Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RustでDeepQNetworkを実装する
Search
NearMeの技術発表資料です
PRO
March 21, 2025
62
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RustでDeepQNetworkを実装する
Rustで強化学習アルゴリズムをフルスクラッチで実装します。
ニューラルネット部分はtch-rsを用いています。
NearMeの技術発表資料です
PRO
March 21, 2025
More Decks by NearMeの技術発表資料です
See All by NearMeの技術発表資料です
PosthogのA/Bテスト機能の紹介
nearme_tech
PRO
1
7
AIフレンドリーなプロダクトに向けて
nearme_tech
PRO
1
32
初めてのLean言語
nearme_tech
PRO
0
61
Apache Airflow Workflow orchestration without turning cron into spaghetti
nearme_tech
PRO
1
19
実務で役立つ幾何学 ボロノイ図の基礎から グラフ・ネットワーク応用まで
nearme_tech
PRO
1
56
SQL/ID抽出タスクから考える 実践的なハルシネーション対策
nearme_tech
PRO
1
65
OpenCode & Local LLM
nearme_tech
PRO
0
180
OpenCode Introduction
nearme_tech
PRO
0
55
【Browser Automation × AI】 Stagehandを試してみよう
nearme_tech
PRO
0
150
Featured
See All Featured
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
How to make the Groovebox
asonas
2
2.3k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
2.9k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
400
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Design in an AI World
tapps
1
250
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
380
Evolving SEO for Evolving Search Engines
ryanjones
0
230
Deep Space Network (abreviated)
tonyrice
0
220
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Transcript
0 2025-03-21 第116回NearMe技術勉強会 Takuma KAKINOUE RustでDeepQNetworkを実装する (おまけ)tch-rsからcandleに移⾏した結果
1 はじめに • 今回のスライドは、Zennにアップロードした記事(以下、url)のダイジェストになり ます ◦ https://zenn.dev/kakky_hacker/articles/652bd7f9a1e6c1
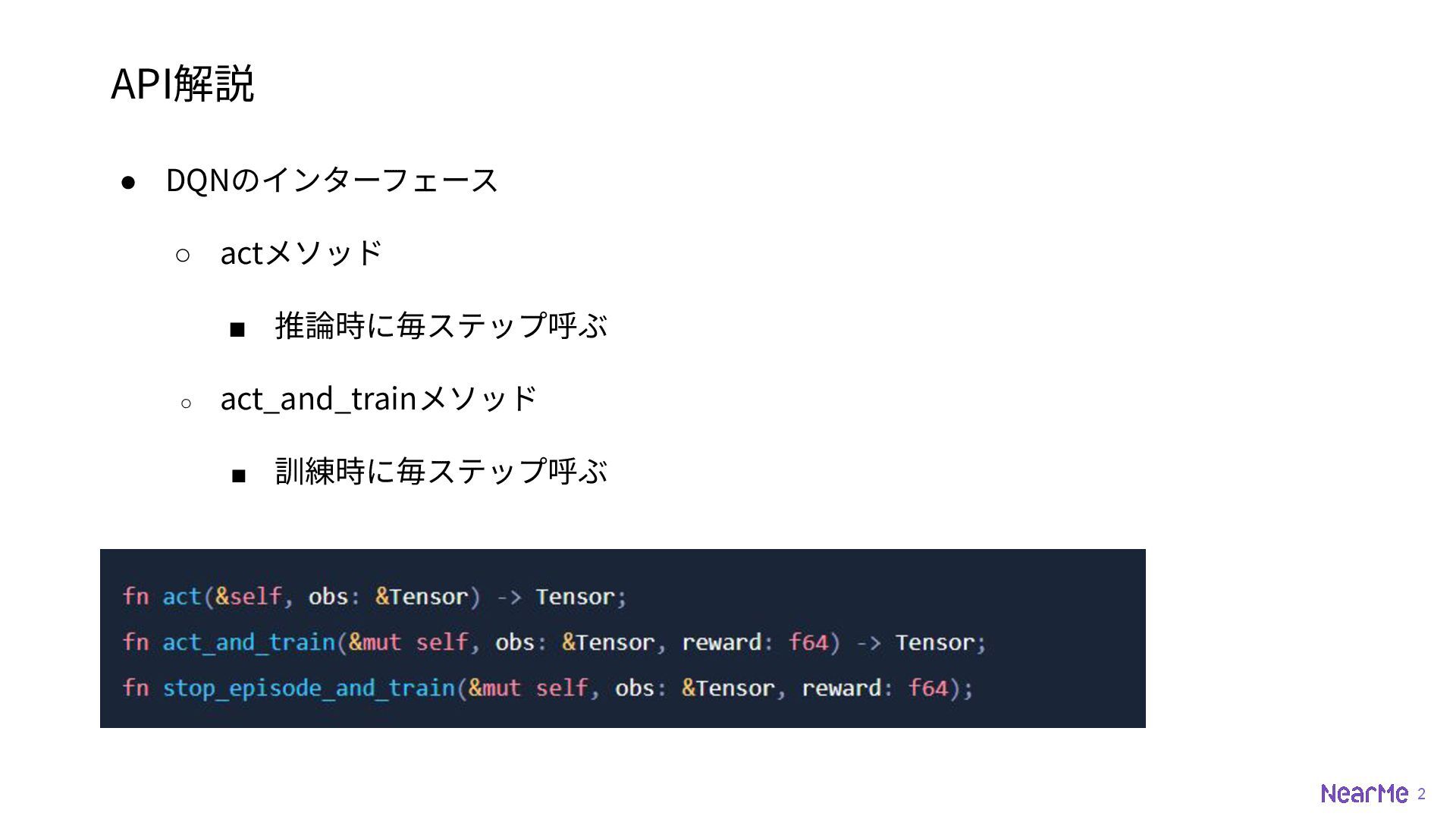
2 API解説 • DQNのインターフェース ◦ actメソッド ▪ 推論時に毎ステップ呼ぶ ◦ act_and_trainメソッド
▪ 訓練時に毎ステップ呼ぶ
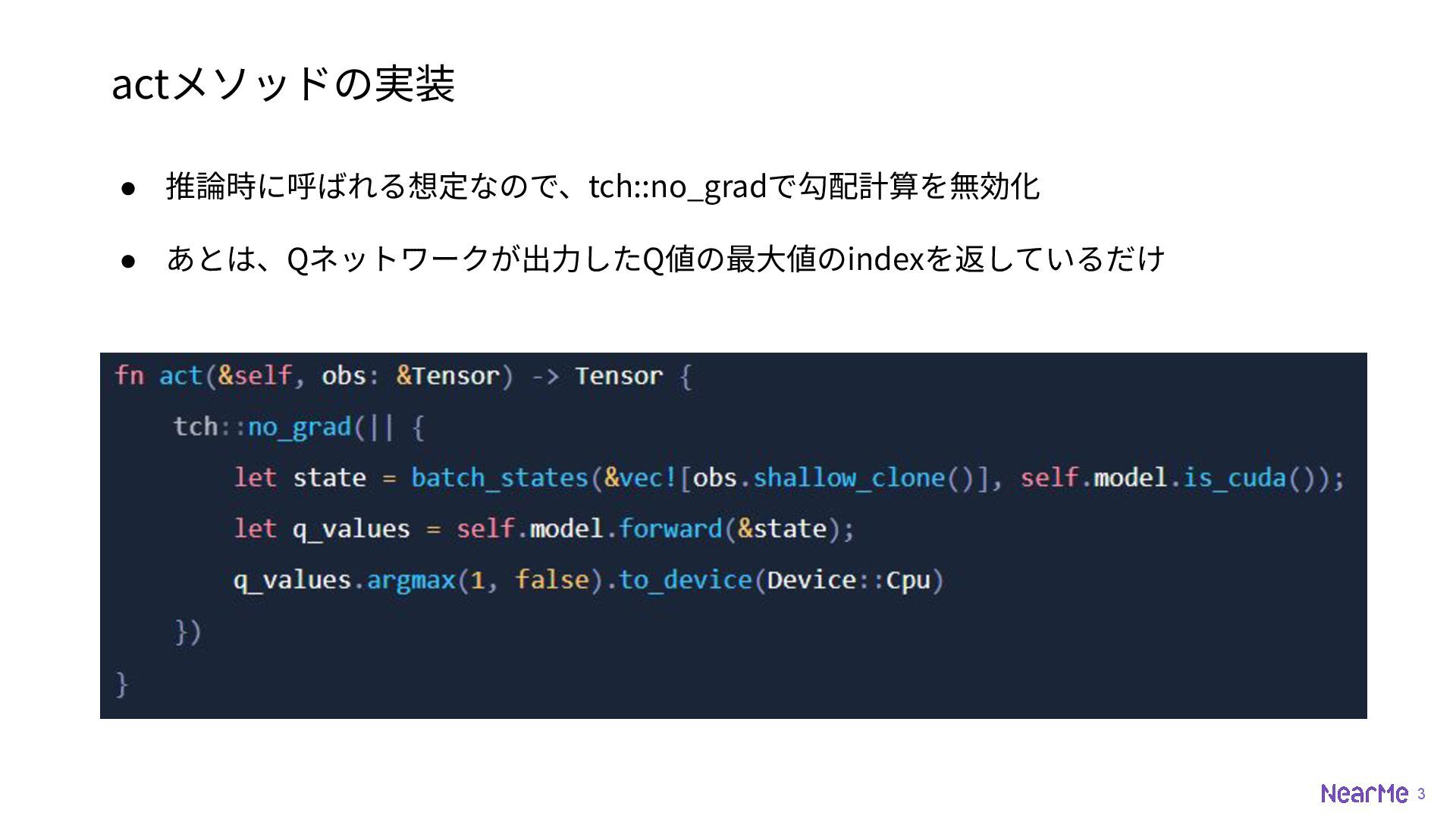
3 actメソッドの実装 • 推論時に呼ばれる想定なので、tch::no_gradで勾配計算を無効化 • あとは、Qネットワークが出⼒したQ値の最⼤値のindexを返しているだけ
4 act_and_trainメソッドの実装 • コードは⻑いので貼れないが、やっていることは以下。 ◦ 観測した状態に対して、最⼤Q値の⾏動を算出する ◦ 最⼤Q値の⾏動を選択するかランダム⾏動を選択するかを決める(ε-greedy法など) ◦ リプレイバッファに状態‧⾏動‧報酬を記録する
◦ update間隔に達していたら、 _updateメソッド(次スライドで解説)で重みを更新する ◦ 選択した⾏動を返す
5 _updateメソッドの実装 • ⼤まかな流れ ◦ リプレイバッファから経験をサンプリング ◦ Q値の更新式の各変数の値を求める ◦ 損失を計算して、重みを更新する
• Q値の更新式は以下
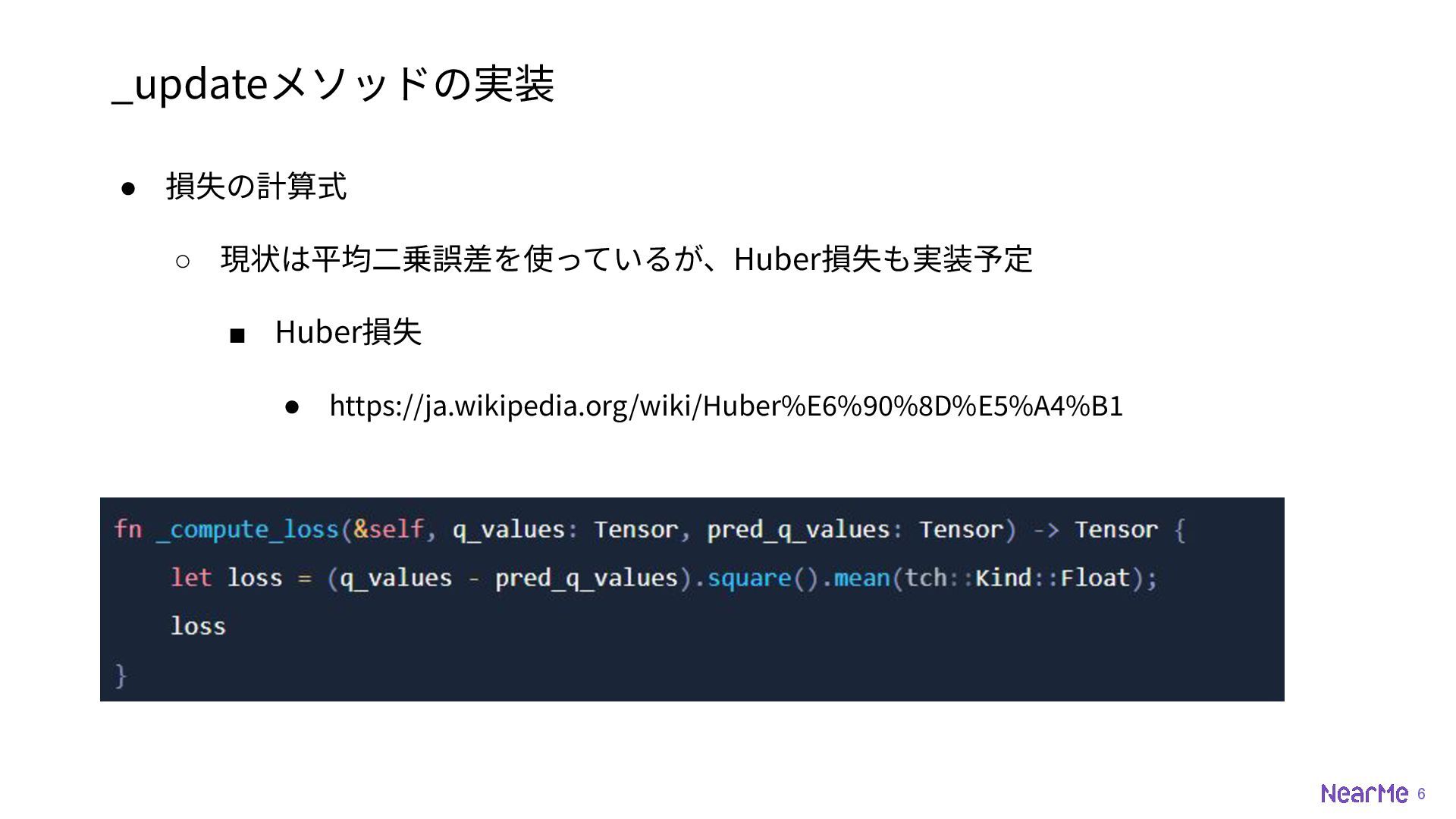
6 _updateメソッドの実装 • 損失の計算式 ◦ 現状は平均⼆乗誤差を使っているが、Huber損失も実装予定 ▪ Huber損失 • https://ja.wikipedia.org/wiki/Huber%E6%90%8D%E5%A4%B1
7 tch-rsとcandle • tch-rs(https://github.com/LaurentMazare/tch-rs) ◦ メリット ▪ コアの部分がPytorchなので実績と信頼性は⼗分 ◦ デメリット
▪ Pytorchの全機能をRustから呼べるわけではない ▪ しかし、全機能を含んだコア部分をinstallするので重くなりがち • candle(https://github.com/huggingface/candle) ◦ メリット ▪ Pure Rustなので、Rustから使う場合は型推論周りは良い ▪ パッケージが軽い、WebAssenbly対応 ◦ デメリット ▪ Pytorchと⽐べてまだ実績が少ない
8 tch-rsからcandle移⾏した結果 • packageの容量を1.7GB → 0.8GBに削減できた! • しかし、訓練時のメモリ使⽤量や実⾏時間はtch-rsの⽅が若⼲性能が良かった ◦ 結局、しばらくはtch-rsで開発を進めることに
9 今後の展望 • [WIP] Proximal Policy Optimizationの実装 ◦ PPO論⽂:https://arxiv.org/abs/1707.06347 •
Soft Actor Criticの実装 ◦ SAC論⽂:https://arxiv.org/abs/1801.01290 • リプレイバッファから経験をサンプリングするときに優先度を設ける ◦ Prioritized Replay Buffer論⽂:https://arxiv.org/abs/1511.05952 • 好奇⼼報酬による探索の効率化の導⼊ ◦ RND論⽂:https://arxiv.org/abs/1810.12894 ◦ SND論⽂:https://arxiv.org/abs/2302.11563
10 Thank you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 今後の展望 • [WIP] Proximal Policy Optimizationの実装 ◦ PPO論⽂:https://arxiv.org/abs/1707.06347 •](https://files.speakerdeck.com/presentations/5bc56ebd2c1d4310adae177c0dd48417/slide_9.jpg){kind=link}
{kind=link}