Sparse data • Semi-structured data • Agile development High Data Throughput • Reads • Writes Big Data • Aggregate Data Size • Number of Objects Low Latency • For reads and writes • Millisecond Latency Cloud Computing • Runs everywhere • No special hardware Commodity Hardware • Ethernet • Local data storage • JSON Based • Dynamic Schemas • Replica Sets to scale reads • Sharding to scale writes • 1000s of shards in a single DB • Data partitioning • Designed for “typical” OS and local file system • Scale-out to overcome hardware limitations • In-memory cache • Scale-out working set
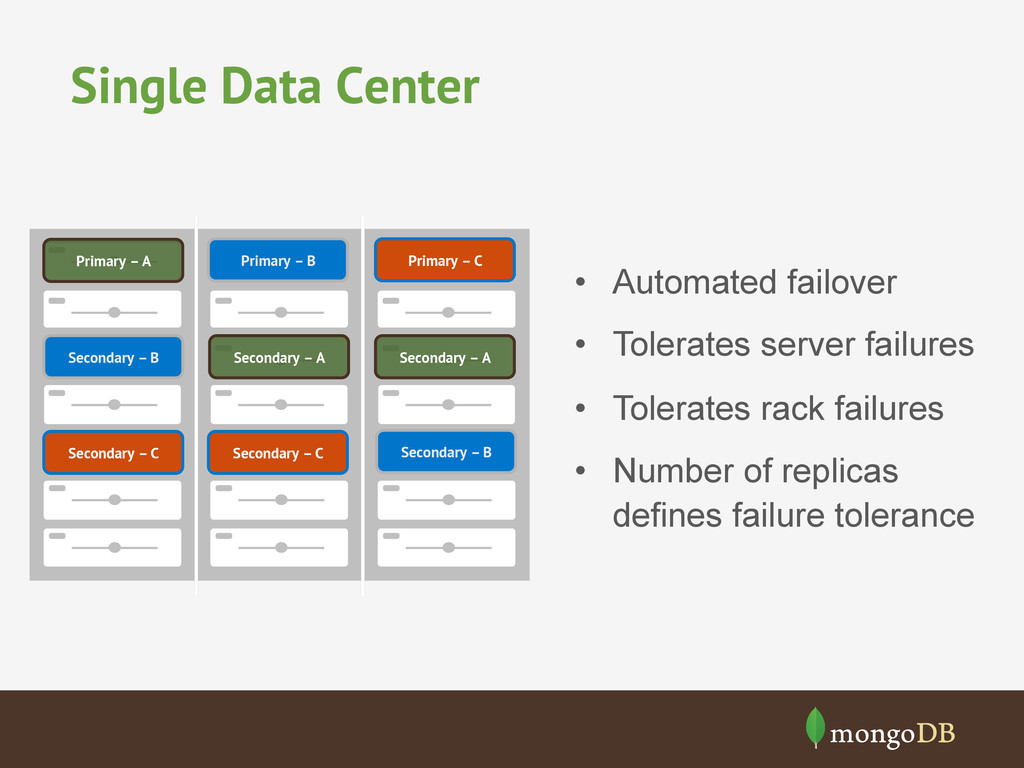
• Tolerates rack failures • Number of replicas defines failure tolerance Primary – A Primary – B Primary – C Secondary – A Secondary – A Secondary – B Secondary – B Secondary – C Secondary – C
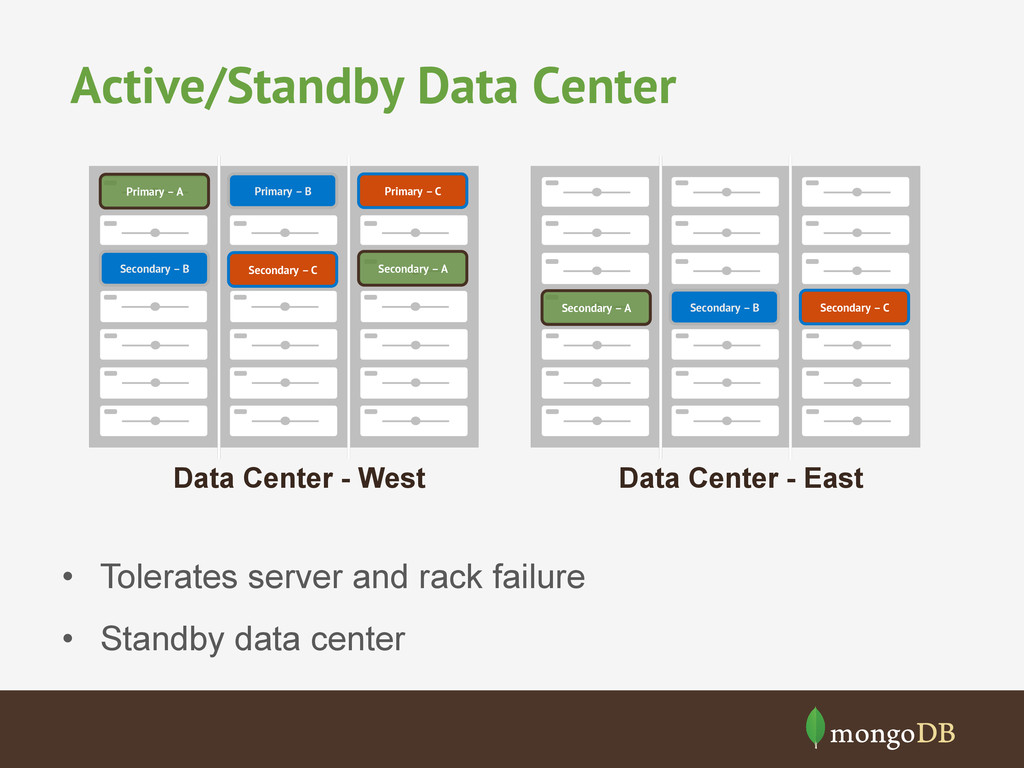
Standby data center Data Center - West Primary – A Primary – B Primary – C Secondary – A Secondary – B Secondary – C Data Center - East Secondary – A Secondary – B Secondary – C
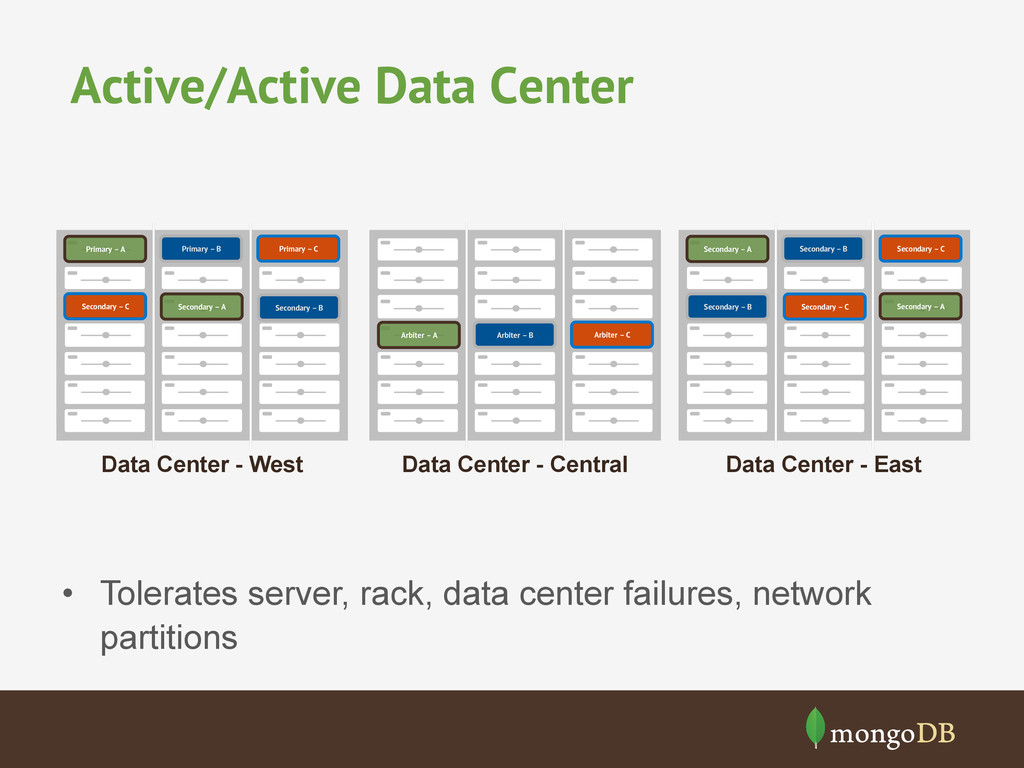
network partitions Data Center - West Primary – A Primary – B Primary – C Secondary – A Secondary – B Secondary – C Data Center - East Secondary – A Secondary – B Secondary – C Secondary – B Secondary – C Secondary – A Data Center - Central Arbiter – A Arbiter – B Arbiter – C
data • Variably structured Machine Generated Data • High frequency trading • Daily closing price Securities Data • Multiple data sources • Each changes their format consistently • Student Scores, Telecom logs Social Media / General Public
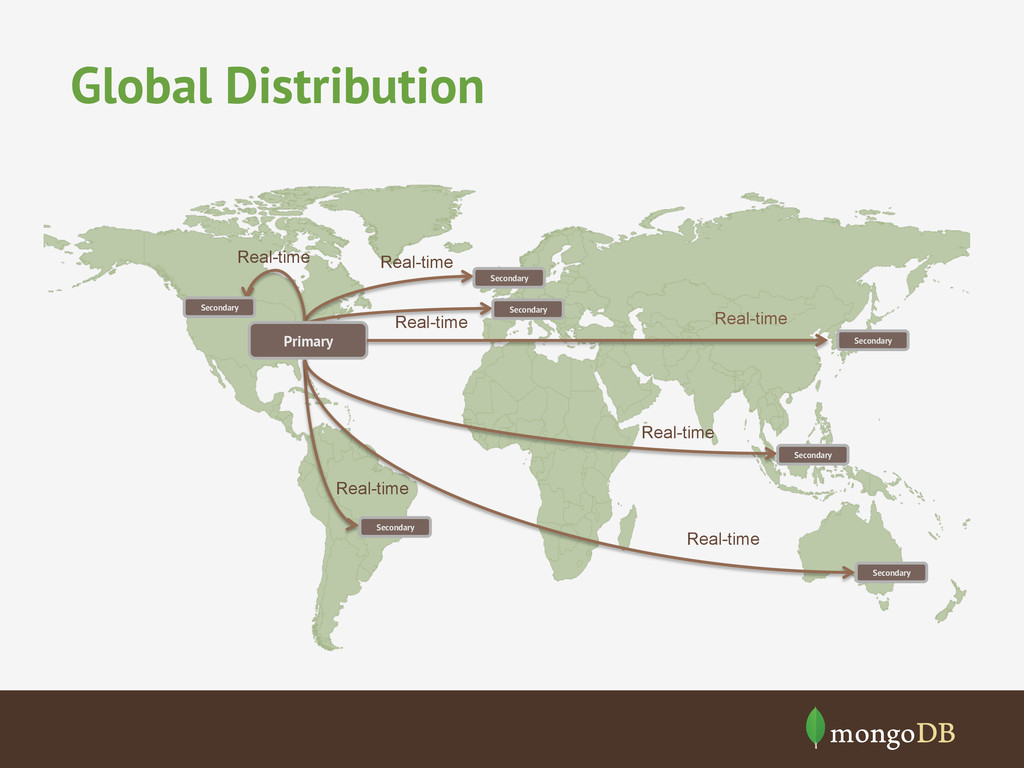
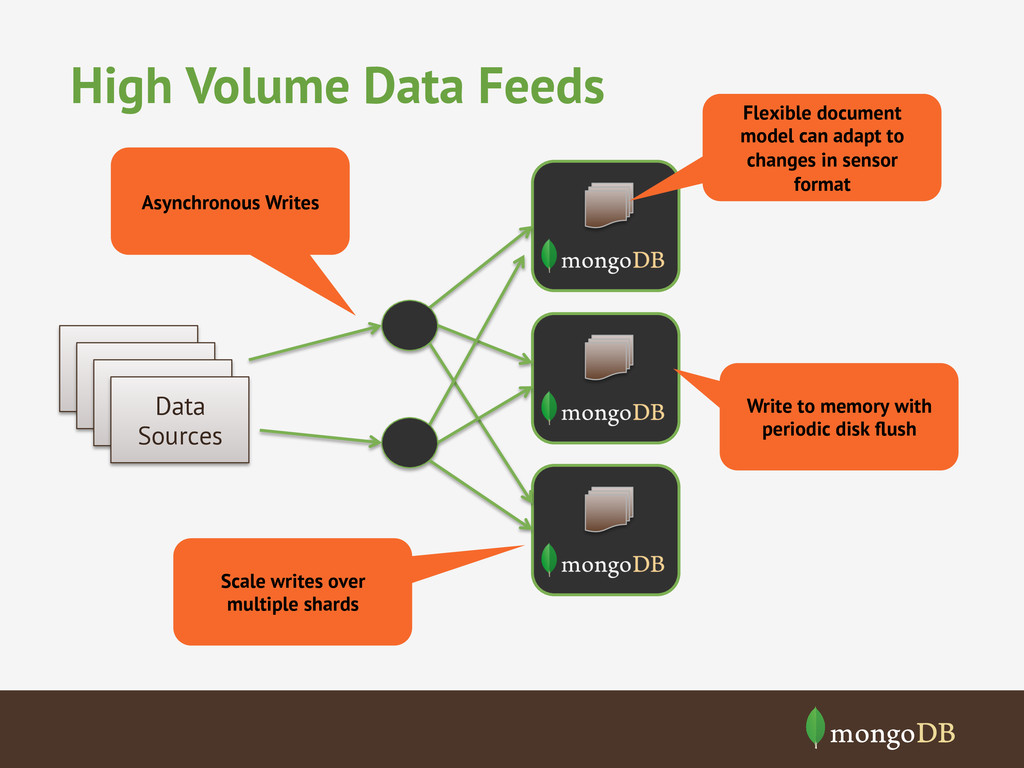
model can adapt to changes in sensor format Write to memory with periodic disk flush Data Sources Data Sources Data Sources Scale writes over multiple shards
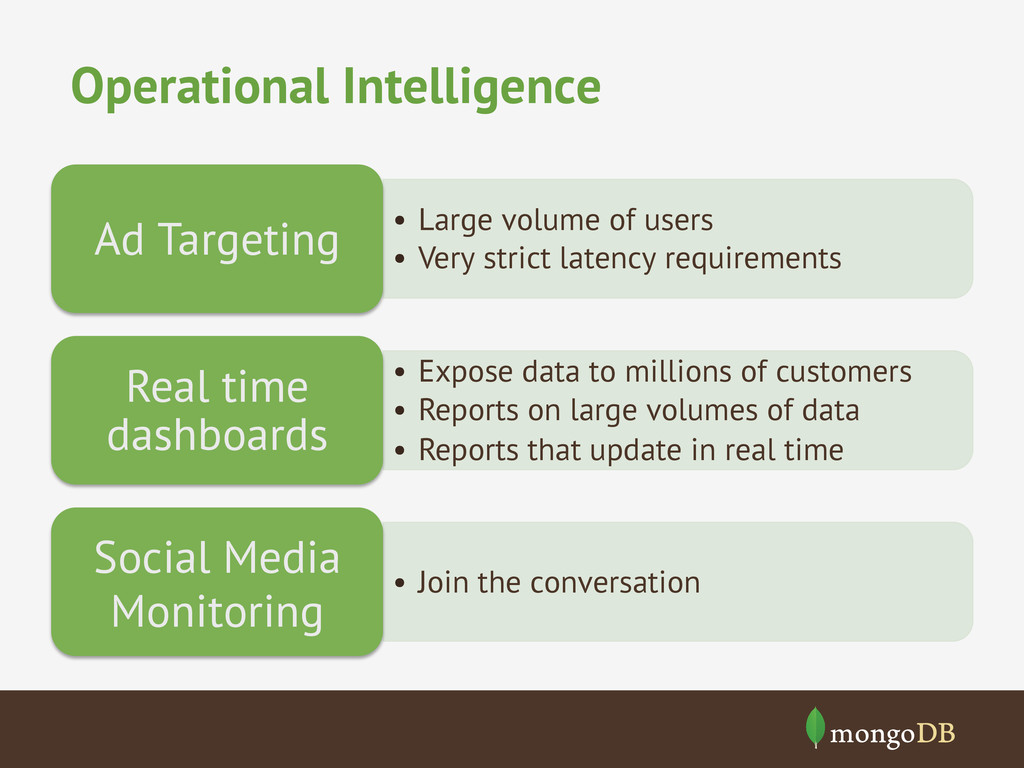
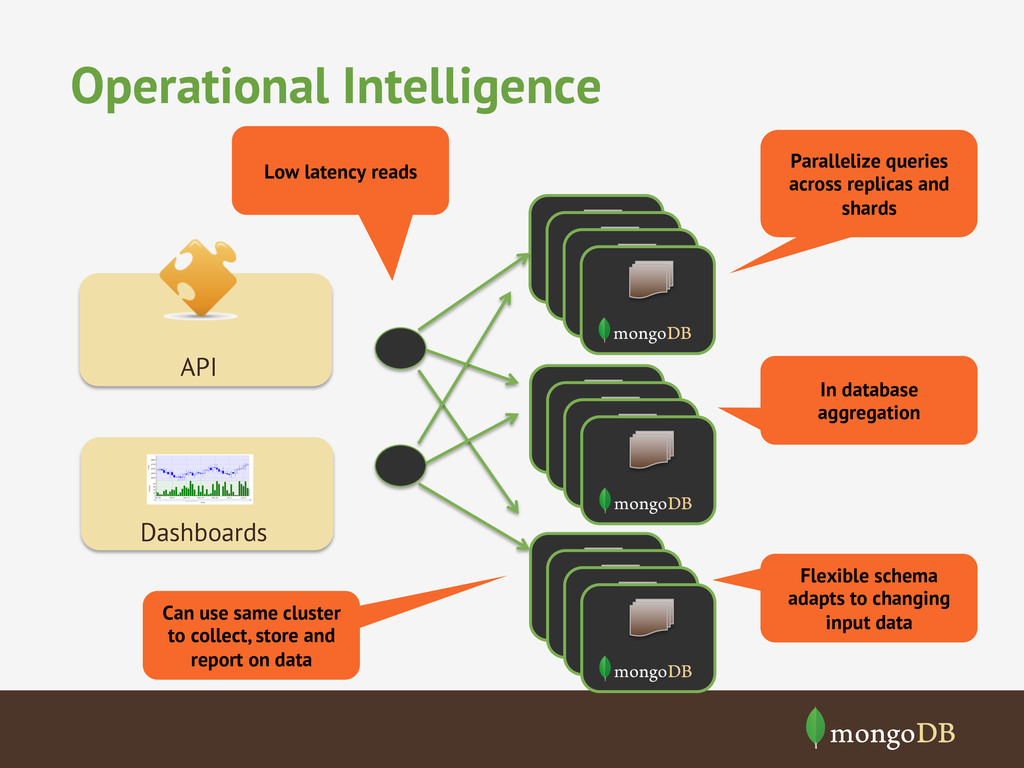
latency requirements Ad Targeting • Expose data to millions of customers • Reports on large volumes of data • Reports that update in real time Real time dashboards • Join the conversation Social Media Monitoring
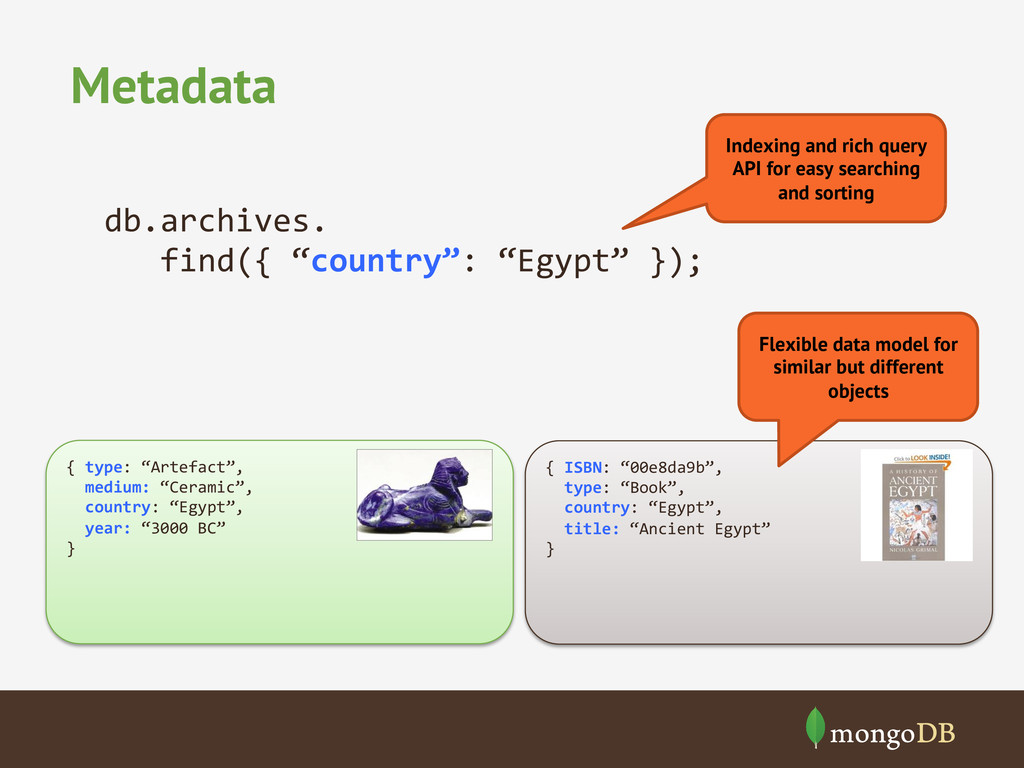
country: “Egypt”, title: “Ancient Egypt” } { type: “Artefact”, medium: “Ceramic”, country: “Egypt”, year: “3000 BC” } Flexible data model for similar but different objects Indexing and rich query API for easy searching and sorting db.archives. find({ “country”: “Egypt” });
of content, layout News Site • Generate layout on the fly • No need to cache static pages Multi-device rendering • Store large objects • Simpler modeling of metadata Sharing
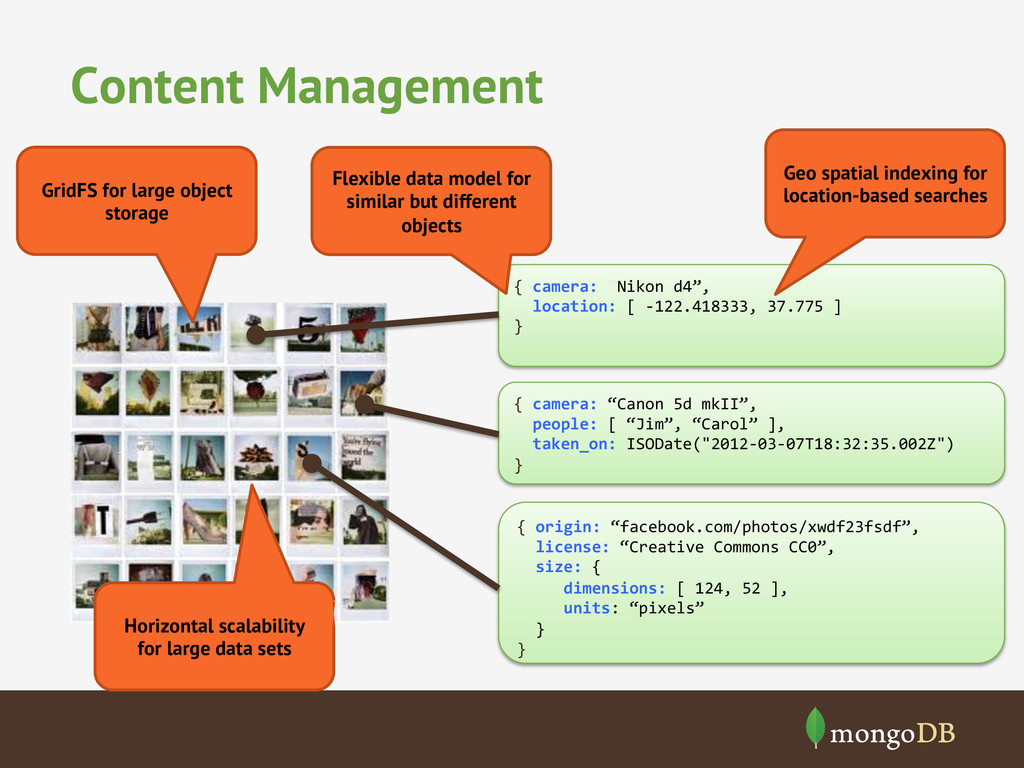
-‐122.418333, 37.775 ] } { camera: “Canon 5d mkII”, people: [ “Jim”, “Carol” ], taken_on: ISODate("2012-‐03-‐07T18:32:35.002Z") } { origin: “facebook.com/photos/xwdf23fsdf”, license: “Creative Commons CC0”, size: { dimensions: [ 124, 52 ], units: “pixels” } } Flexible data model for similar but different objects Horizontal scalability for large data sets Geo spatial indexing for location-based searches GridFS for large object storage
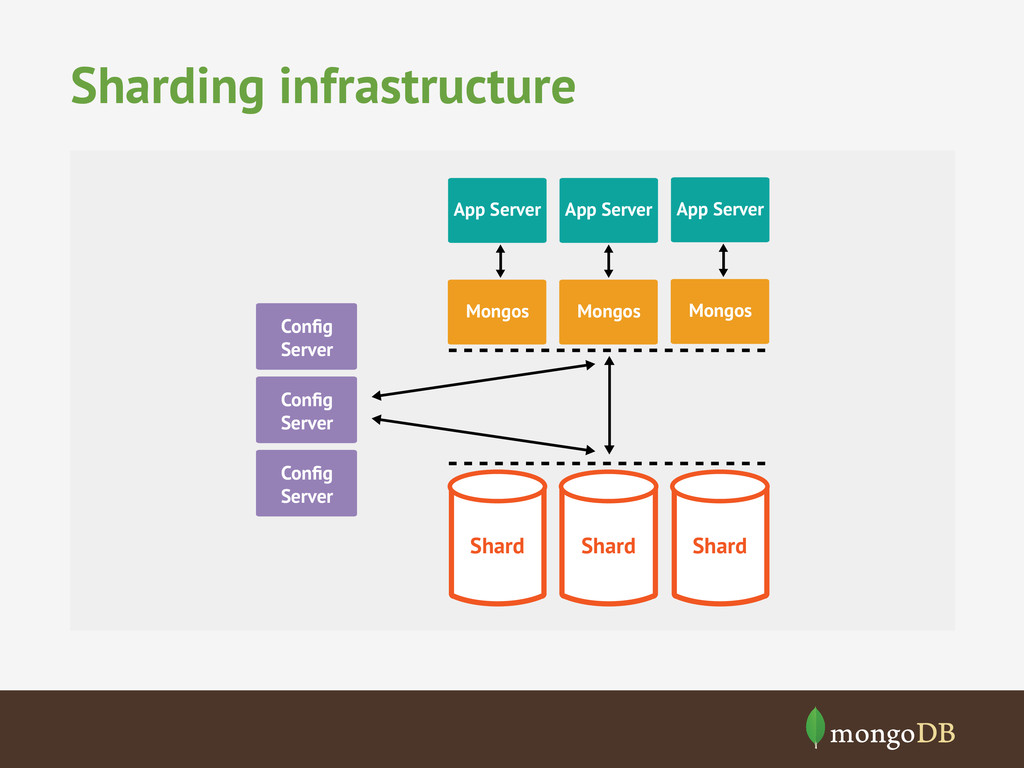
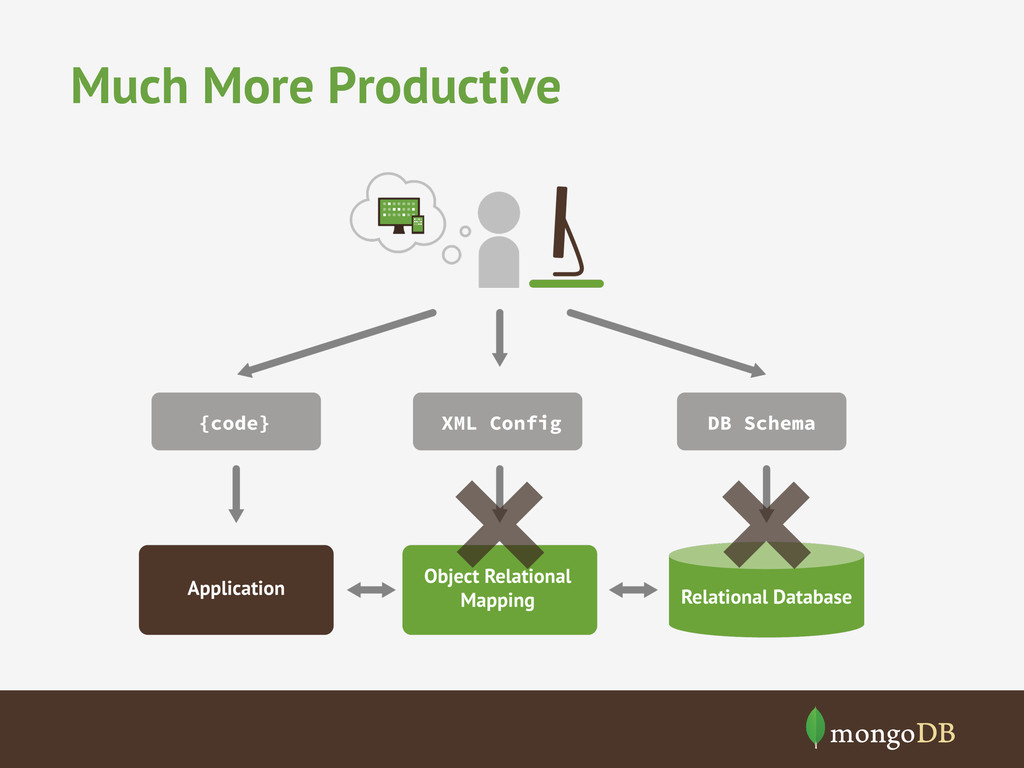
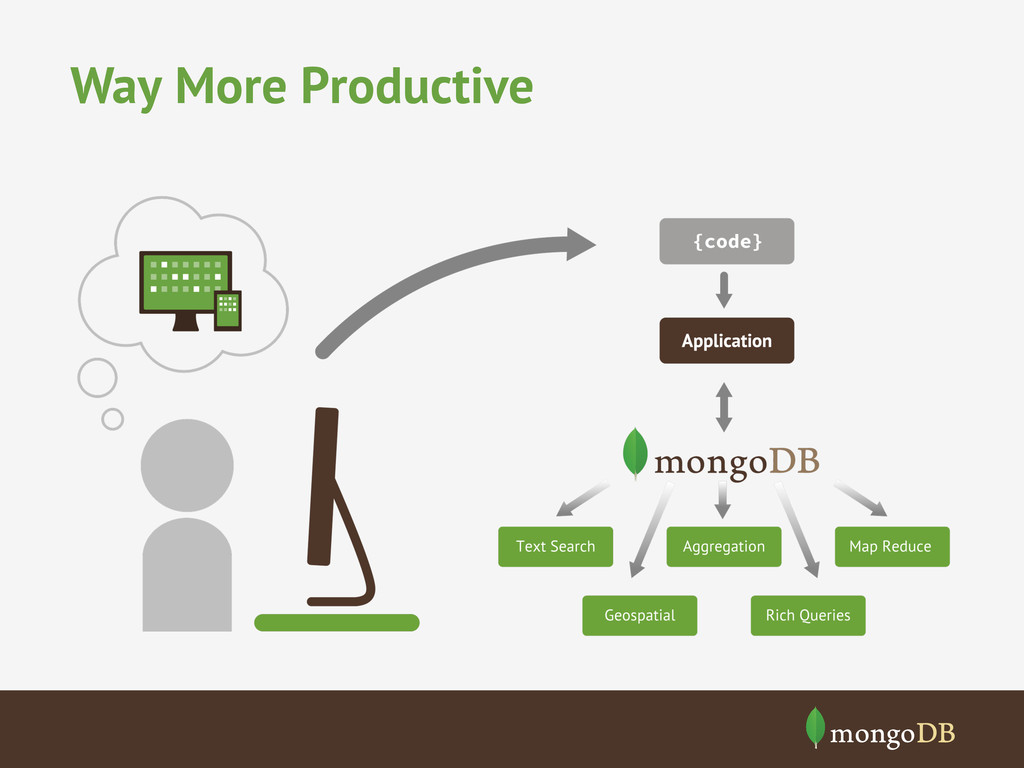
of objects to store Sharding lets you split objects across multiple servers High write or read throughput Sharding + Replication lets you scale read and write traffic across multiple servers Low latency access Memory mapped storage engine cahces documents in RAM, enabling in-memory performance. Data locality of documents can significantly improve latency over join-based approaches Variable data in objects Dynamic schema and JSON data model enable fleixlbe data storage without sparse tables or complex joins Cloud based deployment Sharding and replication let you work around hardware limitations in clouds.
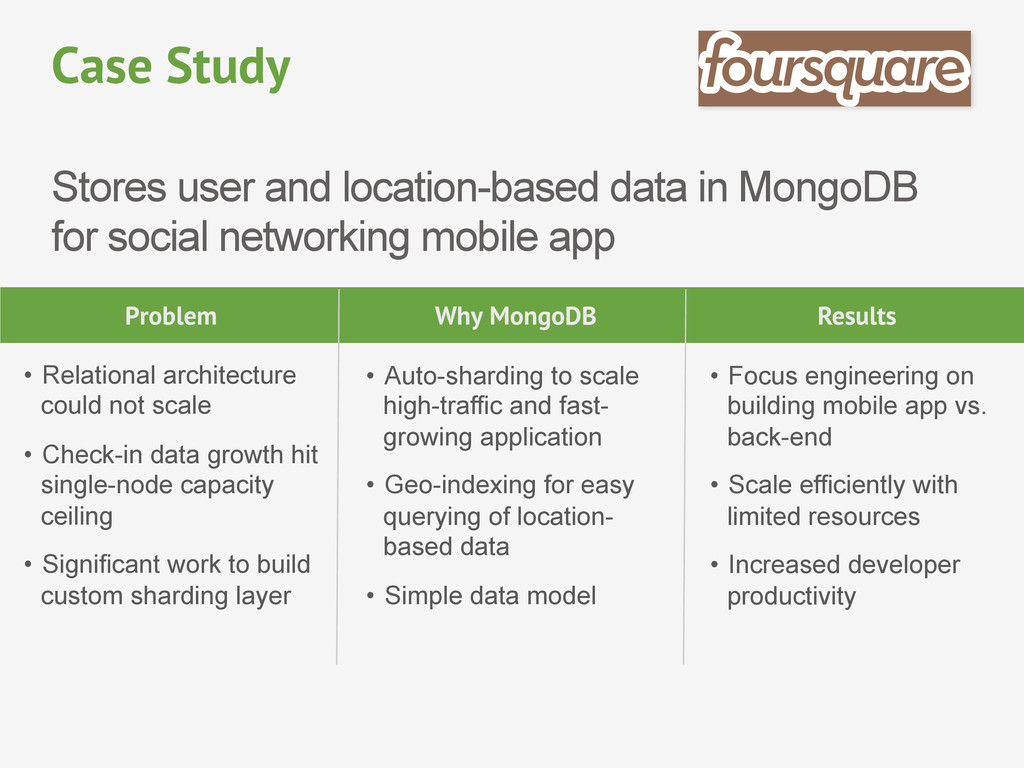
mobile app Case Study Problem Why MongoDB Results • Relational architecture could not scale • Check-in data growth hit single-node capacity ceiling • Significant work to build custom sharding layer • Auto-sharding to scale high-traffic and fast- growing application • Geo-indexing for easy querying of location- based data • Simple data model • Focus engineering on building mobile app vs. back-end • Scale efficiently with limited resources • Increased developer productivity
Case Study Problem Why MongoDB Results • 20M+ unique visitors per month • Rigid relational schema unable to evolve with changing data types and new features • Slow development cycles • Easy-to-manage dynamic data model enables limitless growth, interactive content • Support for ad hoc queries • Highly extensible • Rapid rollout of new features • Customized, social conversations throughout site • Tracks user data to increase engagement, revenue
Study Problem Why MongoDB Results • Needed to handle thousands of requests per second • MySQL resulted in millions of rows per month, per server • Difficult to scale MySQL with replication • General purpose DB • High-write throughput • Scales easily while maintaining performance • Easy-to-use replication and automated failover • Native PHP and Python drivers • MongoDB-first policy • 12+ TB ingested per month • Increased performance, decreased disk usage • Simplified infrastructure cuts costs, frees up resources for dev
millions of customers Case Study Problem Why MongoDB Results • 6B images, 20TB of data • Brittle code base on top of Oracle database – hard to scale, add features • High SW and HW costs • JSON-based data model • Agile, high performance, scalable • Alignment with Shutterfly’s services- based architecture • 80% cost reduction • 900% performance improvement • Faster time-to-market • Dev. cycles in weeks vs. tens of months
time dictionary Case Study Problem Why MongoDB Results • Performance roadblocks with MySQL • Massive data ingestion led to database outages • Tables locked for tens of seconds during inserts • Easy to store, locate, retrieve data • Eliminated Memcached while increasing performance: up to 2M requests per hour, 8,000 words inserted per second • Long runway for scale-out • Migrated 5B records in 1 day, zero downtime • Reduced code by 75% • Sped up document metadata retrieval from 30 ms to 0.1 ms • Significant cost savings, 15% reduction in servers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado [email protected] @nleite #mongodubai](https://files.speakerdeck.com/presentations/6104ec0037e8013110081a093079fa27/slide_49.jpg){kind=link}
{kind=link}