Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Rust 並列強化学習
Search
NearMeの技術発表資料です
PRO
July 18, 2025
97
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Rust 並列強化学習
NearMeの技術発表資料です
PRO
July 18, 2025
More Decks by NearMeの技術発表資料です
See All by NearMeの技術発表資料です
PosthogのA/Bテスト機能の紹介
nearme_tech
PRO
0
8
AIフレンドリーなプロダクトに向けて
nearme_tech
PRO
1
32
初めてのLean言語
nearme_tech
PRO
0
63
Apache Airflow Workflow orchestration without turning cron into spaghetti
nearme_tech
PRO
1
19
実務で役立つ幾何学 ボロノイ図の基礎から グラフ・ネットワーク応用まで
nearme_tech
PRO
1
56
SQL/ID抽出タスクから考える 実践的なハルシネーション対策
nearme_tech
PRO
1
65
OpenCode & Local LLM
nearme_tech
PRO
0
180
OpenCode Introduction
nearme_tech
PRO
0
55
【Browser Automation × AI】 Stagehandを試してみよう
nearme_tech
PRO
0
150
Featured
See All Featured
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
210
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
210
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
55k
Producing Creativity
orderedlist
PRO
348
40k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
The Curious Case for Waylosing
cassininazir
1
420
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
450
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Scaling GitHub
holman
464
140k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
0 Rust 並列強化学習 2025-07-18 第126回NearMe技術勉強会 Takuma KAKINOUE
1 今回のテーマ • Rustで強化学習のDQNアルゴリズムを実装した ◦ https://zenn.dev/kakky_hacker/articles/652bd7f9a1e6c1 • 今回はDQNを並列化し、マルチエージェントで強化学習してみる
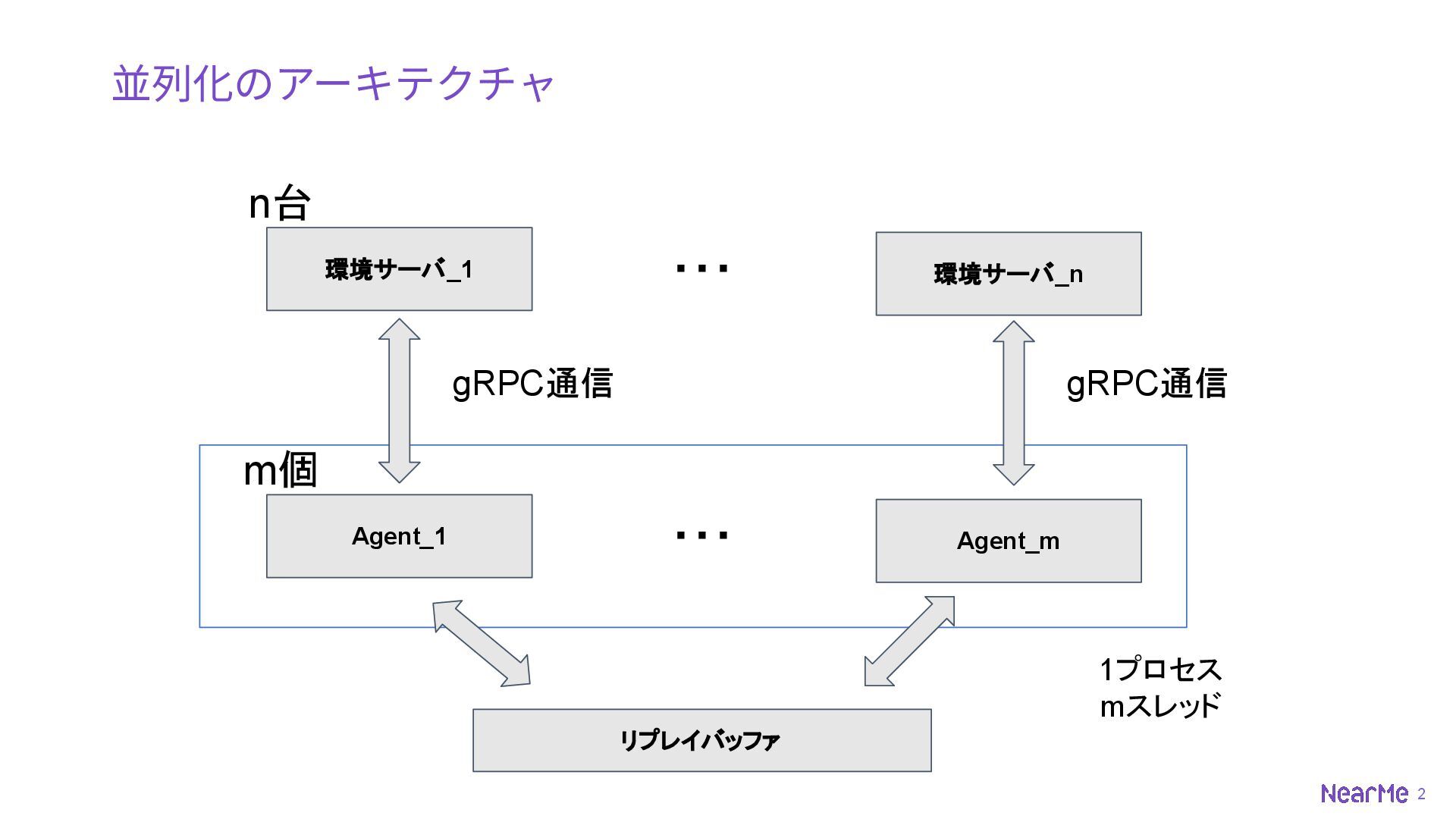
2 並列化のアーキテクチャ 環境サーバ_1 環境サーバ_n ・・・ n台 Agent_1 Agent_m ・・・ m個
リプレイバッファ gRPC通信 gRPC通信 1プロセス mスレッド
3 実装解説 • 左のコードのようにmemoryをMutexで包みつつTransitionBufferを定義 • 各agentにArc::cloneでTransitionBufferのインスタンスの参照を渡す ※TransitionBufferに経験をappendするとき、Q関数ネットを更新するために経験をサン プリングするときは、self.memory.lock()を⾏うことで排他制御する
4 実験概要 • OpenAI GymのLunarLander-v3で実験 ◦ https://gymnasium.farama.org/environments/box2d/lunar_lander/ ◦ DQN(single) vs
並列DQN(multi)で⽐較
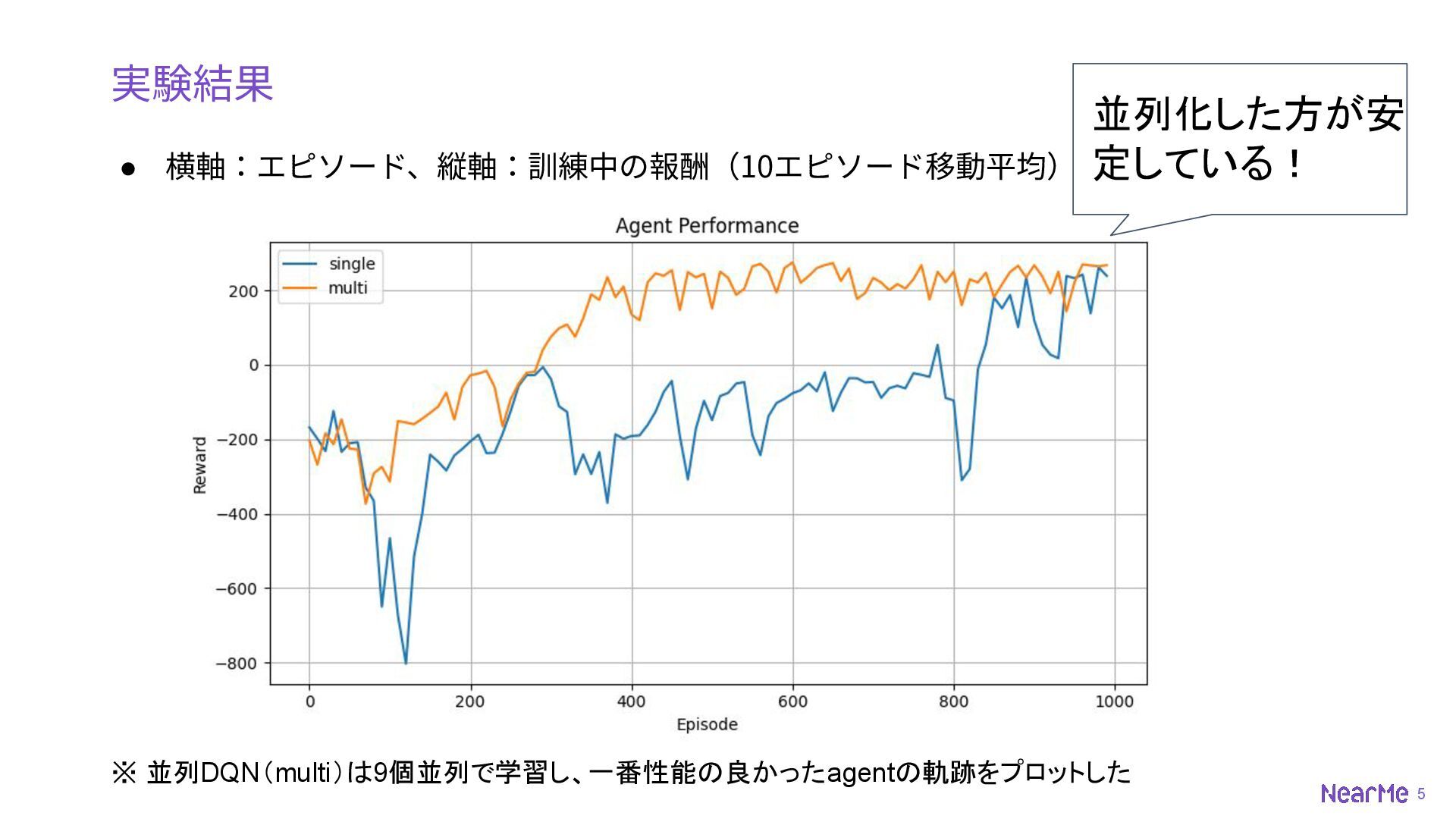
5 実験結果 • 横軸:エピソード、縦軸:訓練中の報酬(10エピソード移動平均) ※ 並列DQN(multi)は9個並列で学習し、一番性能の良かったagentの軌跡をプロットした 並列化した方が安 定している!
6 パフォーマンス⽐較 • single(Python) ※参考 ◦ 実⾏時間:410 s ◦ 使⽤メモリ:93.3
MB • single(Rust) ◦ 実⾏時間:360 s ← Pythonと⽐べて約12%削減! ◦ 使⽤メモリ:79.7 MB ← Pythonと⽐べて約15%削減! • multi(Rust)※9並列 ◦ 実⾏時間:727 s ← singleの約2.0倍に留まった! ◦ 使⽤メモリ:- ※ 実行時間は始め200エピソードにかかった時間 今回の本筋と関係ないが、 一応Rustの優位性を実証 とはいえ、 9並列はtoo muchだったかも(最適な並 列数はありそう ..!)
7 まとめ • リプレイバッファを複数agentで共有するだけというシンプルなアプ ローチで、学習を安定化&効率化させることに成功! • Rustを使うことで、簡単に並列学習を実装できた!
8 今後の展望 • リプレイバッファからのサンプリングの⼯夫 • エージェント毎にハイパーパラメータを変化させて並列学習 • DQNだけでなくPPOやSACなどのアルゴリズムも並列化させて性能検証
9 おわりに • Starよろしくお願いします!⭐ ◦ https://github.com/kakky-hacker/reinforcex
10 実験⽅法詳細 • モデル ◦ 全結合ネットワーク ◦ ニューロン数:300個 ◦ 中間層:2層
◦ 活性化関数:relu • 最適化関数 ◦ Adam ◦ 学習率:3e-4 • DQNのハイパーパラメータ ◦ 更新間隔:8 step ◦ ターゲットネットワークの更新間隔:50 step ◦ ⽅策:ε decay ε-greedy(1.0→0.05, 10000 step) ◦ 割引率:0.99 • CPU → Intel Corei7-10870H, GPU→なし
11 Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}