Scala Swarm 22.06.2017 in Porto
Akka is a toolkit that brings the actor model to the JVM and helps developers to build scalable, resilient and responsive applications. With location transparency and asynchronous message passing it is designed to work distributed from the ground up.
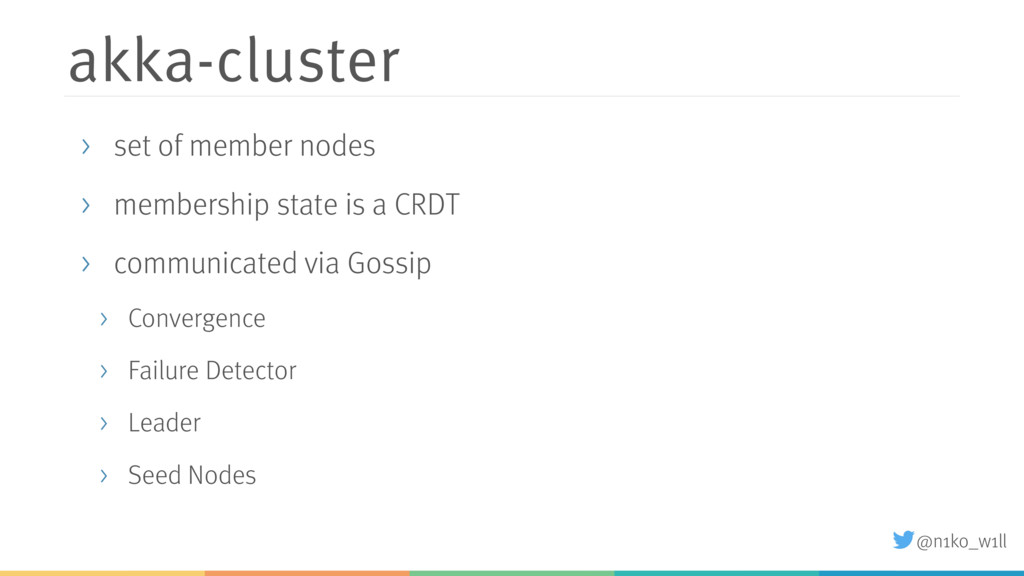
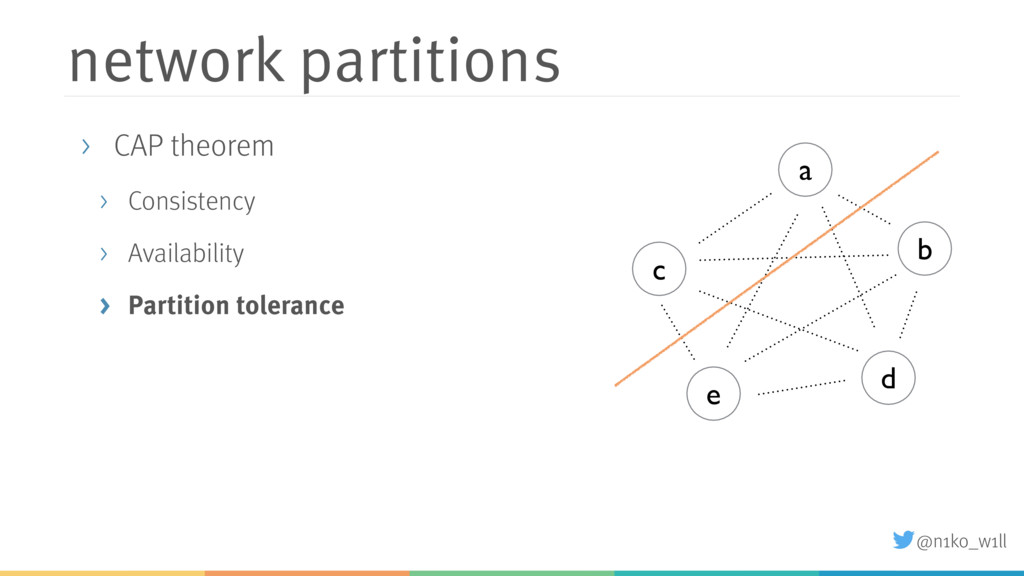
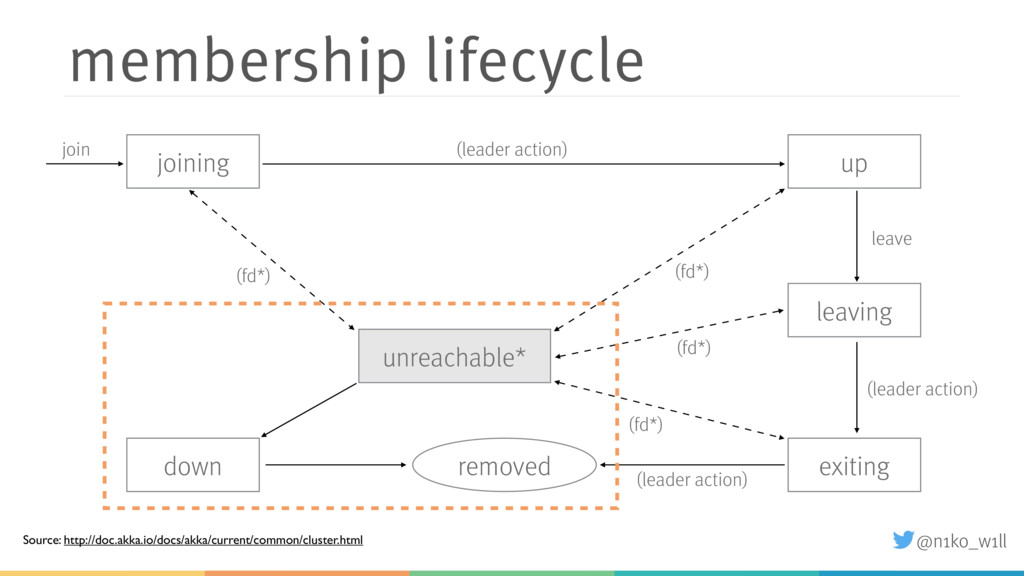
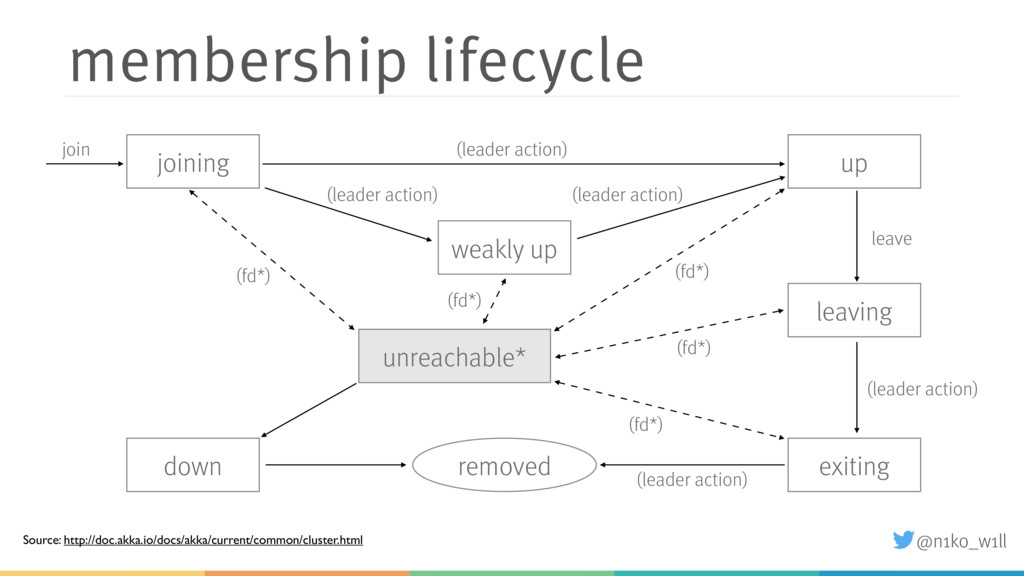
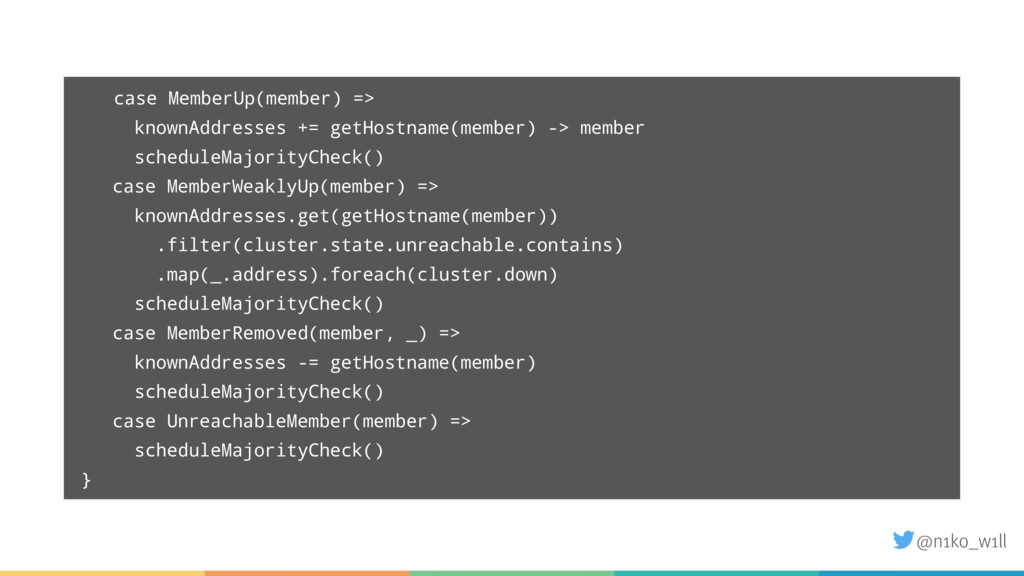
While distributed systems help to solve some problems like availability, a new set of problems arise. For example how do we scale the cluster up or down? What happens if the network is at least partially not available? Akka provides a comprehensive set of cluster features that enable developers to monitor and manage the cluster manually or in most cases even automatically.
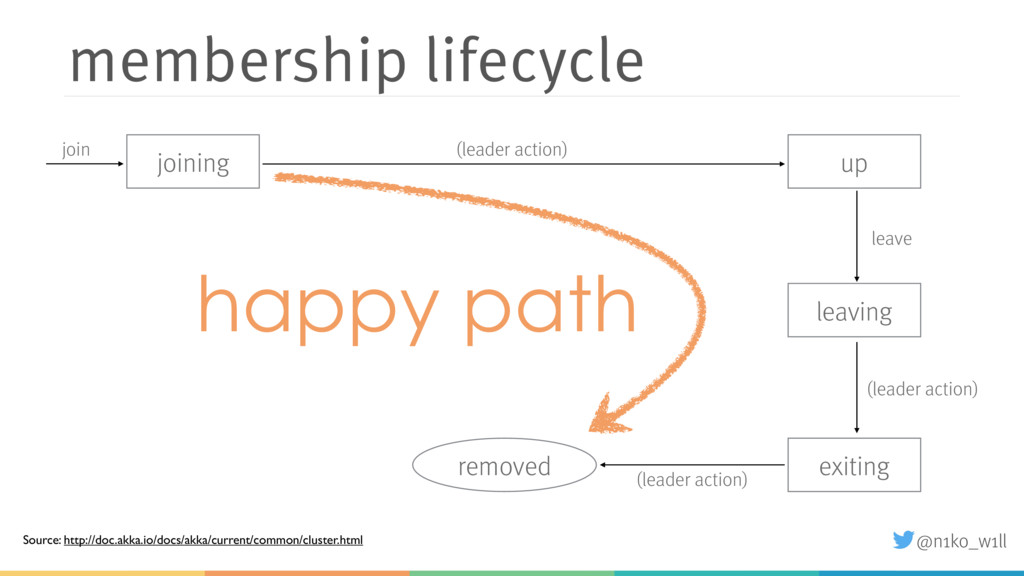
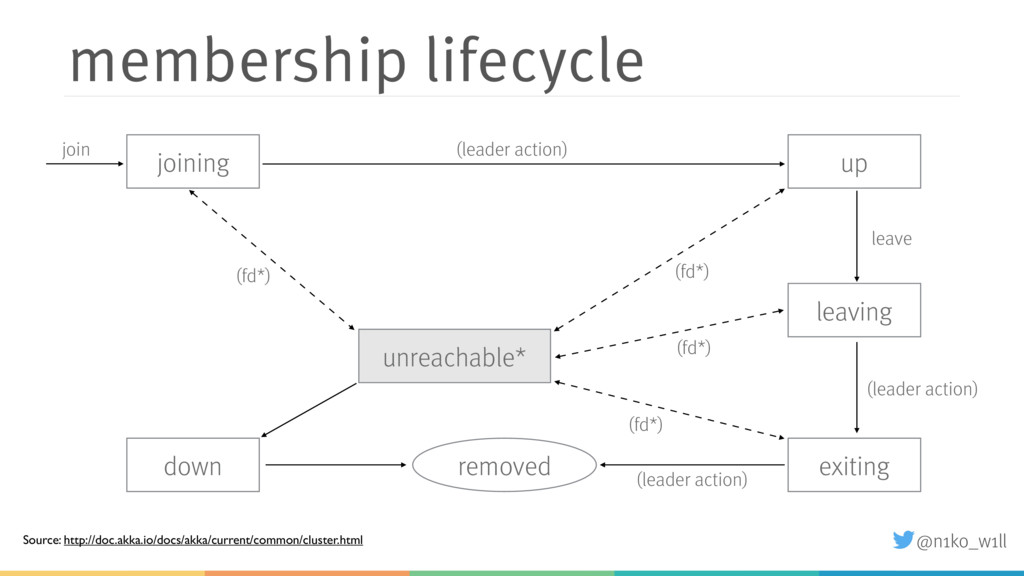
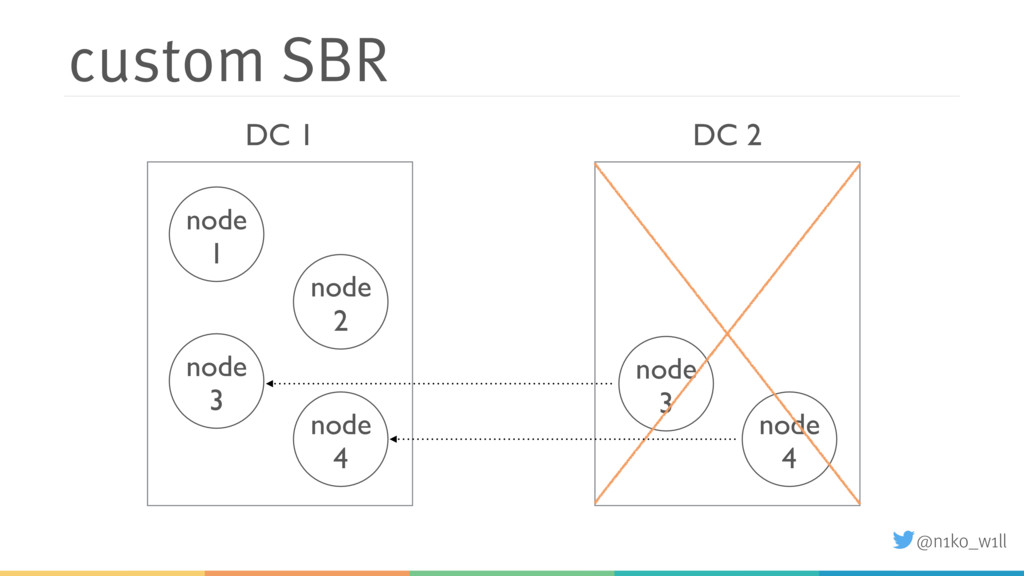
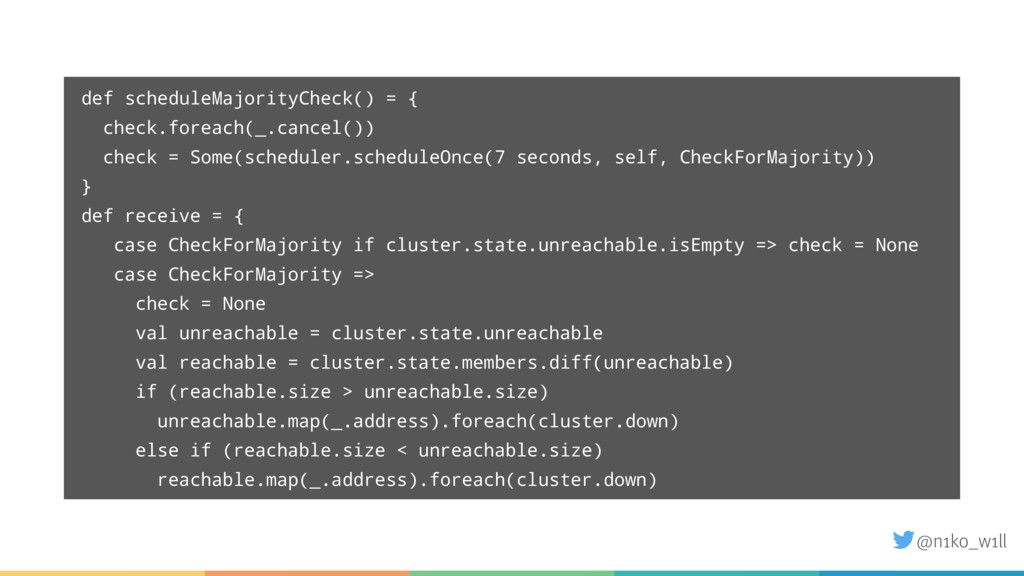
In this talk I will introduce some of these features and explain what you need to be aware of. You will learn how to start a cluster correctly and add / (gracefully) remove nodes to / from a running cluster. Additionally I will show how to handle failure scenarios like network partitions by using an existing or implementing a custom split brain resolver.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@n1ko_w1ll …and then things go south [info] [INFO] [04/05/2017 10:42:22.753]](https://files.speakerdeck.com/presentations/4db71e2946bb45ba913bd0f2a97320dd/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@n1ko_w1ll Thank you. Questions? Comments @n1ko_w1ll Niko Will [email protected] innoQ](https://files.speakerdeck.com/presentations/4db71e2946bb45ba913bd0f2a97320dd/slide_37.jpg){kind=link}