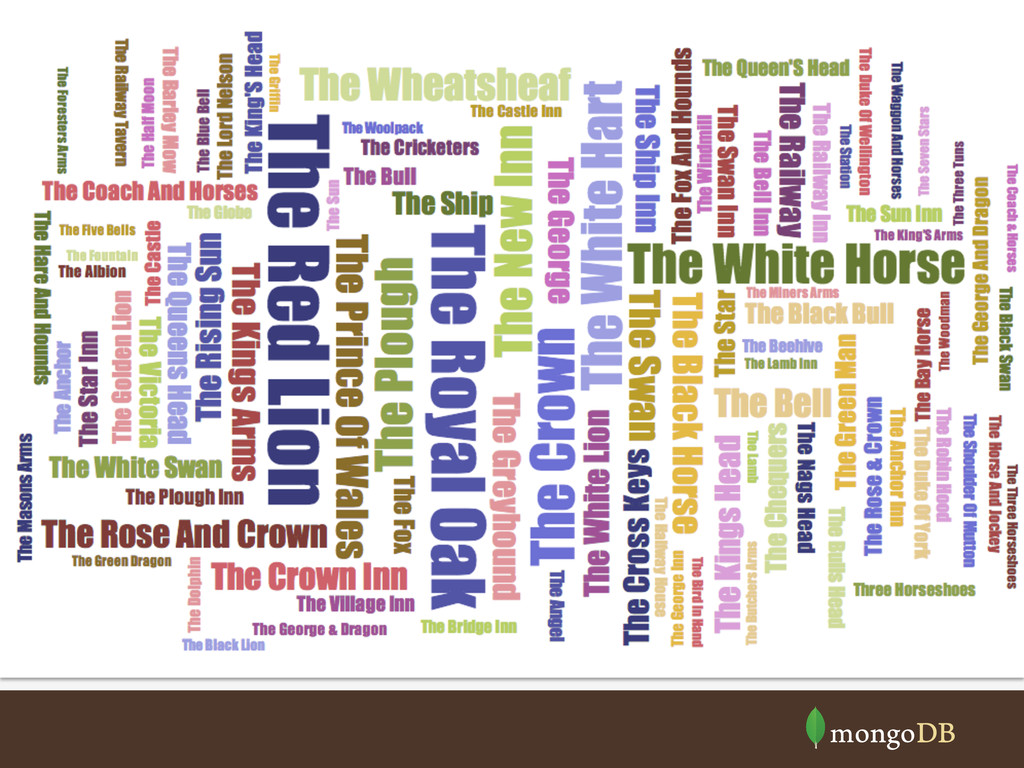
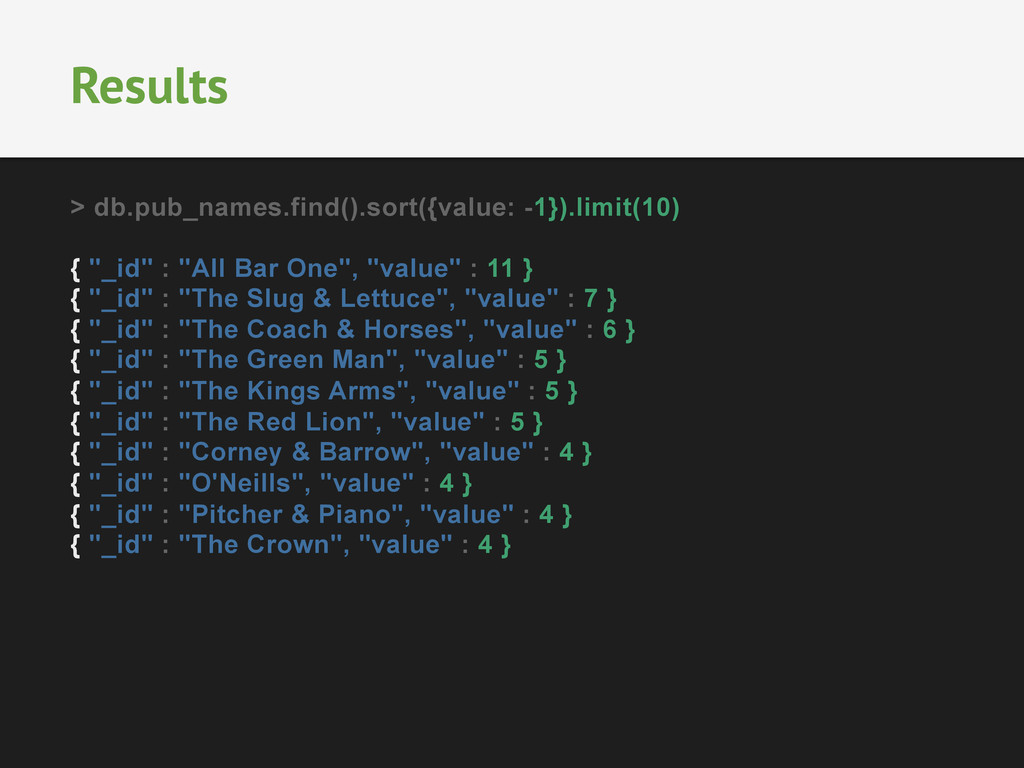
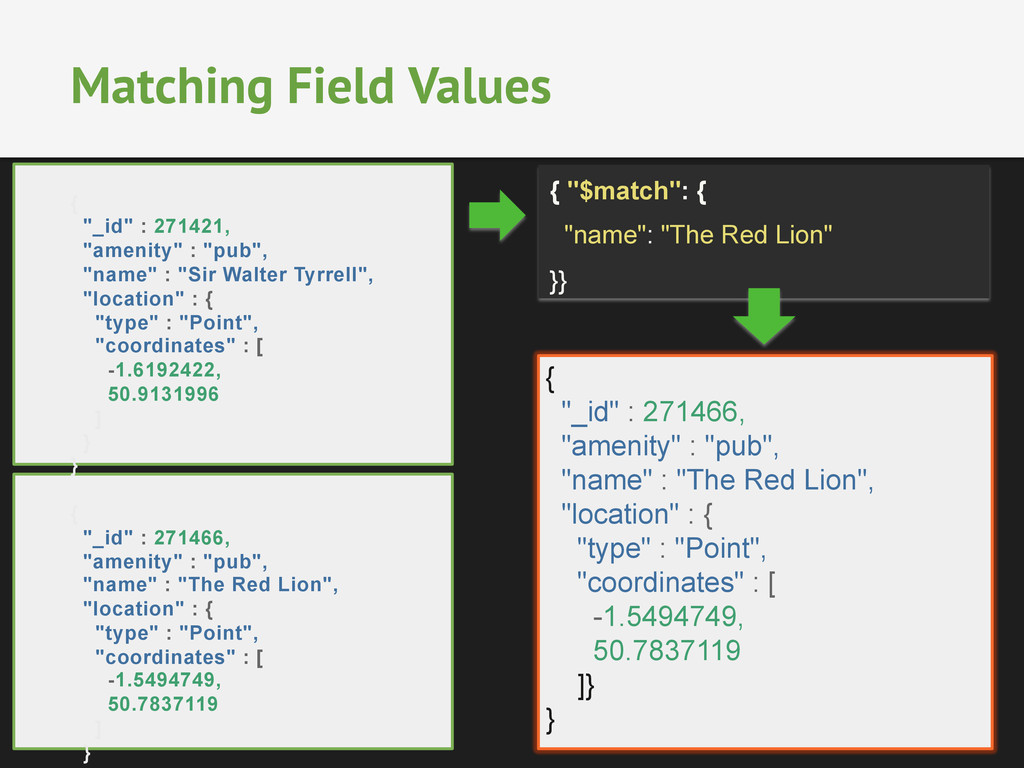
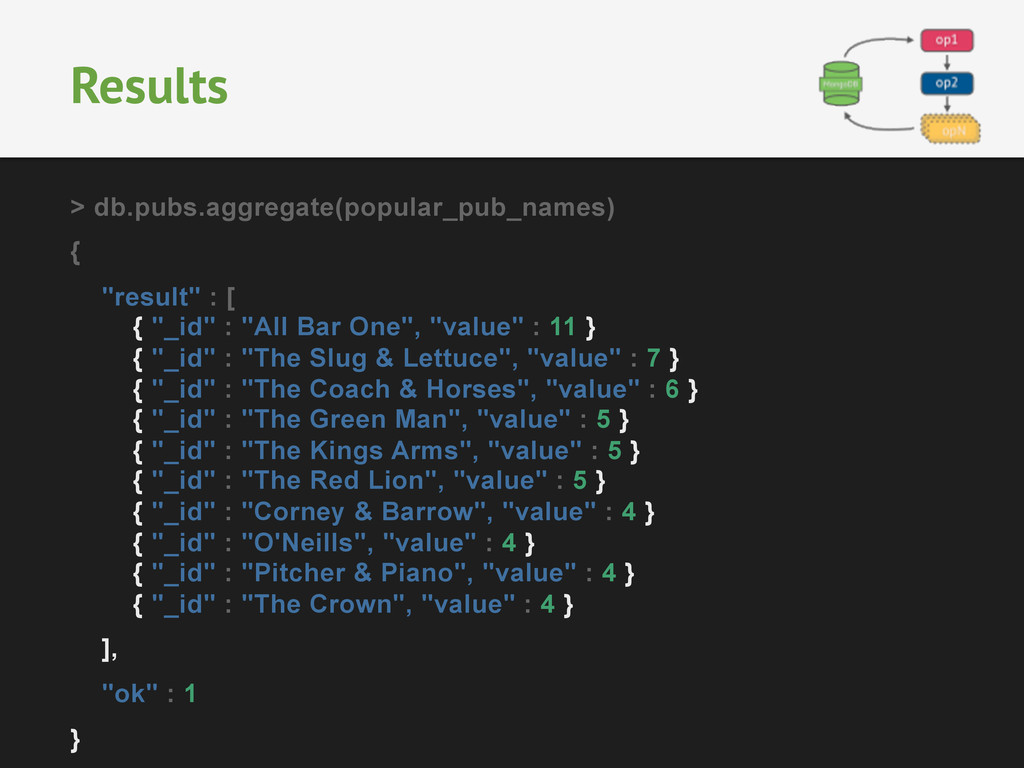
Walter Tyrrell", "location" : { "type" : "Point", "coordinates" : [ -1.6192422, 50.9131996 ] } } { "_id" : 271466, "amenity" : "pub", "name" : "The Red Lion", "location" : { "type" : "Point", "coordinates" : [ -1.5494749, 50.7837119 ] } Matching Field Values { "$match": { "name": "The Red Lion" }} { "_id" : 271466, "amenity" : "pub", "name" : "The Red Lion", "location" : { "type" : "Point", "coordinates" : [ -1.5494749, 50.7837119 ]} }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#!/usr/bin/env python # Data Source # http://www.overpass-api.de/api/xapi?*[amenity=pub][bbox=-10.5,49.78,1.78,59] import re import](https://files.speakerdeck.com/presentations/19d15ab012360131e24e4a1c325d810d/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Senior Solutions Architect, MongoDB Norberto Leite #mongodb_joburg [email protected]](https://files.speakerdeck.com/presentations/19d15ab012360131e24e4a1c325d810d/slide_52.jpg){kind=link}