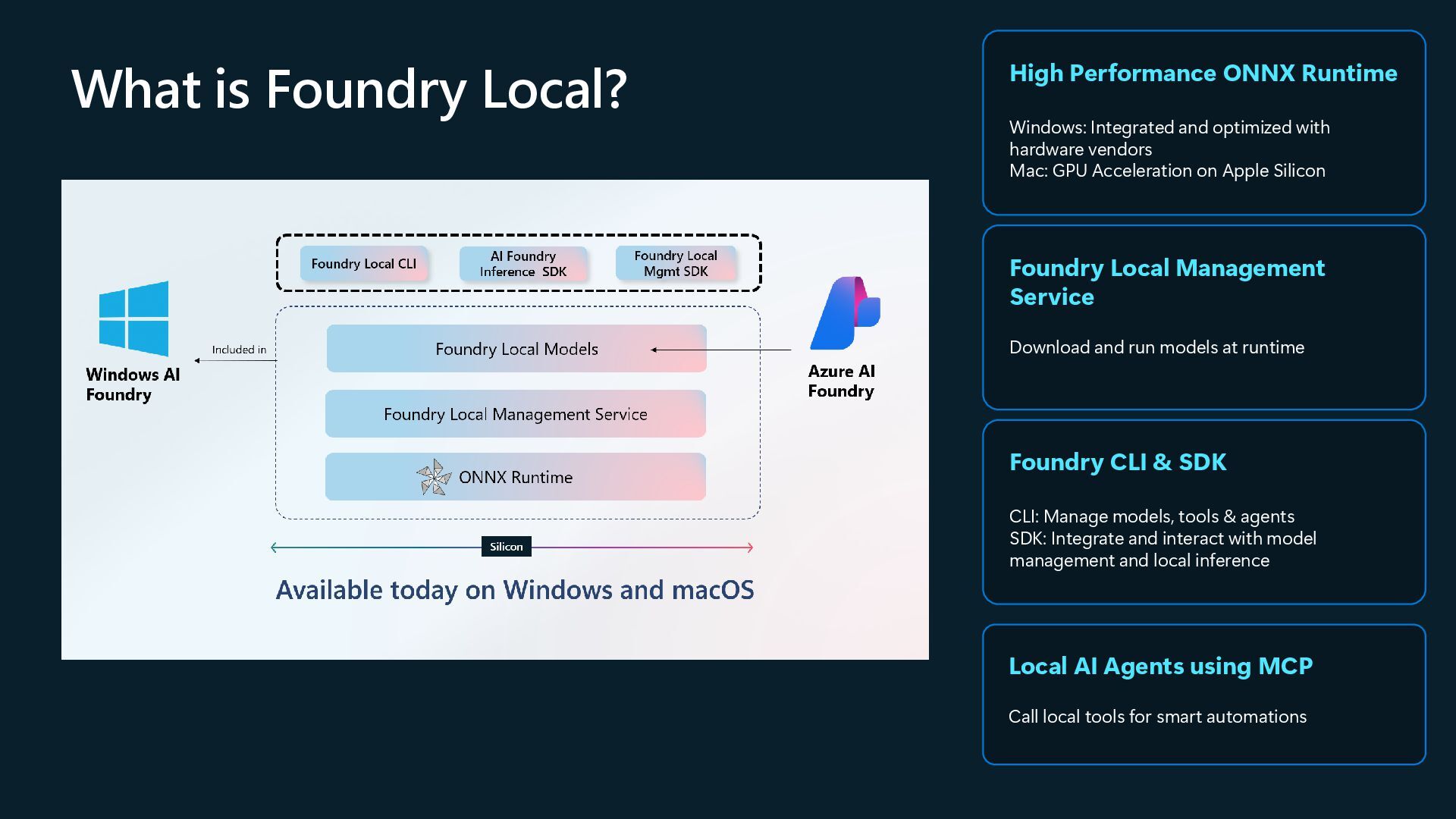
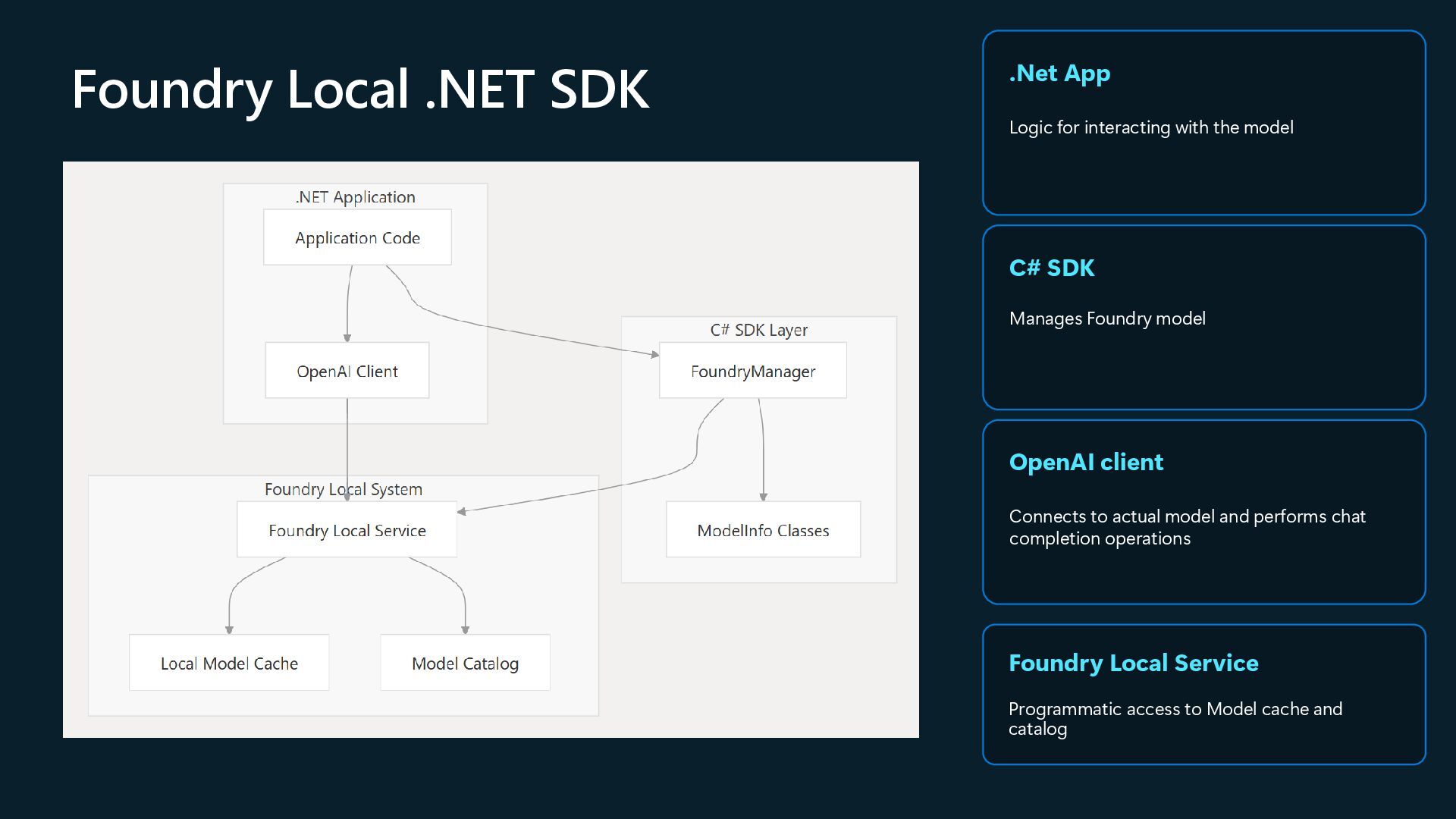
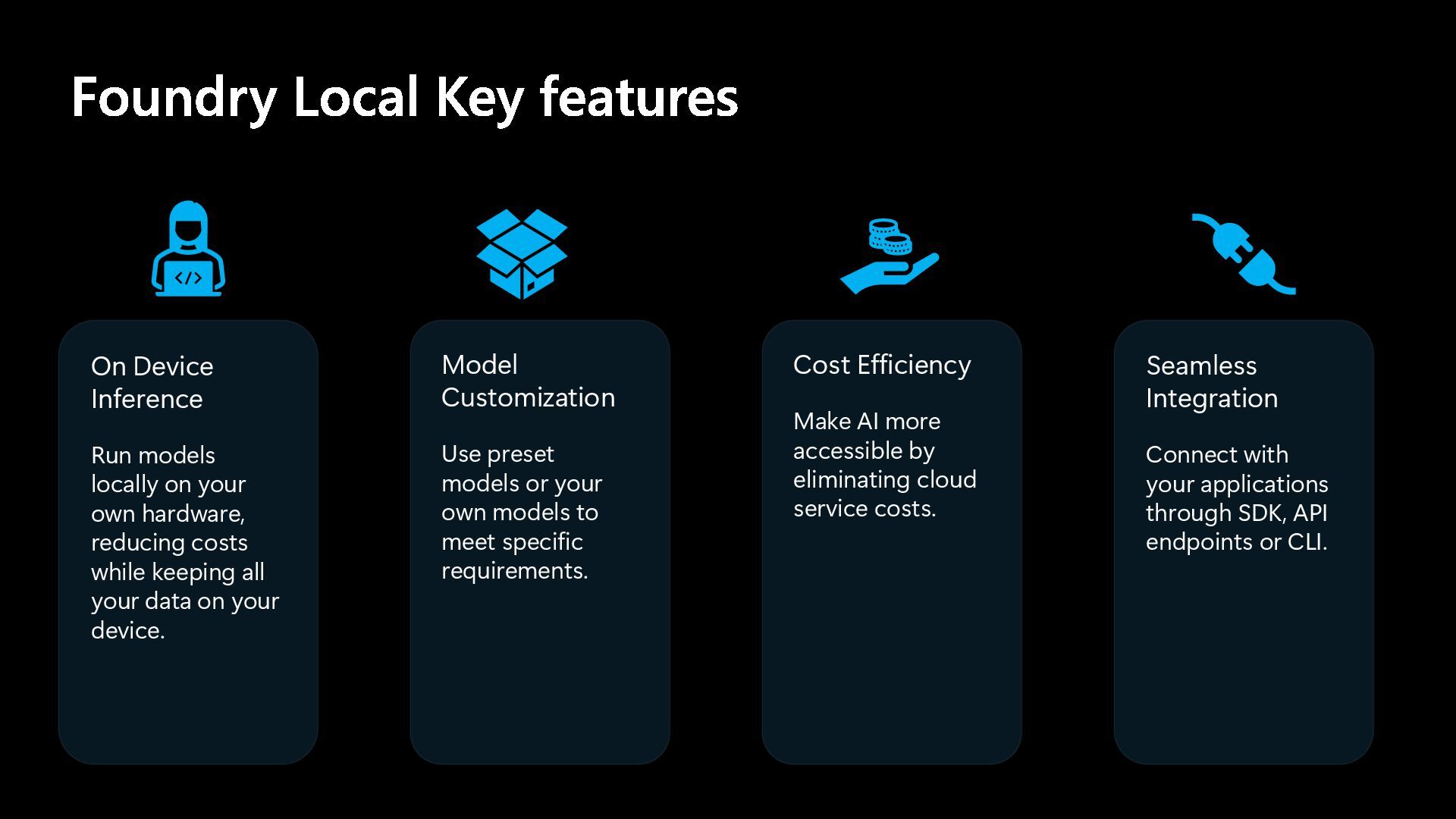
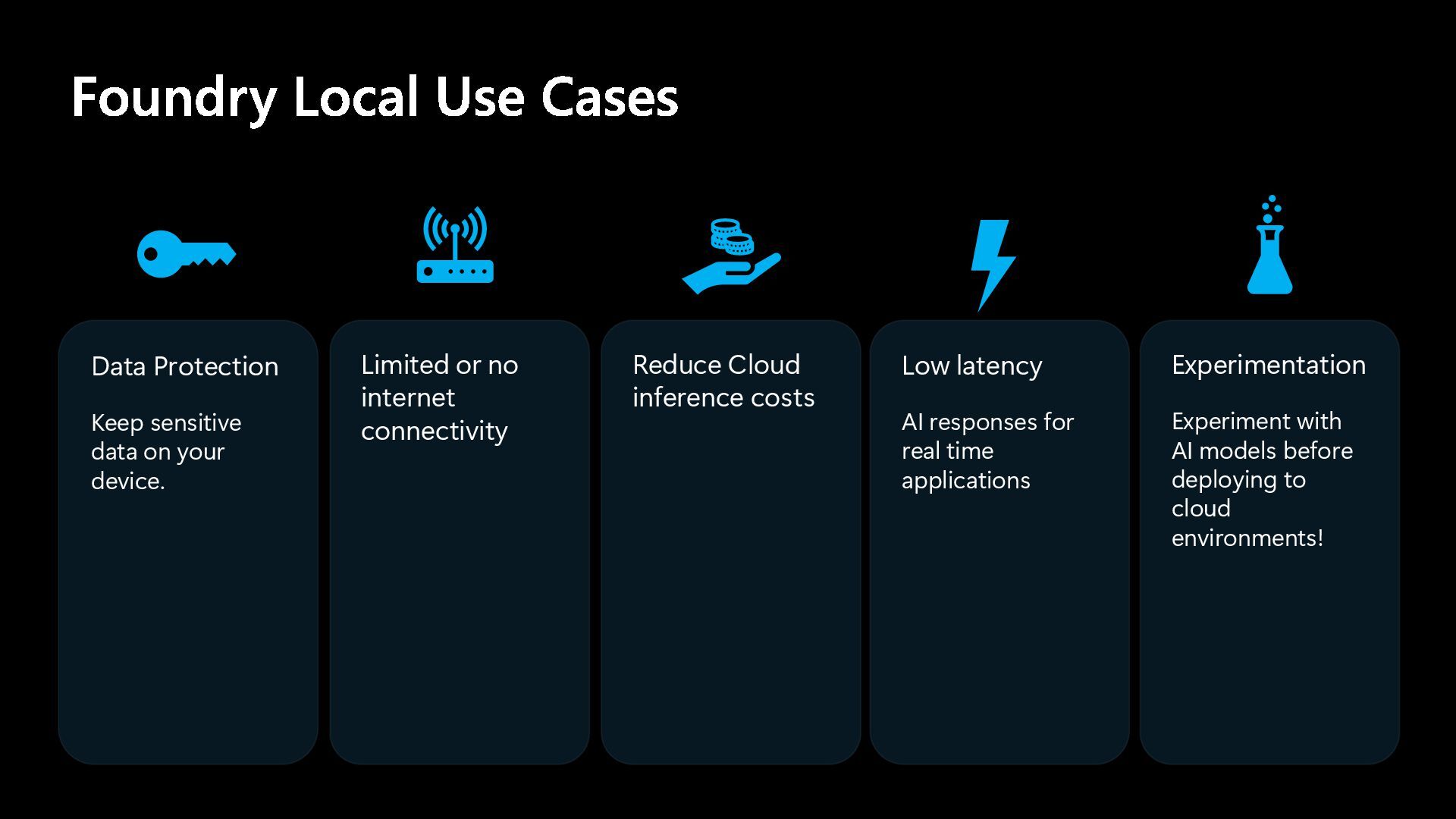
The deck is part of the presentation and live demo conducted at the Melb.Net July meetup in Melbourne on 1 July 2025. It covers the capabilities of Foundry Local using a fun app which impersonates celebrities
https://www.meetup.com/melb-net-meetup/events/308591853/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}