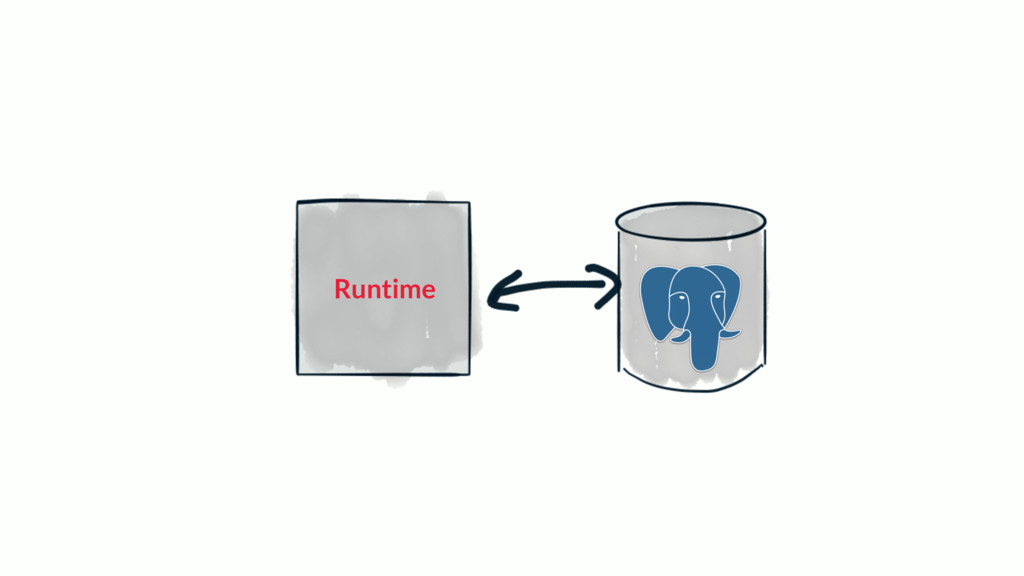
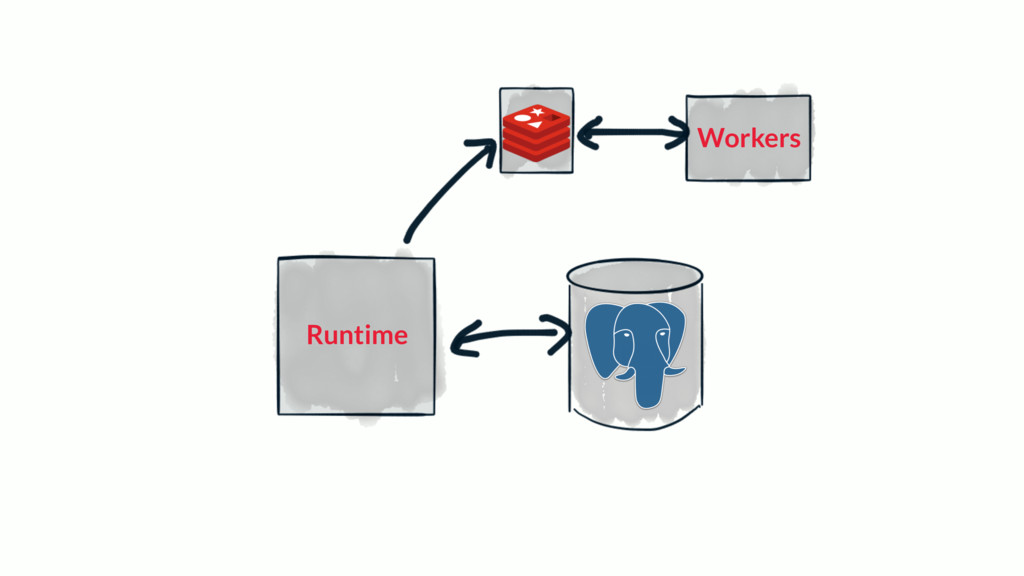
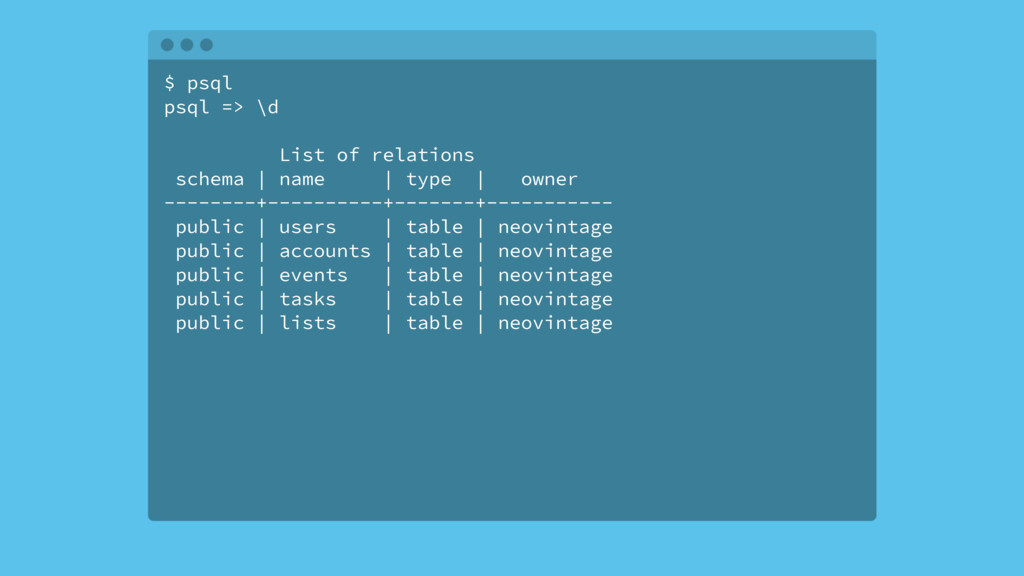
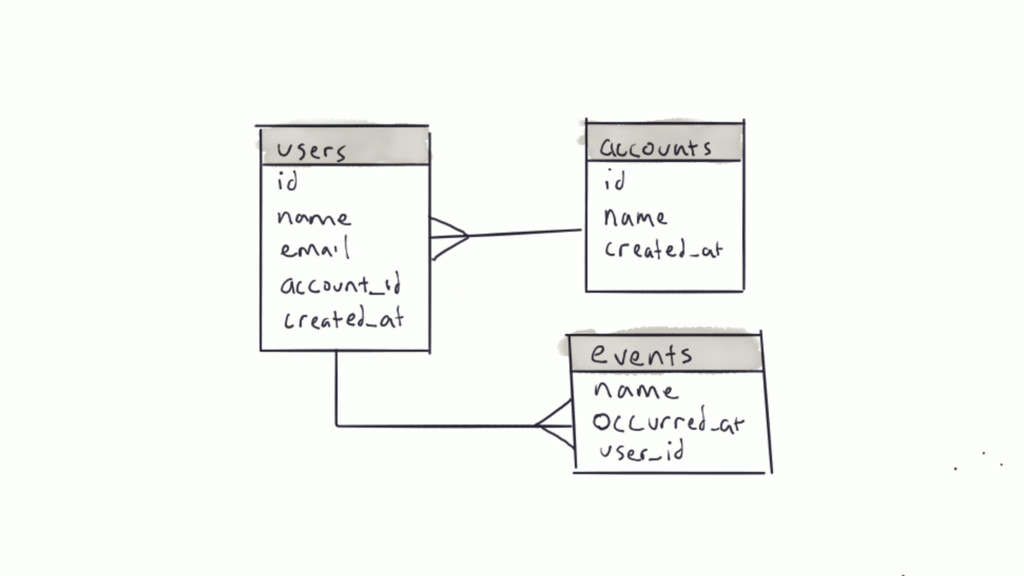
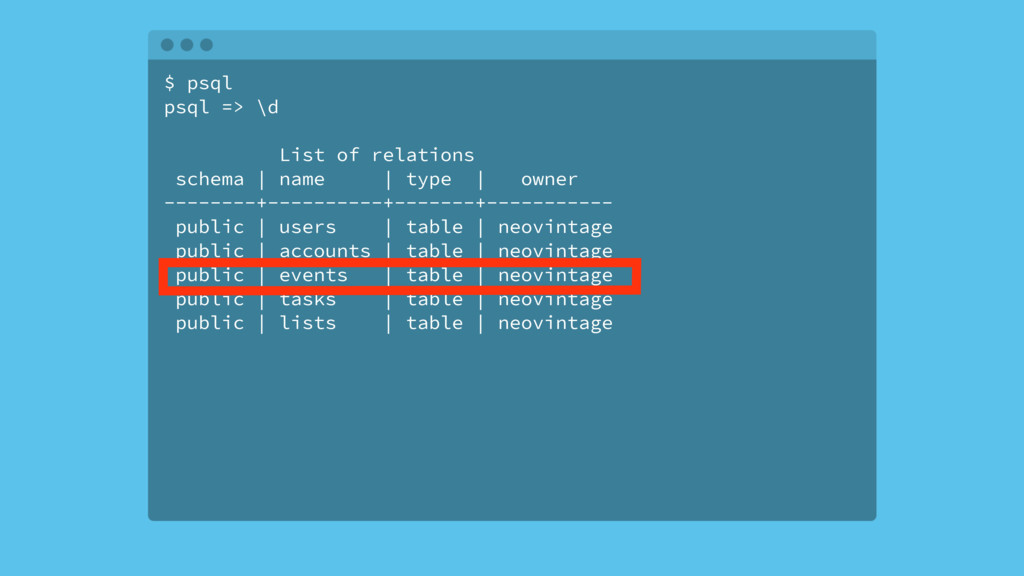
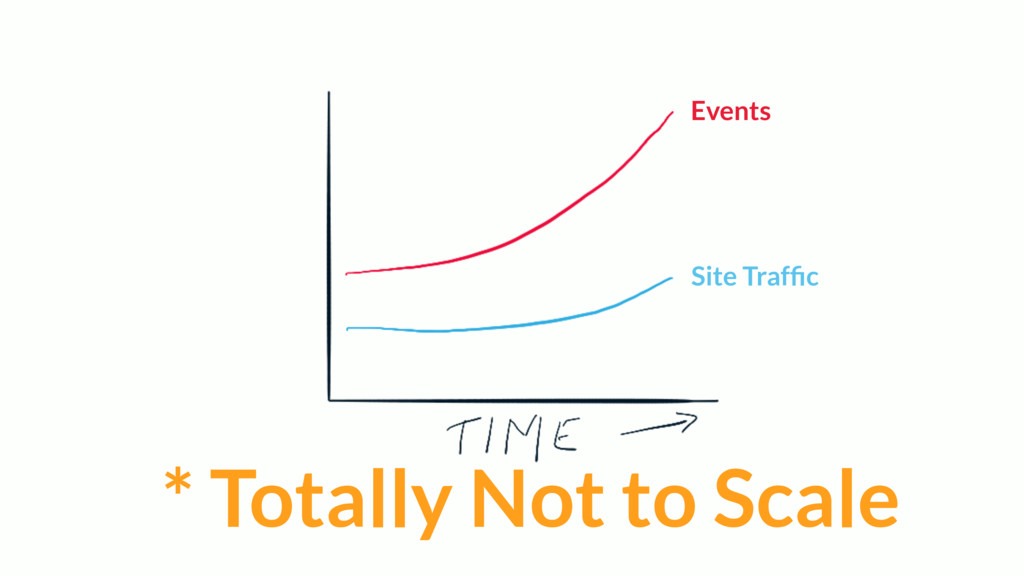
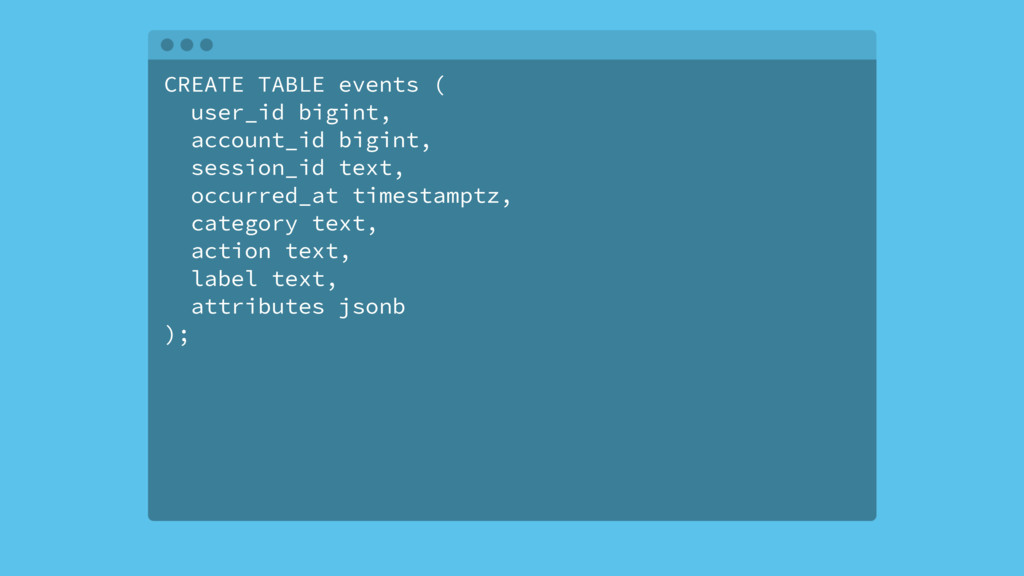
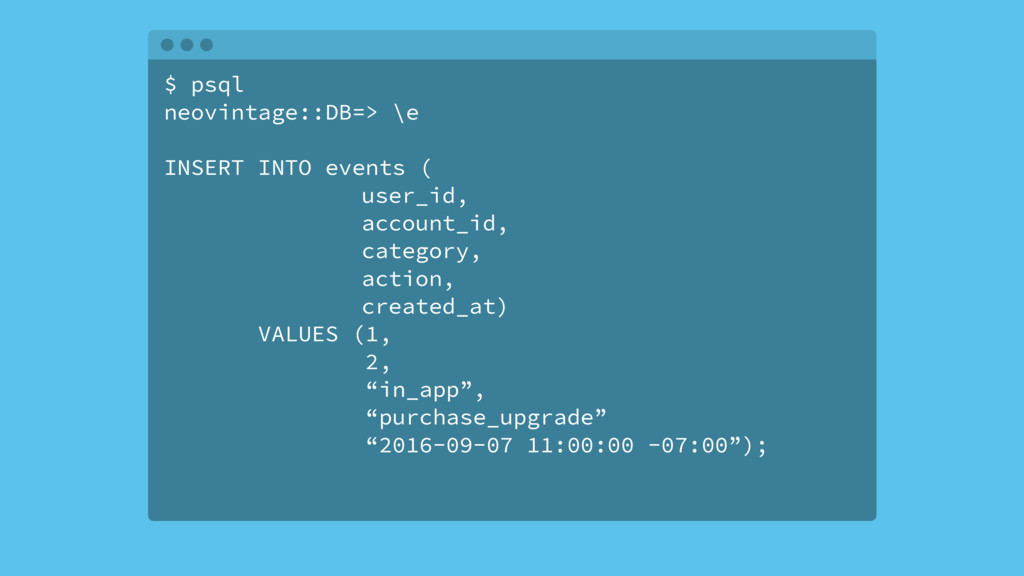
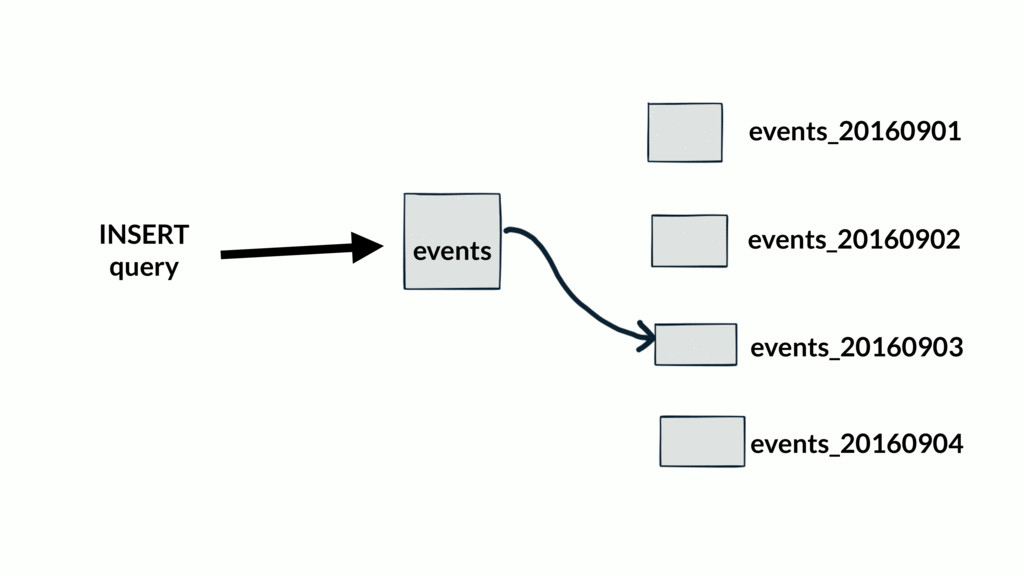
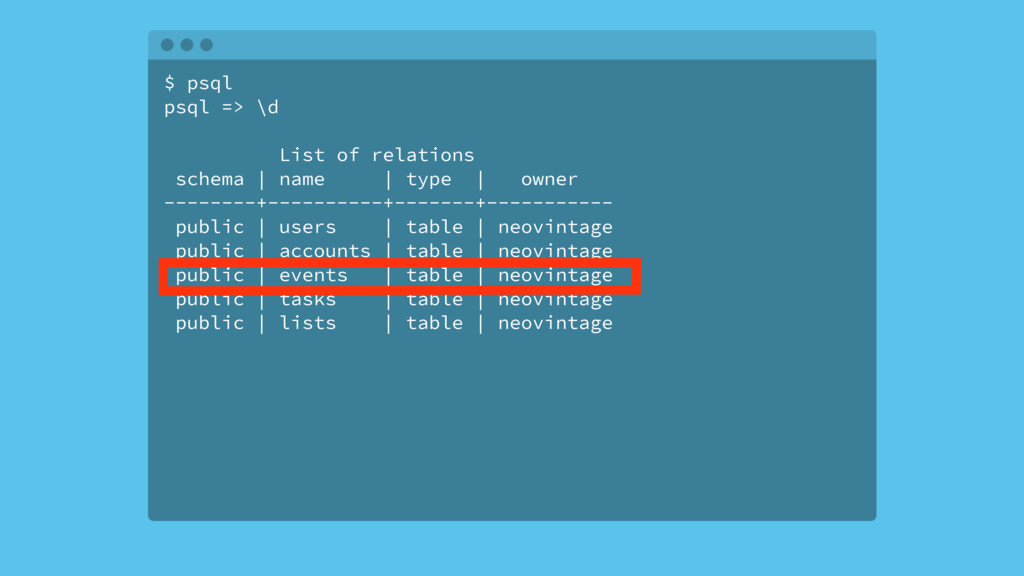
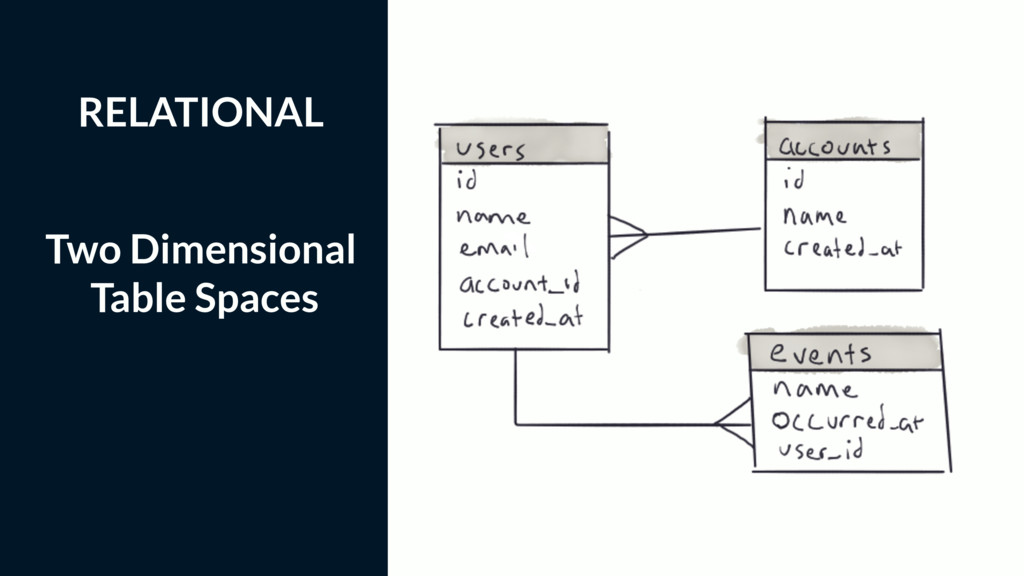
Most web applications start out with a Postgres database and it serves the application very well for an extended period of time. Based on type of application, the data model of the app will have a table that tracks some kind of state for either objects in the system or the users of the application. Names for this table include logs, messages or events. The growth in the number of rows in this table is not linear as the traffic to the app increases, it's typically exponential.
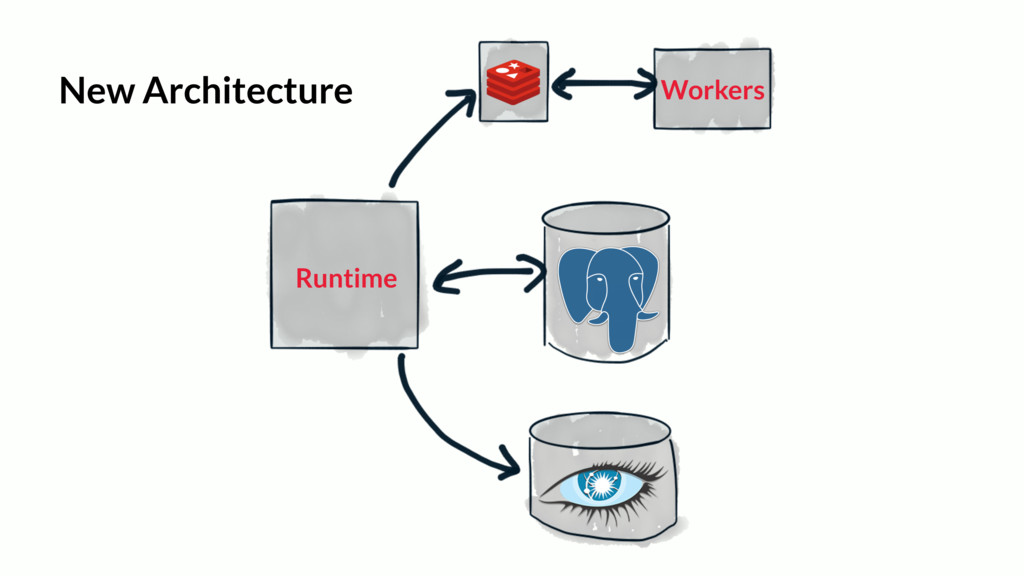
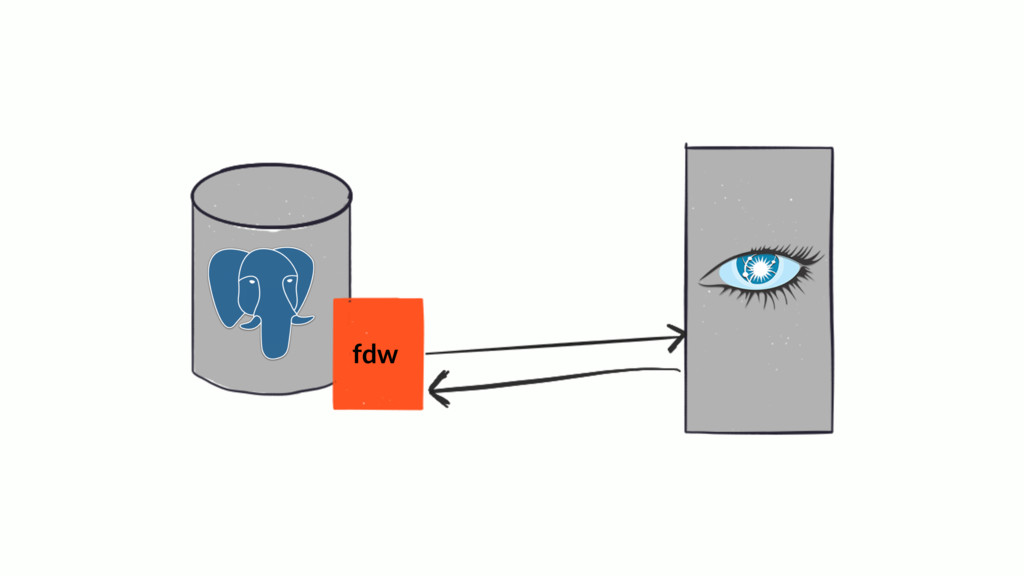
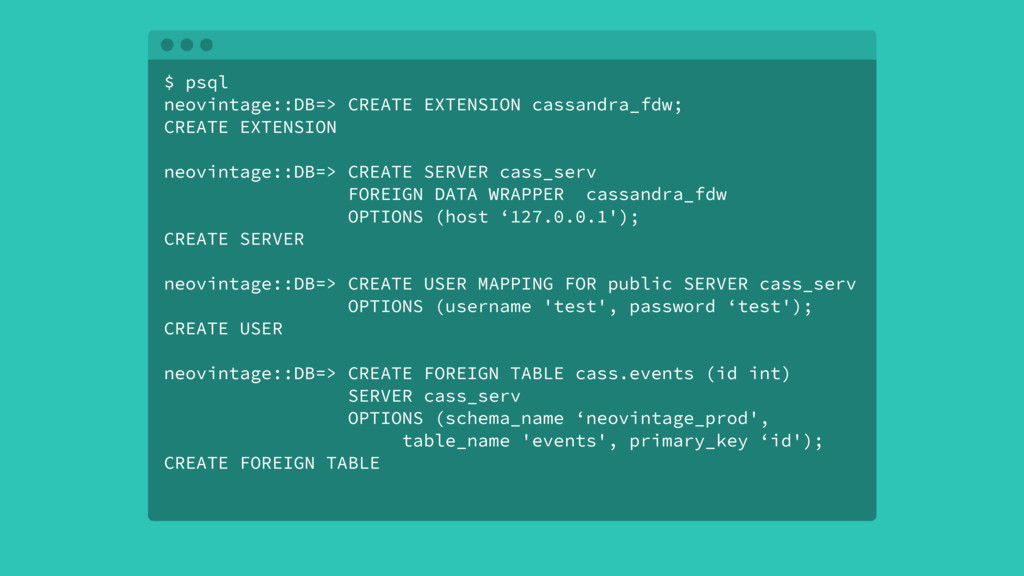
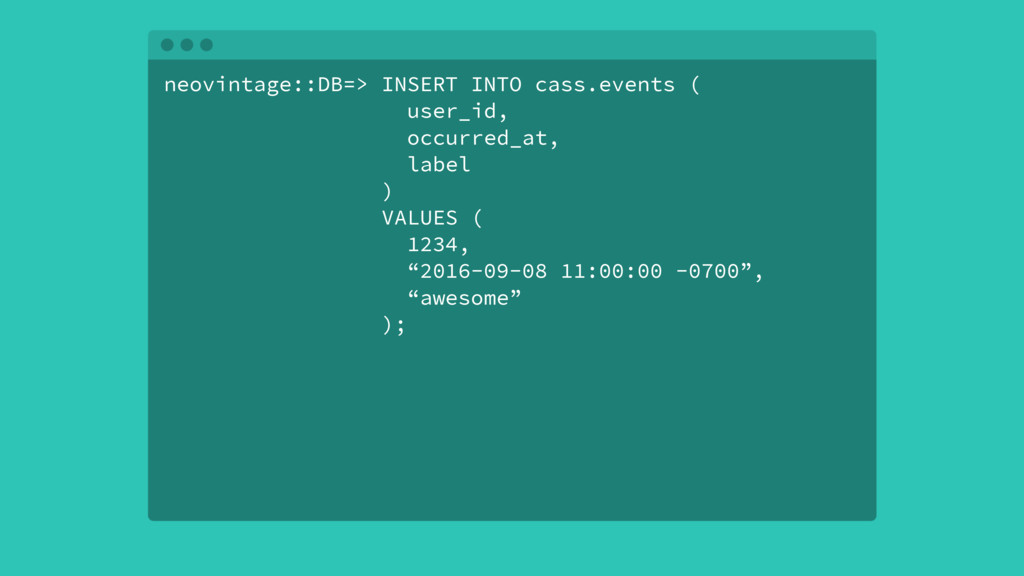
Over time, the state table will increasingly become the bulk of the data volume in Postgres, think terabytes, and become increasingly hard to query. This use case can be characterized as the one-big-table problem. In this situation, it makes sense to move that table out of Postgres and into Cassandra. This talk will walk through the conceptual differences between the two systems, a bit of data modeling, as well as advice on making the conversion.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
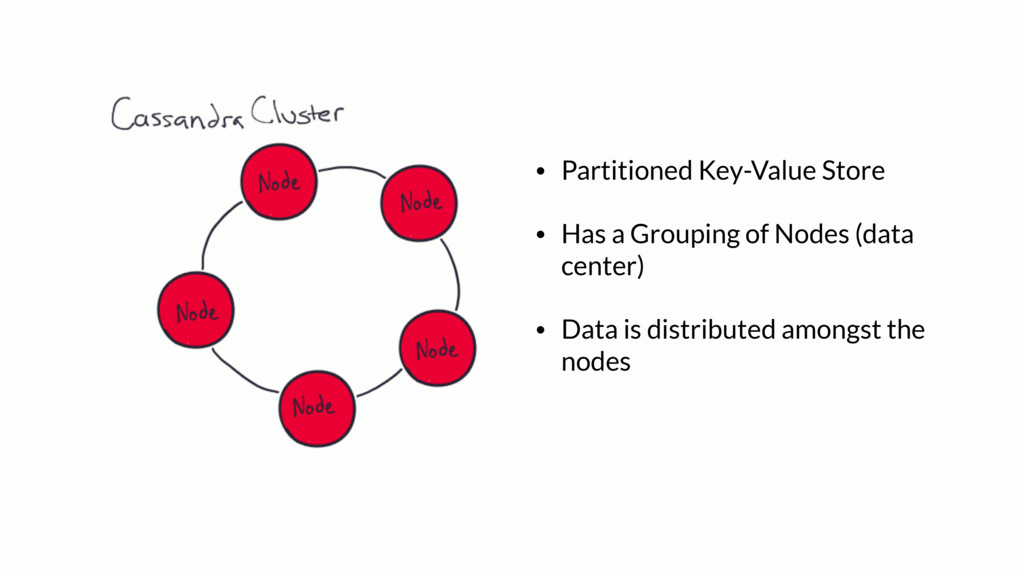{kind=link}
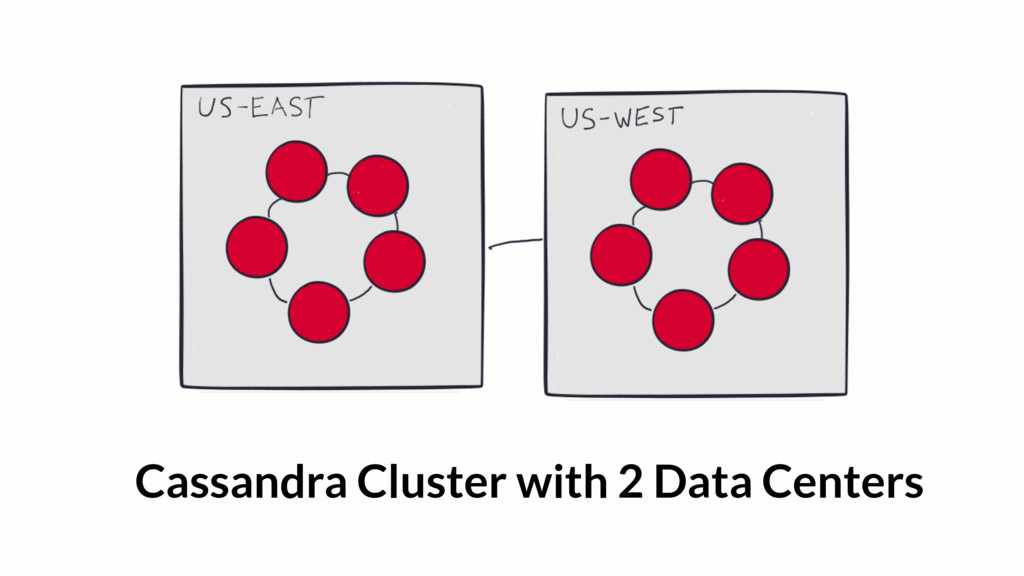{kind=link}
{kind=link}
![SQL-like [sēkwel lahyk] adjective Resembling SQL in appearance, behavior or](https://files.speakerdeck.com/presentations/96aae774448b4d33bb81087cf8229425/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
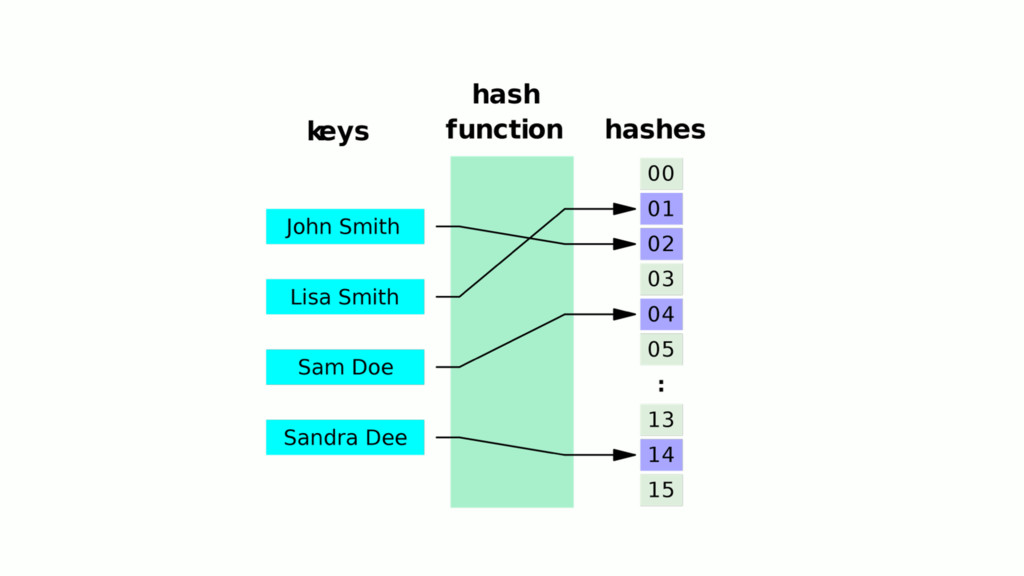{kind=link}
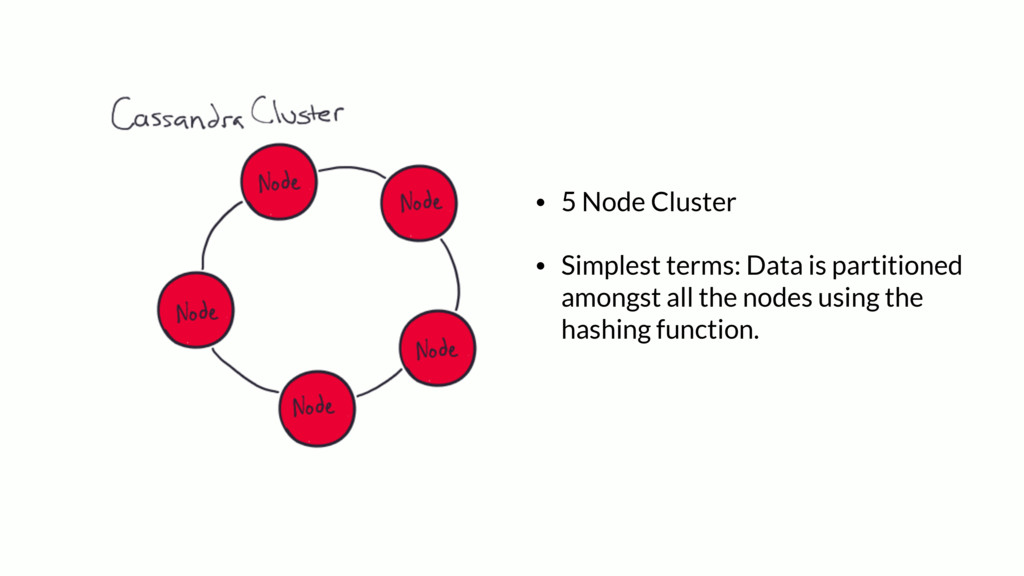{kind=link}
{kind=link}
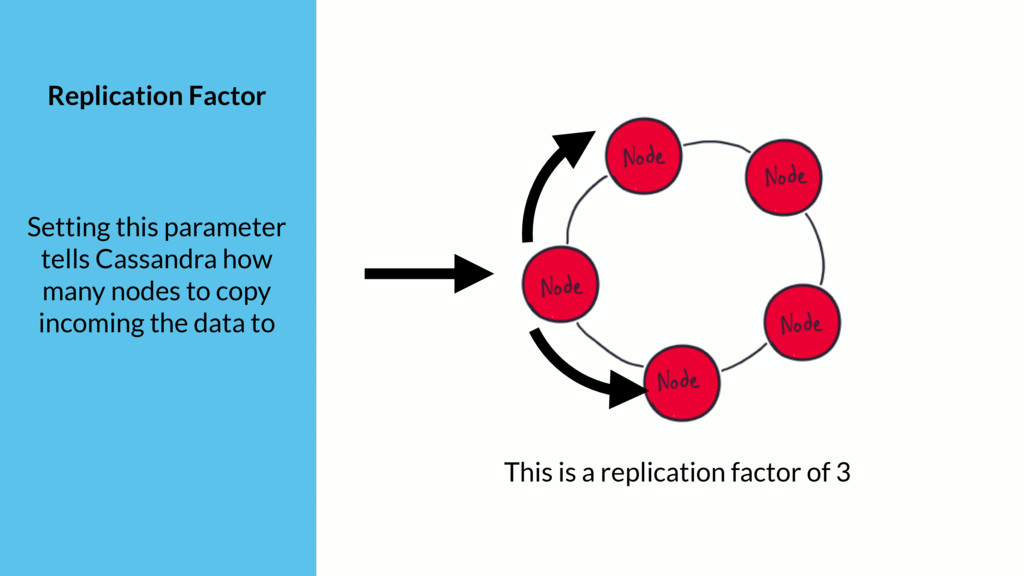{kind=link}
{kind=link}
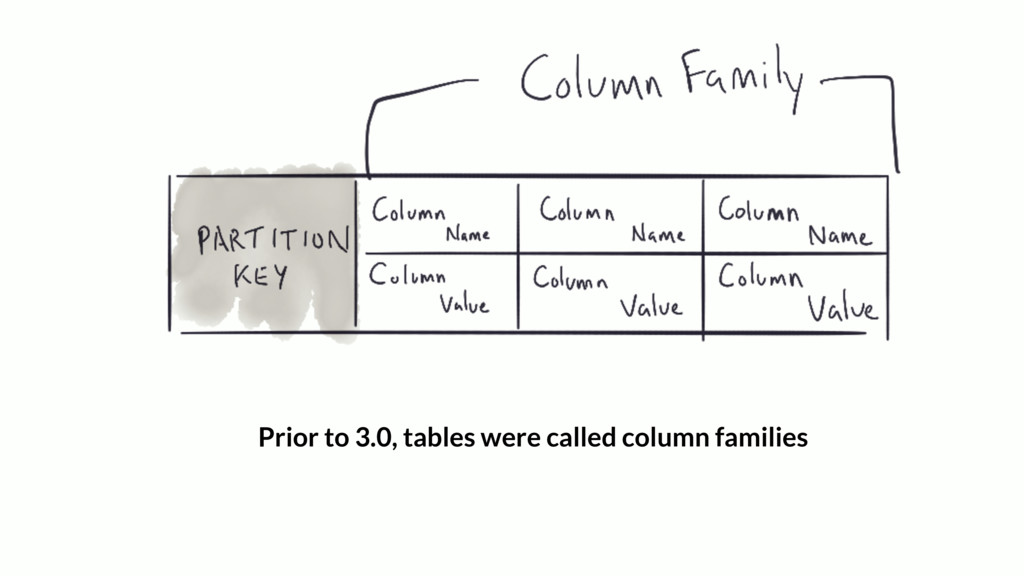{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
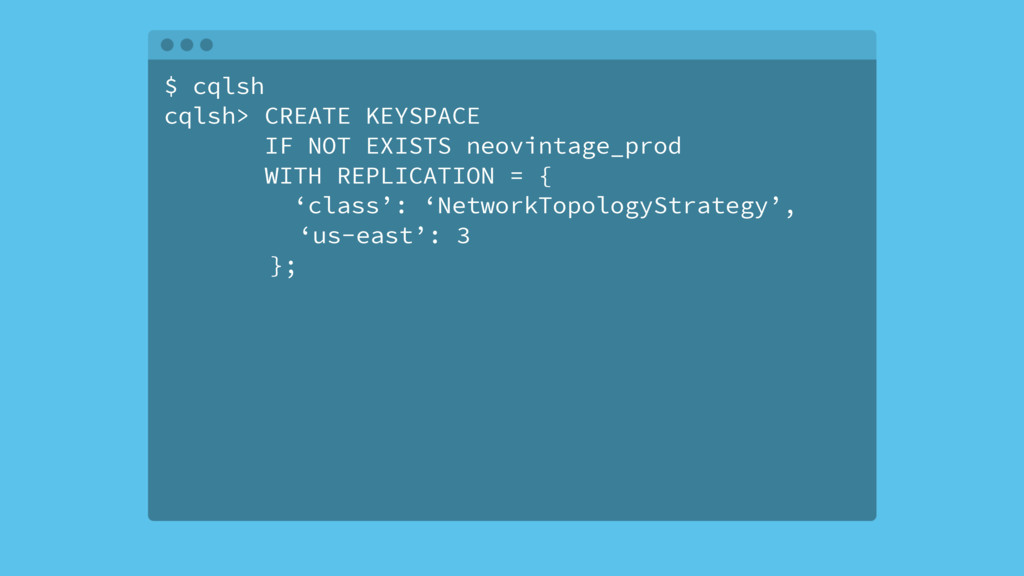{kind=link}
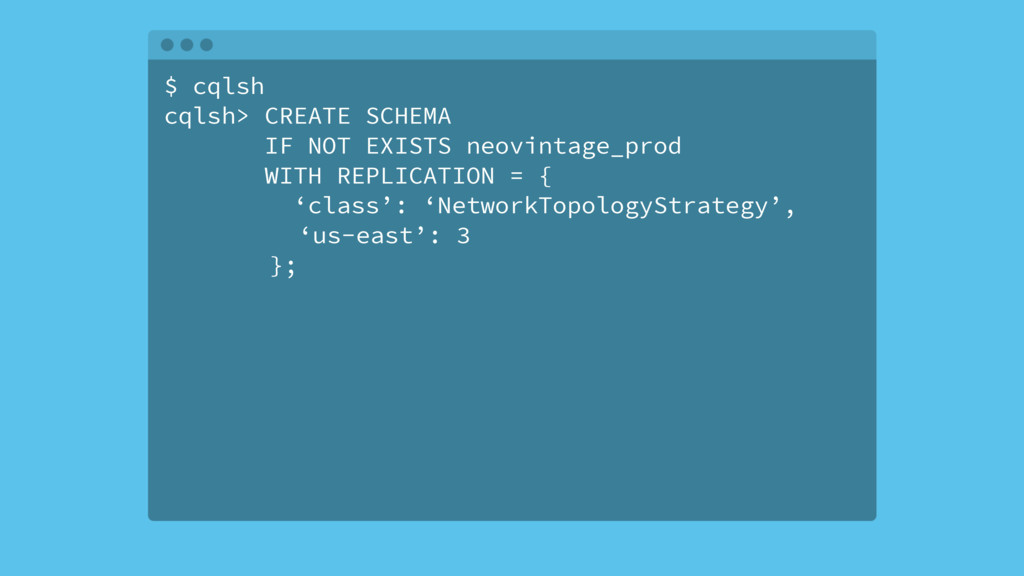{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
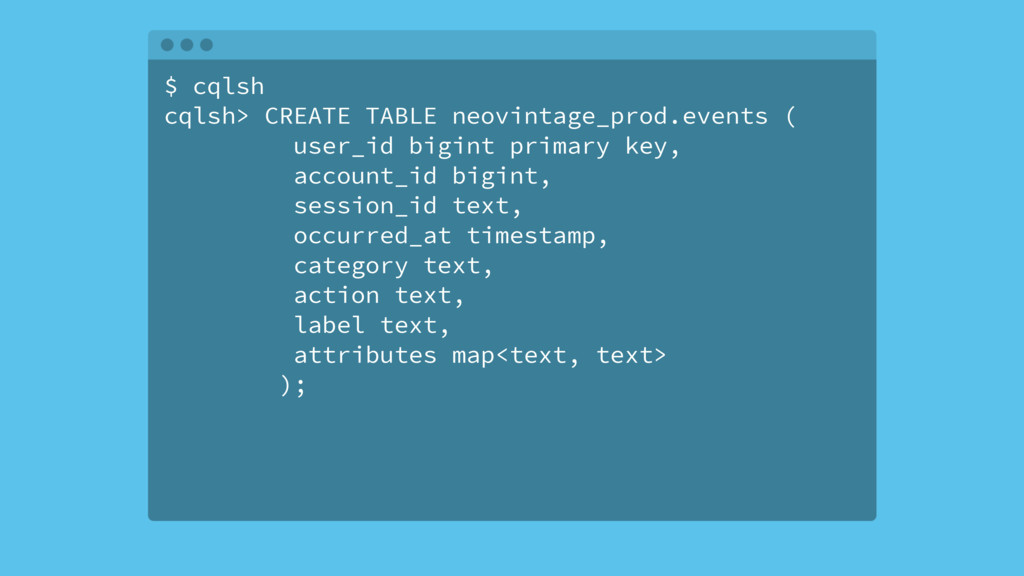{kind=link}
{kind=link}
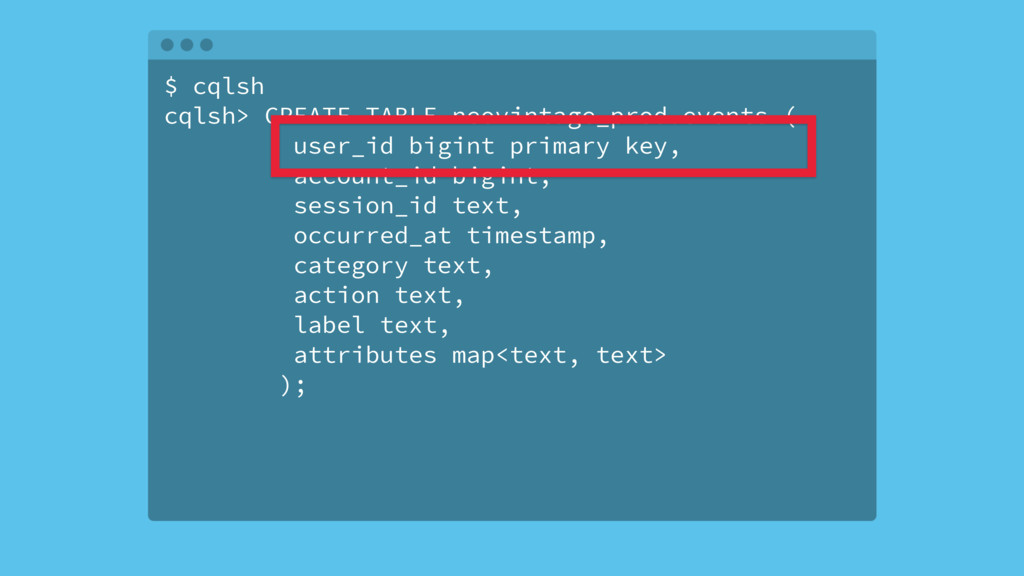{kind=link}
{kind=link}
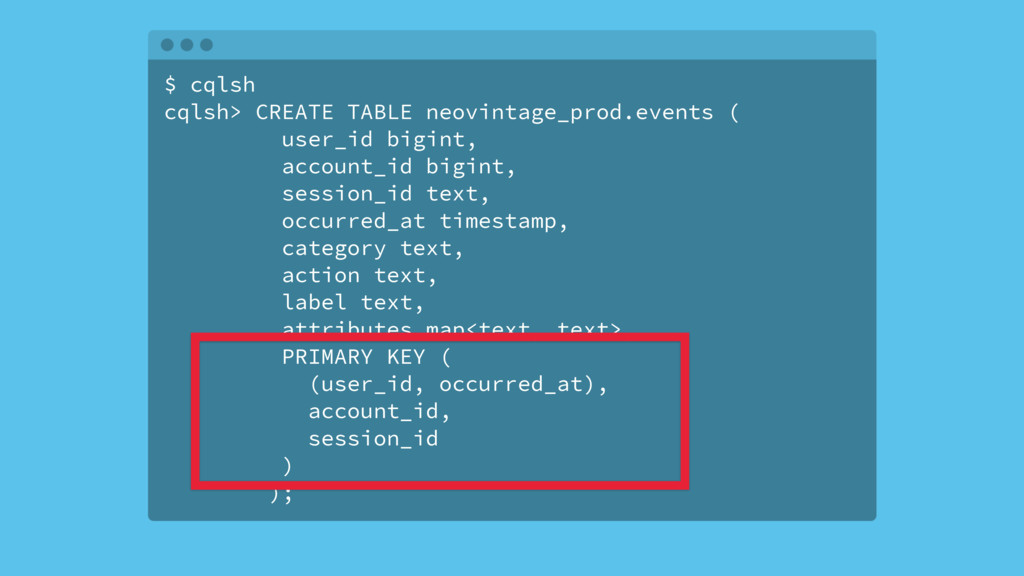{kind=link}
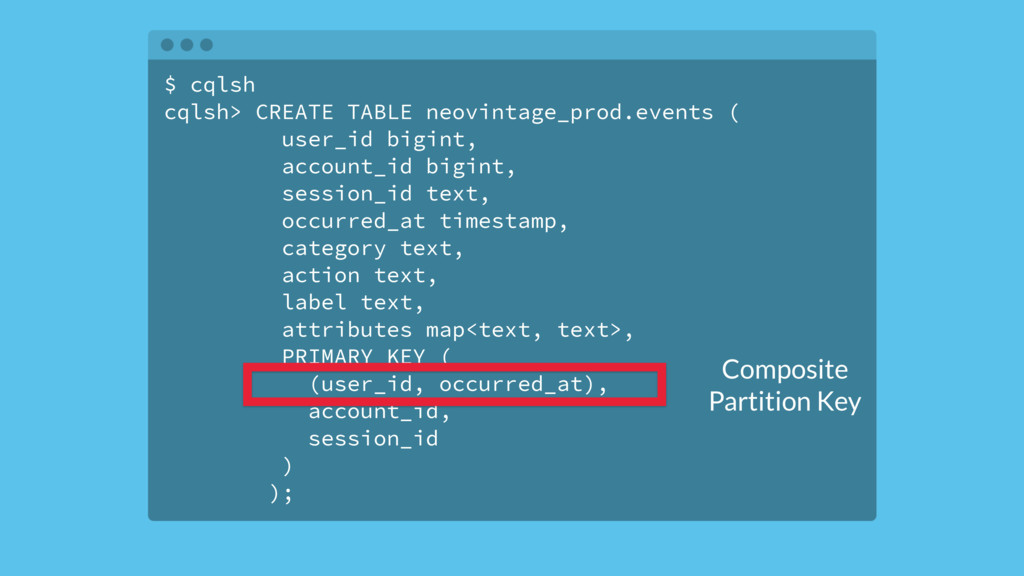{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
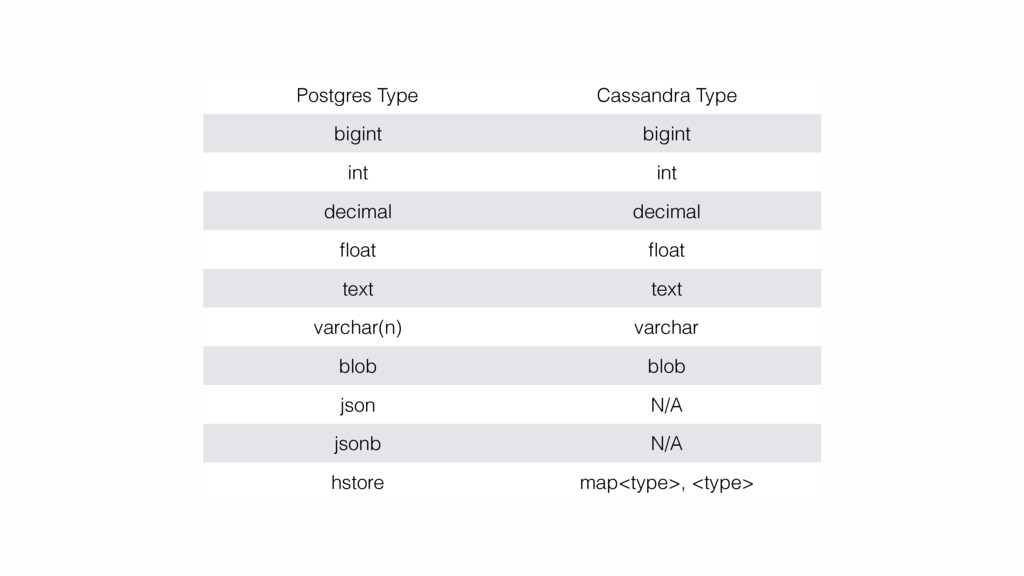{kind=link}
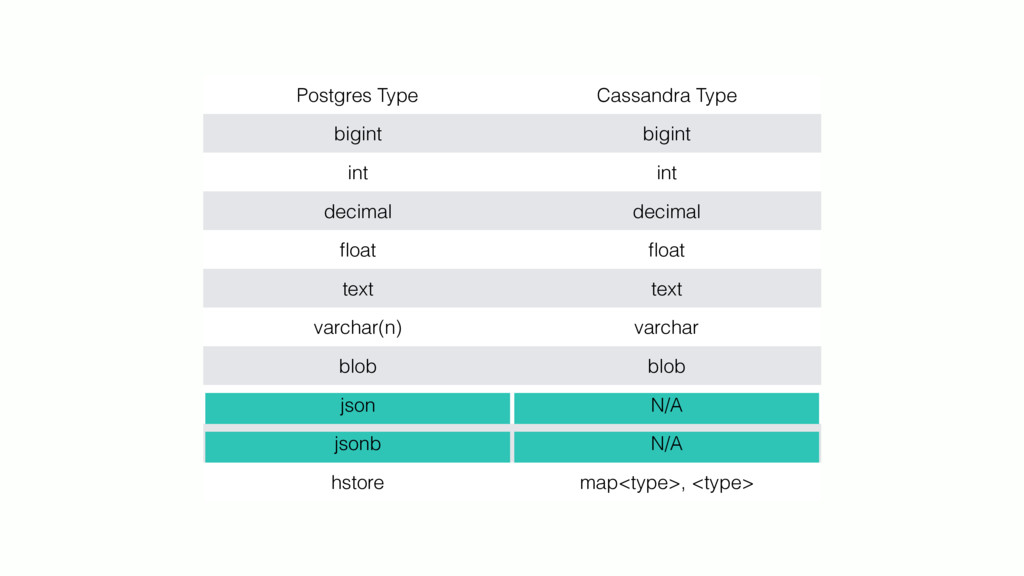{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
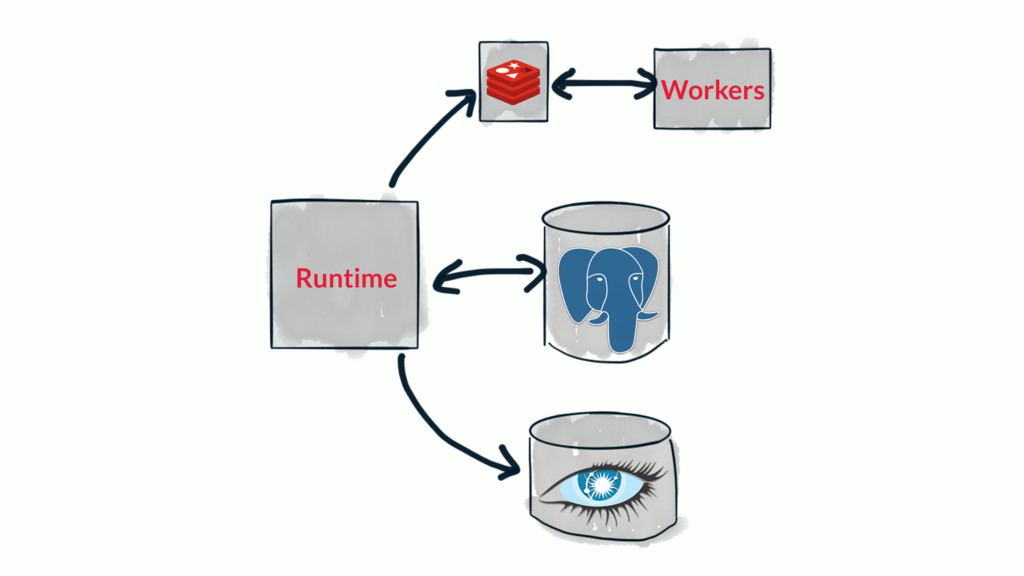{kind=link}
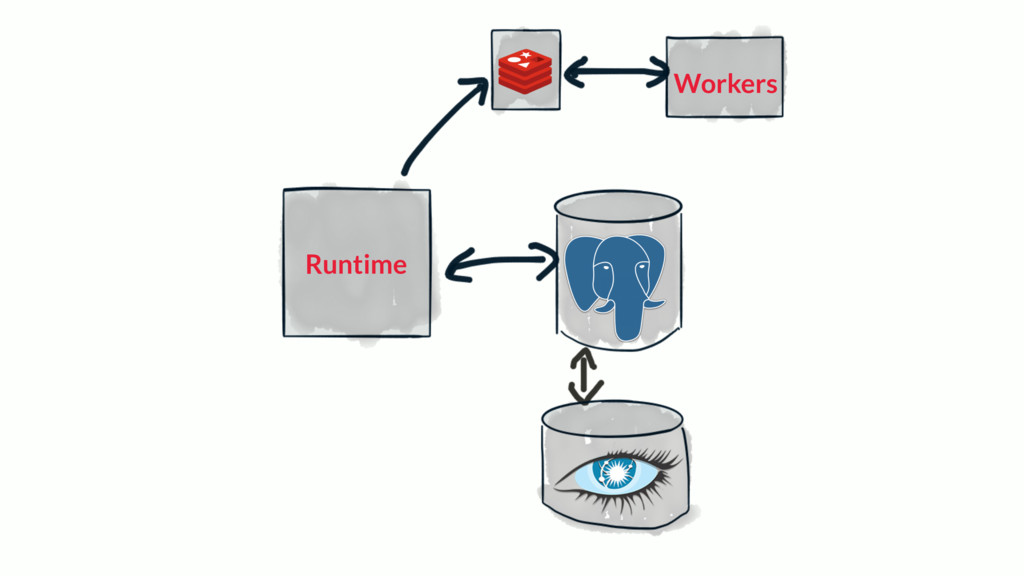{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}