experiment ▸ Think about your user segments ▸ Don’t optimise very small parts of your product ▸ Don’t test too many versions in parallel ▸ Don’t get frustrated 4
define the key metrics you are working on ▸ understand the range of acceptable fluctuations ▸ look at specific time ranges ▸ NOT knowing this will lead to erroneous findings 5
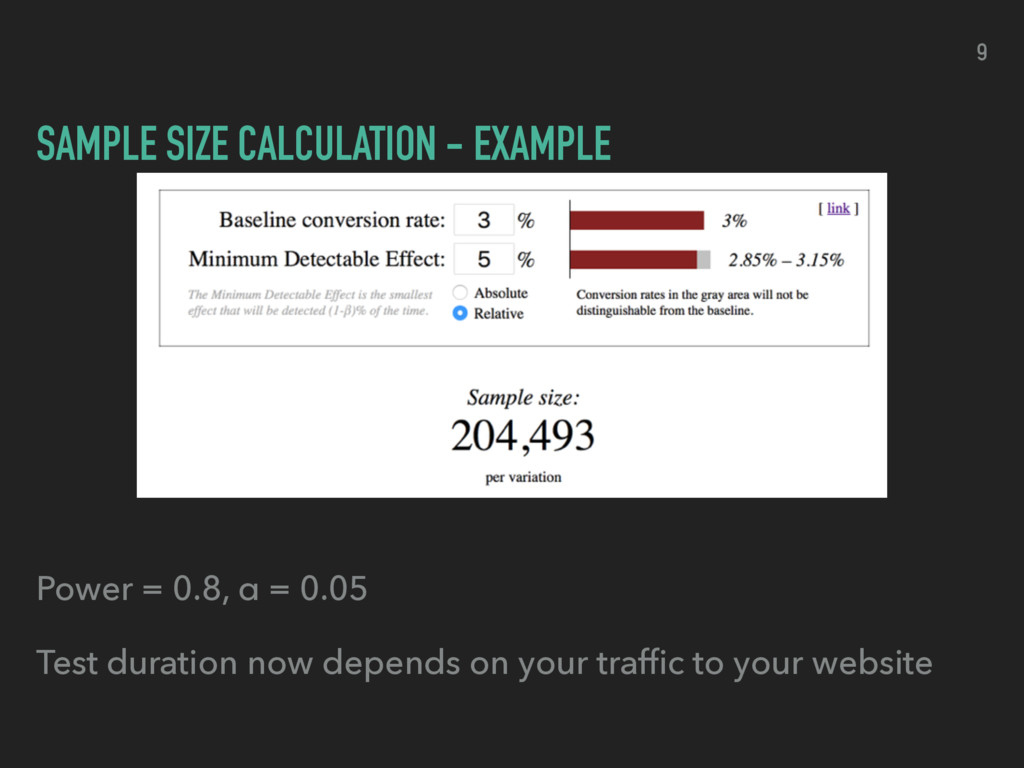
▸ define minimal detectable effect ▸ statistical power ▸ how often will you recognise a successful test ▸ typically 80% ▸ significance level ▸ how often will you observe a positive result although there is none ▸ typically 5% 8
the rules ▸ The experiment runs until the pre calculated sample size ▸ Your website has enough traffic ▸ You don’t look at your experiment while it is running ▸ You only do a simple A/B split experiment ▸ You are patient 10
based experiment evaluation ▸ calculate the p-value using your preferred test ▸ the probability of your data given your hypothesis ▸ you can only reject the null hypothesis ▸ NO indication of the importance of your result ▸ calculate confidence intervals ▸ capture the uncertainty of your measurement 11
experiment run time ▸ Statistical significance is not a valid stopping criterion ▸ p-value reaches significance very early on because of the novelty effect ▸ Confidence interval ▸ NOT 95% probability the true parameter falls within the interval 12
running experiment you increase your chance of falsely detecting a statistically significant result ▸ effectively corrupts your test ▸ Segmentation of experiment after the fact ▸ the greater n the more false positives ▸ Multiple goals 1 (1 0.05)n 13
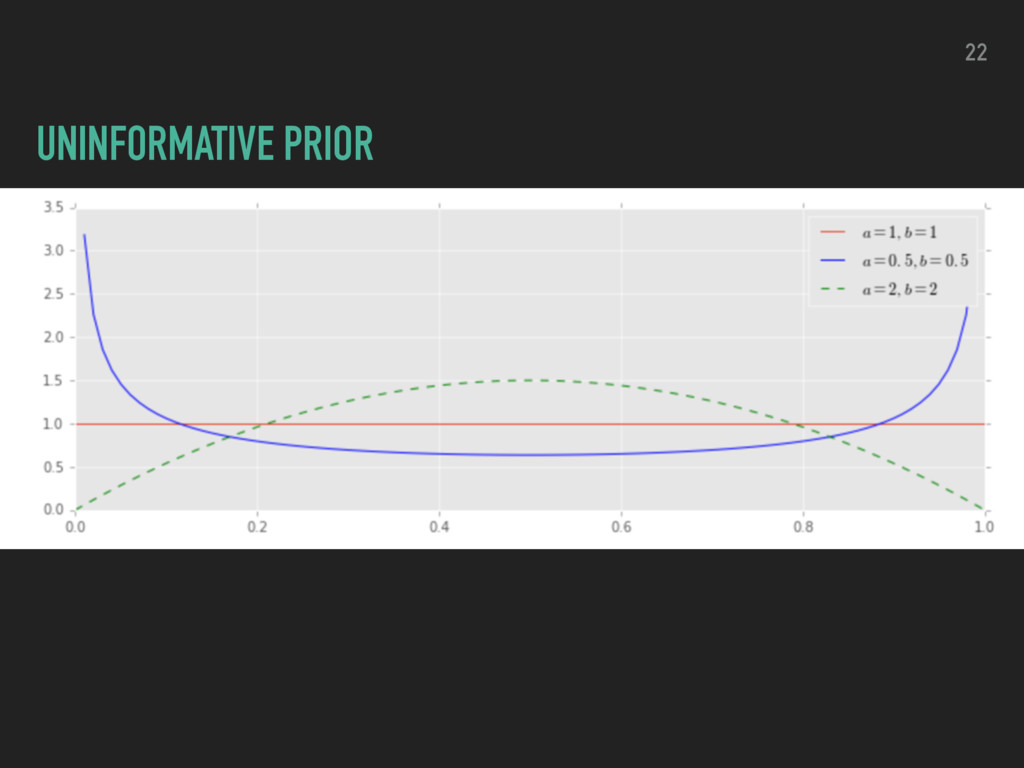
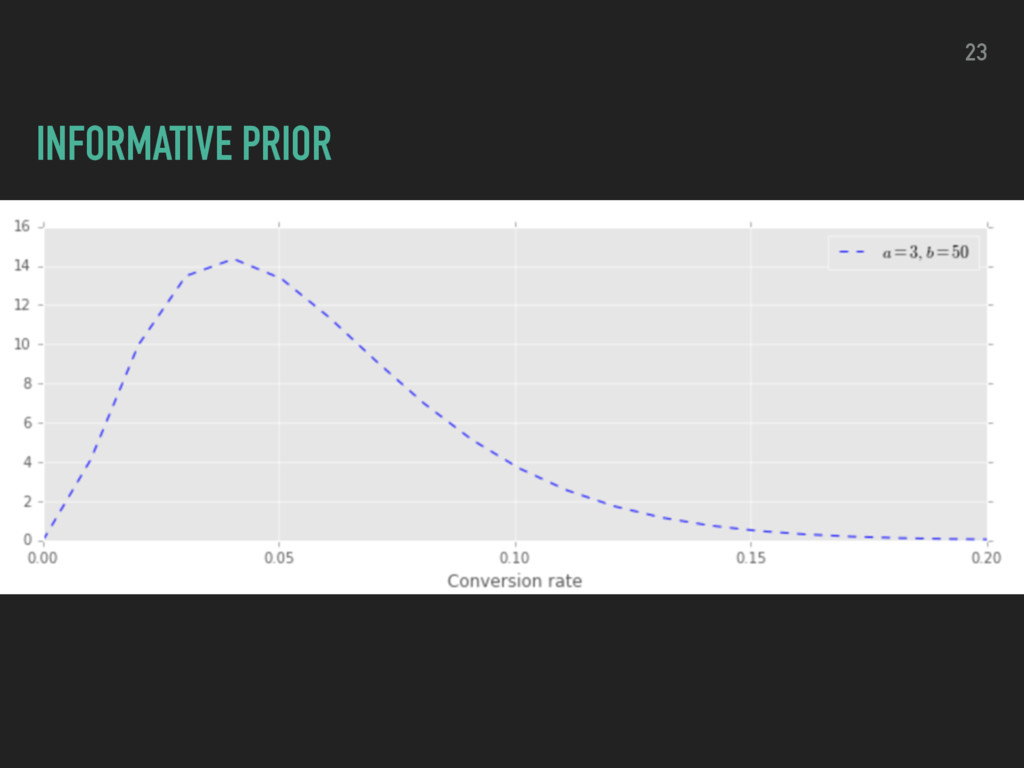
P(E) Posterior probability of your hypothesis given the evidence Prior probability of your hypothesis Likelihood of your evidence if hypothesis is true Prior probability that the evidence is true 16 POSTERIOR ∝ PRIOR * LIKELIHOOD
a coin flip - click or no-click ▸ compare 2 variants (A and B) ▸ Posterior probability is a two dimensional function of CVRA and CVRB P(CV RA, CV RB |data) = P(data|CV RA) P(CV RA) P(data|CV RB) P(CV RB) P(data) P(data) 18
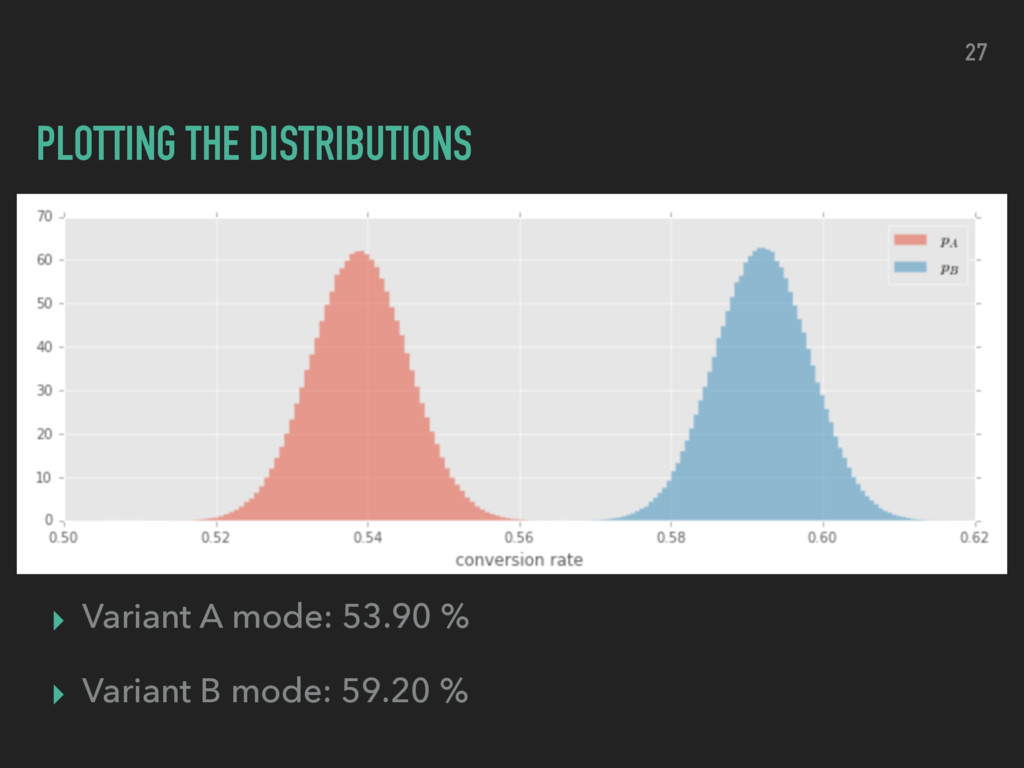
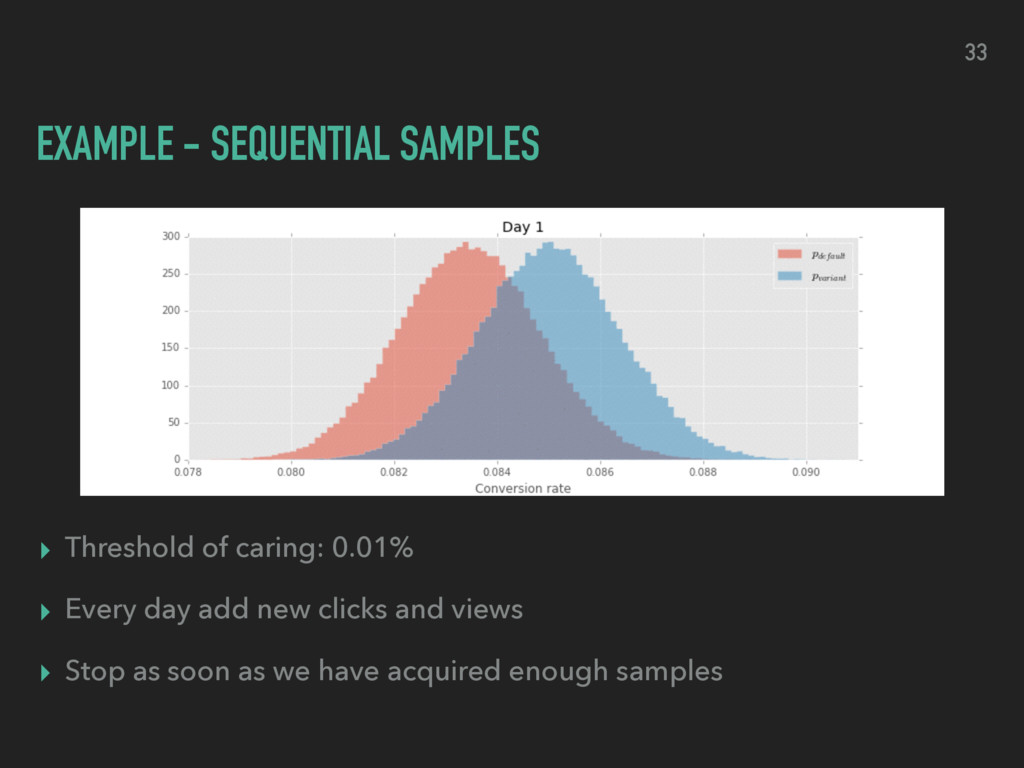
week ▸ find the posterior probability of the CVR of variant B is greater than variant A ▸ Monte Carlo style sampling Clicks Views Variant A 3254 6037 Variant B 3576 6040 24
samples for CVRA and CVRB from their respective posterior distribution ▸ To make this even easier we can do this in python using numpy ▸ Obtain distribution of credible conversion rates ▸ Highest density interval (HDI) 25
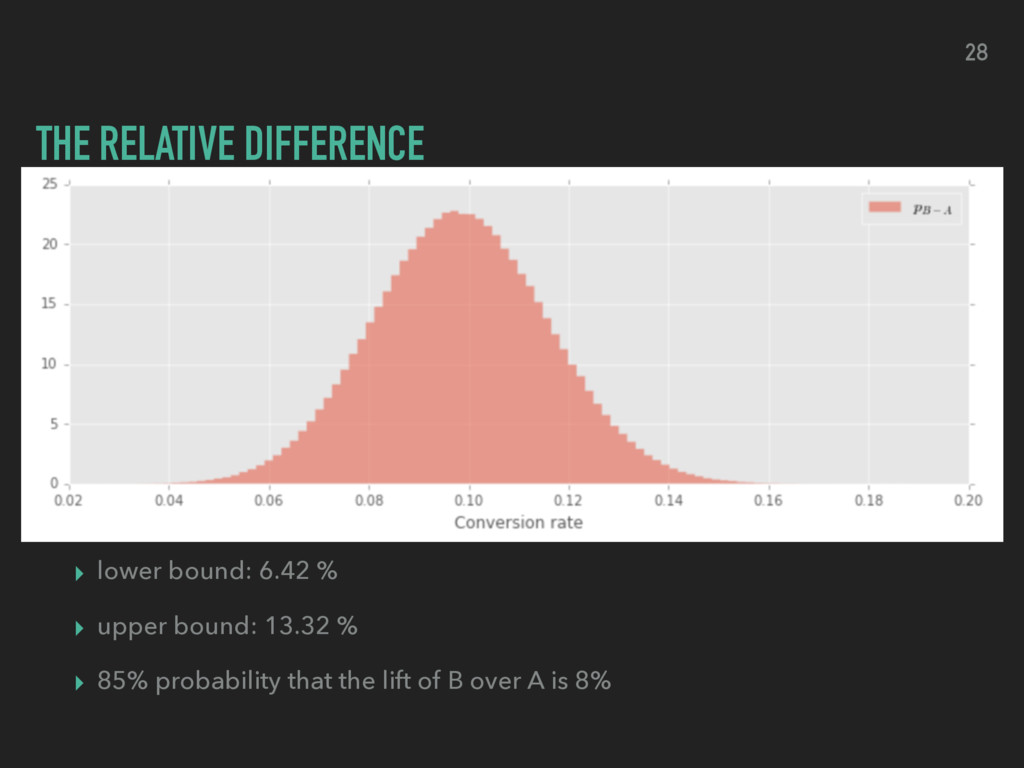
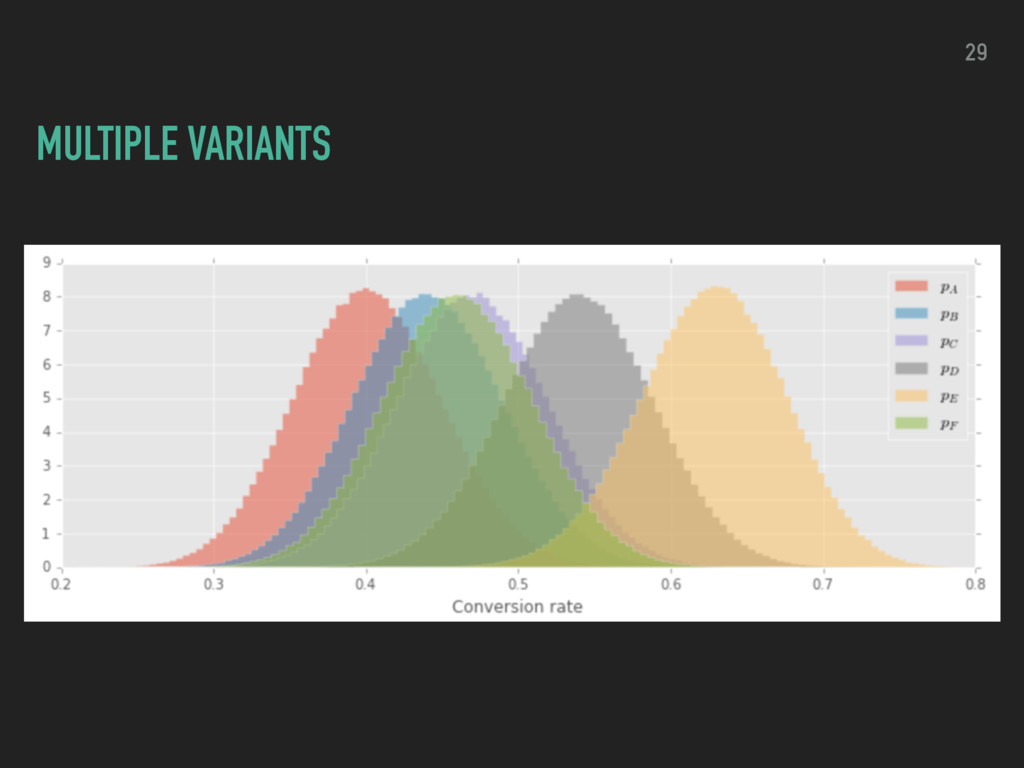
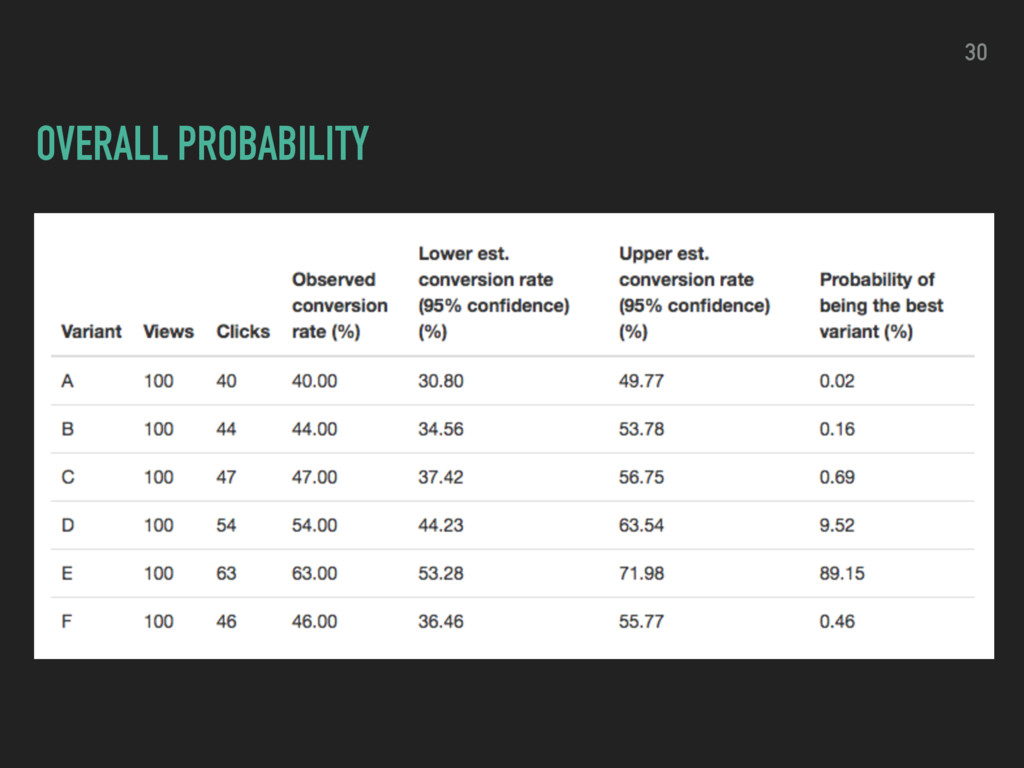
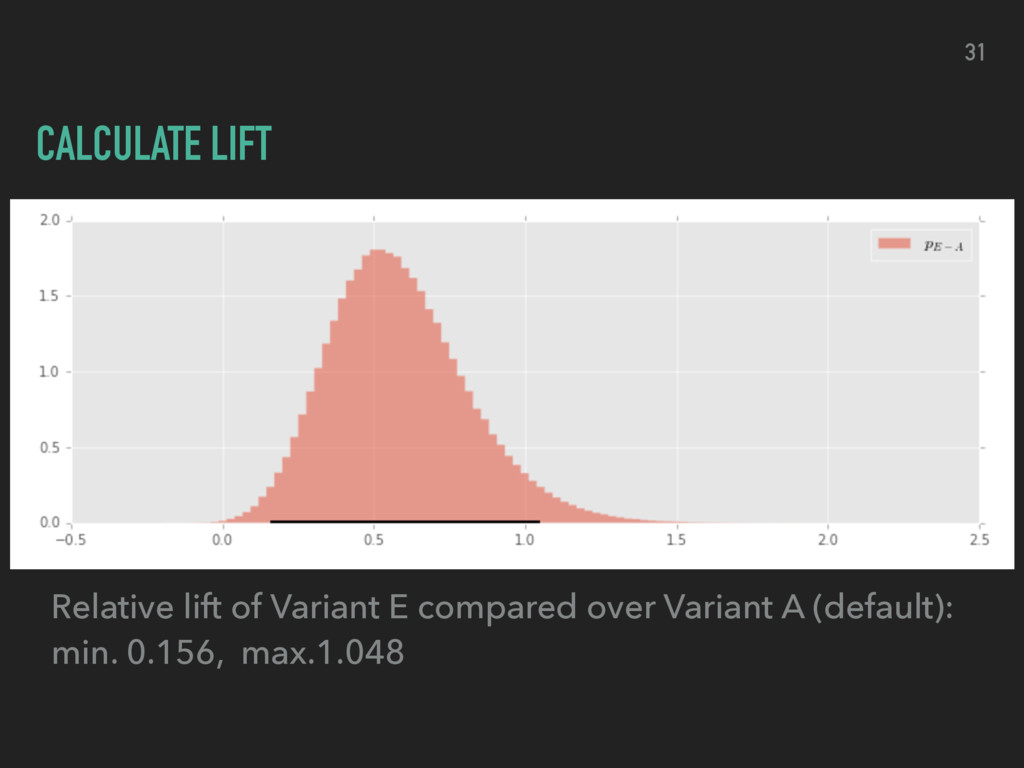
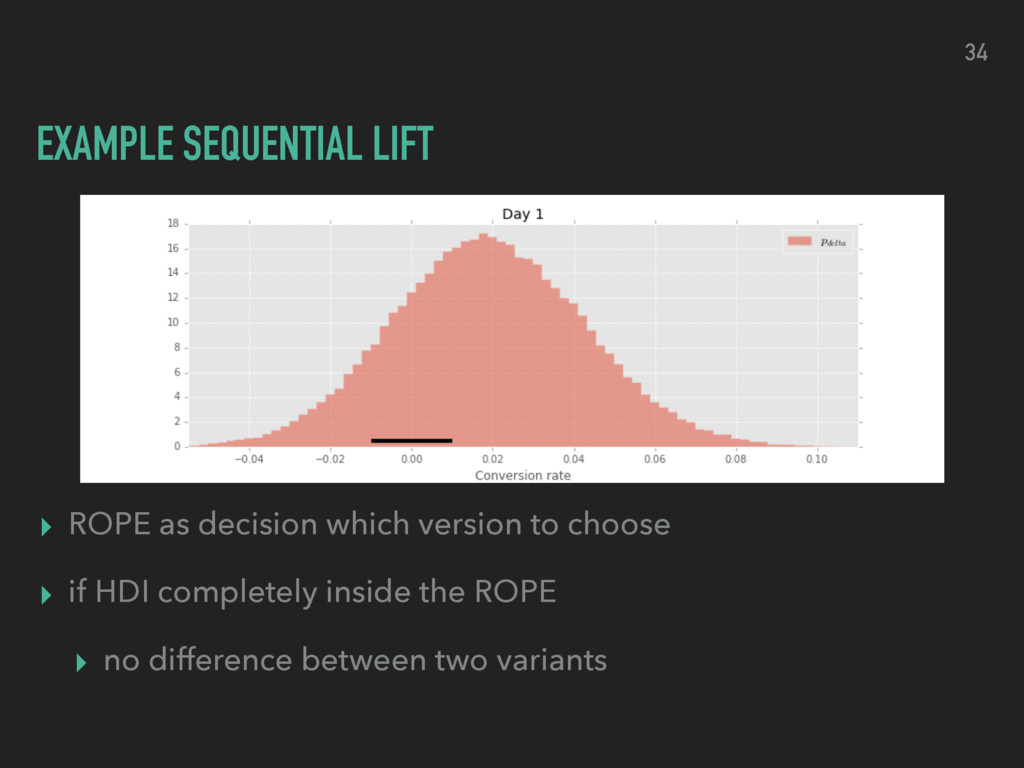
choosing one variant over the other ▸ evaluate the ROPE (region of practical equivalence) ▸ compare ROPE and HDI for relative lift ▸ decide which version to use by weighing potential losses proportional to the lift being lost 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}