Read ExtractTags {a->(argentina, 5M), a->(armenia, 2M), …, ar-> (argentina, 5M), ar->(armenia, 2M), ...} {#argentina scores!, watching #armenia vs #argentina, my #art project, …} {argentina, armenia, argentina, art, ...} {argentina->5M, armenia->2M, art->90M, ...} Tweets Predictions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SELECT repository_language, count (repository_language) as pushes FROM [githubarchive:github.timeline] where type="PushEvent"](https://files.speakerdeck.com/presentations/ffaa5dc2027549b5b26cb51063789e71/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![{a->[apple, art, argentina], ar->[art, argentina, armenia],...} Count ExpandPrefixes Top(3) Write](https://files.speakerdeck.com/presentations/ffaa5dc2027549b5b26cb51063789e71/slide_45.jpg){kind=link}
{kind=link}
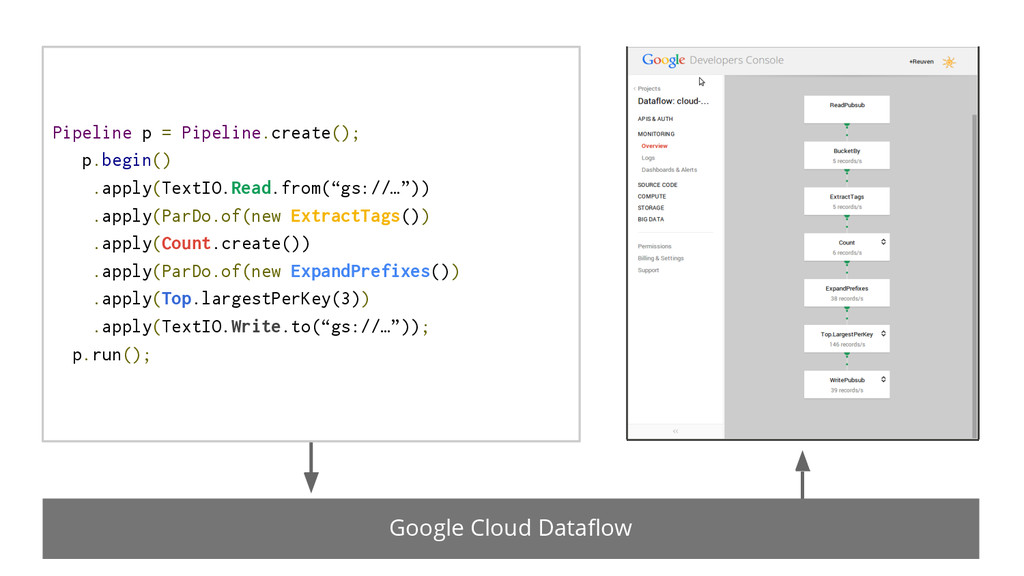{kind=link}
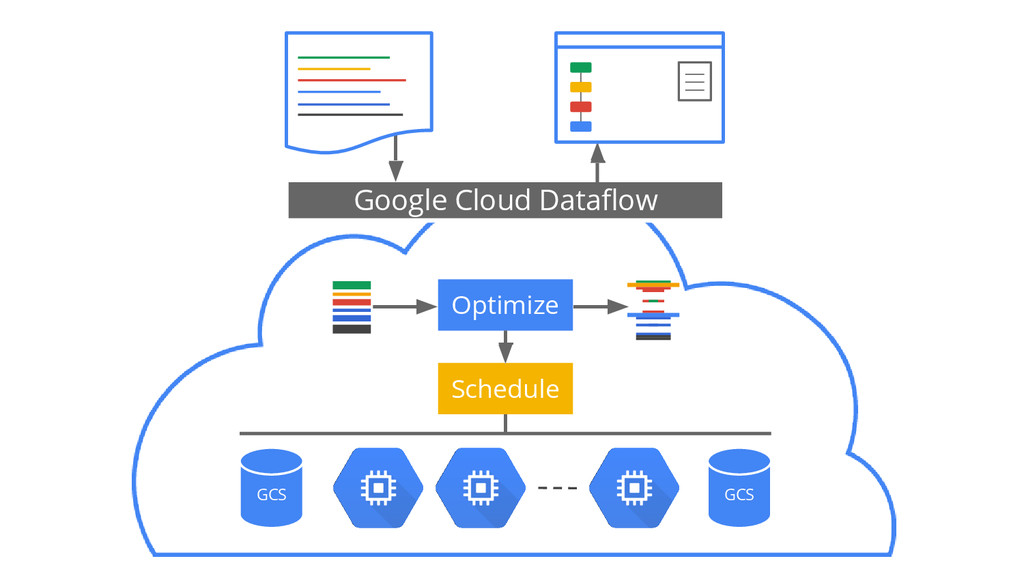{kind=link}
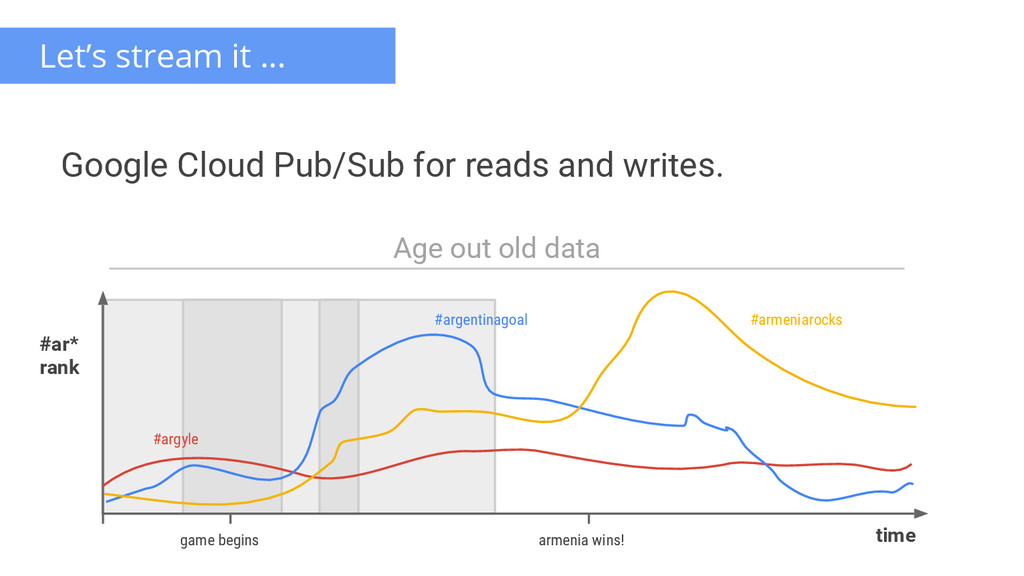{kind=link}
{kind=link}
{kind=link}
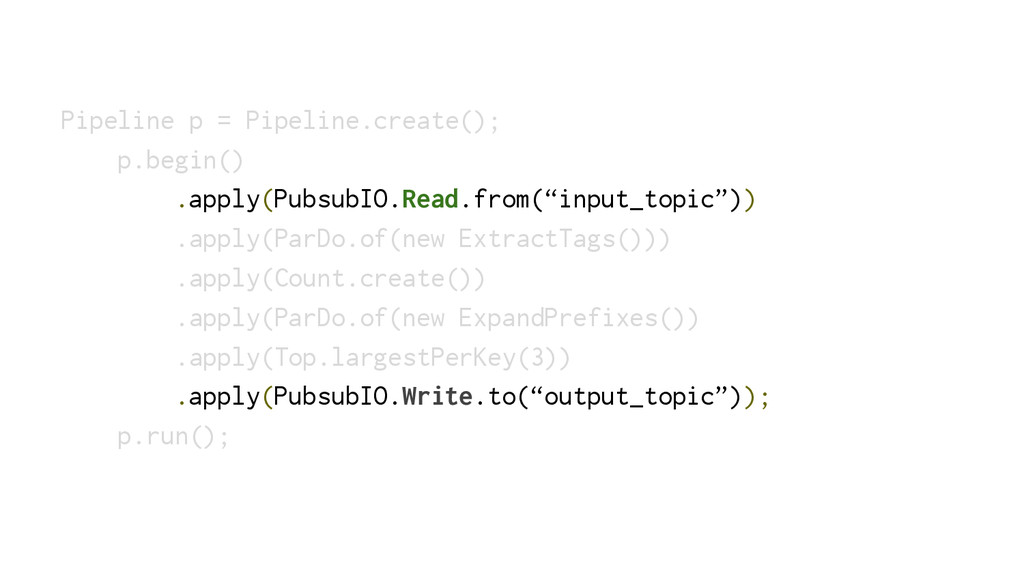{kind=link}
{kind=link}
{kind=link}
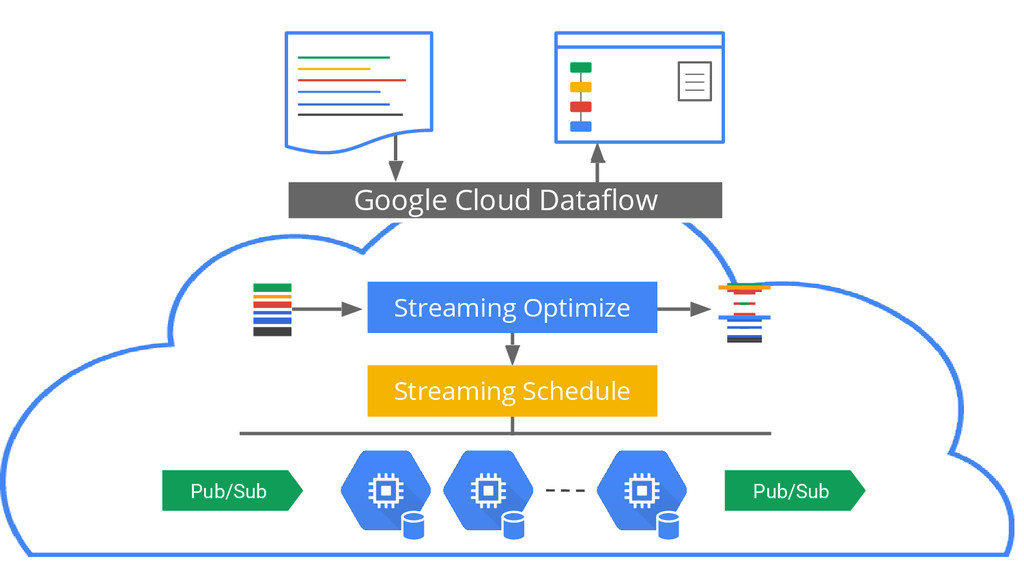{kind=link}
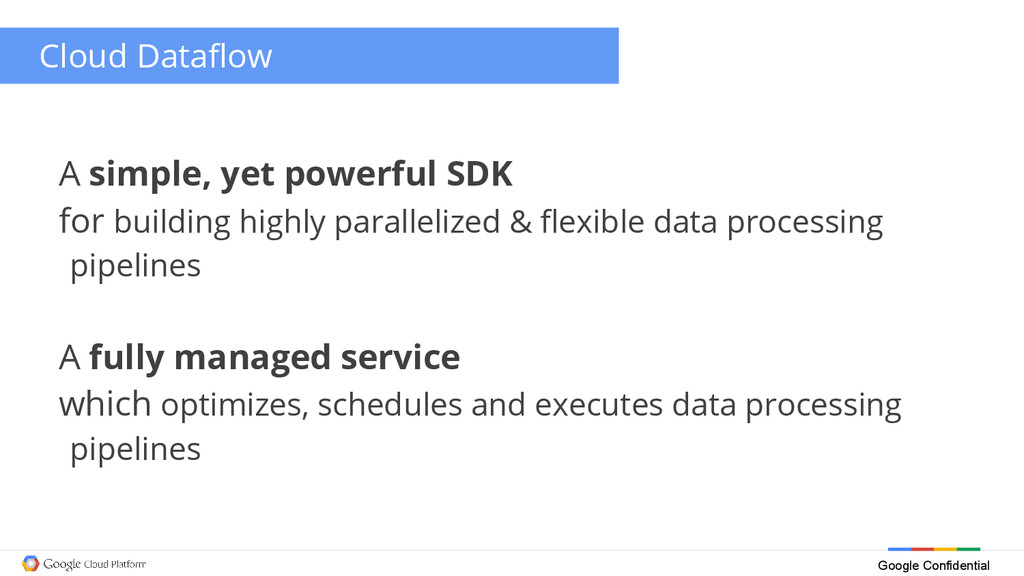{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}