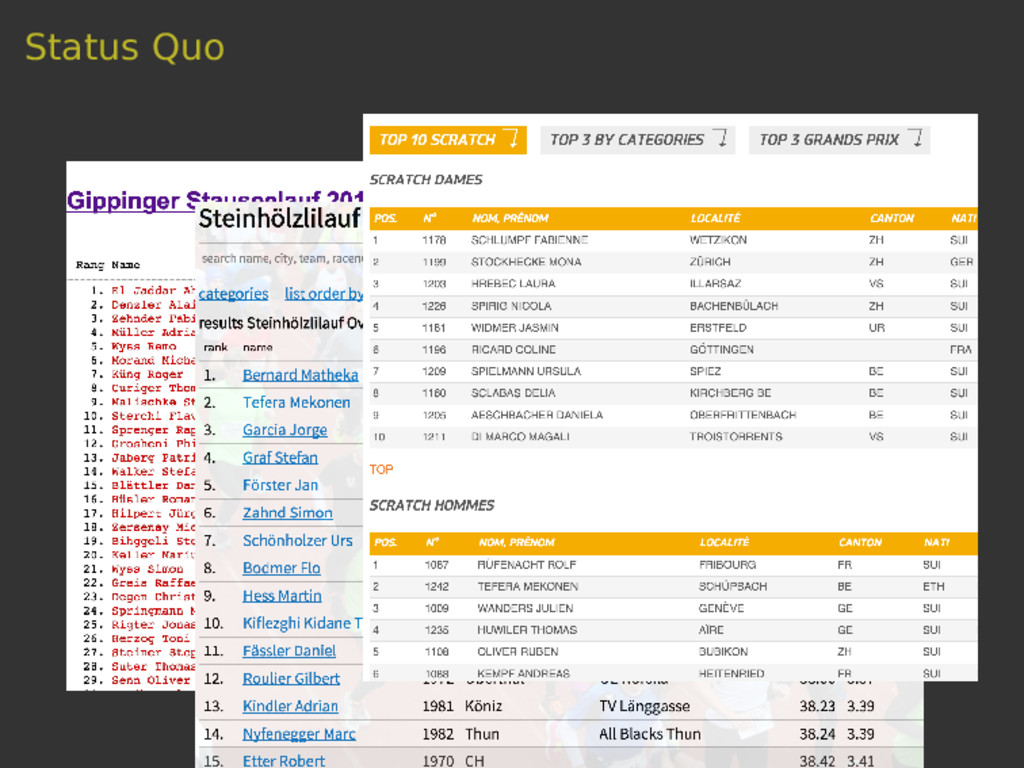
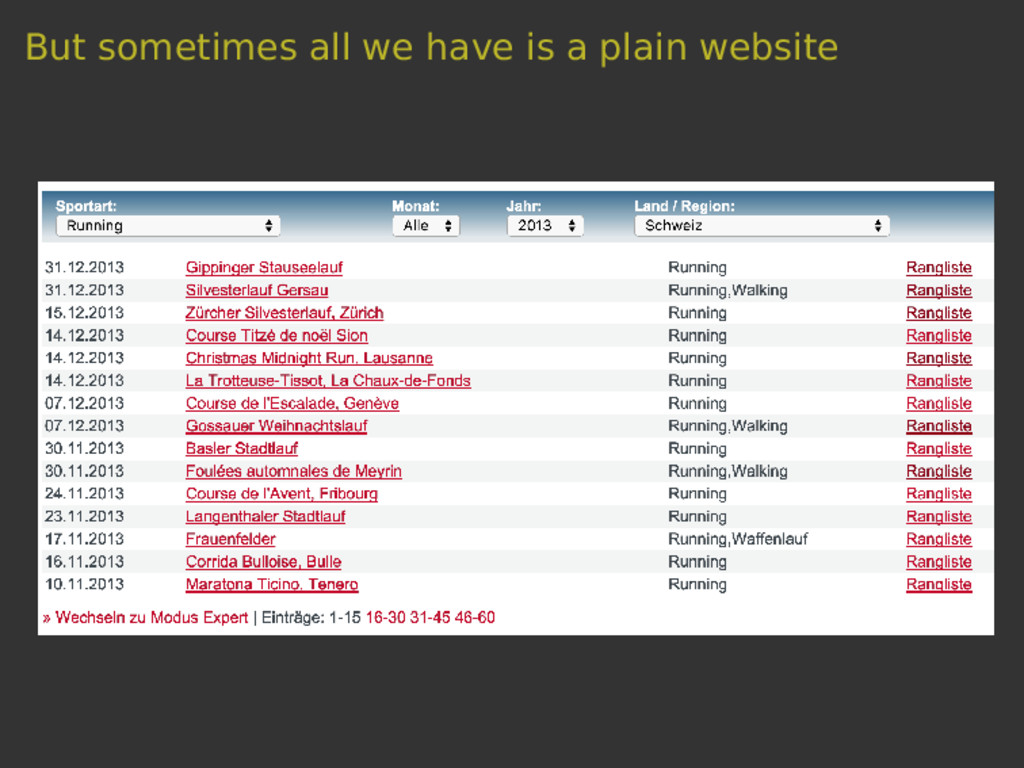
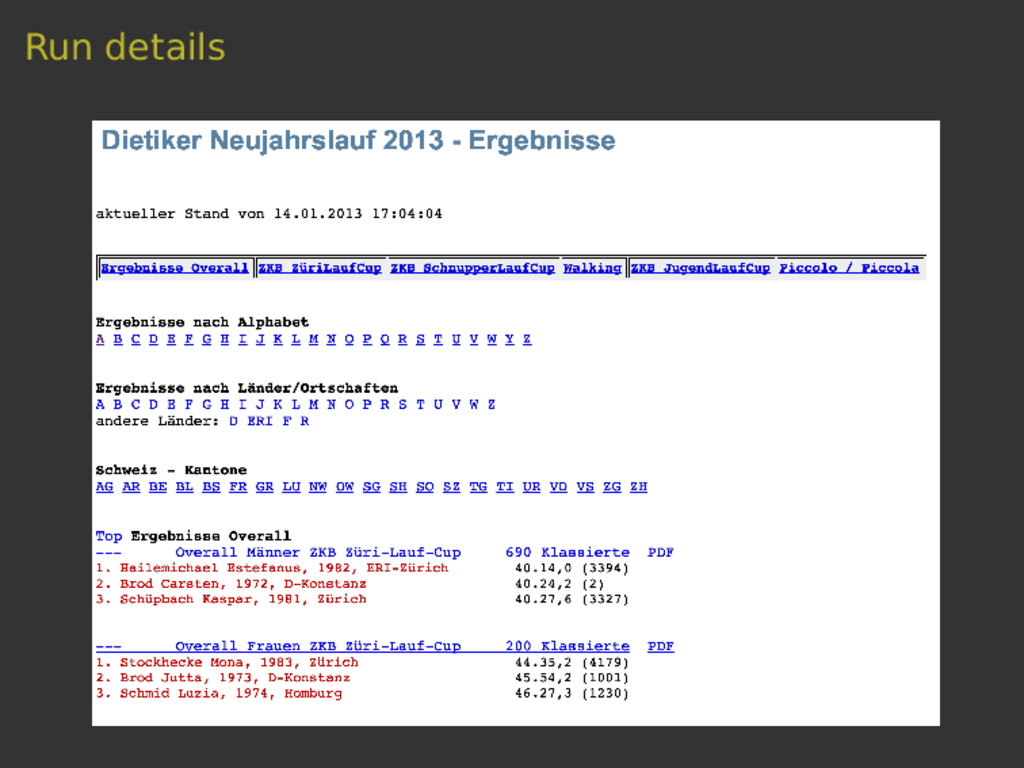
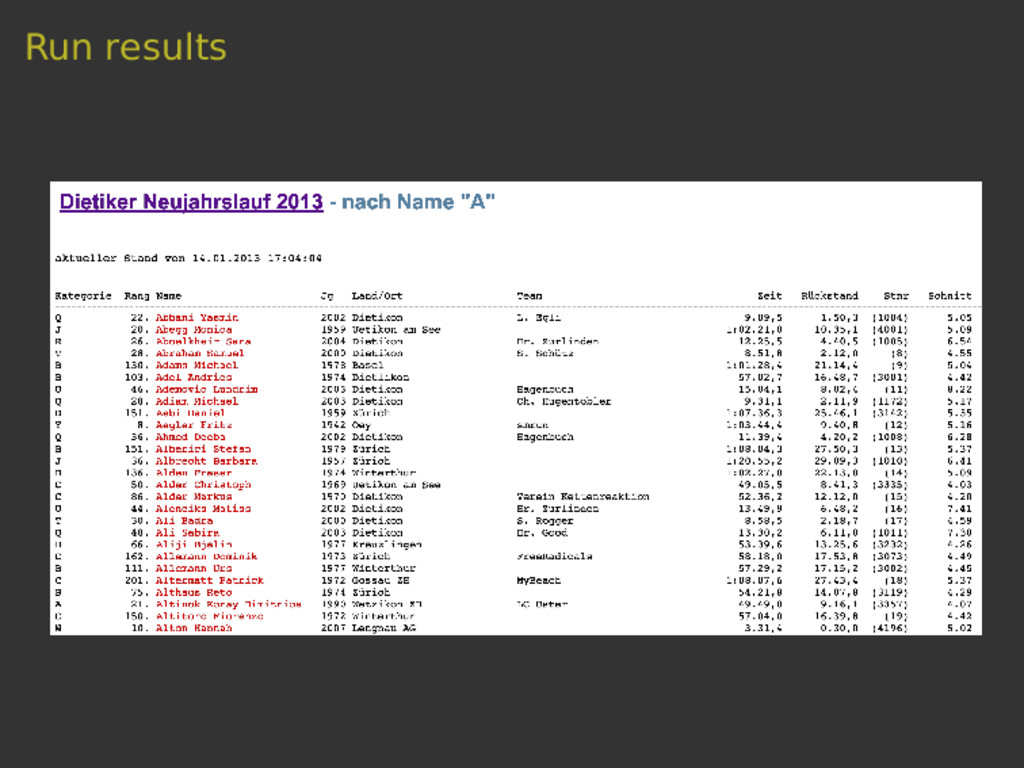
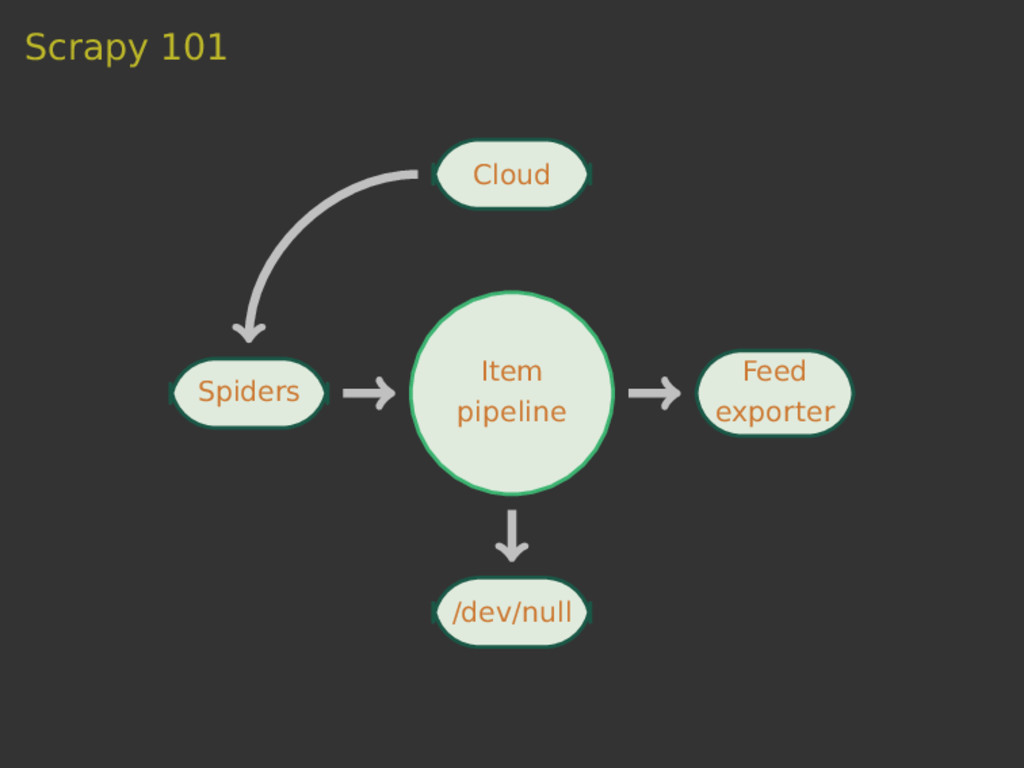
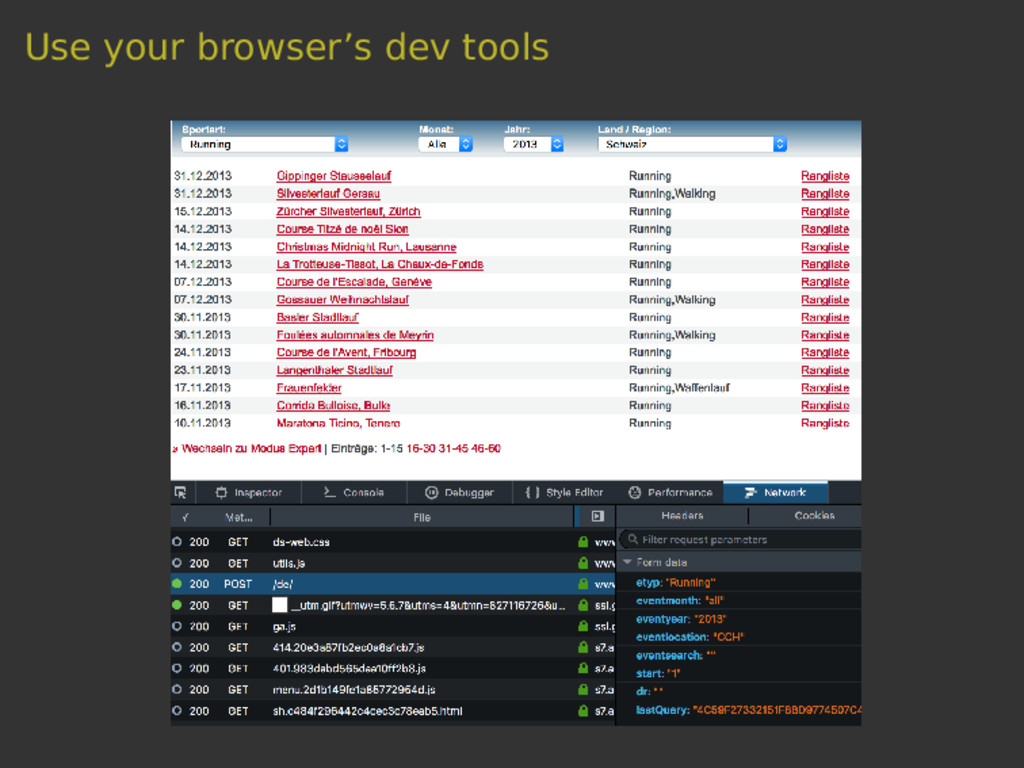
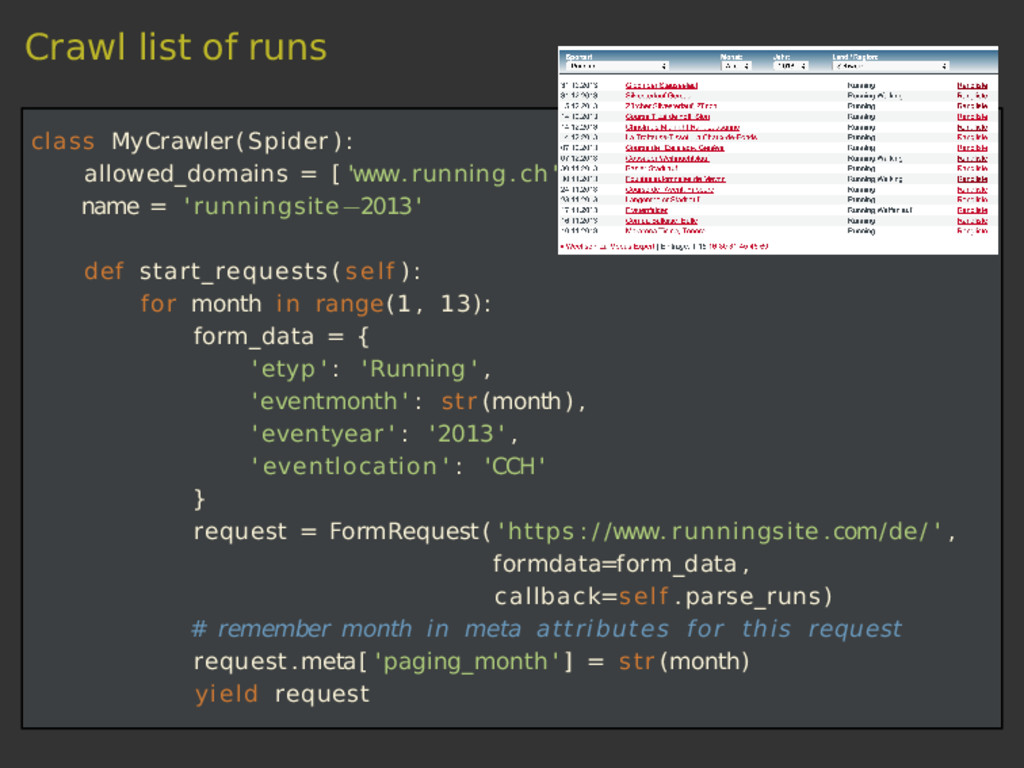
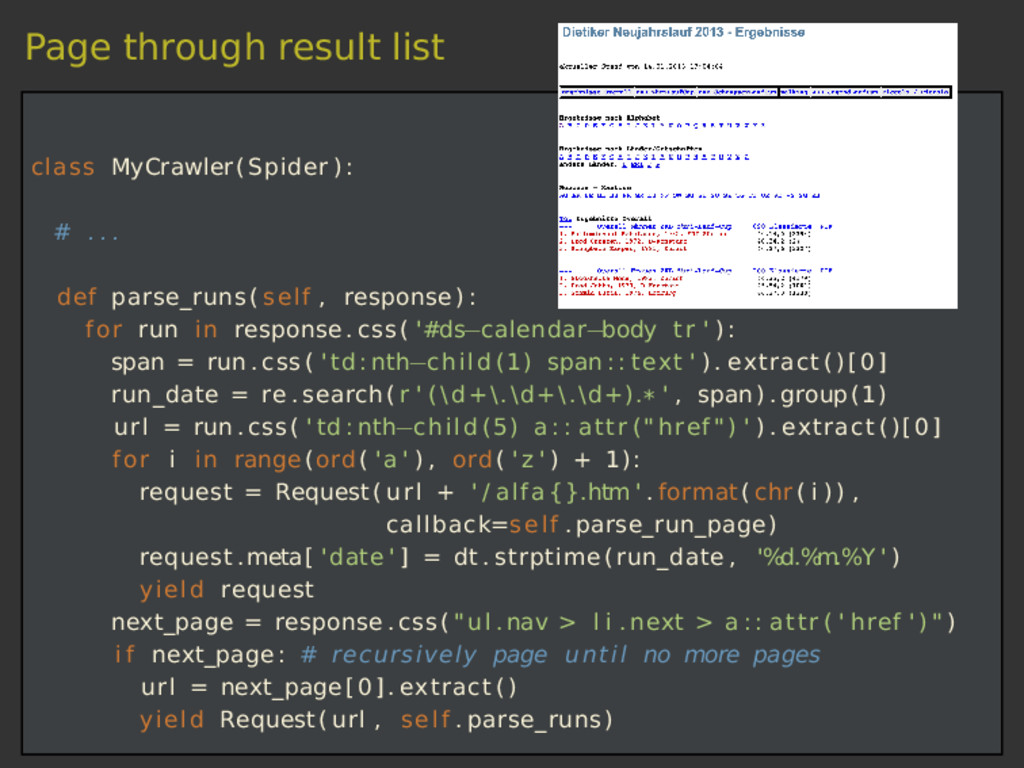
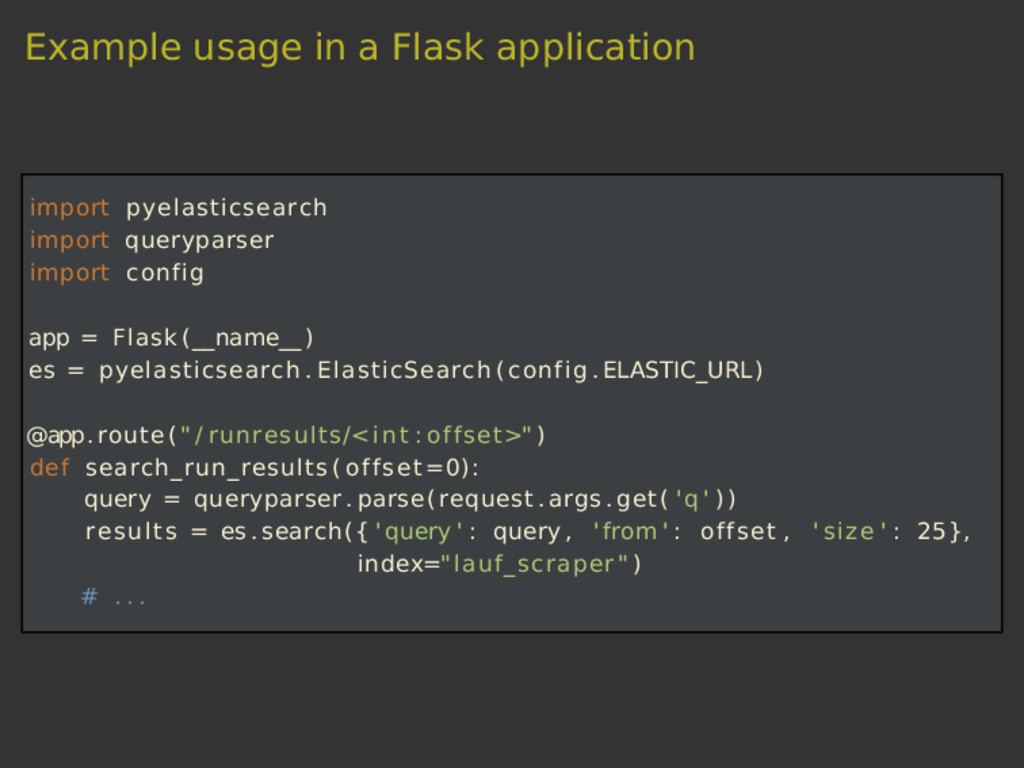
Scrapy is a versatile tool to scrape web pages with Python. Thanks to its pipeline architecture, it is easy to add new consumers to work on the scraped data. One such pipeline allows us to index the scraped data with Elasticsearch. With Elasticsearch, we can make the scraped data searchable in a highly efficient way. In this talk, we will not only show you the basics of the interaction between Scrapy and Elasticsearch, but also a hands-on showcase where we use these tools to collect sport results of Swiss running events and to answer interesting questions related to this data.
Presented at Swiss Python Summit 2016.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
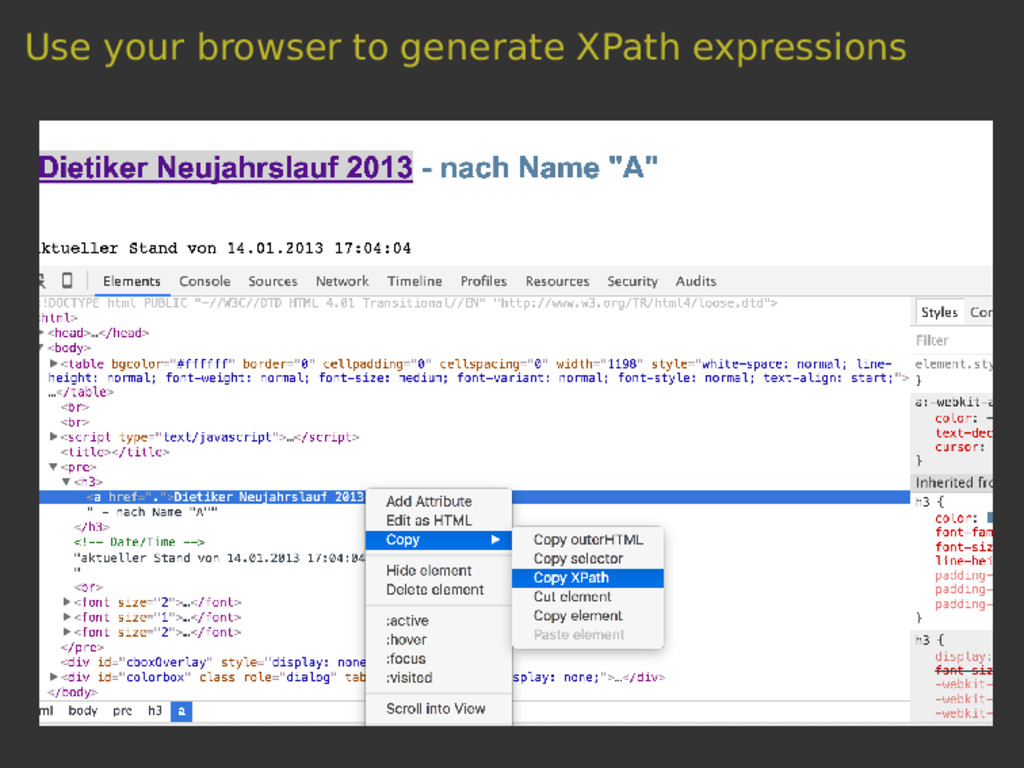{kind=link}
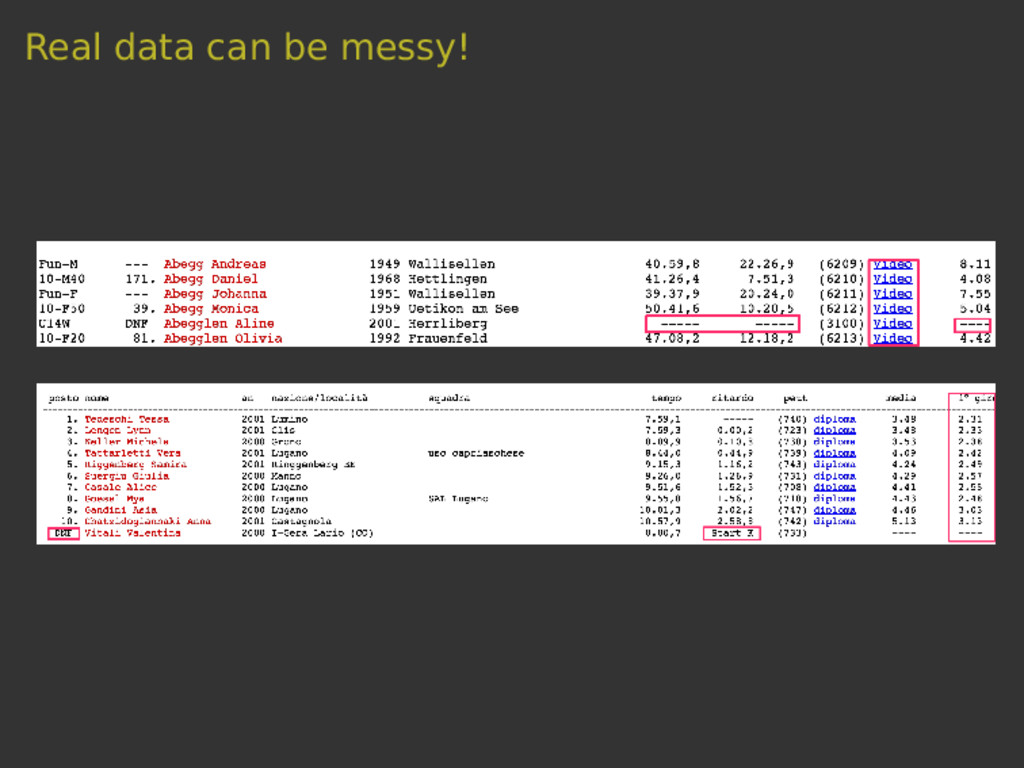{kind=link}
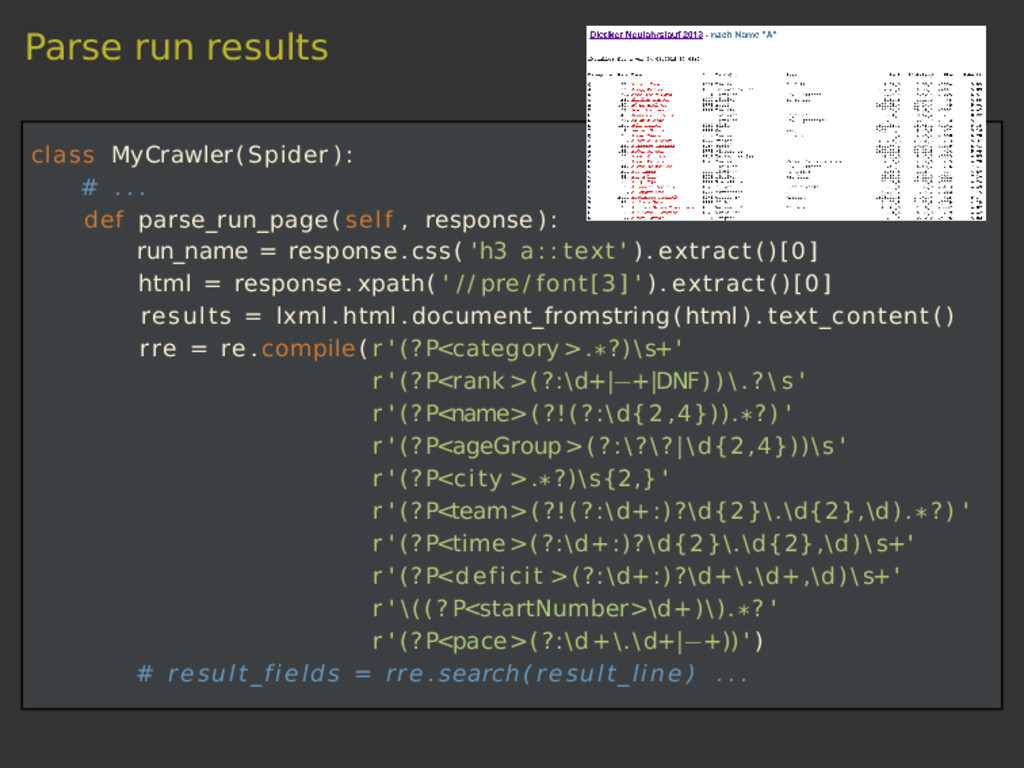{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
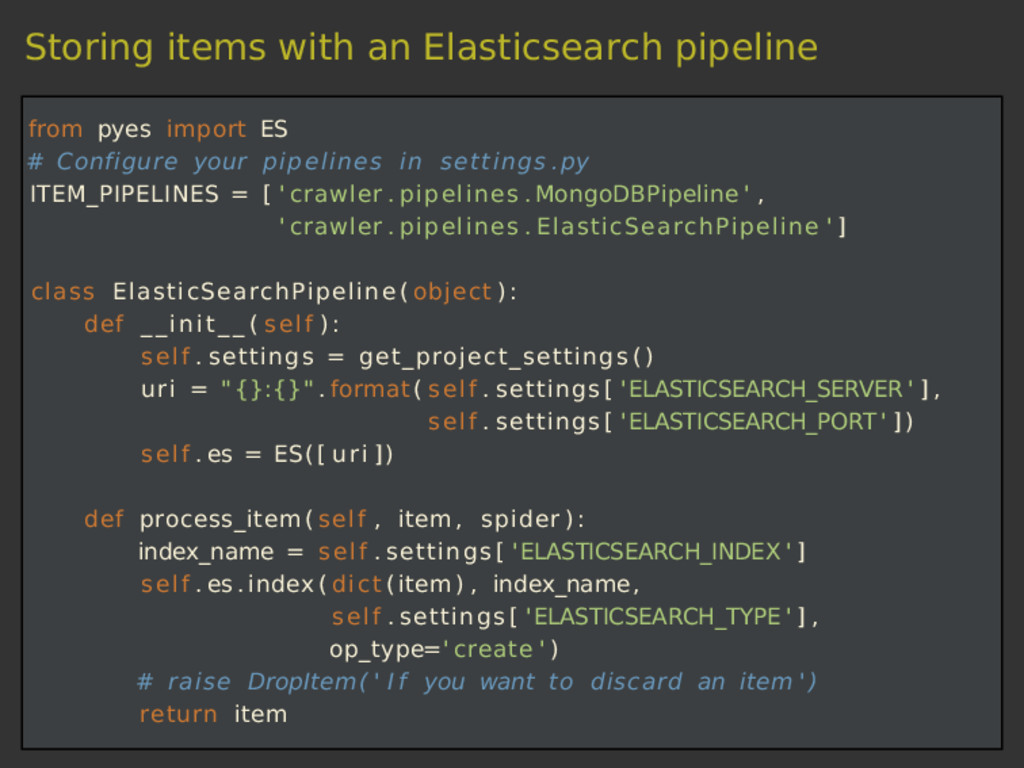{kind=link}
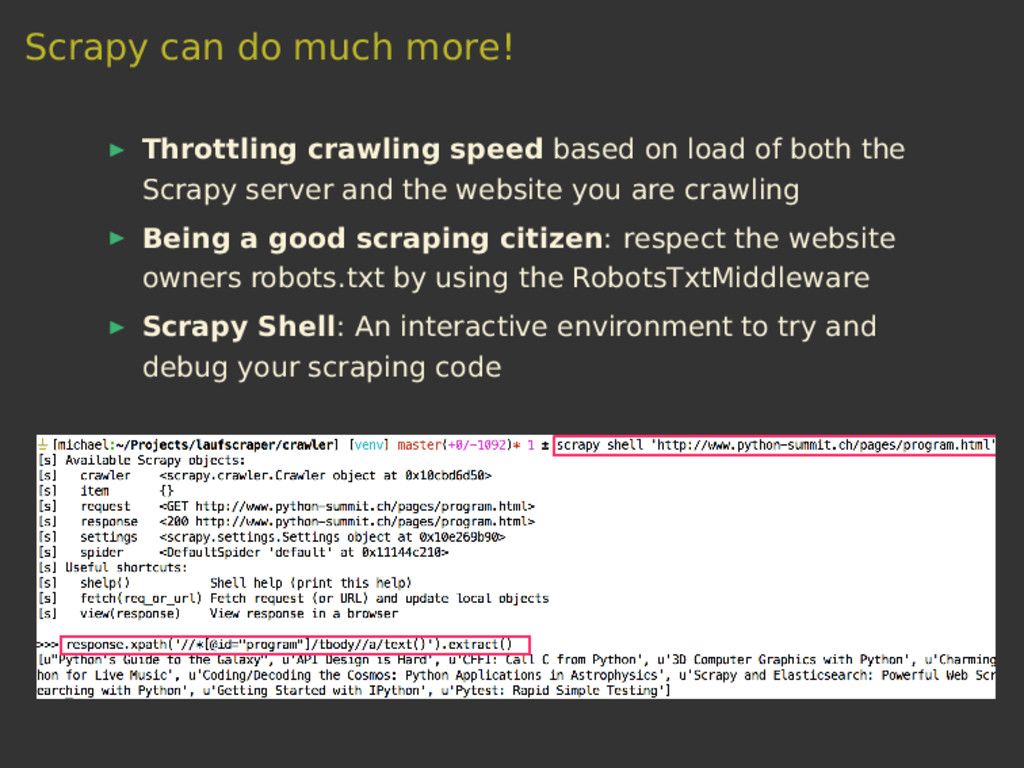{kind=link}
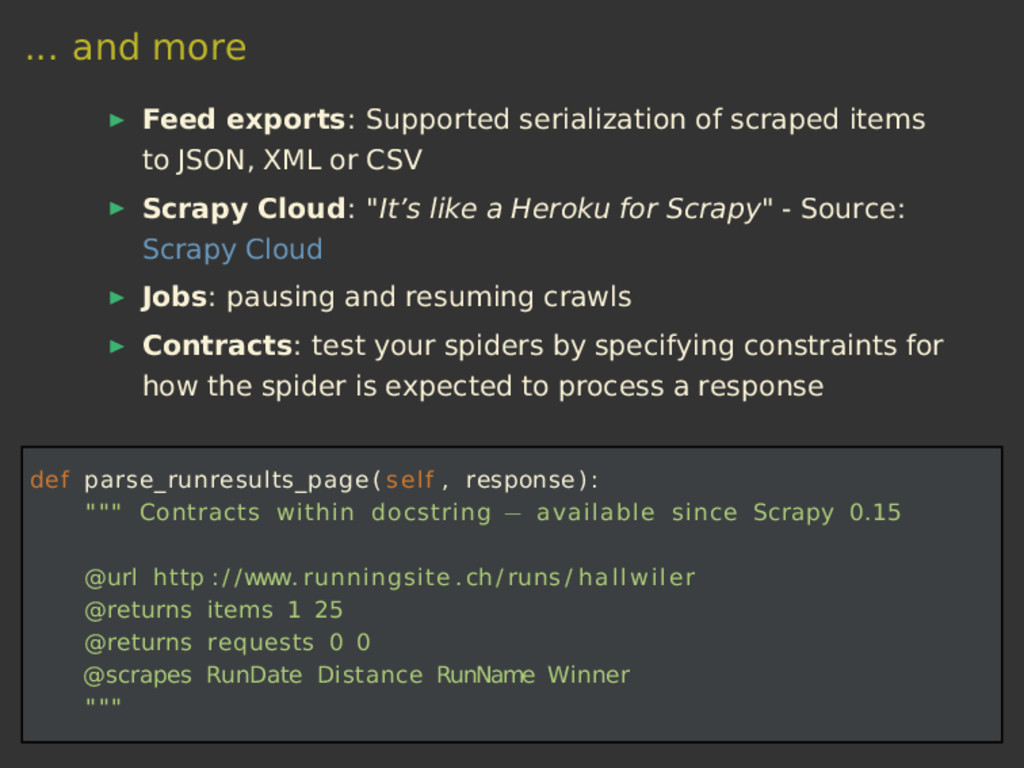{kind=link}
{kind=link}
{kind=link}
{kind=link}
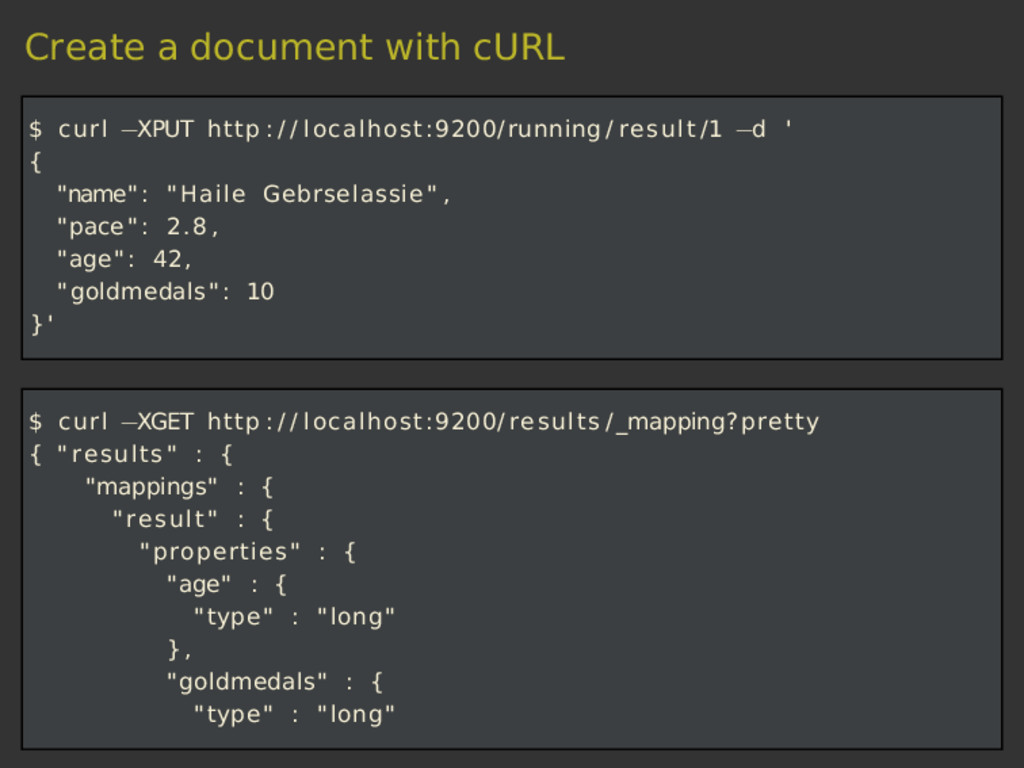{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}