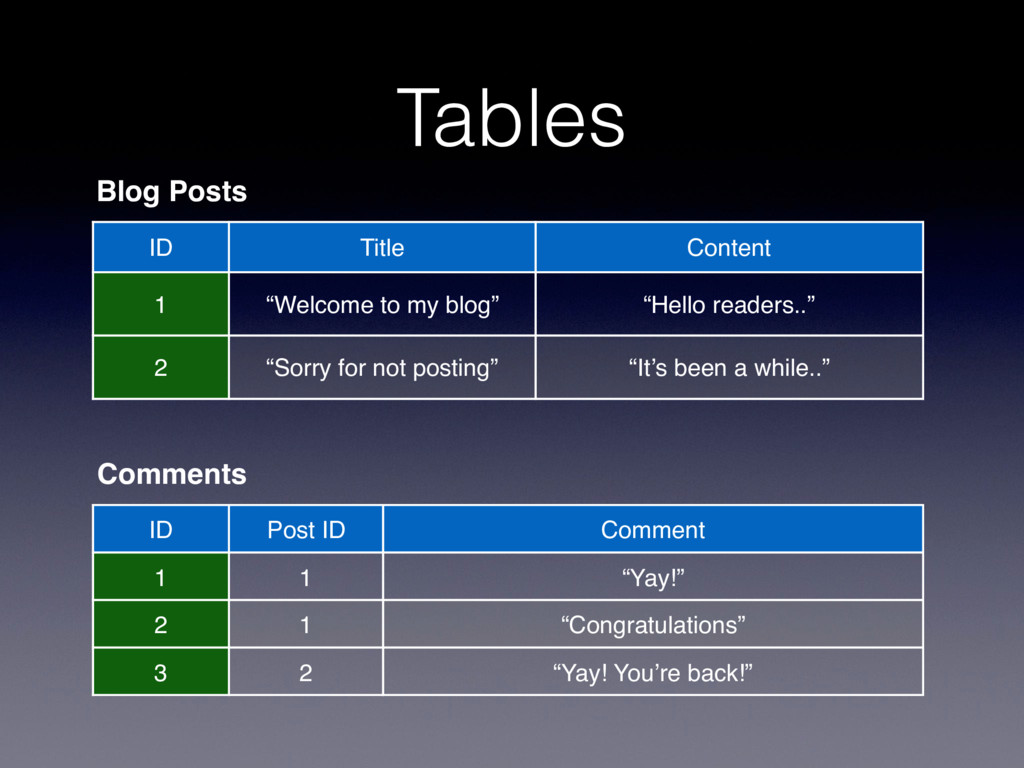
readers..” 2 “Sorry for not posting” “It’s been a while..” ID Post ID Comment 1 1 “Yay!” 2 1 “Congratulations” 3 2 “Yay! You’re back!” Blog Posts Comments
for relational databases • Allows database to be exposed through commonly available mechanisms, such as REST • Leads to a proliferation in clients, tools and add-ons
up to 512MB • Lists: Strings sorted by insertion order, up to 4 billion per list • Sets: Unordered collection of unique strings • Hashes: Mapping between string fields and string values • Sorted Sets: Ordered by a ‘score’
site • Tracks catalogue views for individual domain and month, and all domains for month • Same for searches, product views, referers, sale value • For tracking, uses just ZINCRBY on Sorted Sets
track:referers:domain_id:period • Each contains Sorted Set of Key-Value pairs • Key is something like a product_id, or a name • Value is number of events • product:views:mysite.com:2013-01 => { “teddy bear” => 4, “book” => 3, “poster” => 1 } • product:views:mysite.com:2013-02 => { “book” => 7, “poster” => 1, “cutlery set” => 4 }
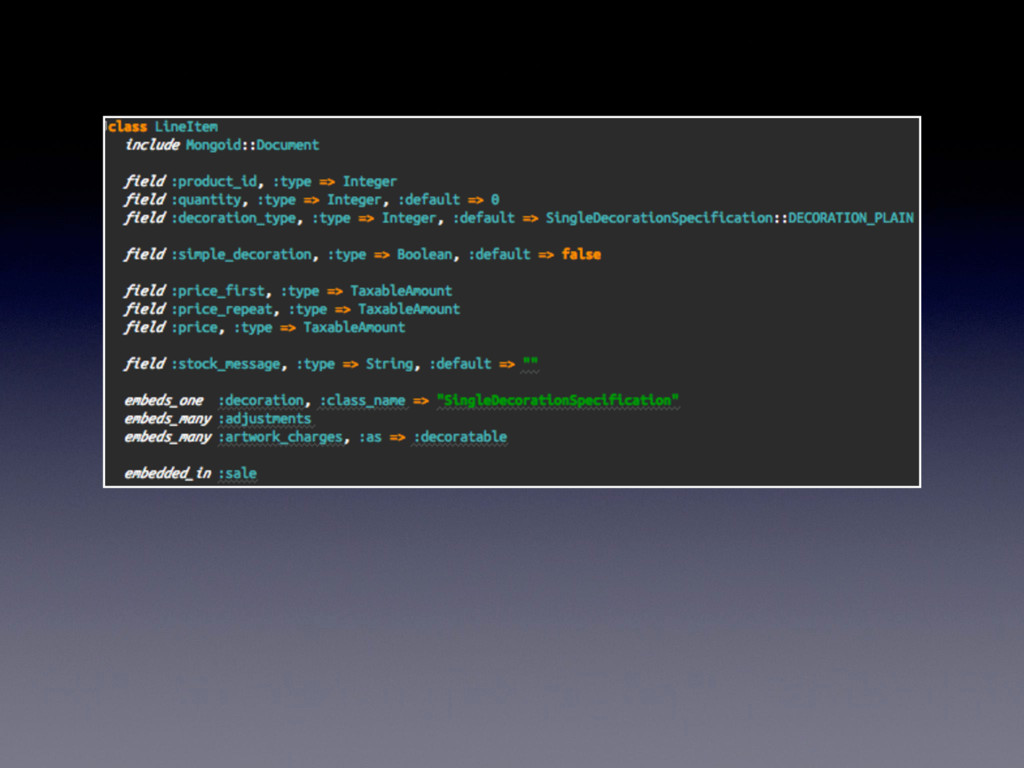
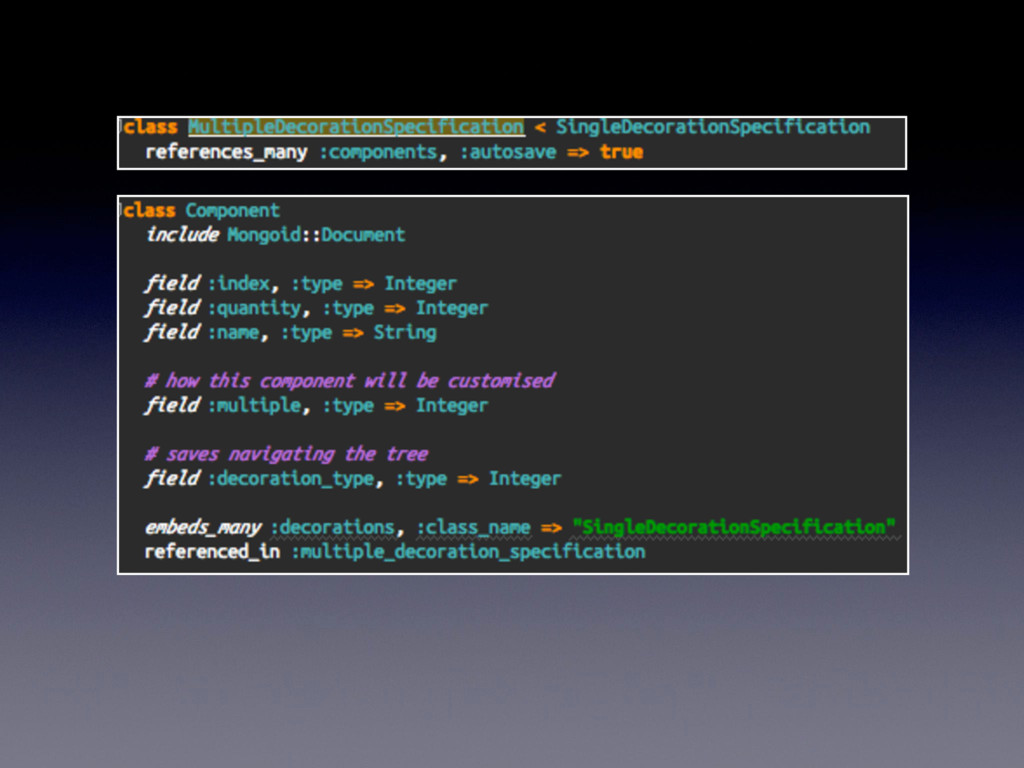
customisable product • A product may have more than one customisable component • Customisable components can be of same customisation as other components in Line Item • Customisation varies according to the type of component
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}