Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
強化学習アルゴリズムPPOの改善案を考えてみた
Search
NearMeの技術発表資料です
PRO
August 22, 2025
200
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
強化学習アルゴリズムPPOの改善案を考えてみた
NearMeの技術発表資料です
PRO
August 22, 2025
More Decks by NearMeの技術発表資料です
See All by NearMeの技術発表資料です
PosthogのA/Bテスト機能の紹介
nearme_tech
PRO
1
21
AIフレンドリーなプロダクトに向けて
nearme_tech
PRO
1
50
初めてのLean言語
nearme_tech
PRO
0
76
Apache Airflow Workflow orchestration without turning cron into spaghetti
nearme_tech
PRO
1
21
実務で役立つ幾何学 ボロノイ図の基礎から グラフ・ネットワーク応用まで
nearme_tech
PRO
1
59
SQL/ID抽出タスクから考える 実践的なハルシネーション対策
nearme_tech
PRO
1
67
OpenCode & Local LLM
nearme_tech
PRO
0
200
OpenCode Introduction
nearme_tech
PRO
0
59
【Browser Automation × AI】 Stagehandを試してみよう
nearme_tech
PRO
0
160
Featured
See All Featured
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
WENDY [Excerpt]
tessaabrams
11
38k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
380
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Between Models and Reality
mayunak
4
380
Un-Boring Meetings
codingconduct
0
350
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Documentation Writing (for coders)
carmenintech
77
5.4k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
0 強化学習アルゴリズムPPOの改善案を考えてみた 2025-08-22 第128回NearMe技術勉強会 Takuma KAKINOUE
1 概要 • 強化学習の従来のオンポリシーアルゴリズムの⽋点 ◦ 良い⾏動軌跡を⾒つけて⼀度学習しても、探索するうちに忘れてしまう • 提案⼿法 ◦ 報酬が⾼かったエピソードの各ステップの⾏動確率分布を記録する
◦ “記録した分布”と”現在の⽅策が出⼒した分布”のKLダイバージェンスを計算 ◦ 算出したKLダイバージェンスを最⼩化する項を⽬的関数に加える
2 提案⼿法の実装詳細 • ベースはProximal Policy Optimization(PPO)で⽬的関数のみ以下のよう に変更した ※提案⼿法は、Anchored Policy Optimization(APO)と名付けた
• KLダイバージェンスの計算⽅向は、best→θとした ◦ bestな分布を含むように(再現できるように)θが最適化される ◦ 逆向きだとbestな分布に含まれるようになるため縛りが強くなる
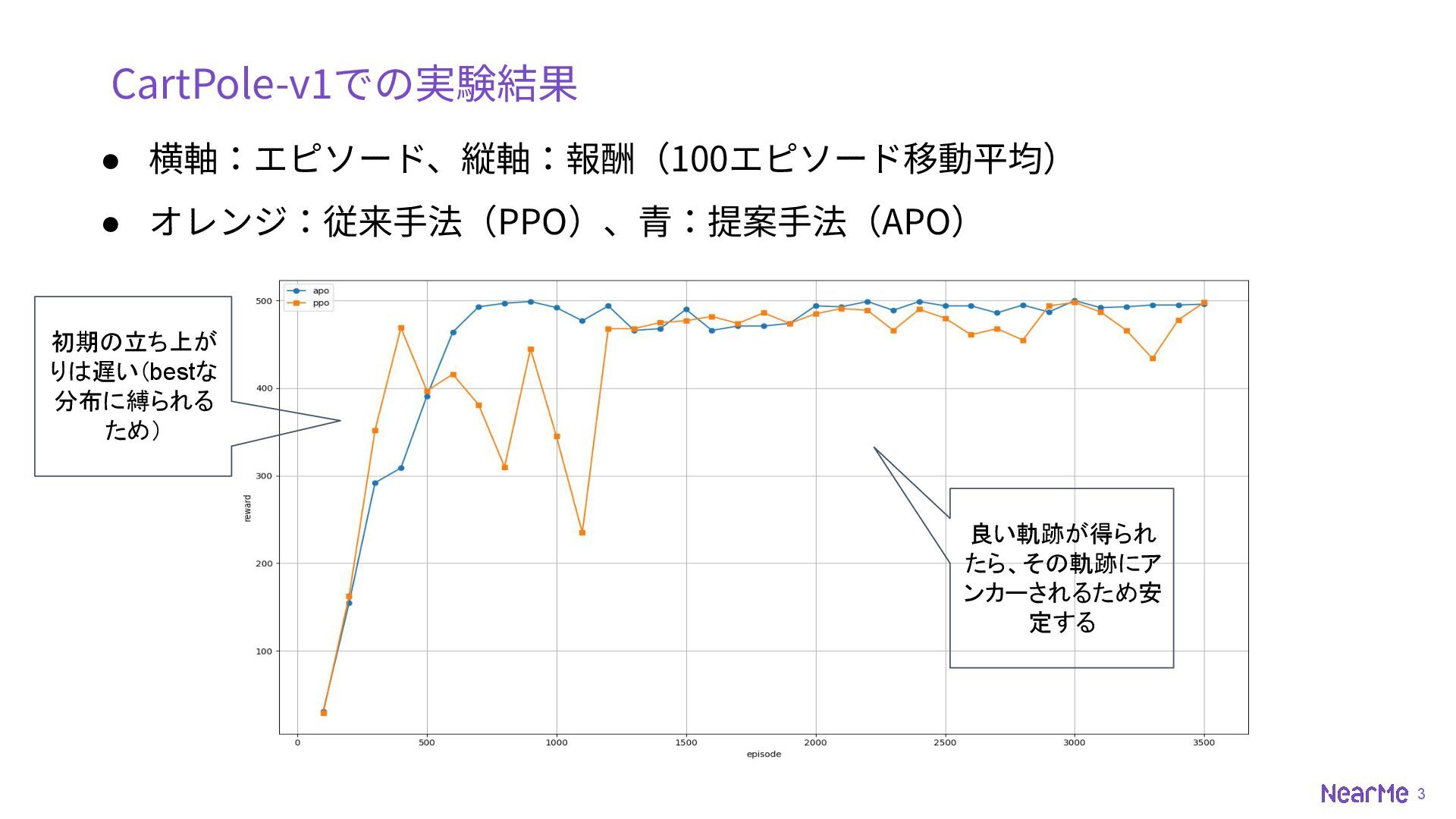
3 CartPole-v1での実験結果 • 横軸:エピソード、縦軸:報酬(100エピソード移動平均) • オレンジ:従来⼿法(PPO)、⻘:提案⼿法(APO) 初期の立ち上が りは遅い(bestな 分布に縛られる ため)
良い軌跡が得られ たら、その軌跡にア ンカーされるため安 定する
4 今後の展望 • 複数エージェントで並列化訓練させる仕組みと組み合わせてみる ◦ どれか1つのエージェントが良い⾏動軌跡を発⾒したら、他のエージェントに も共有して、良い⾏動軌跡にアンカーすることで学習の安定性と効率を向上 させる狙い • スーパーマリオなどの滅多にゴールに辿り着けない環境で真価を発揮するのでは
ないかと考えているので実験してみる
5 Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}