of Roots and Features are---------------------- Token : जाऊ ं गा, Total Output : 1 [ Root : जा, Class : , Category : verb, Suffix : ऊ ं गा ] [ Gender : +masc, Number : -pl, Person : 1p, Case : x, Tense : +future, Aspect : x, Mood : x ] ोा -> [ Gender : +masc, Number : +pl, Person : x, Case : x, Tense : x, Aspect : x, Mood : x ] ग -> [ Gender : x, Number : x, Person : x, Case : x, Tense : +future, Aspect : x, Mood : x ] ऊ ं -> [ Gender : x, Number : -pl, Person : 1p, Case : x, Tense : x, Aspect : x, Mood : x ] Queried Word: लड़ना ------------------Set of Roots and Features are---------------------- Token : लड़ना, Total Output : 3 [ Root : लड़ना, Class : D, Category : noun, Suffix : Null ] [ Gender : +masc, Number : , Person : , Case : , Tense : , Aspect : , Mood : ] [ Root : लड़, Class : , Category : verb, Suffix : ना ] [ Gender : x, Number : x, Person : x, Case : x, Tense : x, Aspect : x, Mood : x ] [ Root : लड़, Class : , Category : verb, Suffix : ना ] [ Gender : +masc, Number : +pl, Person : x, Case : x, Tense : +infinitive, Aspect : x, Mood : x ] ोा -> [ Gender : +masc, Number : +pl, Person : x, Case : x, Tense : x, Aspect : x, Mood : x ] न -> [ Gender : x, Number : x, Person : x, Case : x, Tense : +infinitive, Aspect : x, Mood : x ]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Morphology - Various Approaches • Lexicalist Approach [Lieber, 1992] –](https://files.speakerdeck.com/presentations/11bddc40ae500131410102d8ec170fc5/slide_7.jpg){kind=link}
![Morphology - Various Approaches (cont..) • Affix-less Approach [Anderson, 1992]](https://files.speakerdeck.com/presentations/11bddc40ae500131410102d8ec170fc5/slide_8.jpg){kind=link}
{kind=link}
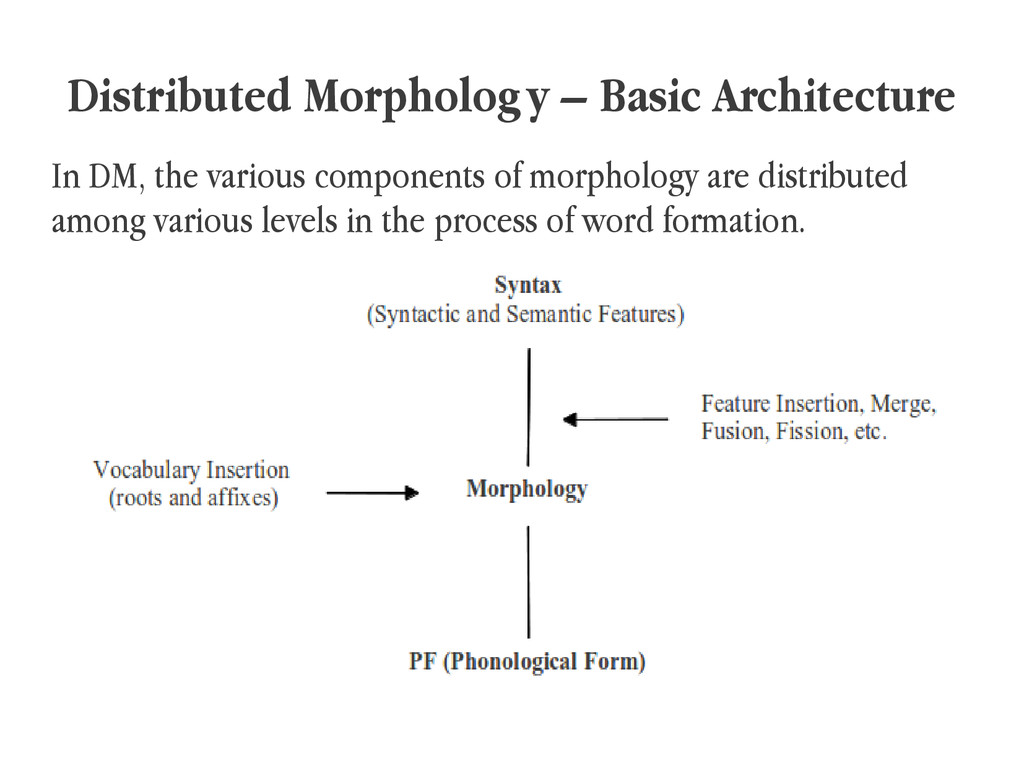{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
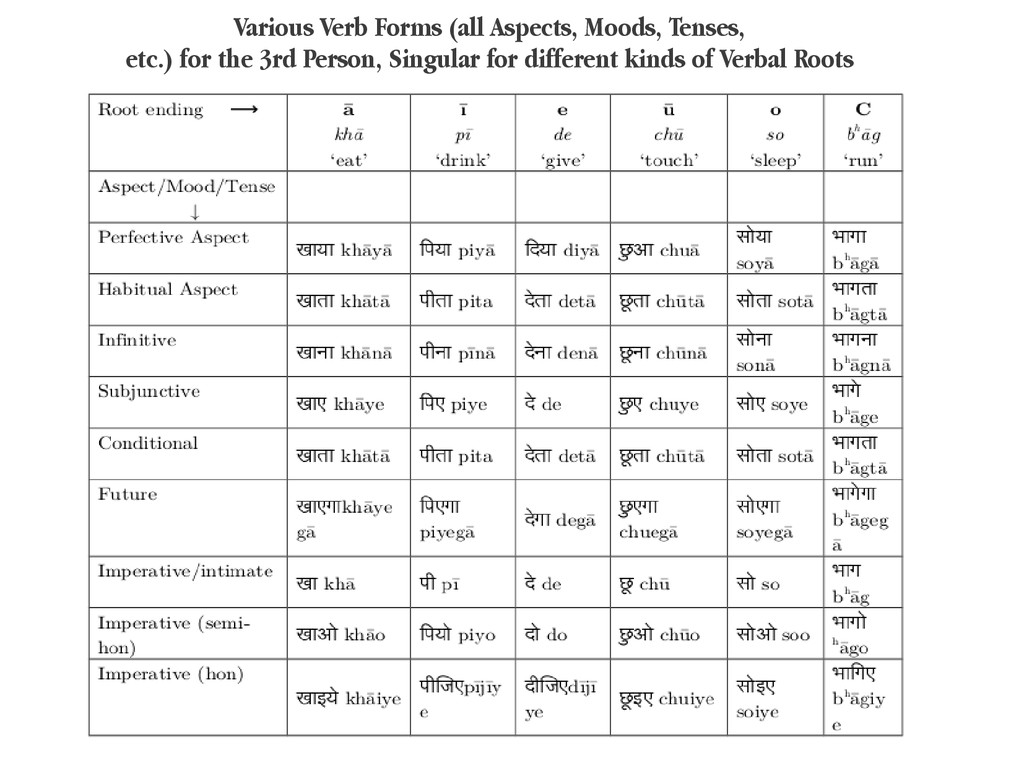{kind=link}
{kind=link}
{kind=link}
{kind=link}
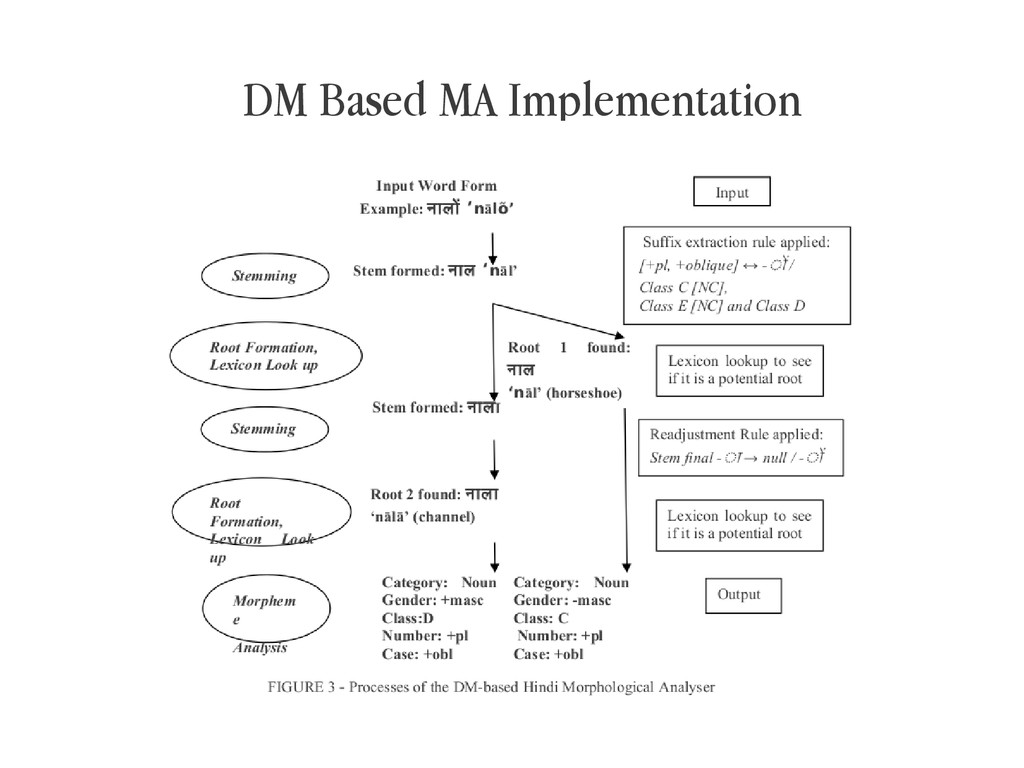{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}