of being a sole software developer, I started studying Business Informatics and later on focused on machine learning and mathematical optimization in Paderborn and Helsinki. My Bachelor and Master theses dealt with outlier detection and recommender systems. In my students job, I helped to design operations research solutions. After finishing master studies, Alex Thamm offered me an fantastic position as a consultant for business analytics projects. Since then I've seen one or the other real world data science problems (including predictive maintenance, search for patterns, anomaly detection and some more), team and project. I enjoy studying and solving data problems (even in my spare time...), keeping their potential effects on business in mind. And I like cats.
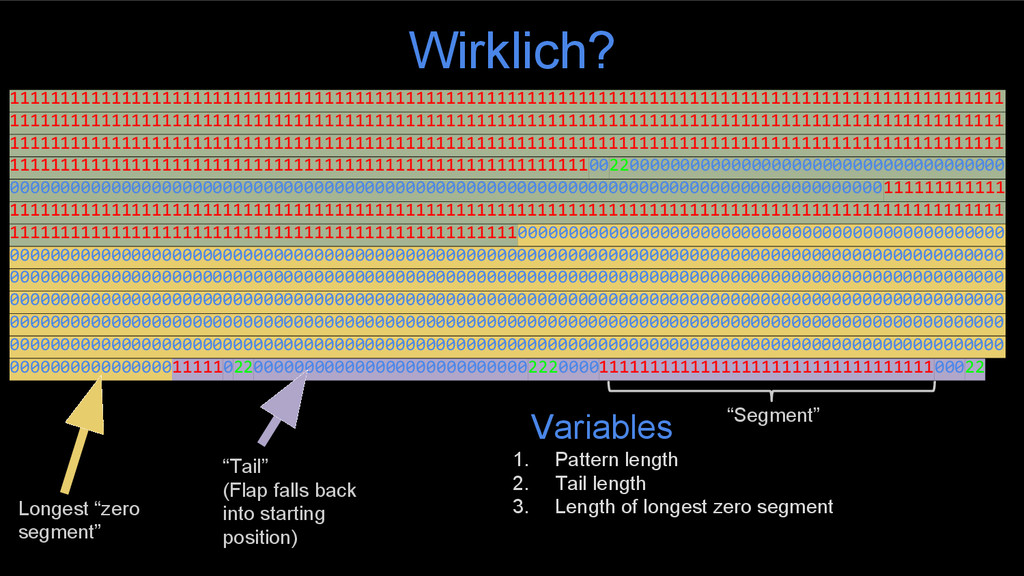
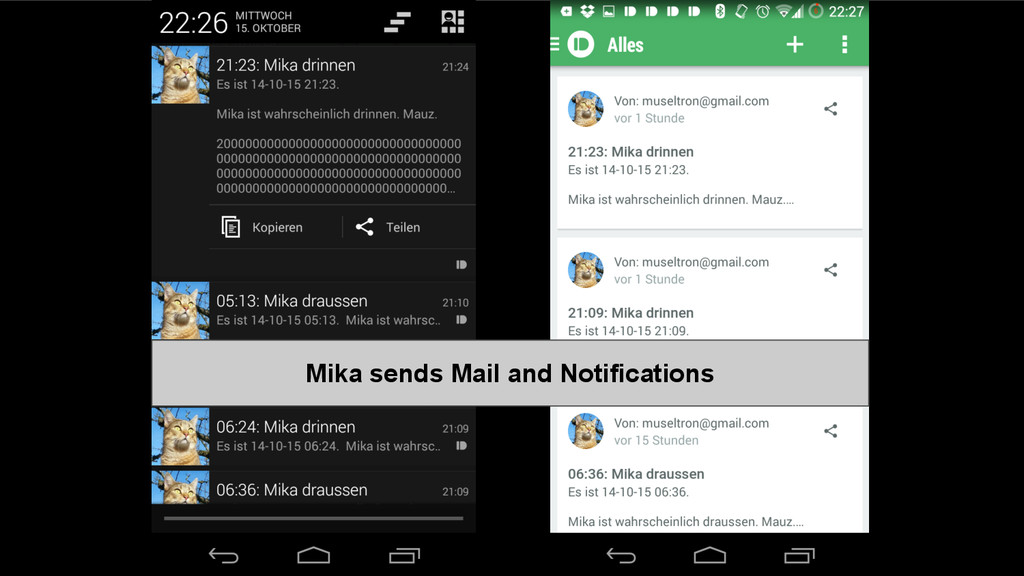
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000011111022000000000000000000000000000222000011111111111111111111111111111111100022 Zero and one. And two.
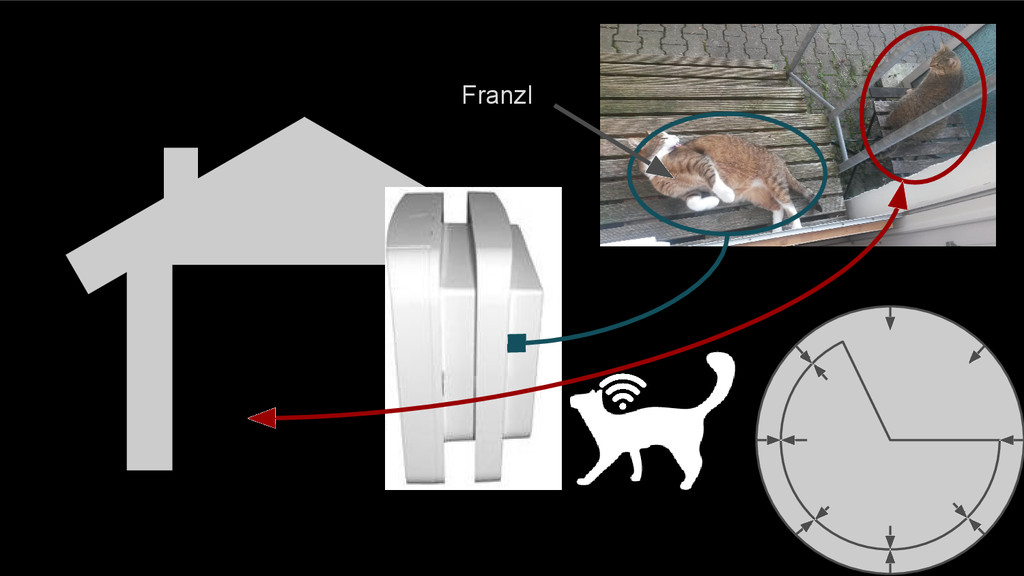
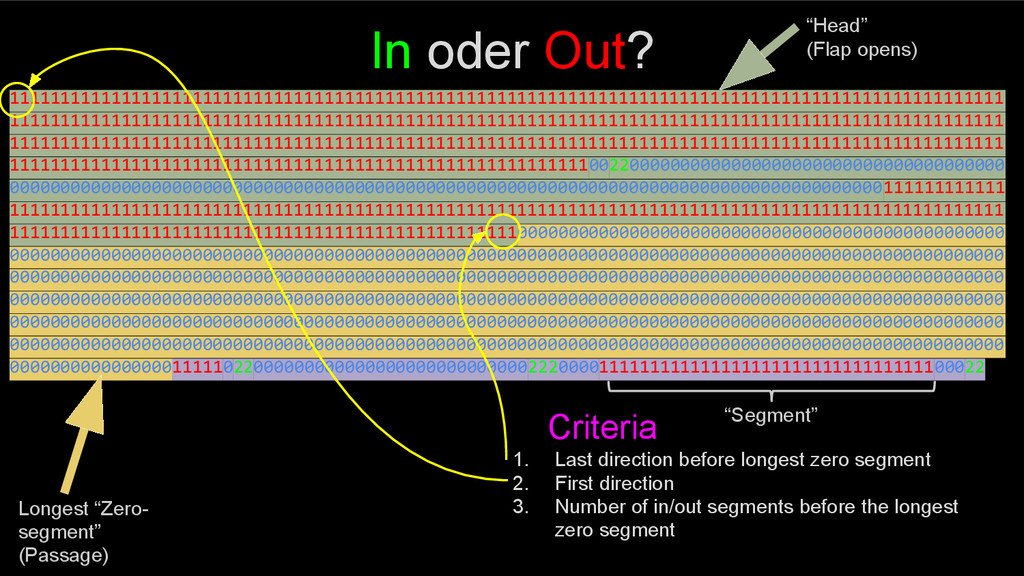
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000011111022000000000000000000000000000222000011111111111111111111111111111111100022 In oder Out? Really? ~1 Second (100 checks per second)
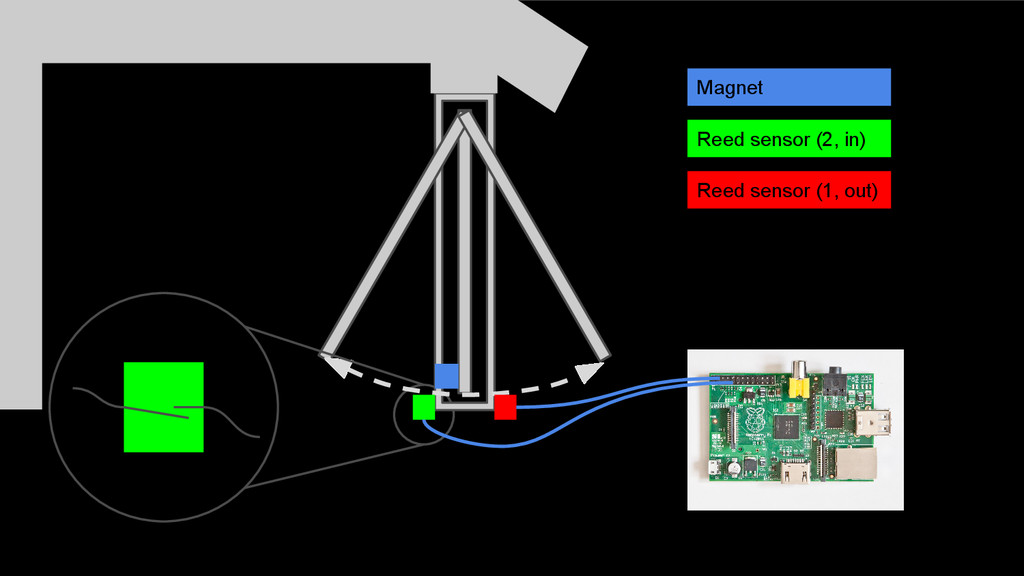
00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 000000000000000011111022000000000000000000000000000222000011111111111111111111111111111111100022 Longest “Zero- segment” (Passage) In oder Out? “Segment” 1. Last direction before longest zero segment 2. First direction 3. Number of in/out segments before the longest zero segment Criteria “Head” (Flap opens)
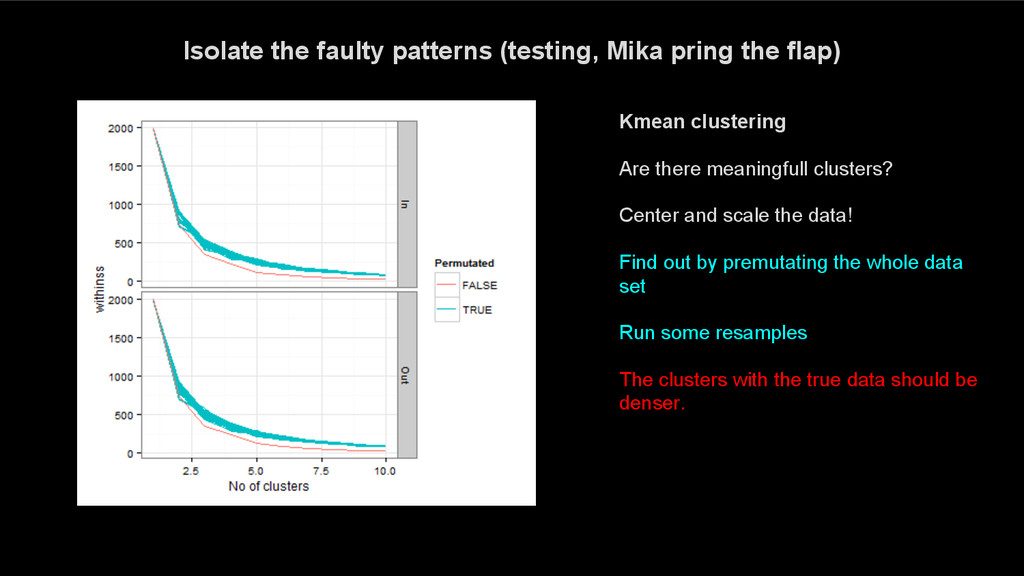
data! Find out by premutating the whole data set Run some resamples The clusters with the true data should be denser. Isolate the faulty patterns (testing, Mika pring the flap)
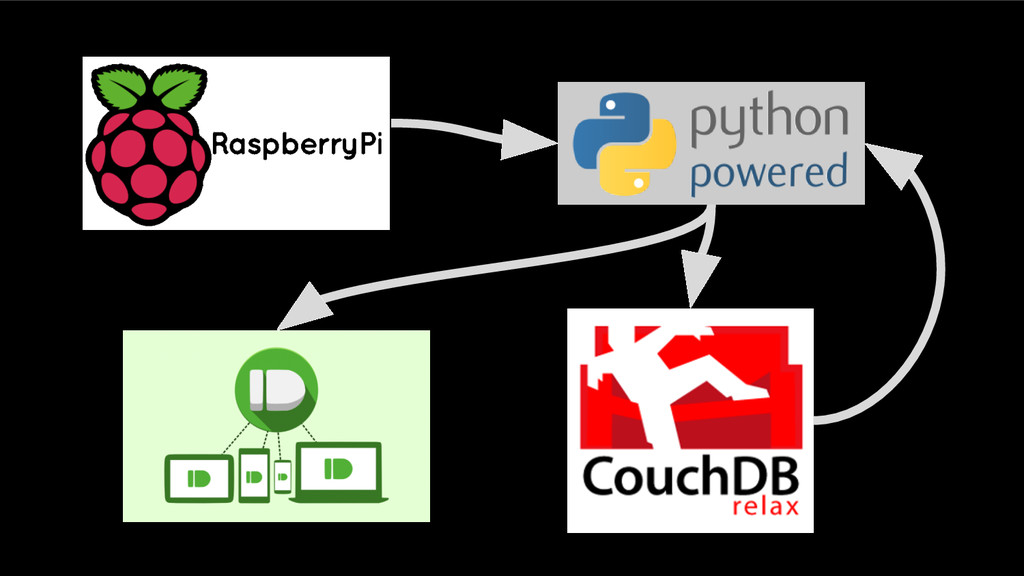
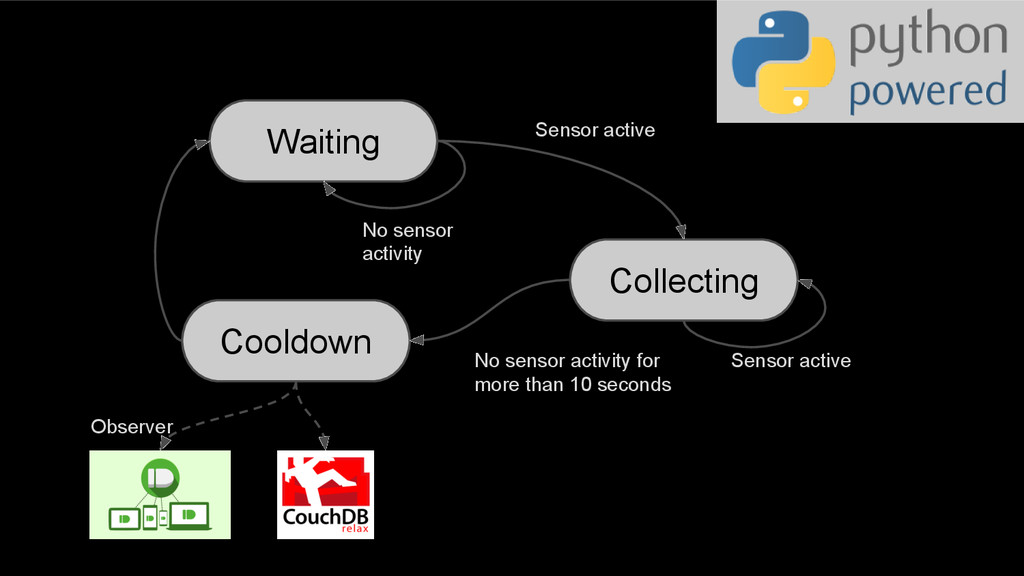
Use the cluster labels for patterns Train a model (yes, validate and test…) Apply the model to new patterns Give feedback (send a notification) Store the predicted class Add most confident predictions to train Retrain the model (eventually down- weight by proprensity score and “age”) http://is.tuebingen.mpg.de/fileadmin/user_upload/files/publications/taxo_[0].pdf https://en.wikipedia.org/wiki/Ma% C3%9F#/media/File: Jugg_with_Beer_Loewenbraeu_ one_liter.JPG
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}