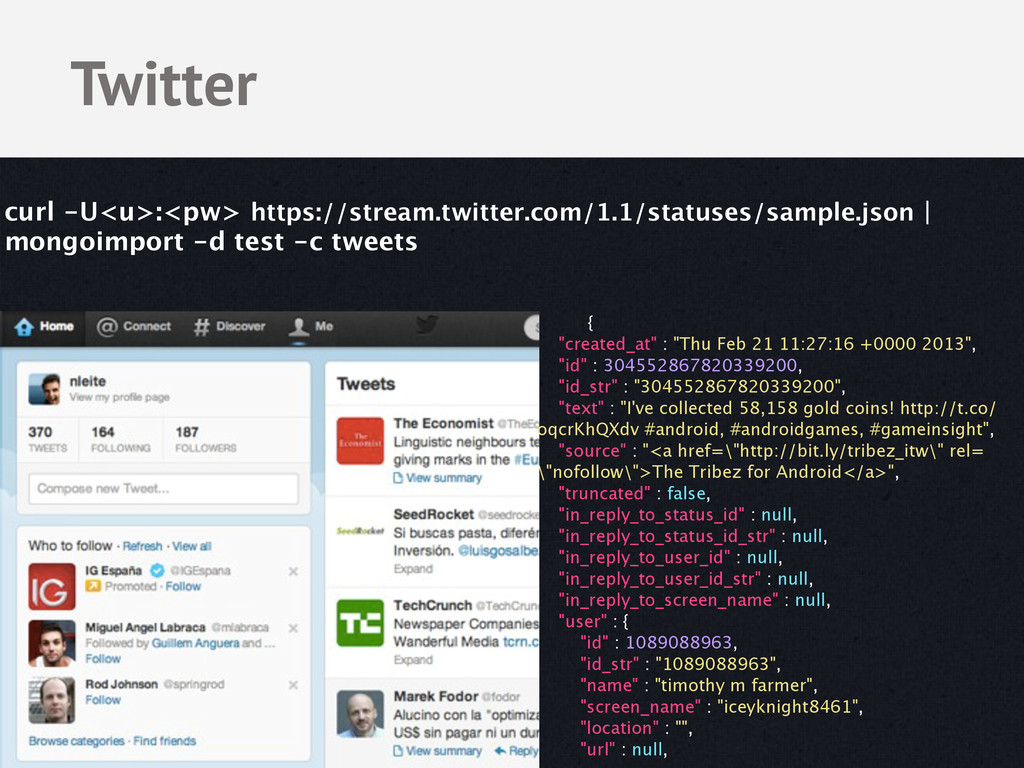
"id" : 304552867820339200, "id_str" : "304552867820339200", "text" : "I've collected 58,158 gold coins! http://t.co/ oqcrKhQXdv #android, #androidgames, #gameinsight", "source" : "<a href=\"http://bit.ly/tribez_itw\" rel= \"nofollow\">The Tribez for Android</a>", "truncated" : false, "in_reply_to_status_id" : null, "in_reply_to_status_id_str" : null, "in_reply_to_user_id" : null, "in_reply_to_user_id_str" : null, "in_reply_to_screen_name" : null, "user" : { "id" : 1089088963, "id_str" : "1089088963", "name" : "timothy m farmer", "screen_name" : "iceyknight8461", "location" : "", "url" : null, curl -U<u>:<pw> https://stream.twitter.com/1.1/statuses/sample.json | mongoimport -d test -c tweets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}