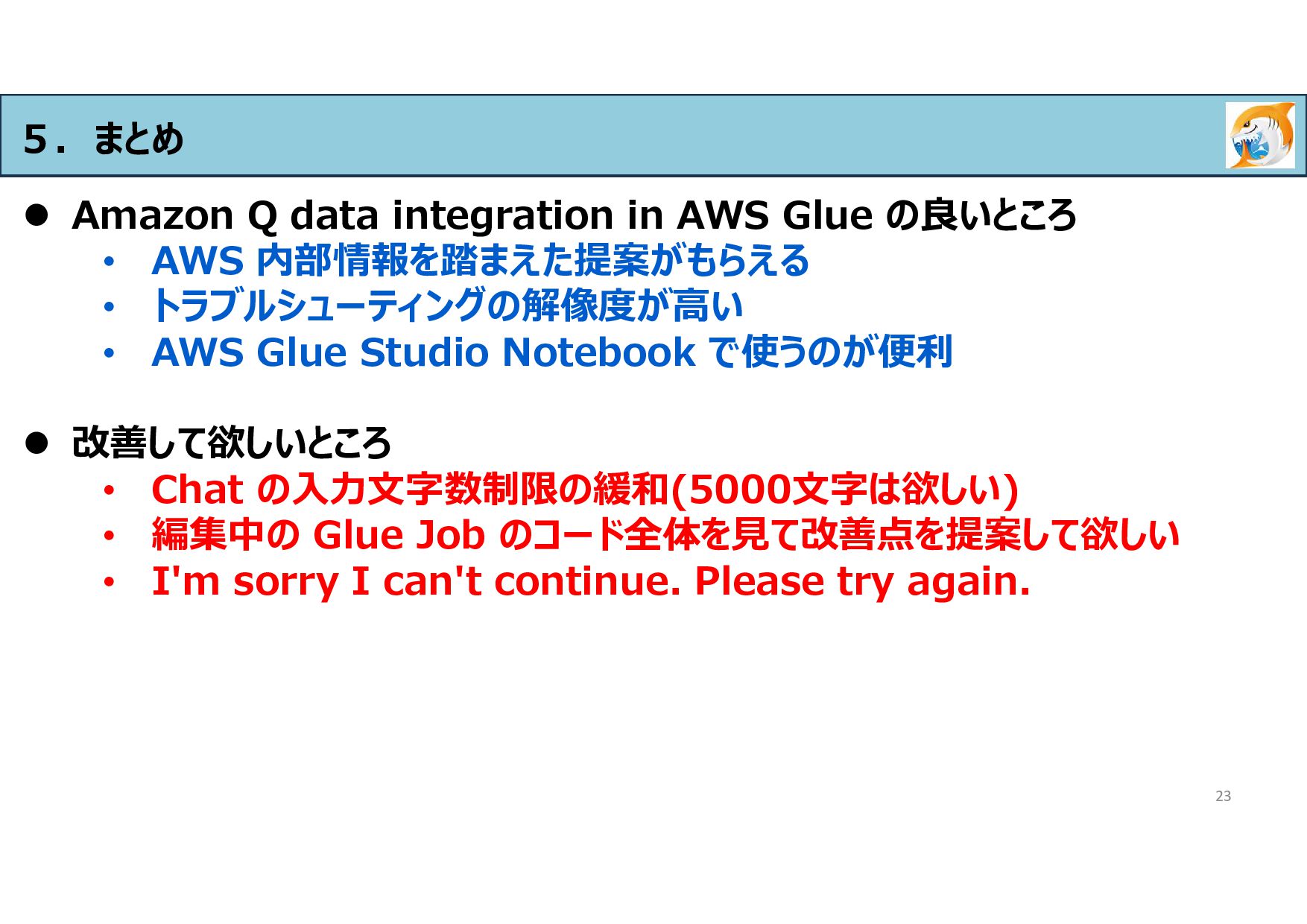
Amazon S3 using Amazon Data Firehose with a subscription filter. The data in question does not use Lambda and does not use Firehose's decompression feature, so it contains unnecessary CloudWatch information. Therefore, the data is in a state of nested JSON that cannot be easily parsed by Amazon Athena. The data stored in S3 was cataloged by Glue Crawlers of AWS Glue. After this, we want to convert the data into a form that is easy to analyze from Athena with Glue Job and store it in another S3. One data file contains multiple logs that we want to retrieve, so we want to combine each log into one file with newlines. We want to use the gluetest_raw_crawlergluetest202406_raw table in the gluetest database in Glue DataCatalog for the ETL process described above. We want to export the data after ETL to S3 at s3://gluetest-output with the same folder structure as s3://gluetest202406-raw. Please create a Glue Job that meets the requirements.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}