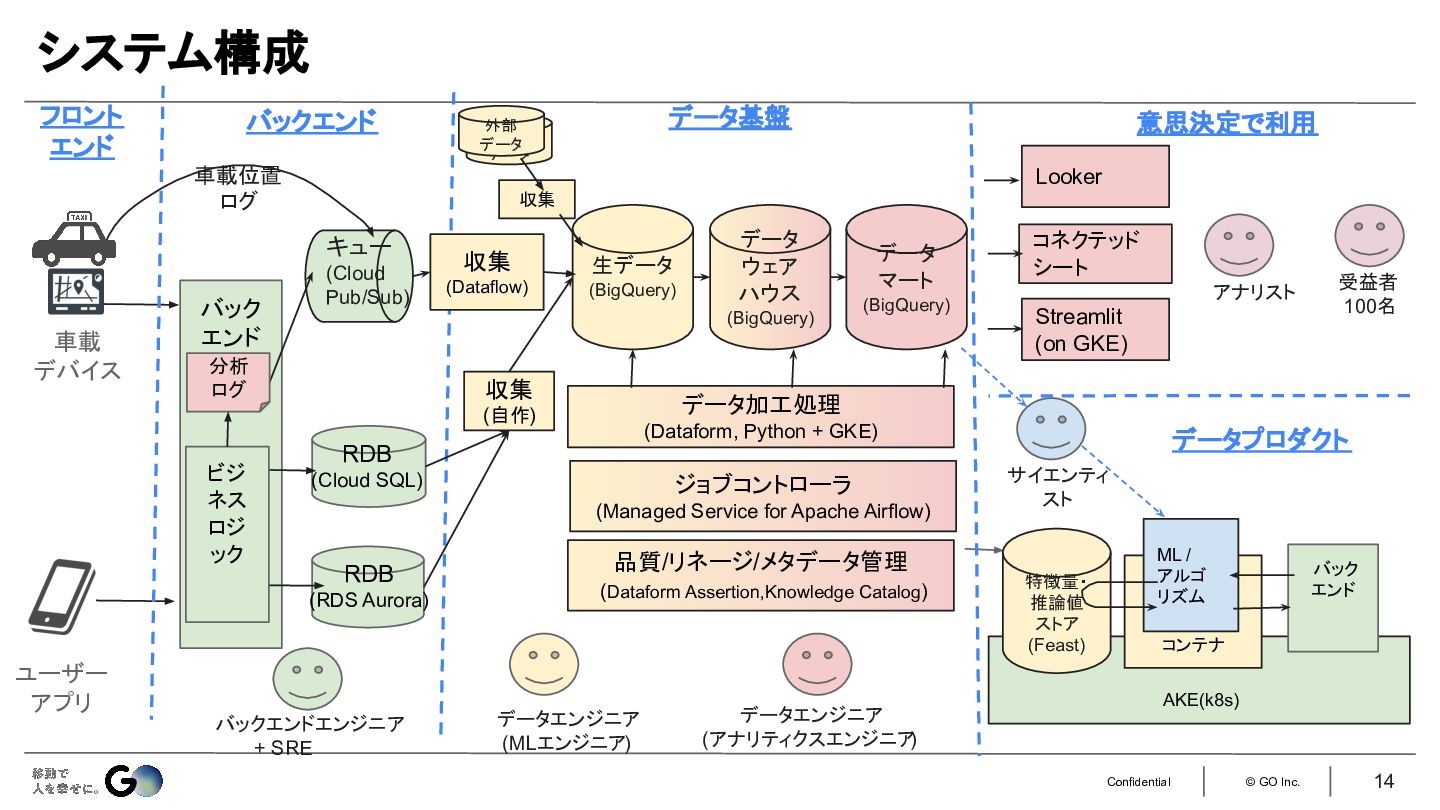
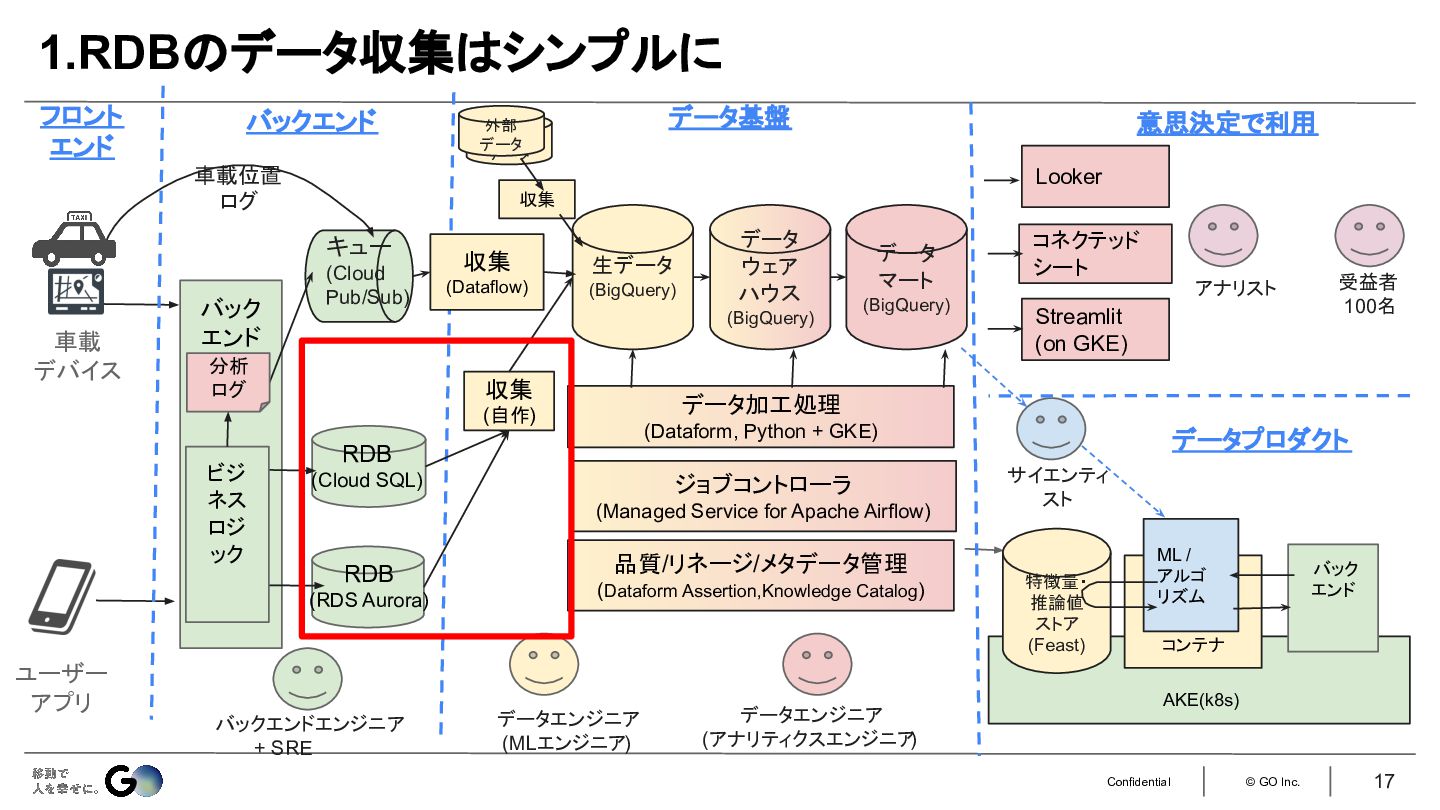
1.RDBのデータ収集はシンプルに。難しいCDCはやらない。
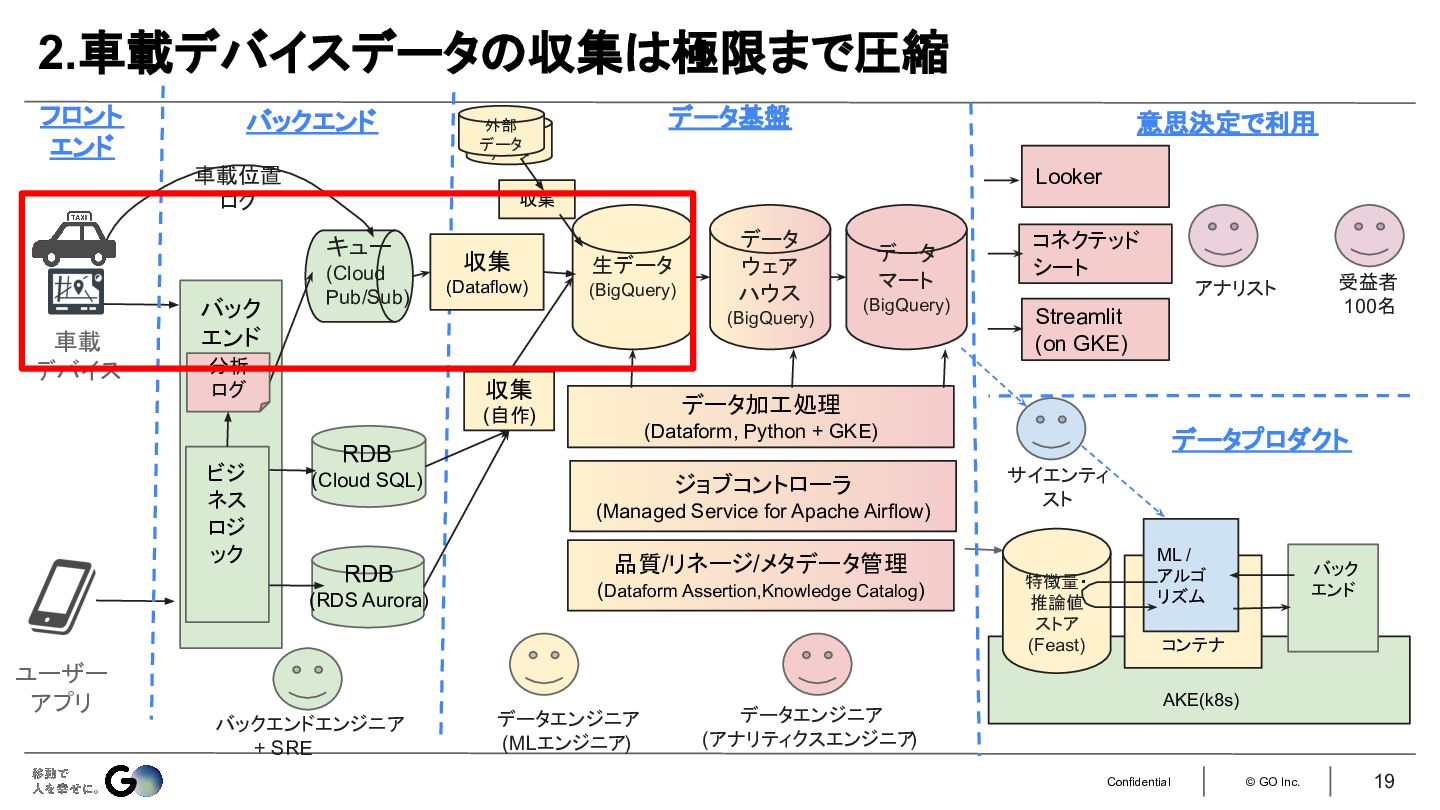
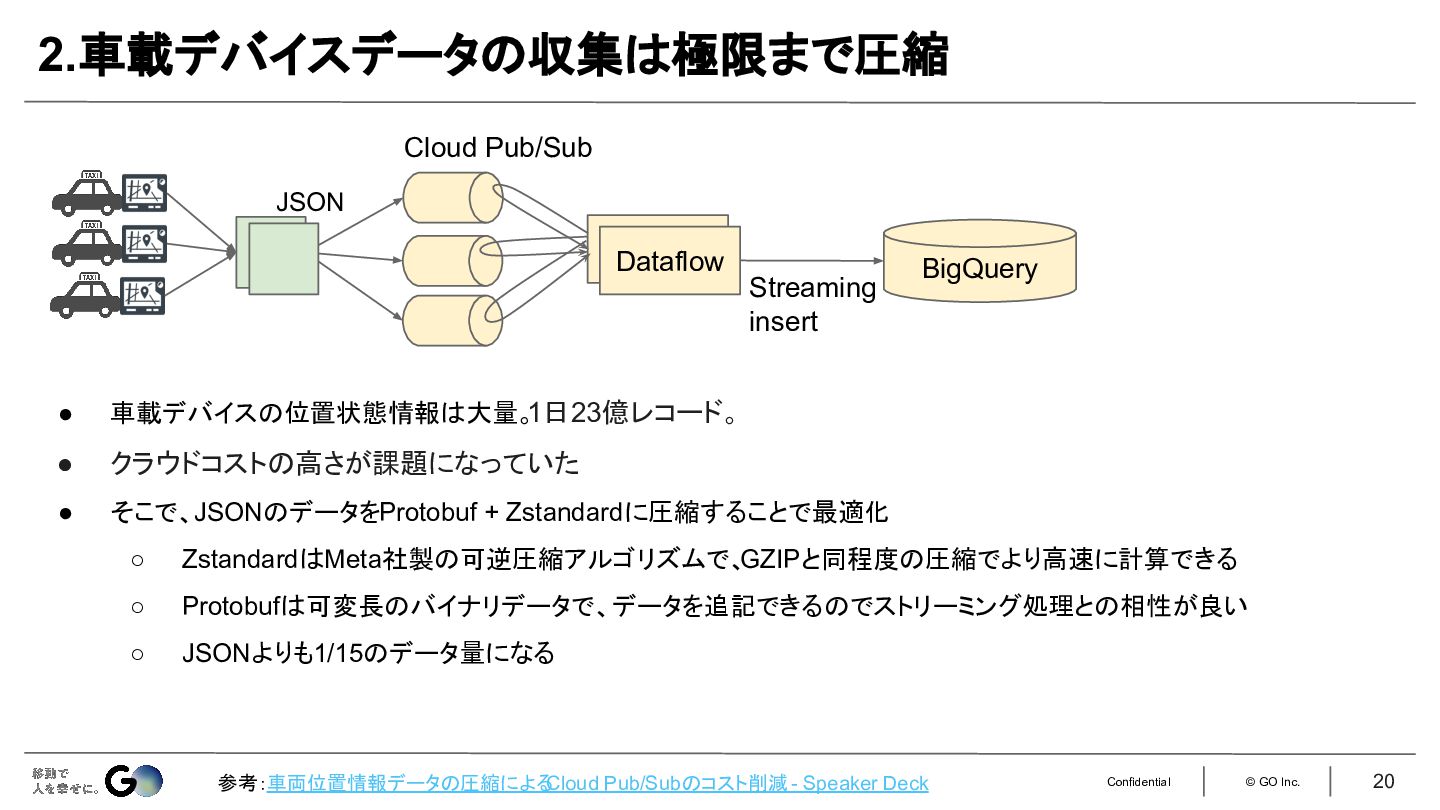
2.車載デバイスのデータはProtobuf + Zstandardで極限まで圧縮して扱う。
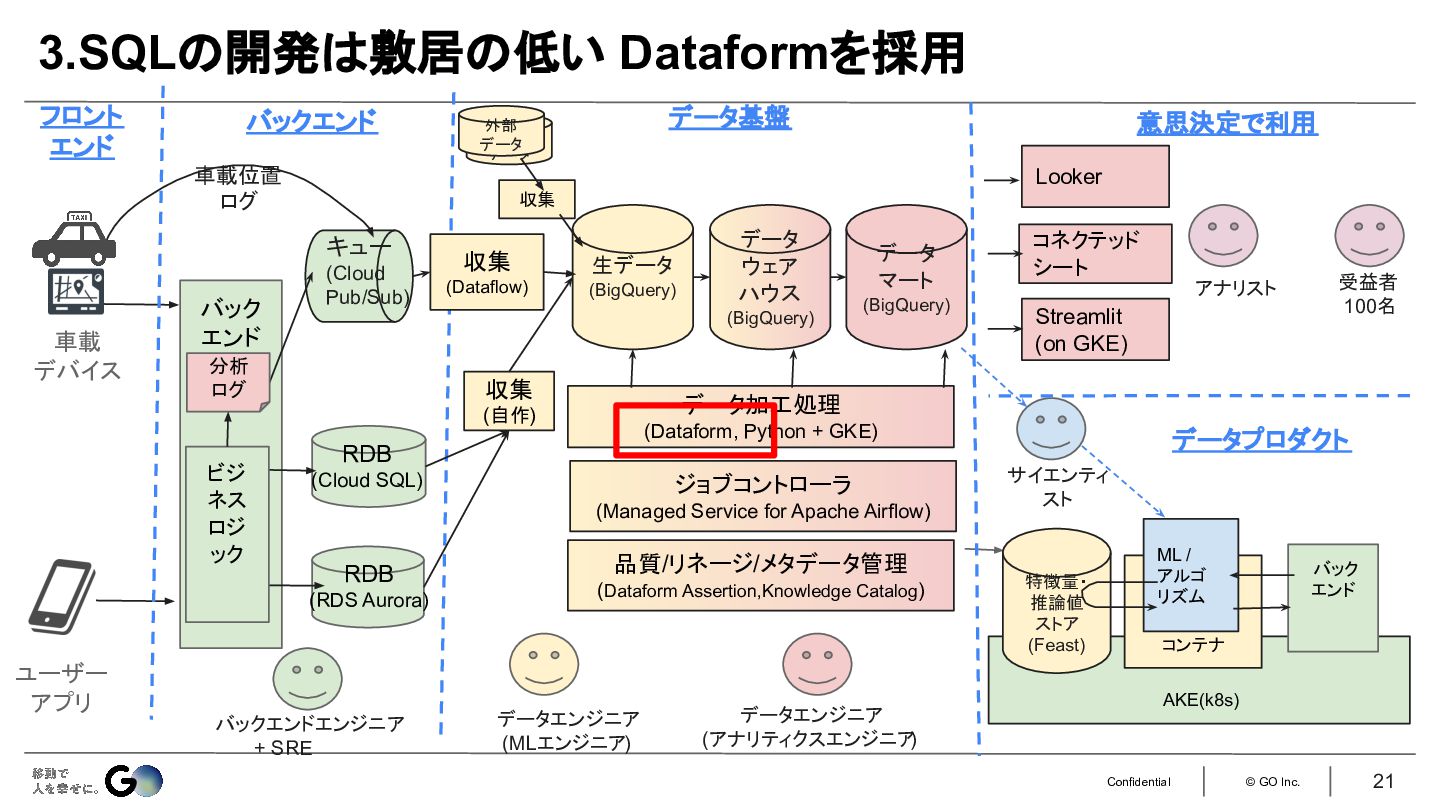
3.SQLの開発はdbtではなく敷居の低いDataformを採用
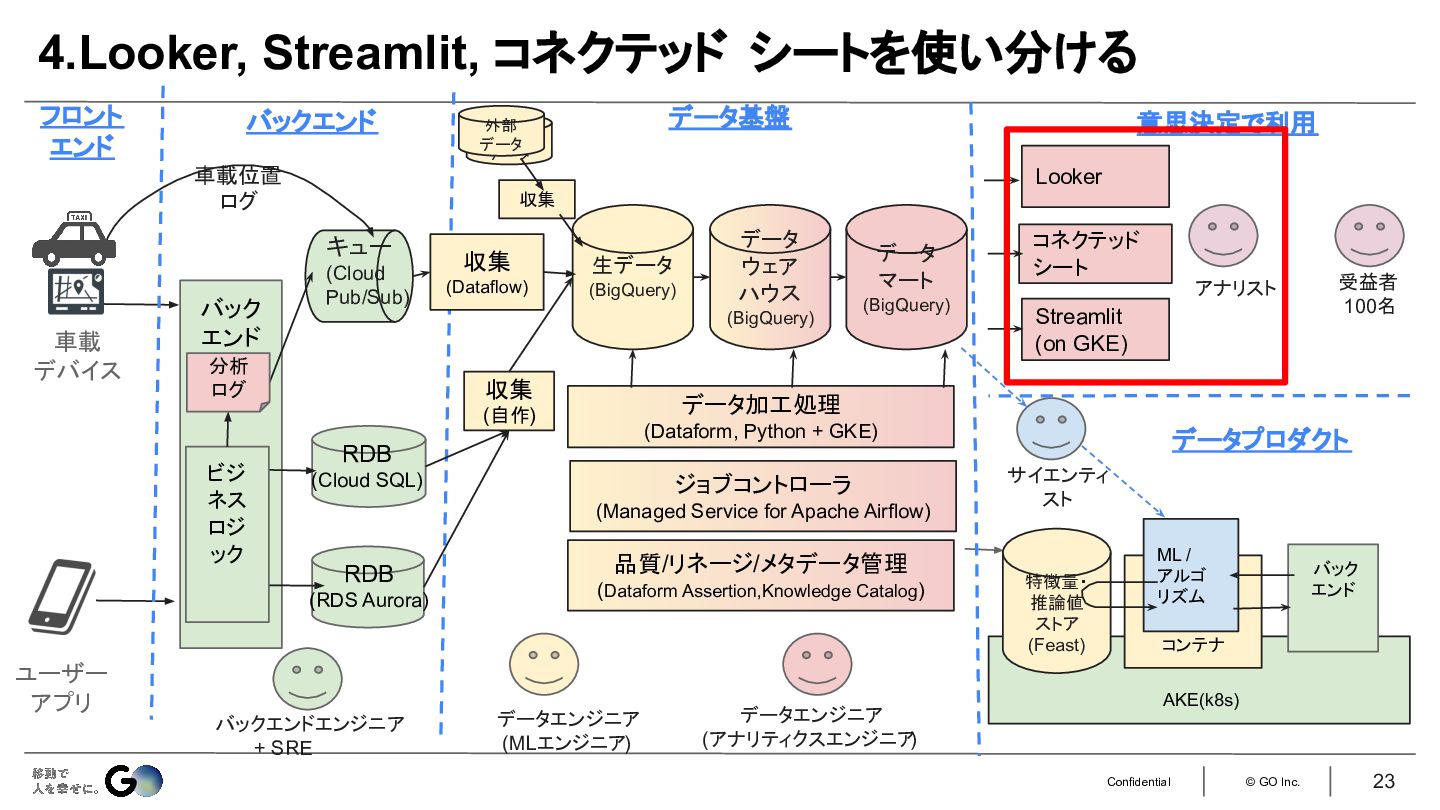
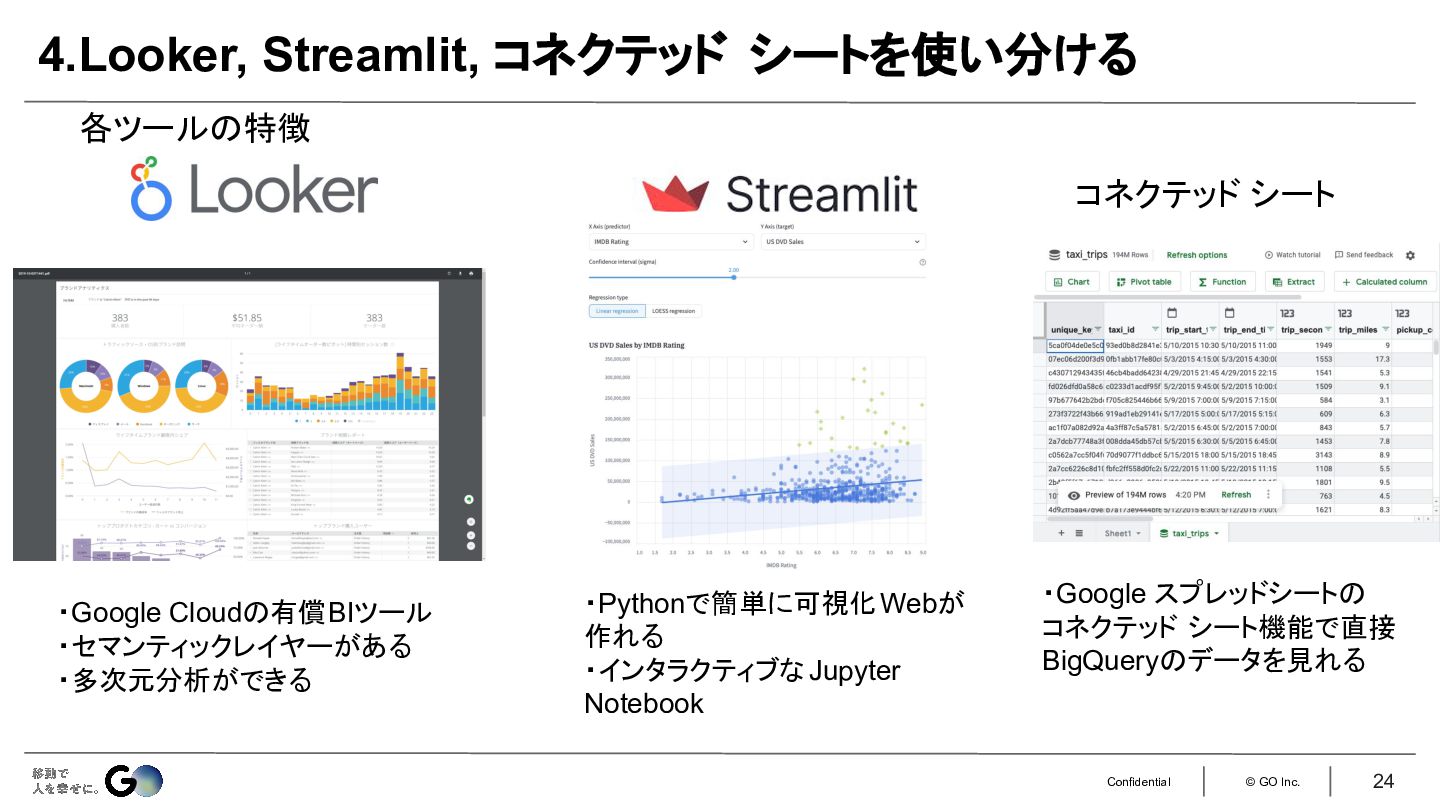
4.Lookerだけだと提供が遅くなるため、 Streamlitやコネクテッド シートを使い分ける
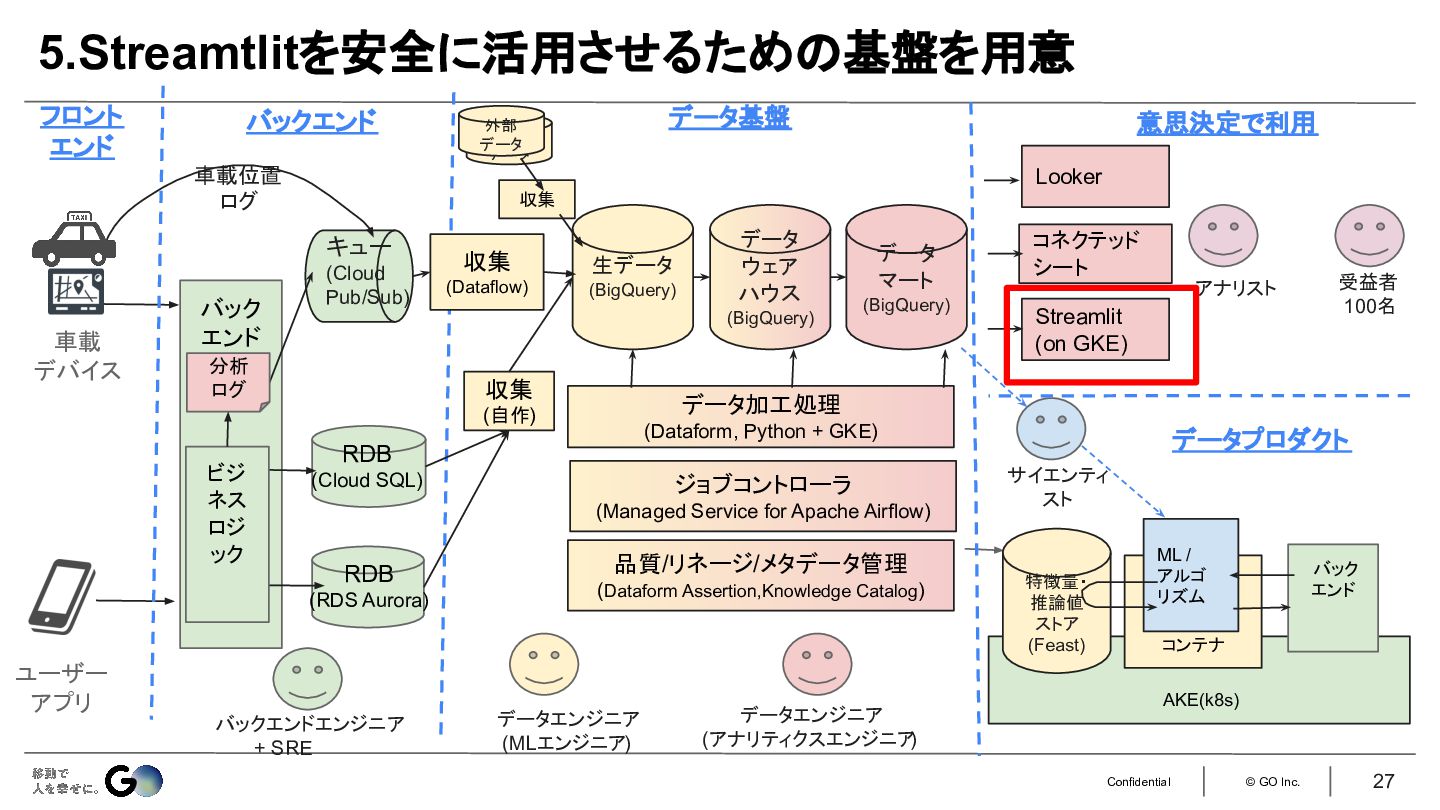
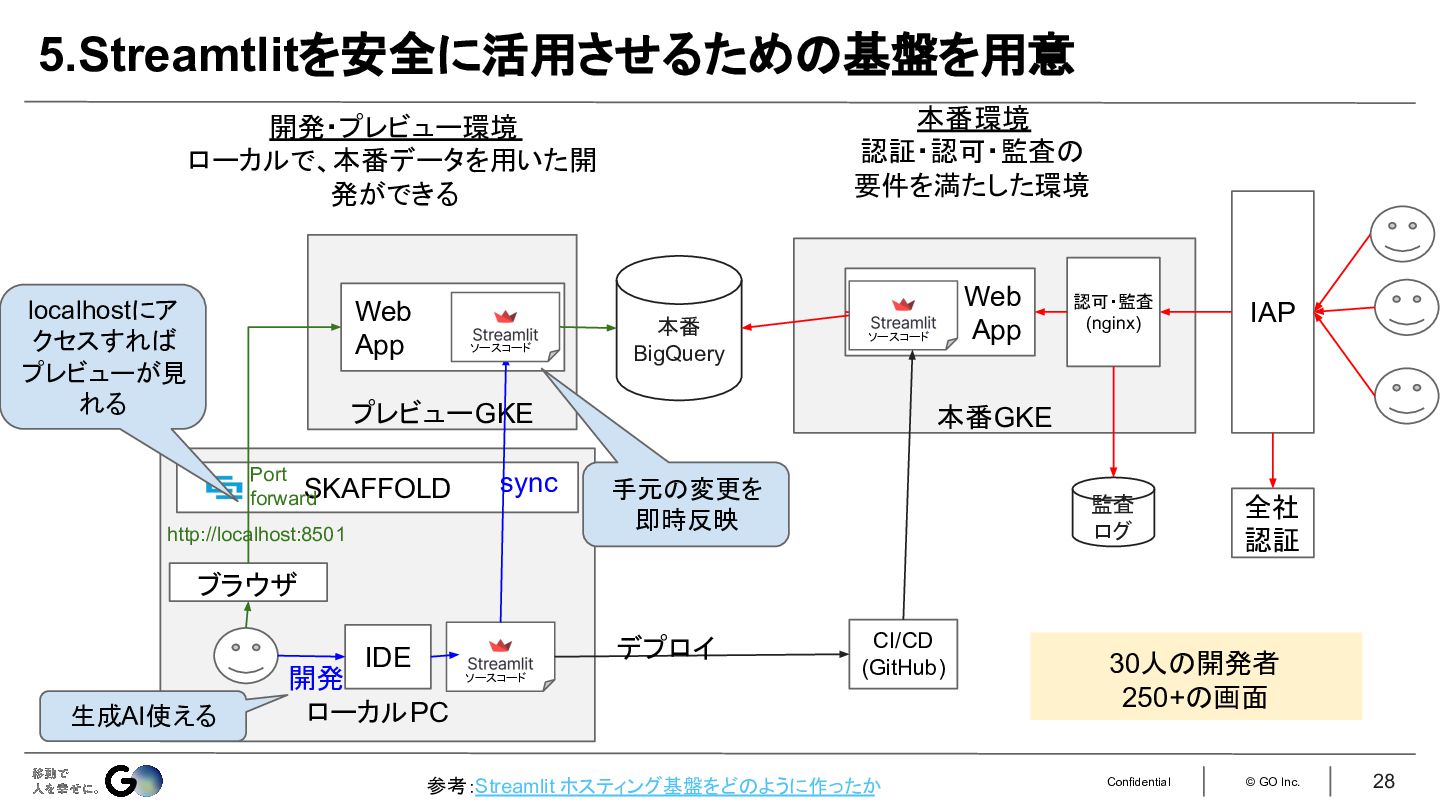
5.ローカルPCで本番のデータを扱えるStreamtlit開発環境を整備
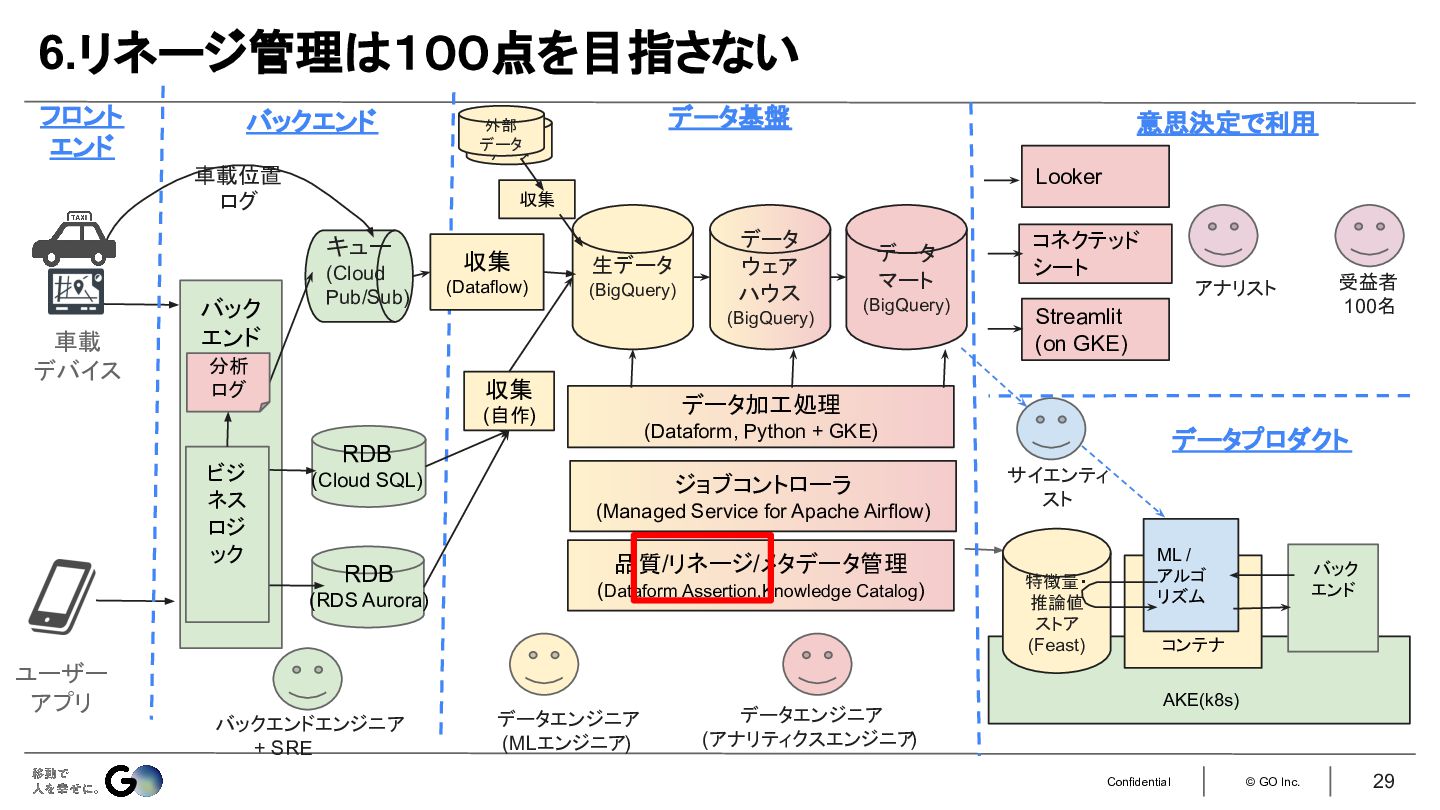
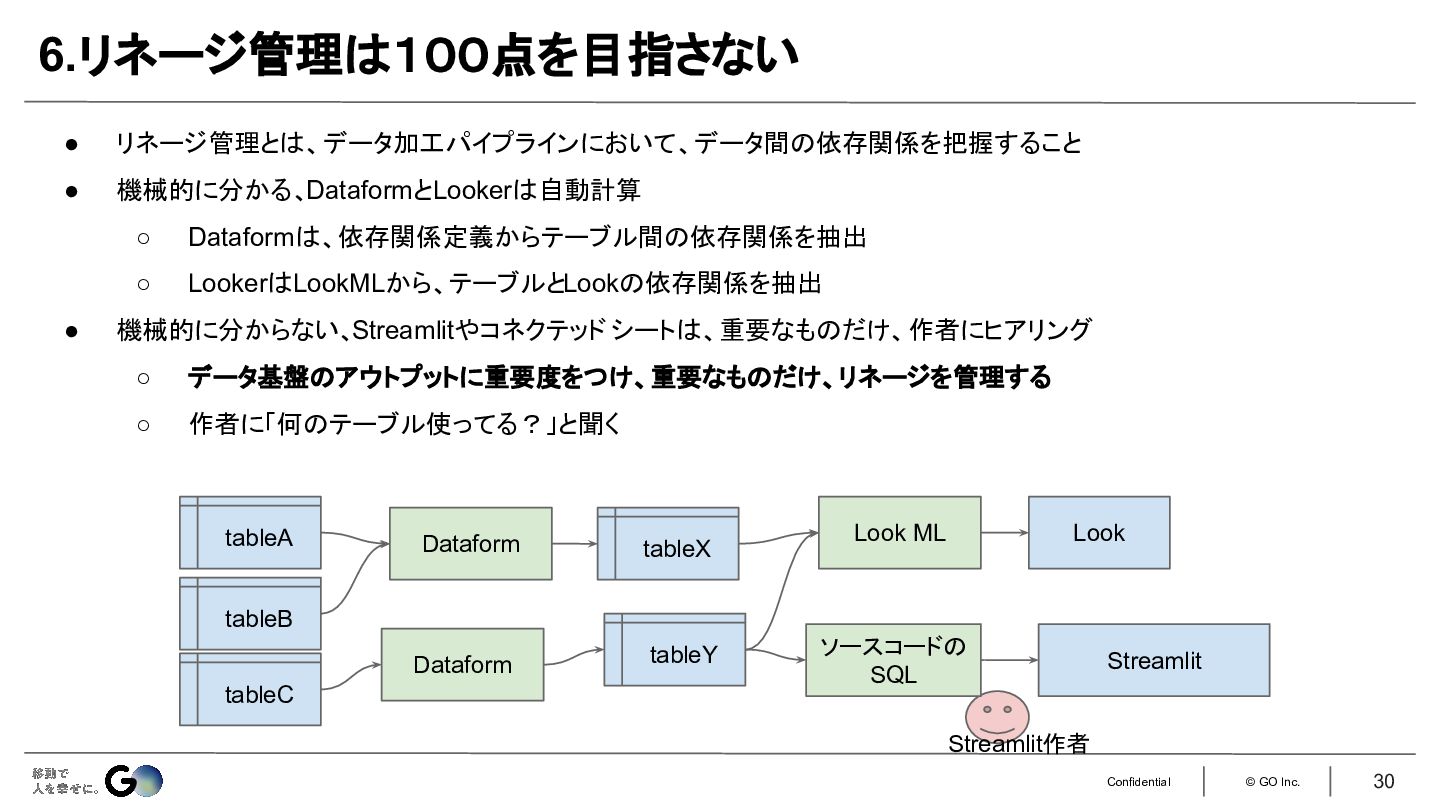
6.リネージ管理は100点を目指さない
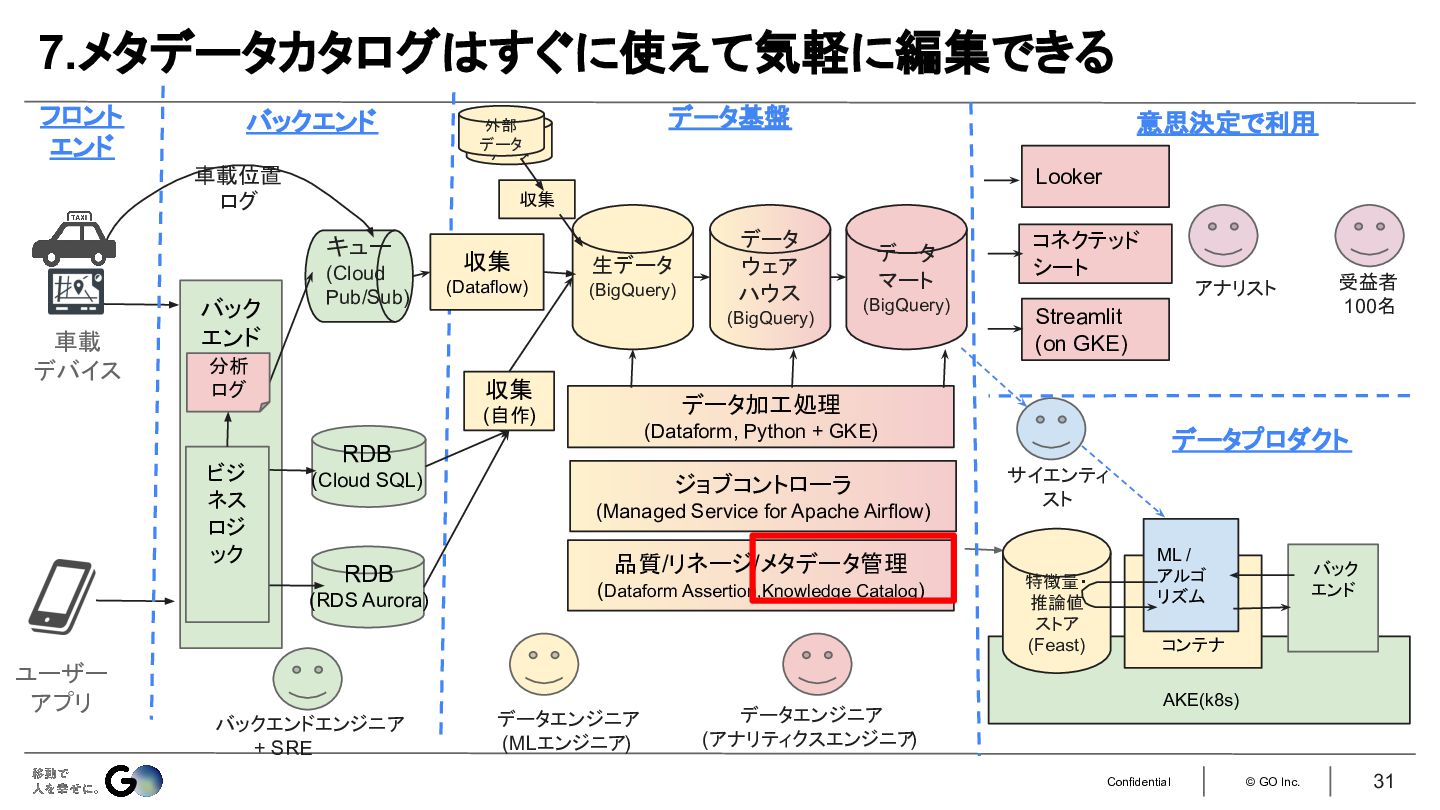
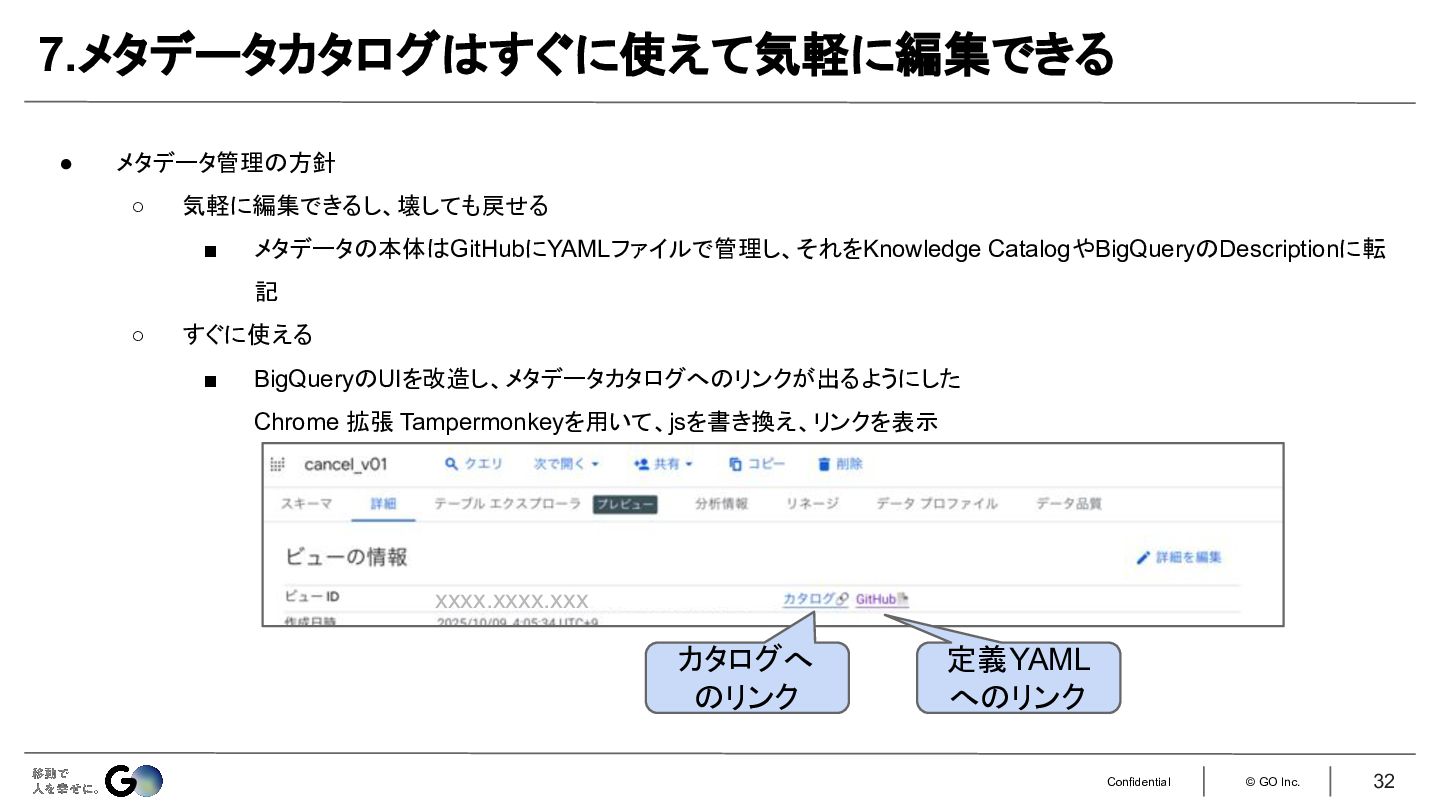
7.メタデータカタログへはすぐに飛べるようにBigQueryのUIを改造
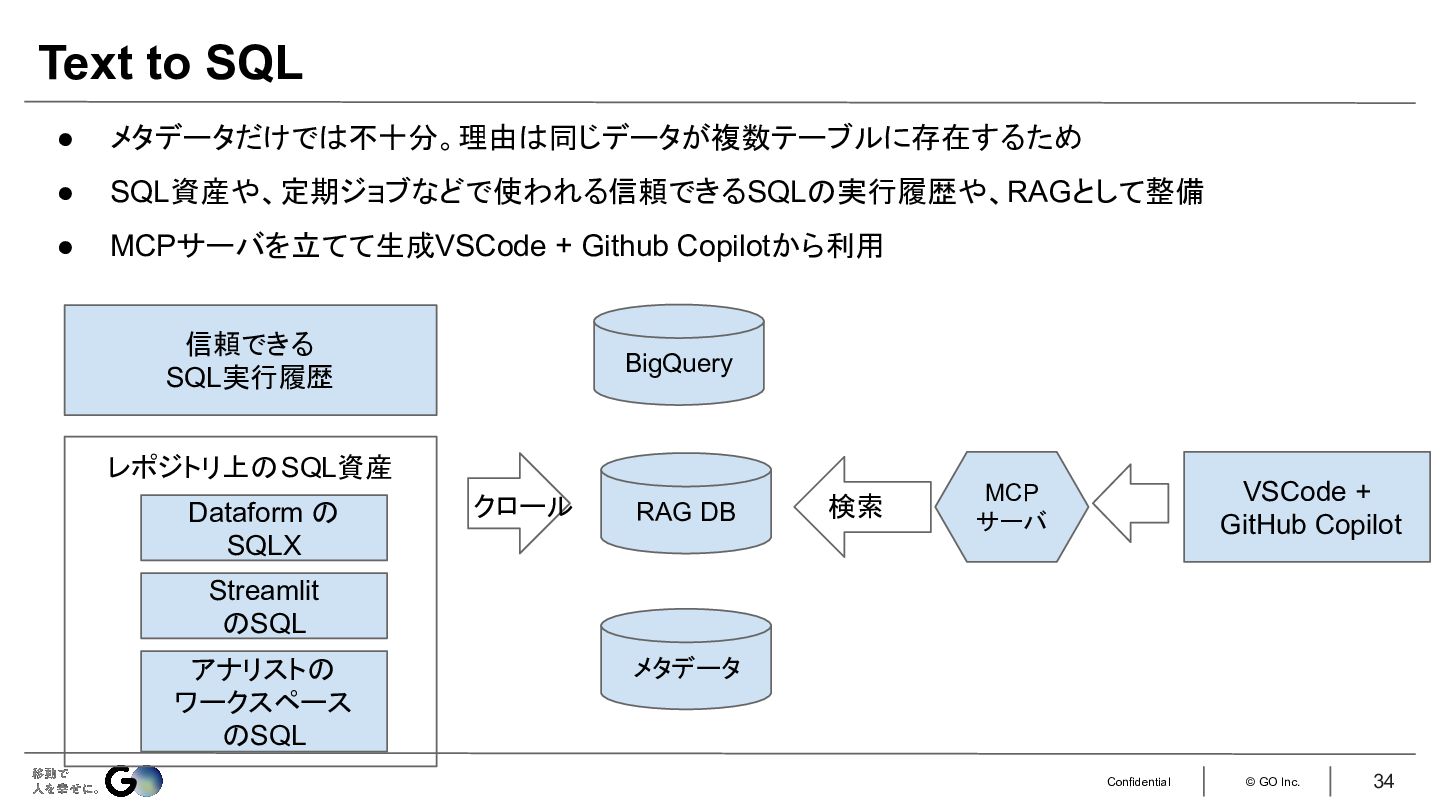
最後に、今チャレンジしているText to SQLの取り組みの紹介もしています
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}