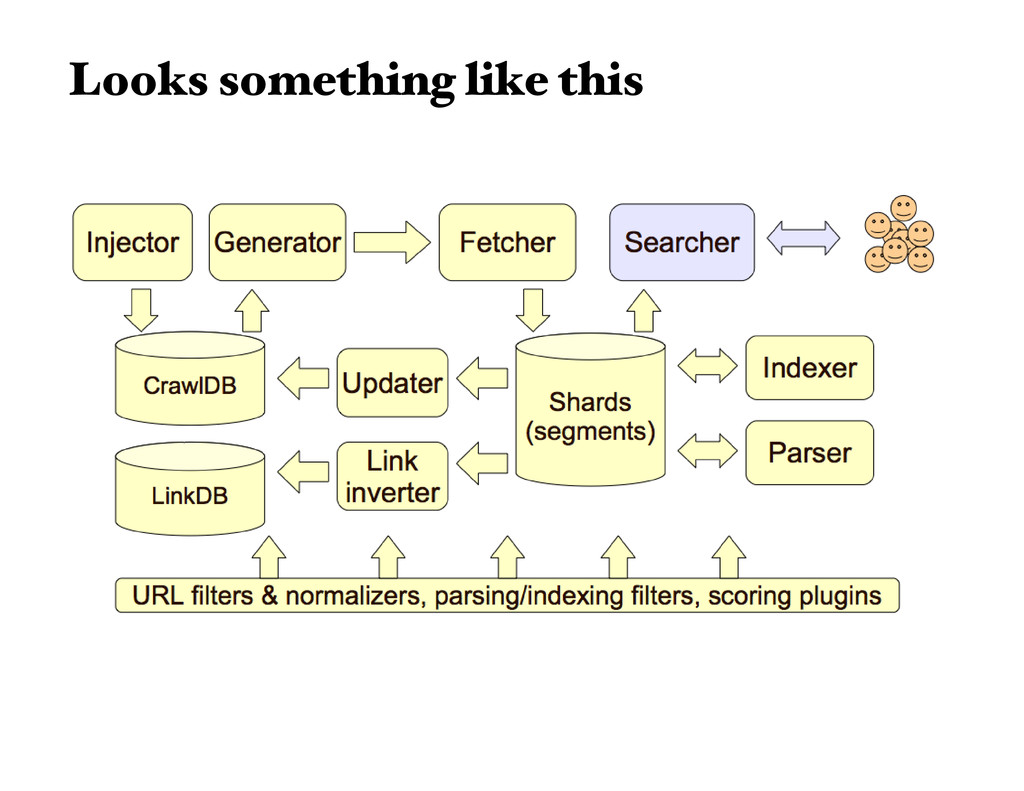
crawler written in Java. By using it, we can find Web page hyperlinks in an automated manner, reduce lots of maintenance work, for example checking broken links, and create a copy of all the visited pages for searching over (using solr). Multi-protocol, multi-threaded, distributed crawler Full-text indexer and support for distributed search (Solr) Plugin based, highly modular (if ur into Java)
framework, with Solr we can search the visited pages from Nutch. Luckily, integration between Nutch and Solr is pretty straightforward. Apache Nutch supports Solr out-the-box, greatly simplifying Nutch-Solr integration. However, Solr needs to be have specific field mappings setup to properly handle indexing requests from Nutch. There is a schema.xml file located in the Nutch conf directory which contains a Solr schema that Nutch utilizes and expects to be present when posting data. A recommended course of action would be to use this schema in it's own core instance in Solr, assuming you are running Solr in multicore mode. Nutch-to-Solr Index Structure
bzip2, gz, tgz Text Document Formats doc, xls, ppt, rtf, pdf, html, xhtml, OpenDocument, txt Image Formats bmp, gif, png, jpeg, tiff Audio Formats mp3, aiff, au, midi, wav Misc Formats pst (Outlook Mail), xml, class SIDENOTE An endpoint can be configured in solr for parsing and indexing documents without Nutch. I was tinkering around with this before I started working with Nutch. I prefer the flexibilty of the request handler in Solr, because you could configure it to ignore divs and store paragraph tags so search results looked more authentic.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}