As companies move towards Microservices and Cloud-based deployments, multiple points of failure emerge in the infrastructure. With critical uptime demands and tight SLAs, high availability and reliability become just as important and visible. In this talk I'll cover the what, why, and how of Disaster Recovery.
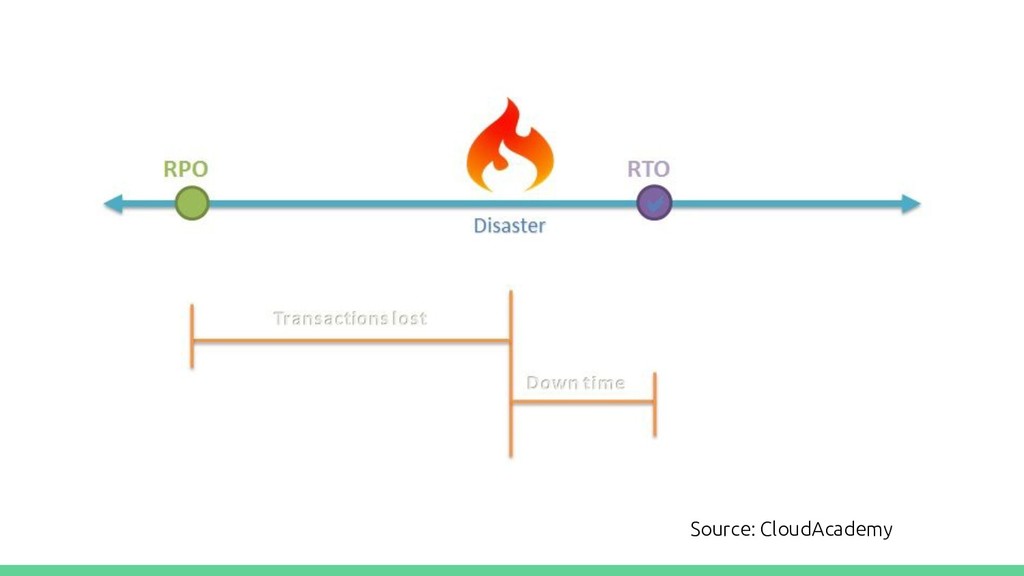
Disaster Recovery usually is an afterthought, but with good blueprints and practices, it should and can be a part of the SDLC, allowing us to build mission critical services that can survive disasters without degrading the quality of service. With the PasS offerings from public cloud platforms, DR has become a lot more cost effective and easy to implement. I will talk about key terms and metrics used for DR, and strategies which can be applicable to any type of infrastructure - on prem, on cloud, or hybrid.
After this talk, you will become very familiar with Disaster Recovery fundamentals, and start thinking about options and strategies available based on your SLA while you architect your service. Terms like hot-cold, active-active will become much more relatable as well!
I'll briefly refer to AWS and Data Center infrastructure during this talk - so basic familiarity with these will be helpful.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
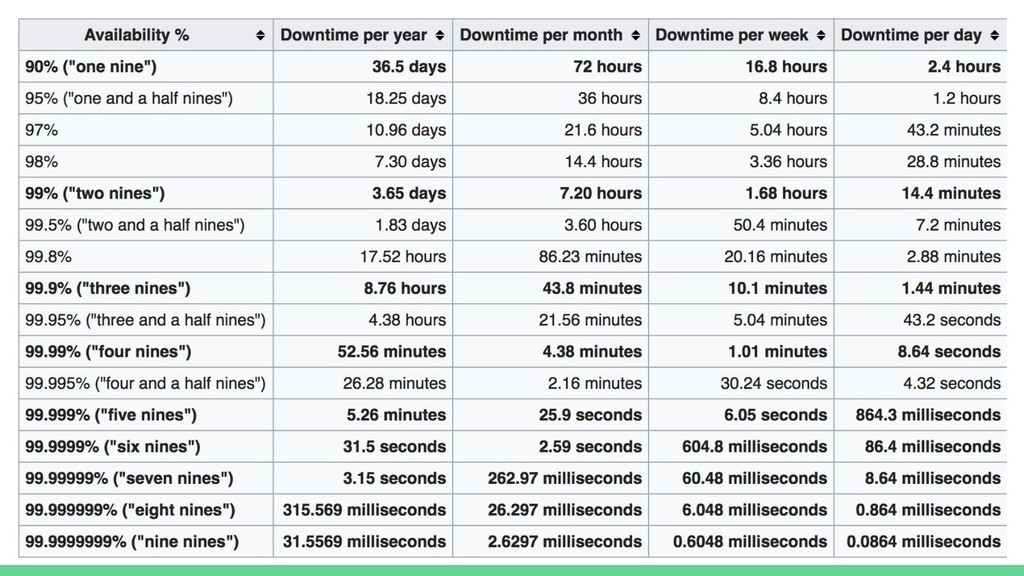{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}