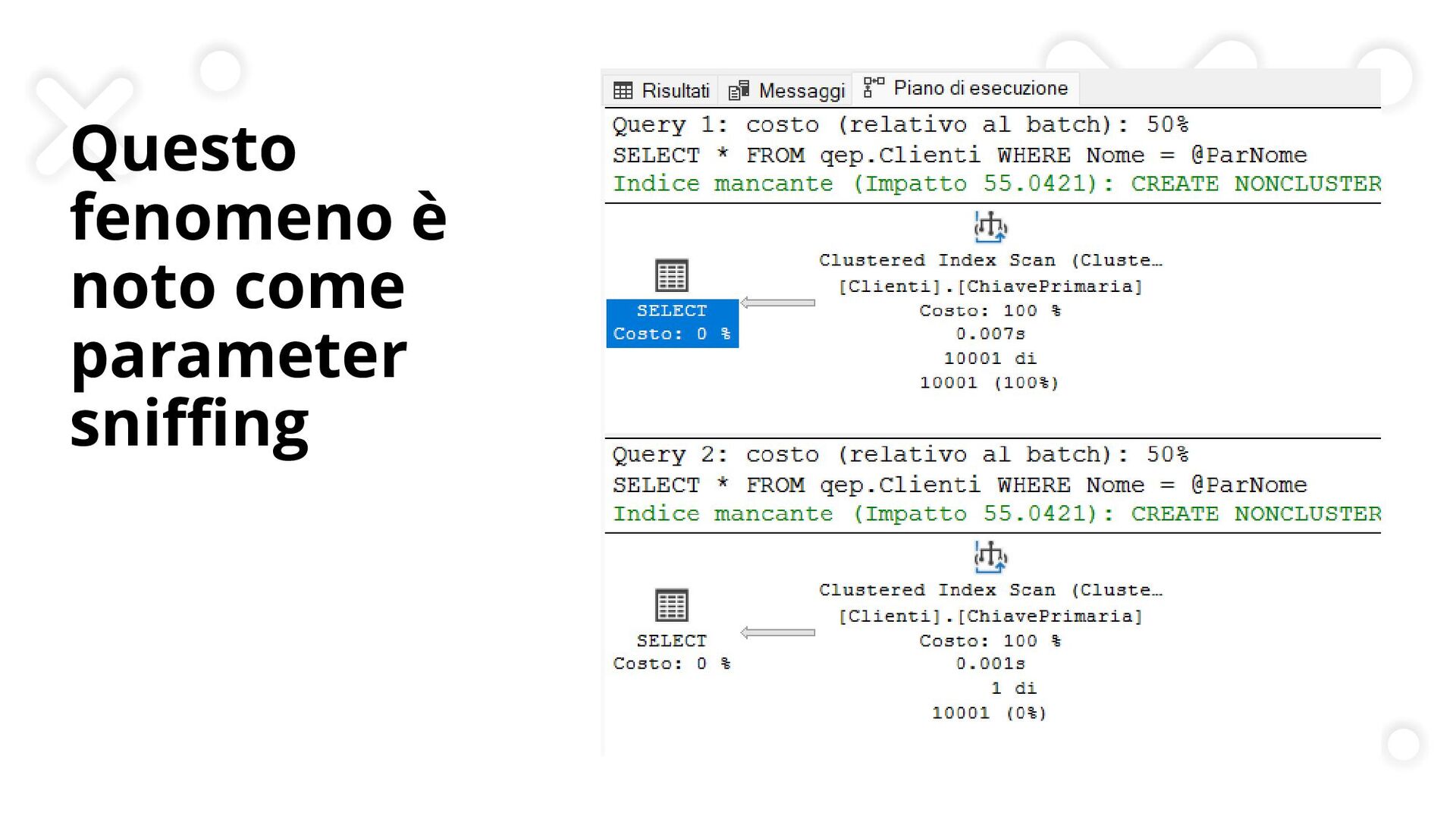
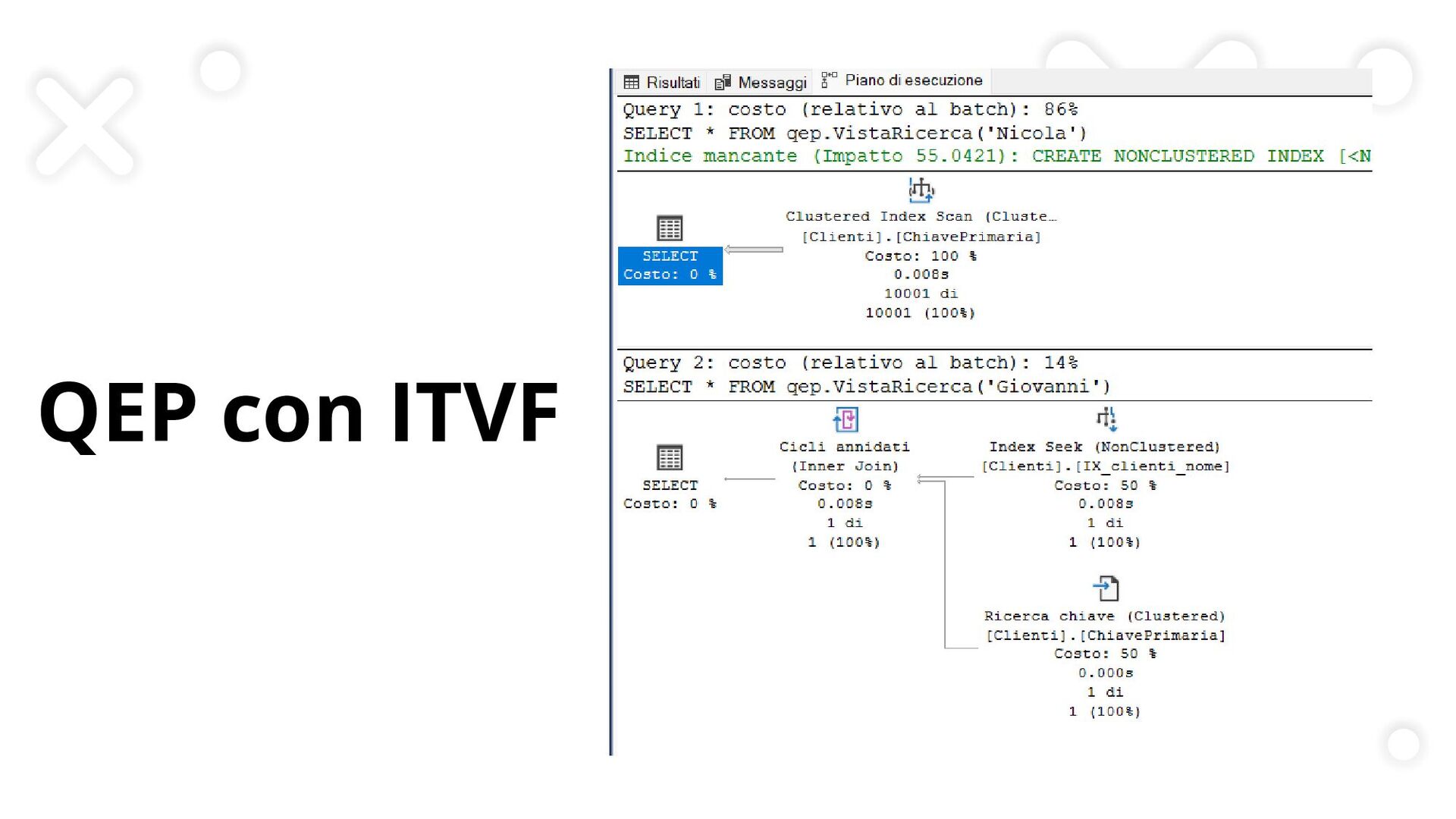
Tutorial tecnico che esplora le dinamiche dei piani di esecuzione in SQL Server, con focus sulle strategie di ottimizzazione delle query. Questa presentazione illustra l'impatto delle strutture dati (indici clustered e non-clustered) e dei diversi pattern di programmazione (stored procedure, ITVF, variabili) sulle performance del database.
Attraverso esempi pratici, vengono analizzati concetti avanzati come il parameter sniffing e l'utilizzo delle statistiche nella scelta dei piani di esecuzione. Un'analisi dettagliata delle best practice per sviluppatori SQL e database administrator che vogliono massimizzare l'efficienza delle loro query.
Per approfondimenti su tecniche di ottimizzazione SQL Server: www.nicolaiantomasi.com
#DatabasePerformance #SQLServer #QueryOptimization #DatabaseTuning
{kind=link}
{kind=link}
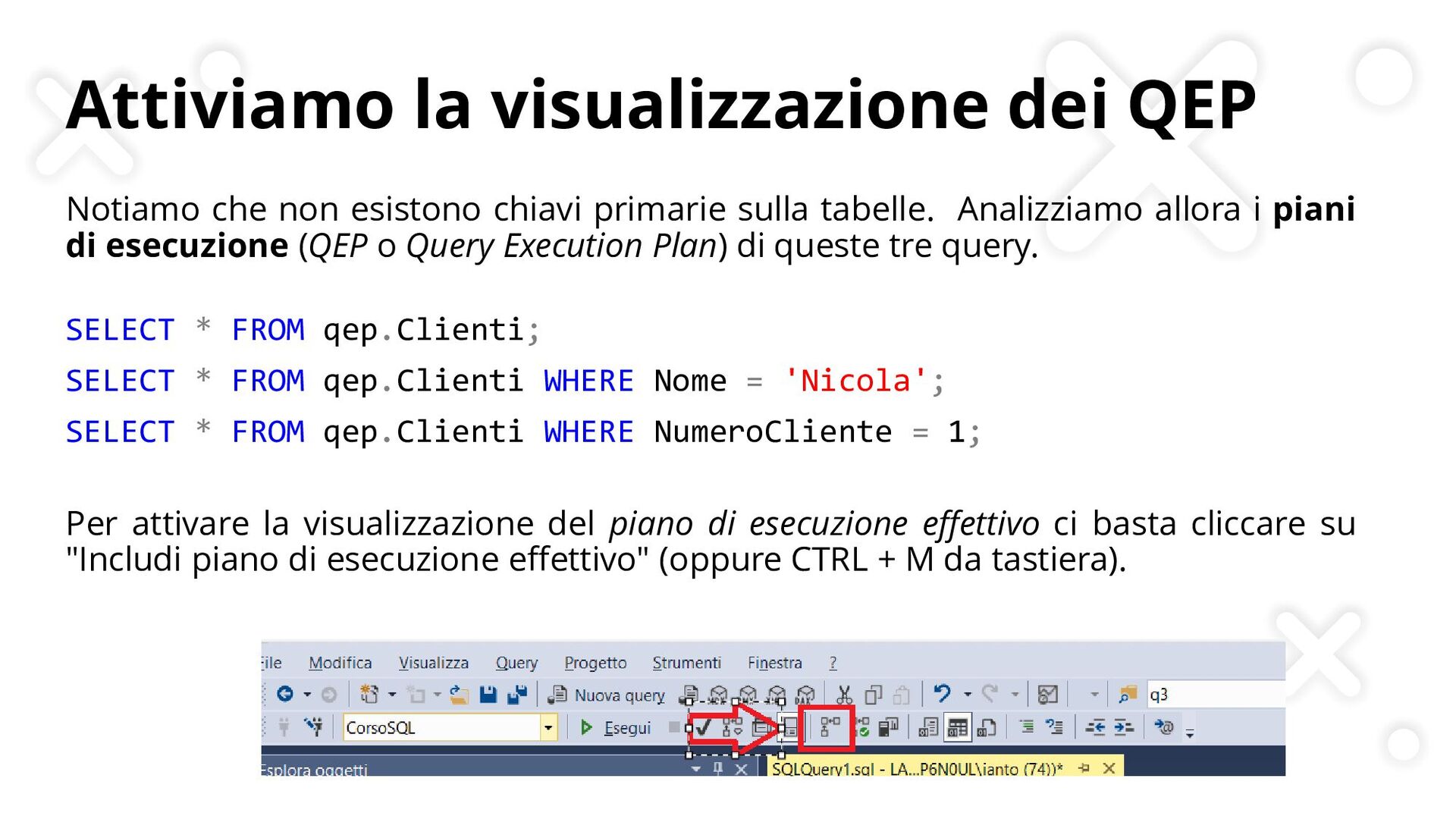{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
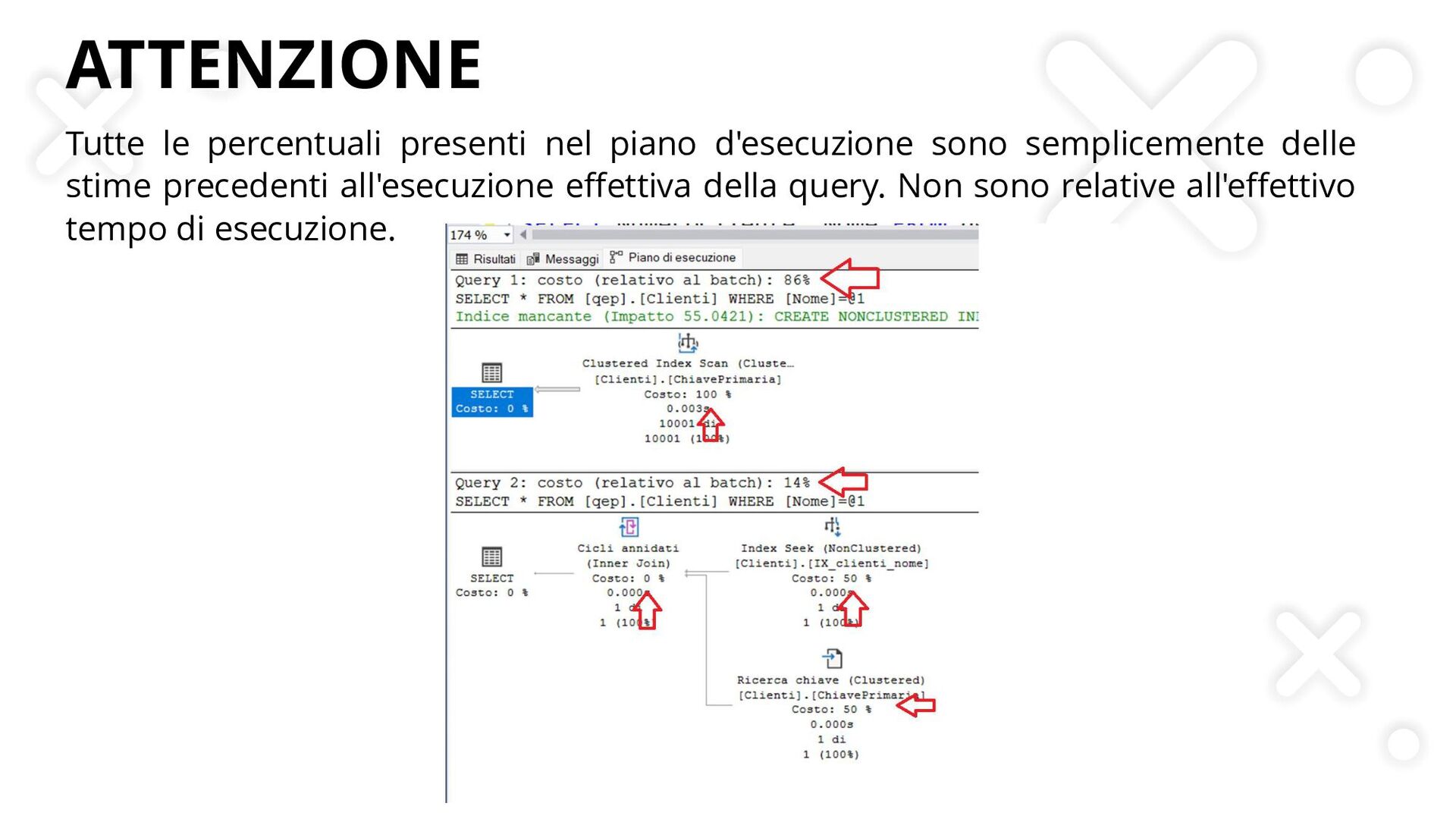{kind=link}
{kind=link}
{kind=link}
{kind=link}
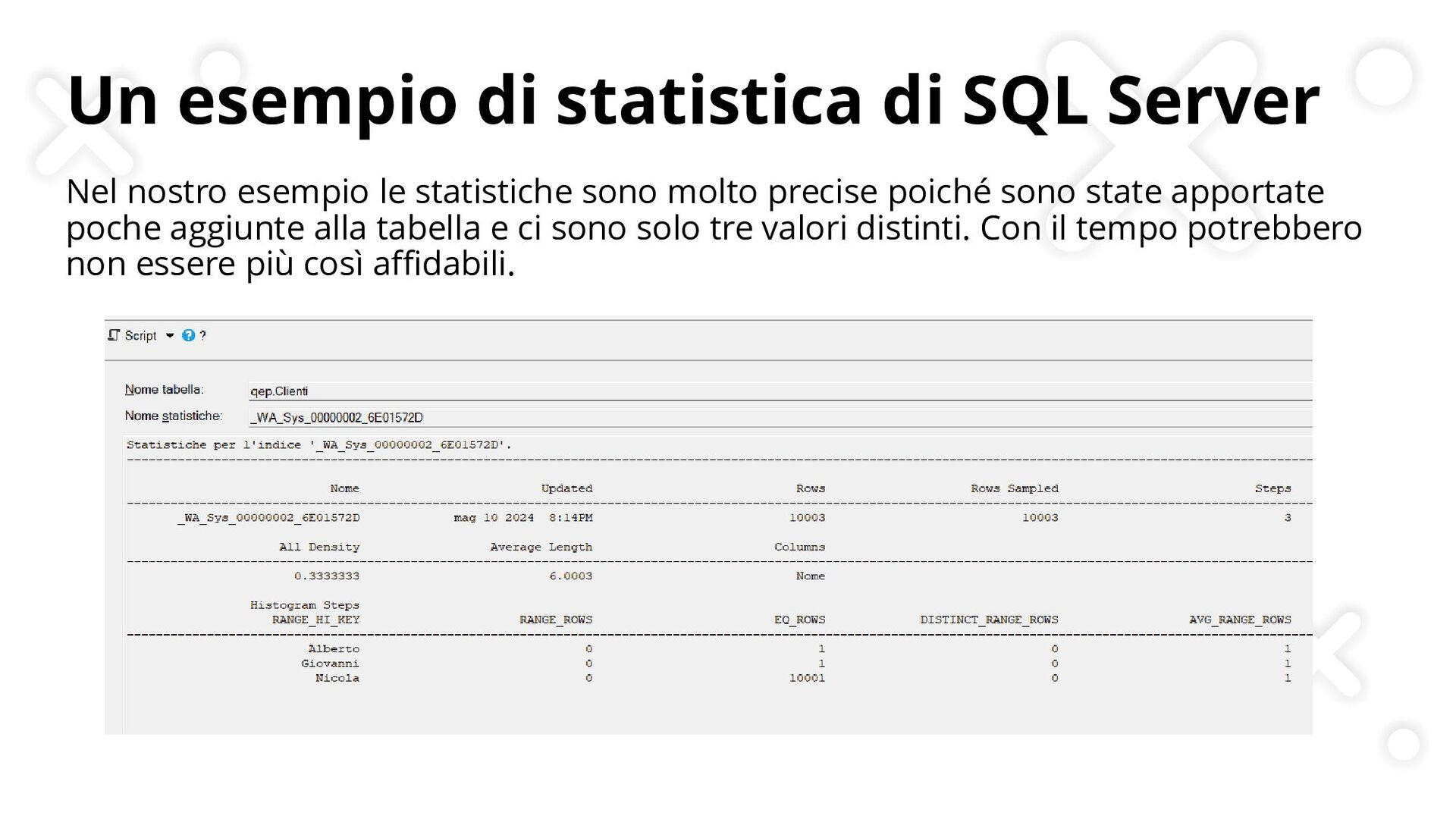{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}