Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWS ParallelClusterでTrainiumを使って大規模言語モデルをトレーニング...
Search
nokomoro3
November 13, 2024
580
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWS ParallelClusterでTrainiumを使って大規模言語モデルをトレーニングする方法
2024-11-13_まるクラ勉強会
nokomoro3
November 13, 2024
More Decks by nokomoro3
See All by nokomoro3
今から始めるClaude Code入門〜AIコーディングエージェントの歴史と導入〜
nokomoro3
0
1.1k
AIや機械学習を更に発展的に学んで、キャリアの強みにしていく方法
nokomoro3
0
610
re:Invent 2024 振り返り re:Growth AIML アップデート 個人的ニュース
nokomoro3
0
940
pandasとpolarsと私
nokomoro3
2
2.5k
Featured
See All Featured
Raft: Consensus for Rubyists
vanstee
141
7.6k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Faster Mobile Websites
deanohume
310
32k
Code Reviewing Like a Champion
maltzj
528
40k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Ruling the World: When Life Gets Gamed
codingconduct
0
270
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
280
Music & Morning Musume
bryan
47
7.3k
Transcript
2024/11/13 データ事業本部 中村祥吾 AWS ParallelCluster + Trainiumを使って 大規模言語モデルをトレーニングする入門
今日は 2 • ParallelClusterって何? • 基本的な使い方は? • 大規模言語モデル向けにはどうすれば? • 何から始めたら良い?
ParallelClusterに入門しよう!!
• データ事業本部で機械学習エンジニアしています • 機械学習基盤を作ったり、ブログ書いたり、登壇したりしてます 私について 3 中村祥吾 / nokomoro3 /
ハラショー ・X https://twitter.com/nokomoro3 ・ブログ https://dev.classmethod.jp/author/shogo-nakamura/ https://qiita.com/nokomoro3 ・Kaggle https://www.kaggle.com/snkmr0221
ParallelClusterって何?
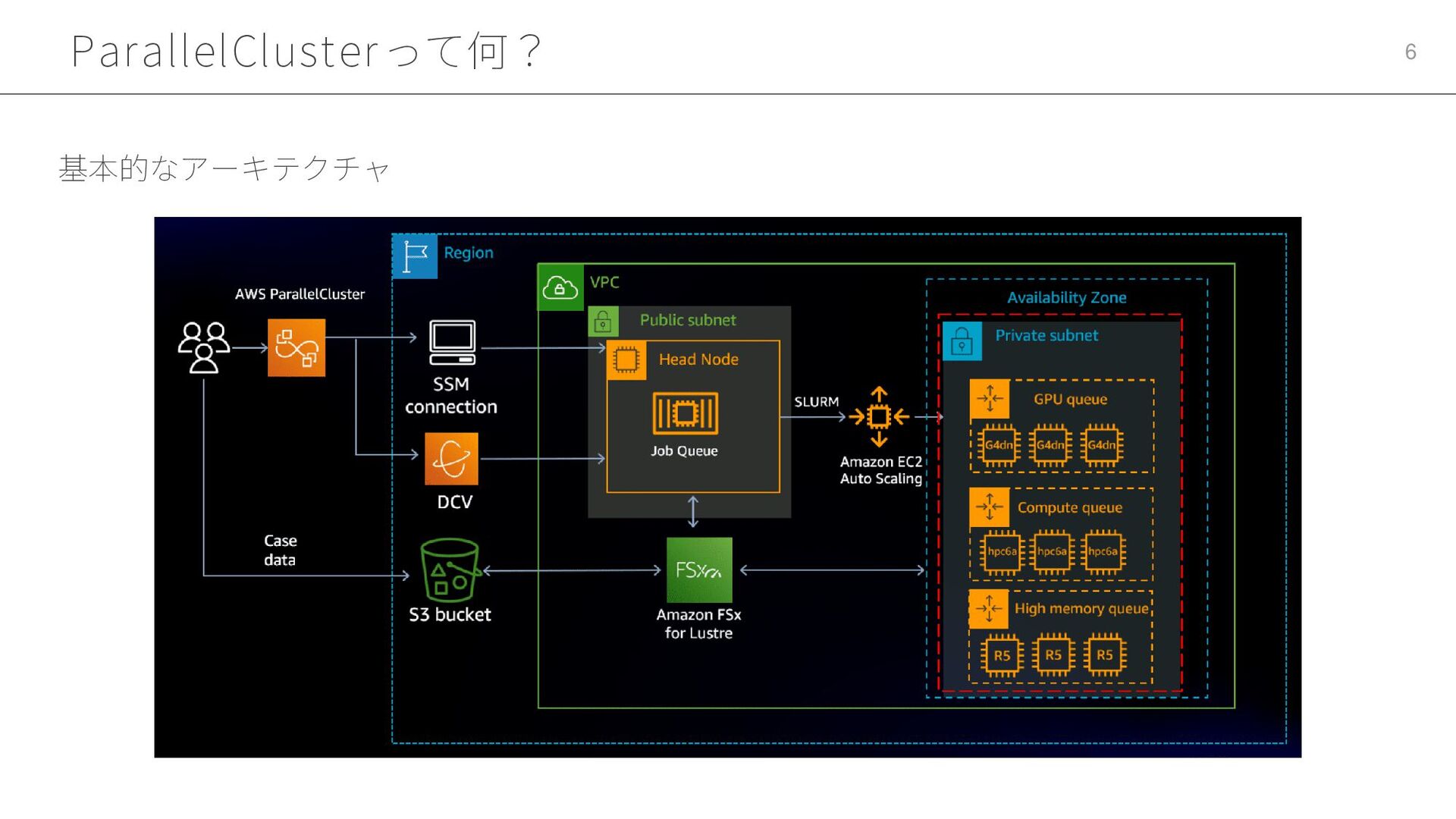
ParallelClusterって何? 5 • HPCクラスタは高負荷な処理を複数のマシンノードで分散処理するための環境 ・高負荷な処理:気象予測、金融モデリング、ゲノム解析 ・機械学習モデルの学習などももちろん可能 • サービスとしてマネジメントコンソールには存在しない ・実体としてはEC2などを作るCloudFormationのテンプレートが動く ・コストもこれらのリソースに対して発生
AWS上でHPCクラスタを管理するためのオープンソースのツール AWS ParallelCluster
ParallelClusterって何? 6 基本的なアーキテクチャ
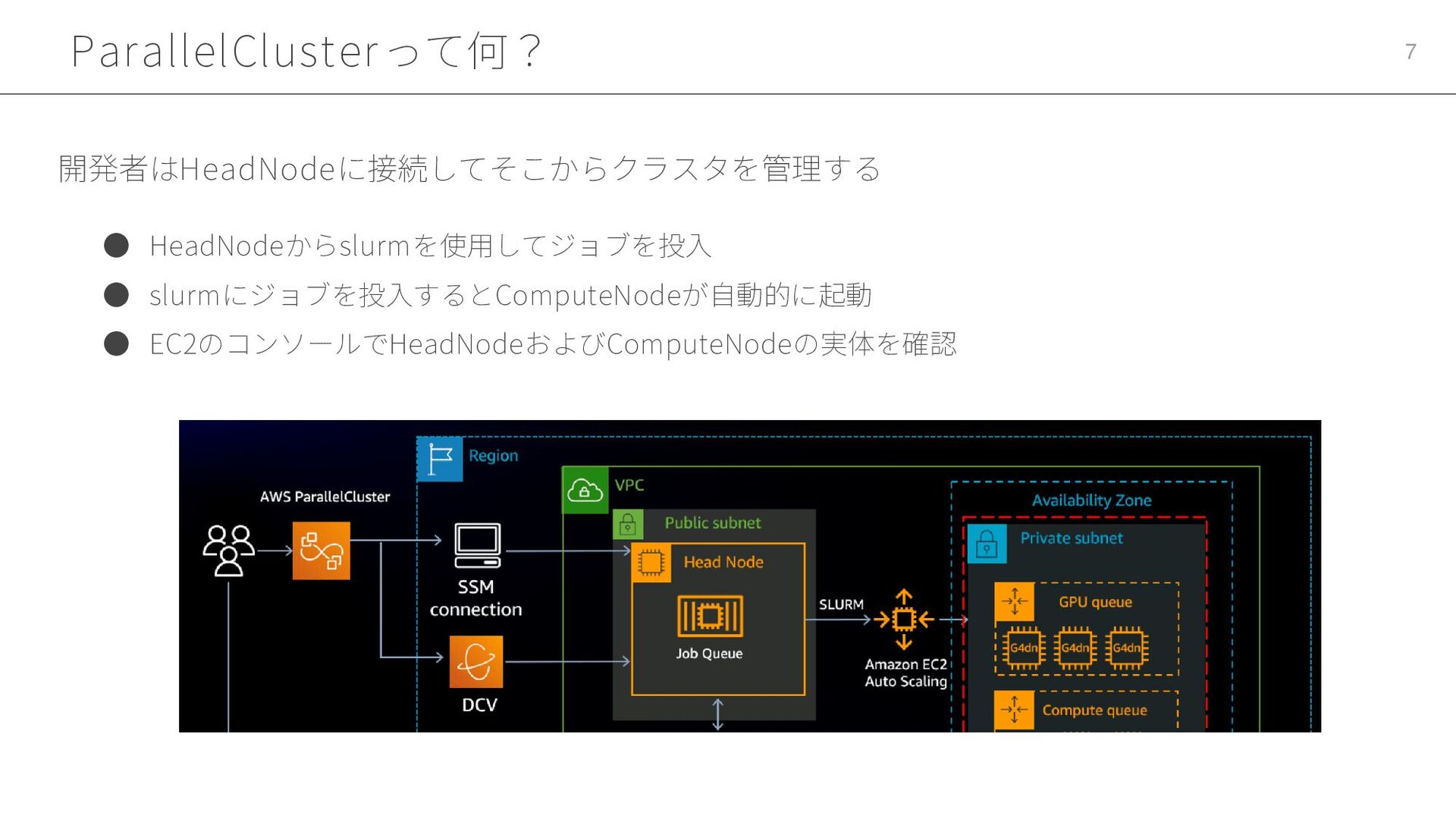
ParallelClusterって何? 7 • HeadNodeからslurmを使用してジョブを投入 • slurmにジョブを投入するとComputeNodeが自動的に起動 • EC2のコンソールでHeadNodeおよびComputeNodeの実体を確認 開発者はHeadNodeに接続してそこからクラスタを管理する
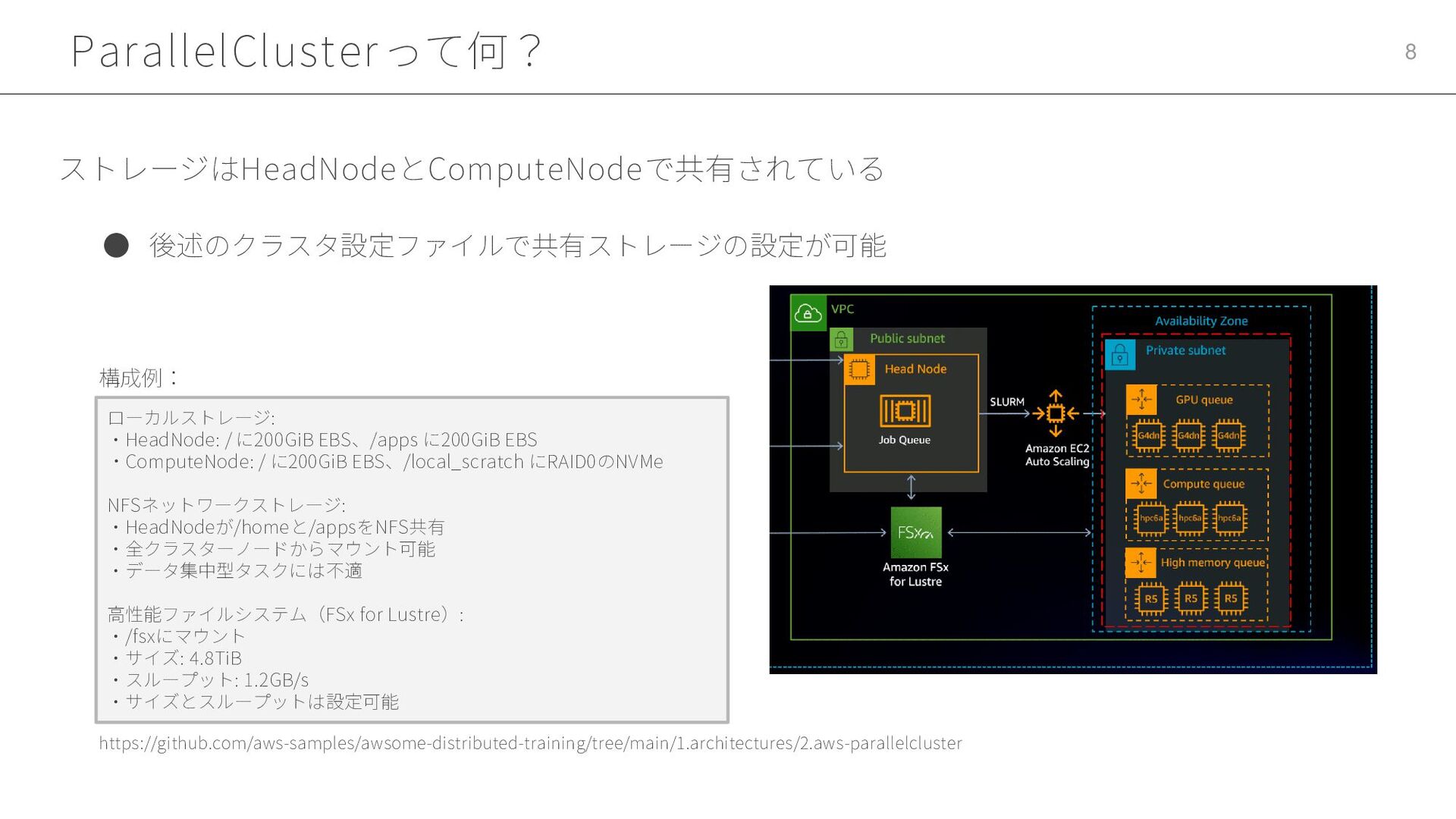
ParallelClusterって何? 8 • 後述のクラスタ設定ファイルで共有ストレージの設定が可能 ストレージはHeadNodeとComputeNodeで共有されている ローカルストレージ: ・HeadNode: / に200GiB EBS、/apps
に200GiB EBS ・ComputeNode: / に200GiB EBS、/local_scratch にRAID0のNVMe NFSネットワークストレージ: ・HeadNodeが/homeと/appsをNFS共有 ・全クラスターノードからマウント可能 ・データ集中型タスクには不適 高性能ファイルシステム(FSx for Lustre): ・/fsxにマウント ・サイズ: 4.8TiB ・スループット: 1.2GB/s ・サイズとスループットは設定可能 構成例: https://github.com/aws-samples/awsome-distributed-training/tree/main/1.architectures/2.aws-parallelcluster
基本的な使い方は?
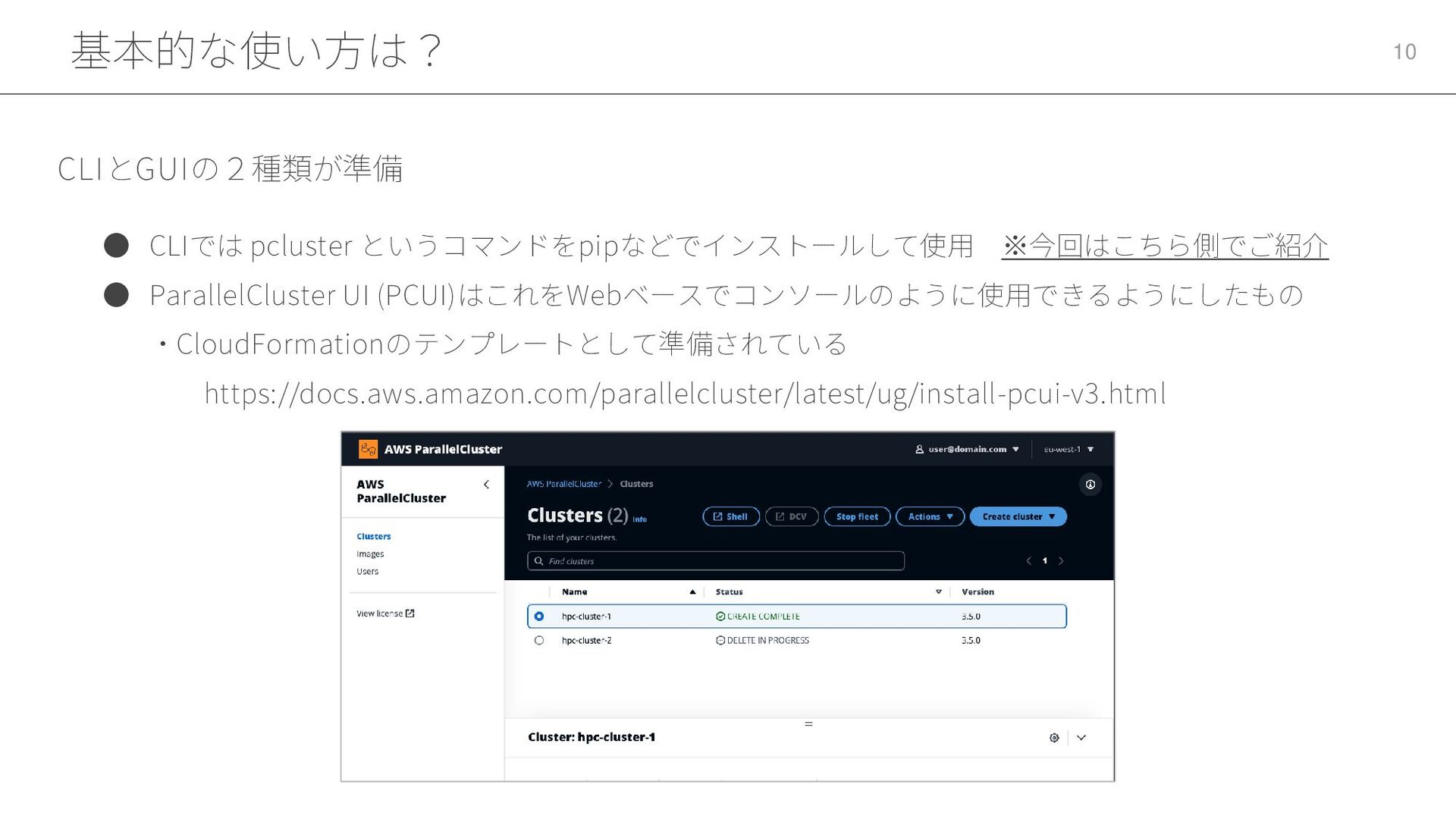
基本的な使い方は? 10 • CLIでは pcluster というコマンドをpipなどでインストールして使用 ※今回はこちら側でご紹介 • ParallelCluster UI
(PCUI)はこれをWebベースでコンソールのように使用できるようにしたもの ・CloudFormationのテンプレートとして準備されている https://docs.aws.amazon.com/parallelcluster/latest/ug/install-pcui-v3.html CLIとGUIの2種類が準備
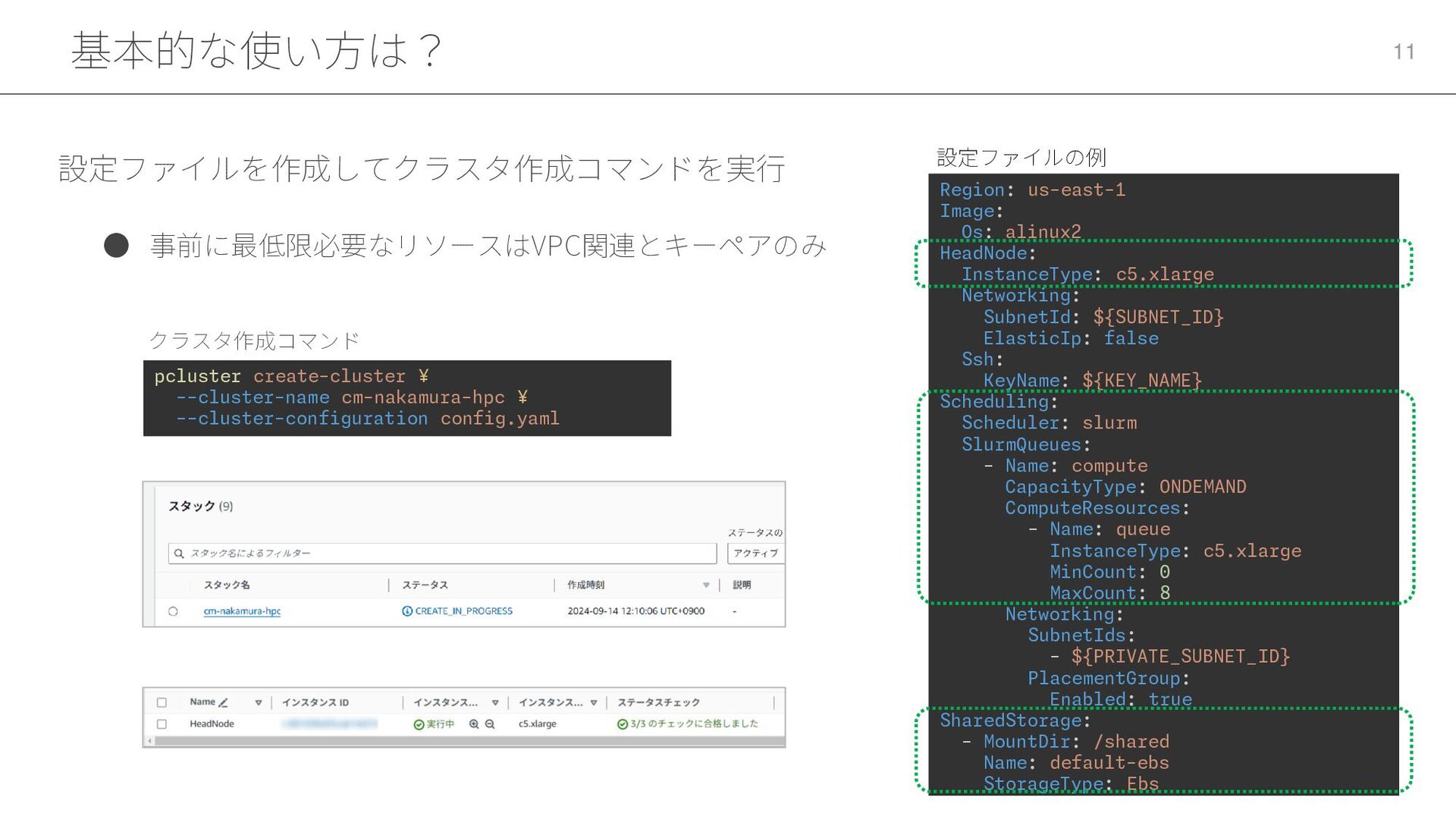
基本的な使い方は? 11 • 事前に最低限必要なリソースはVPC関連とキーペアのみ 設定ファイルを作成してクラスタ作成コマンドを実行 Region: us-east-1 Image: Os: alinux2
HeadNode: InstanceType: c5.xlarge Networking: SubnetId: ${SUBNET_ID} ElasticIp: false Ssh: KeyName: ${KEY_NAME} Scheduling: Scheduler: slurm SlurmQueues: - Name: compute CapacityType: ONDEMAND ComputeResources: - Name: queue InstanceType: c5.xlarge MinCount: 0 MaxCount: 8 Networking: SubnetIds: - ${PRIVATE_SUBNET_ID} PlacementGroup: Enabled: true SharedStorage: - MountDir: /shared Name: default-ebs StorageType: Ebs pcluster create-cluster ¥ --cluster-name cm-nakamura-hpc ¥ --cluster-configuration config.yaml 設定ファイルの例 クラスタ作成コマンド
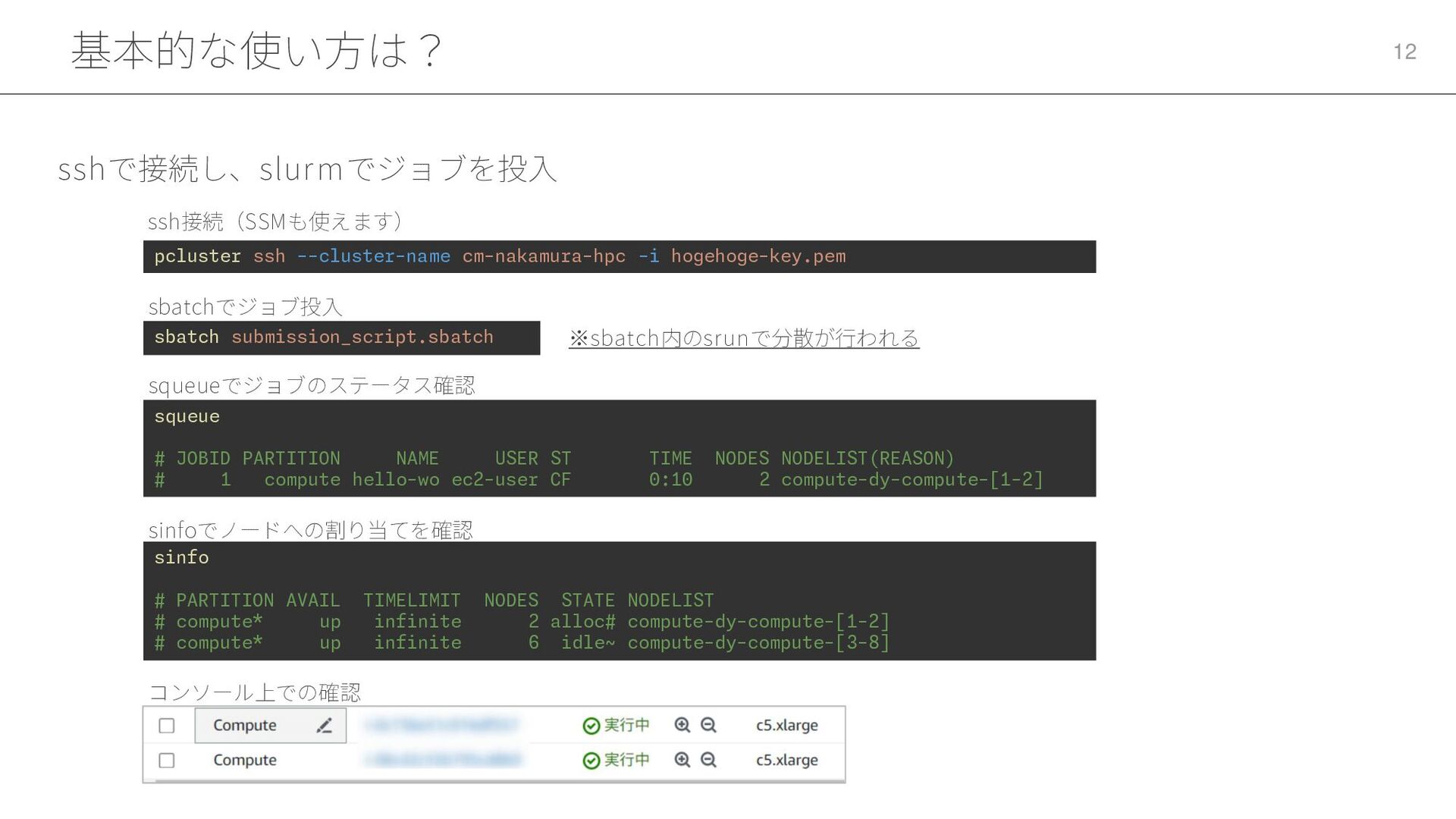
基本的な使い方は? 12 sshで接続し、slurmでジョブを投入 pcluster ssh --cluster-name cm-nakamura-hpc -i hogehoge-key.pem sbatch
submission_script.sbatch squeue # JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) # 1 compute hello-wo ec2-user CF 0:10 2 compute-dy-compute-[1-2] sinfo # PARTITION AVAIL TIMELIMIT NODES STATE NODELIST # compute* up infinite 2 alloc# compute-dy-compute-[1-2] # compute* up infinite 6 idle~ compute-dy-compute-[3-8] ssh接続(SSMも使えます) sbatchでジョブ投入 squeueでジョブのステータス確認 sinfoでノードへの割り当てを確認 コンソール上での確認 ※sbatch内のsrunで分散が行われる
基本的な使い方は? 13 クラスタ設定とslurmの参考 • クラスタ設定の詳細 ・https://docs.aws.amazon.com/parallelcluster/latest/ug/cluster-configuration-file-v3.html • slurmコマンドの詳細 ・https://www.j-focus.jp/user_guide/ug0004020000/ ・https://slurm.schedmd.com/man_index.html
どうやって大規模言語モデル向けに使う?
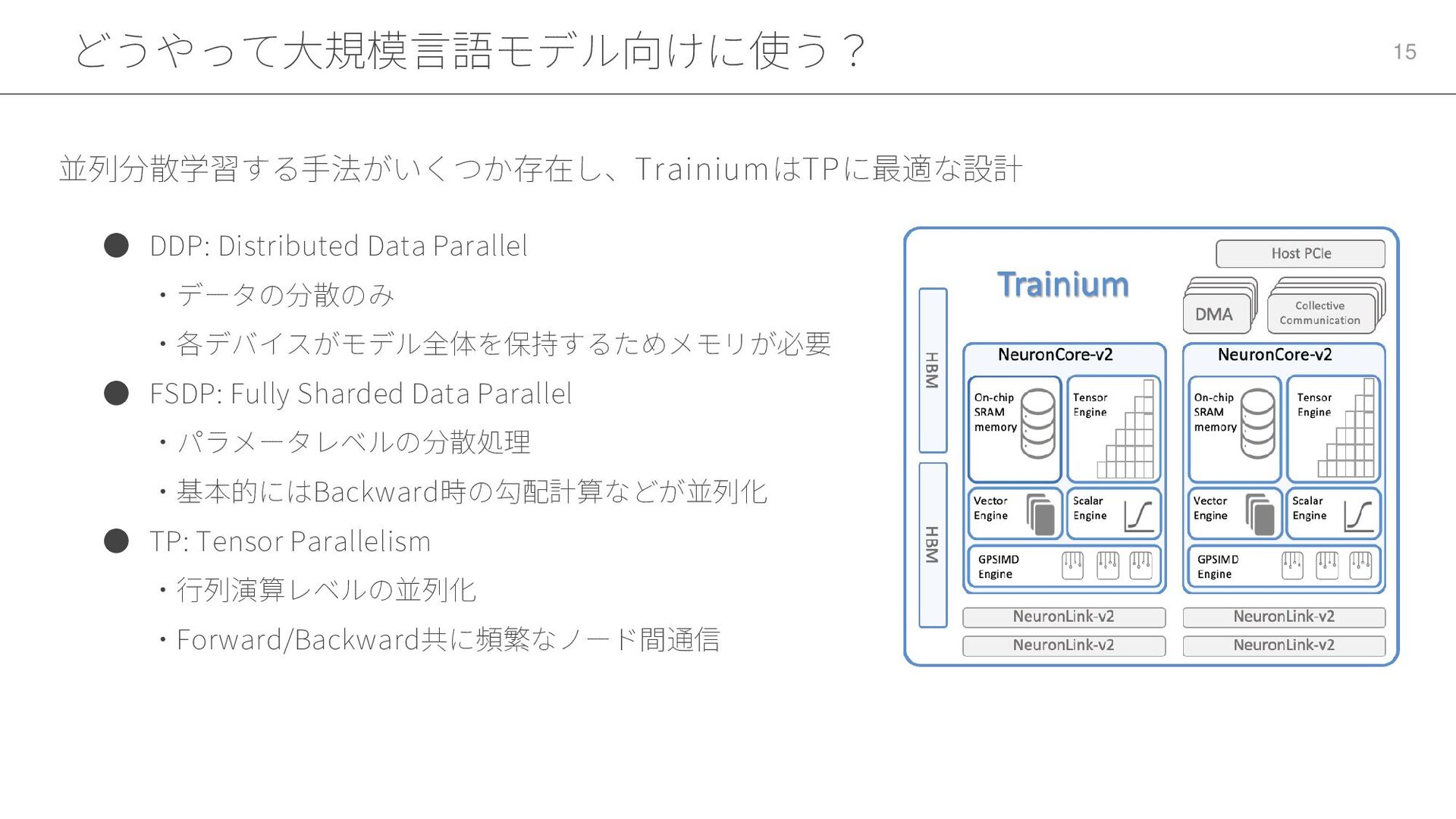
どうやって大規模言語モデル向けに使う? 15 • DDP: Distributed Data Parallel ・データの分散のみ ・各デバイスがモデル全体を保持するためメモリが必要 •
FSDP: Fully Sharded Data Parallel ・パラメータレベルの分散処理 ・基本的にはBackward時の勾配計算などが並列化 • TP: Tensor Parallelism ・行列演算レベルの並列化 ・Forward/Backward共に頻繁なノード間通信 並列分散学習する手法がいくつか存在し、TrainiumはTPに最適な設計
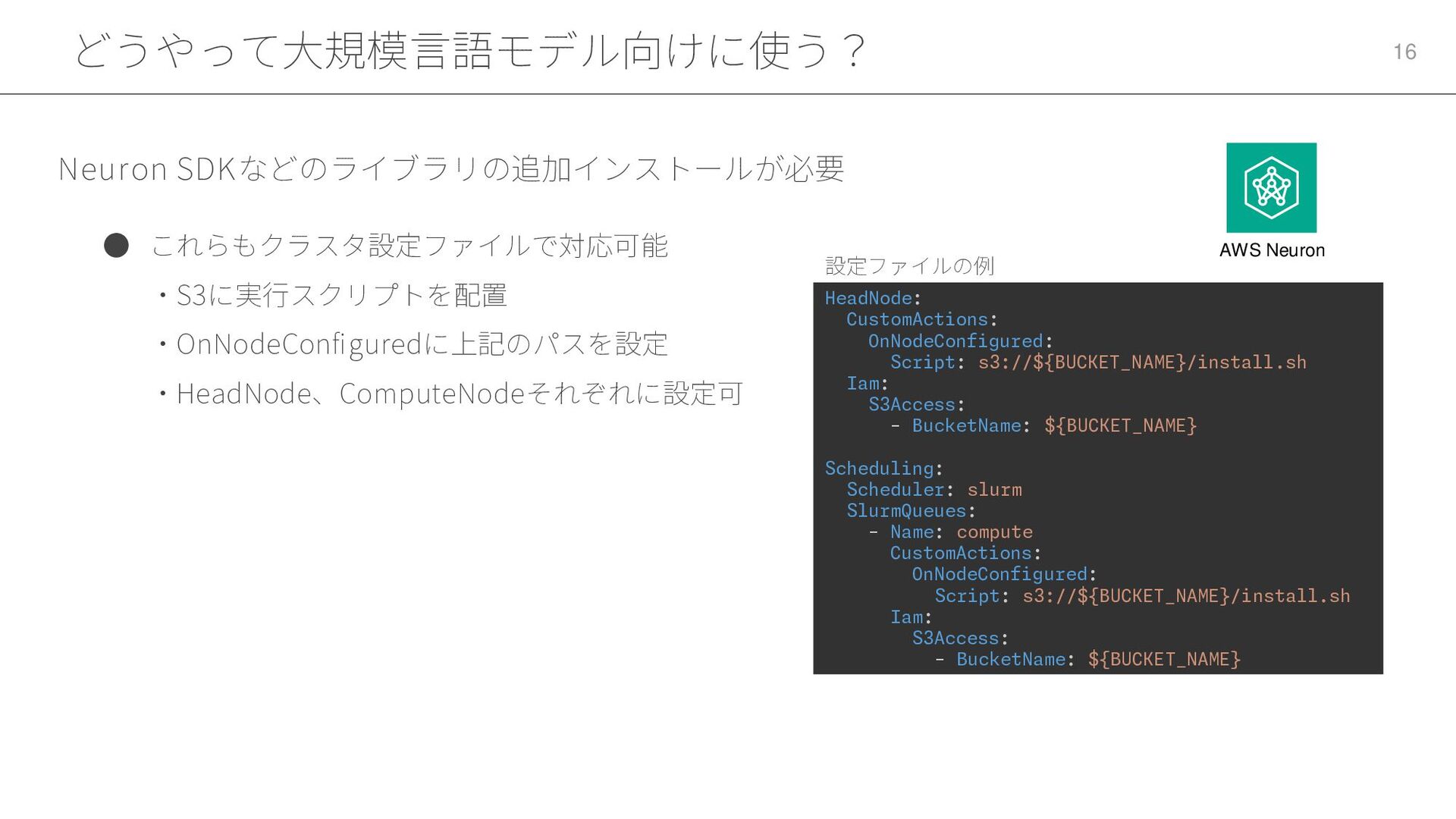
どうやって大規模言語モデル向けに使う? 16 • これらもクラスタ設定ファイルで対応可能 ・S3に実行スクリプトを配置 ・OnNodeConfiguredに上記のパスを設定 ・HeadNode、ComputeNodeそれぞれに設定可 Neuron SDKなどのライブラリの追加インストールが必要 HeadNode:
CustomActions: OnNodeConfigured: Script: s3://${BUCKET_NAME}/install.sh Iam: S3Access: - BucketName: ${BUCKET_NAME} Scheduling: Scheduler: slurm SlurmQueues: - Name: compute CustomActions: OnNodeConfigured: Script: s3://${BUCKET_NAME}/install.sh Iam: S3Access: - BucketName: ${BUCKET_NAME} 設定ファイルの例 AWS Neuron
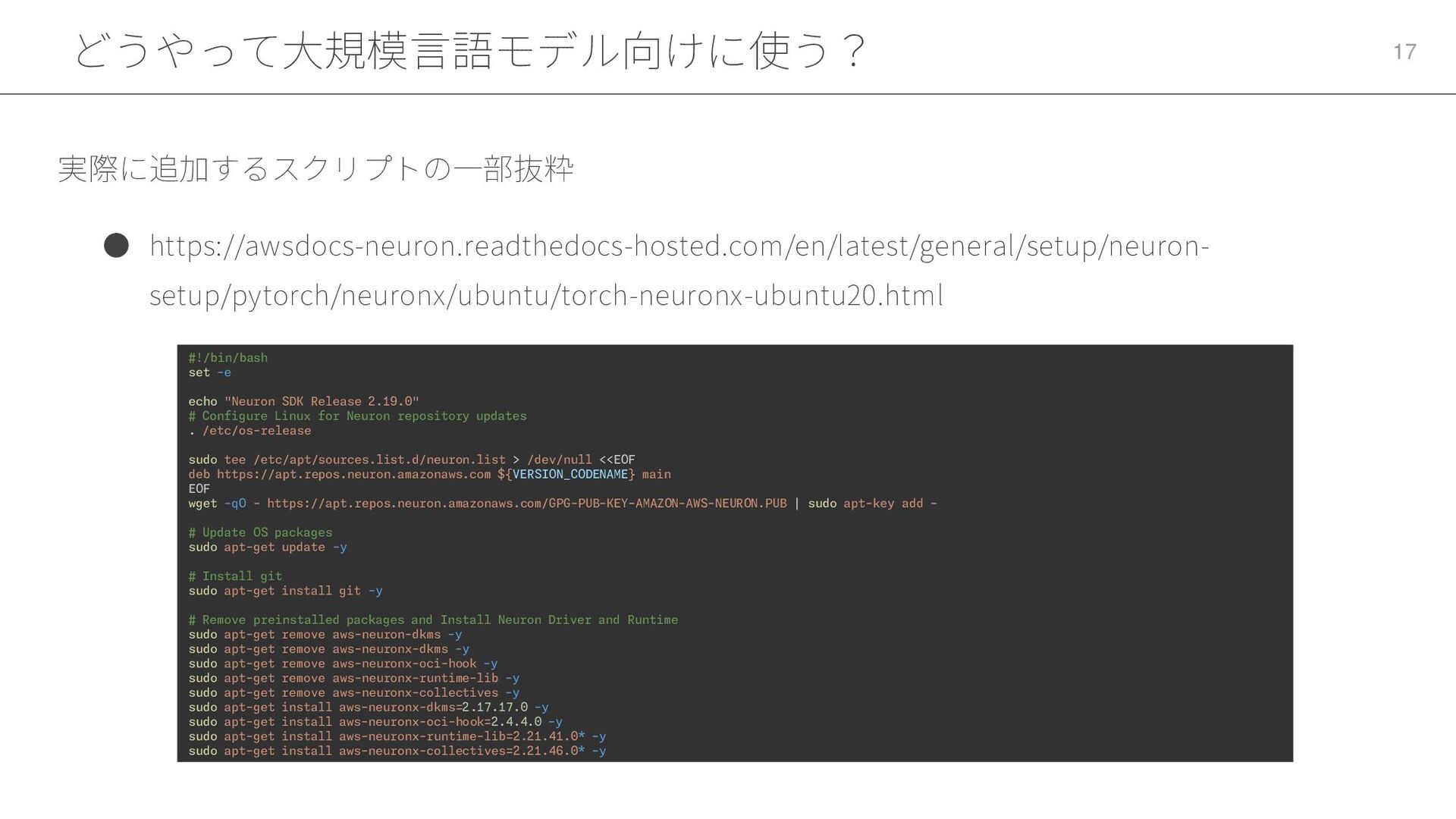
どうやって大規模言語モデル向けに使う? 17 • https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/setup/neuron- setup/pytorch/neuronx/ubuntu/torch-neuronx-ubuntu20.html 実際に追加するスクリプトの一部抜粋 #!/bin/bash set -e echo
"Neuron SDK Release 2.19.0" # Configure Linux for Neuron repository updates . /etc/os-release sudo tee /etc/apt/sources.list.d/neuron.list > /dev/null <<EOF deb https://apt.repos.neuron.amazonaws.com ${VERSION_CODENAME} main EOF wget -qO - https://apt.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB | sudo apt-key add - # Update OS packages sudo apt-get update -y # Install git sudo apt-get install git -y # Remove preinstalled packages and Install Neuron Driver and Runtime sudo apt-get remove aws-neuron-dkms -y sudo apt-get remove aws-neuronx-dkms -y sudo apt-get remove aws-neuronx-oci-hook -y sudo apt-get remove aws-neuronx-runtime-lib -y sudo apt-get remove aws-neuronx-collectives -y sudo apt-get install aws-neuronx-dkms=2.17.17.0 -y sudo apt-get install aws-neuronx-oci-hook=2.4.4.0 -y sudo apt-get install aws-neuronx-runtime-lib=2.21.41.0* -y sudo apt-get install aws-neuronx-collectives=2.21.46.0* -y
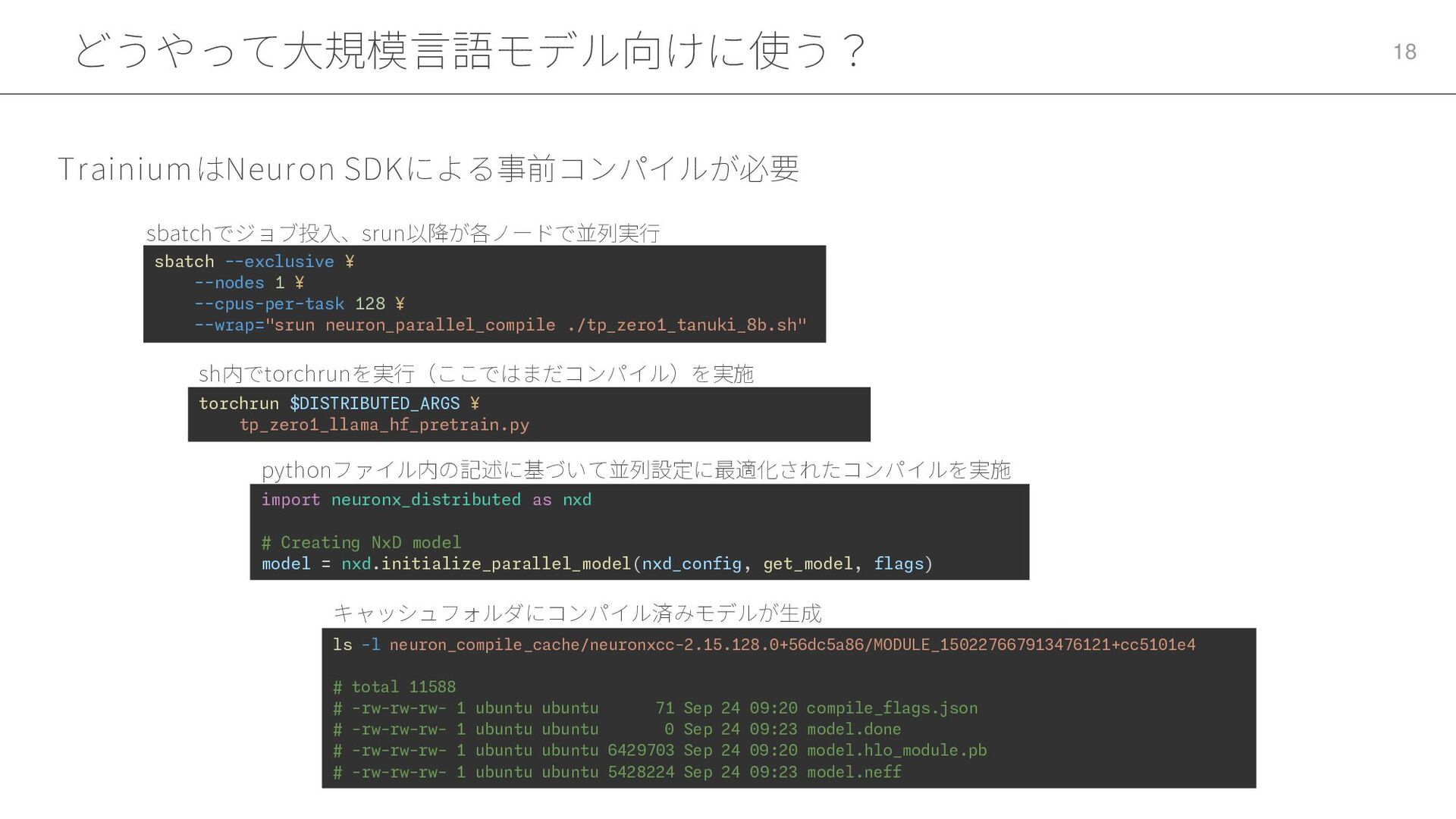
どうやって大規模言語モデル向けに使う? 18 TrainiumはNeuron SDKによる事前コンパイルが必要 sbatch --exclusive ¥ --nodes 1 ¥
--cpus-per-task 128 ¥ --wrap="srun neuron_parallel_compile ./tp_zero1_tanuki_8b.sh" torchrun $DISTRIBUTED_ARGS ¥ tp_zero1_llama_hf_pretrain.py sh内でtorchrunを実行(ここではまだコンパイル)を実施 sbatchでジョブ投入、srun以降が各ノードで並列実行 import neuronx_distributed as nxd # Creating NxD model model = nxd.initialize_parallel_model(nxd_config, get_model, flags) pythonファイル内の記述に基づいて並列設定に最適化されたコンパイルを実施 ls -l neuron_compile_cache/neuronxcc-2.15.128.0+56dc5a86/MODULE_150227667913476121+cc5101e4 # total 11588 # -rw-rw-rw- 1 ubuntu ubuntu 71 Sep 24 09:20 compile_flags.json # -rw-rw-rw- 1 ubuntu ubuntu 0 Sep 24 09:23 model.done # -rw-rw-rw- 1 ubuntu ubuntu 6429703 Sep 24 09:20 model.hlo_module.pb # -rw-rw-rw- 1 ubuntu ubuntu 5428224 Sep 24 09:23 model.neff キャッシュフォルダにコンパイル済みモデルが生成
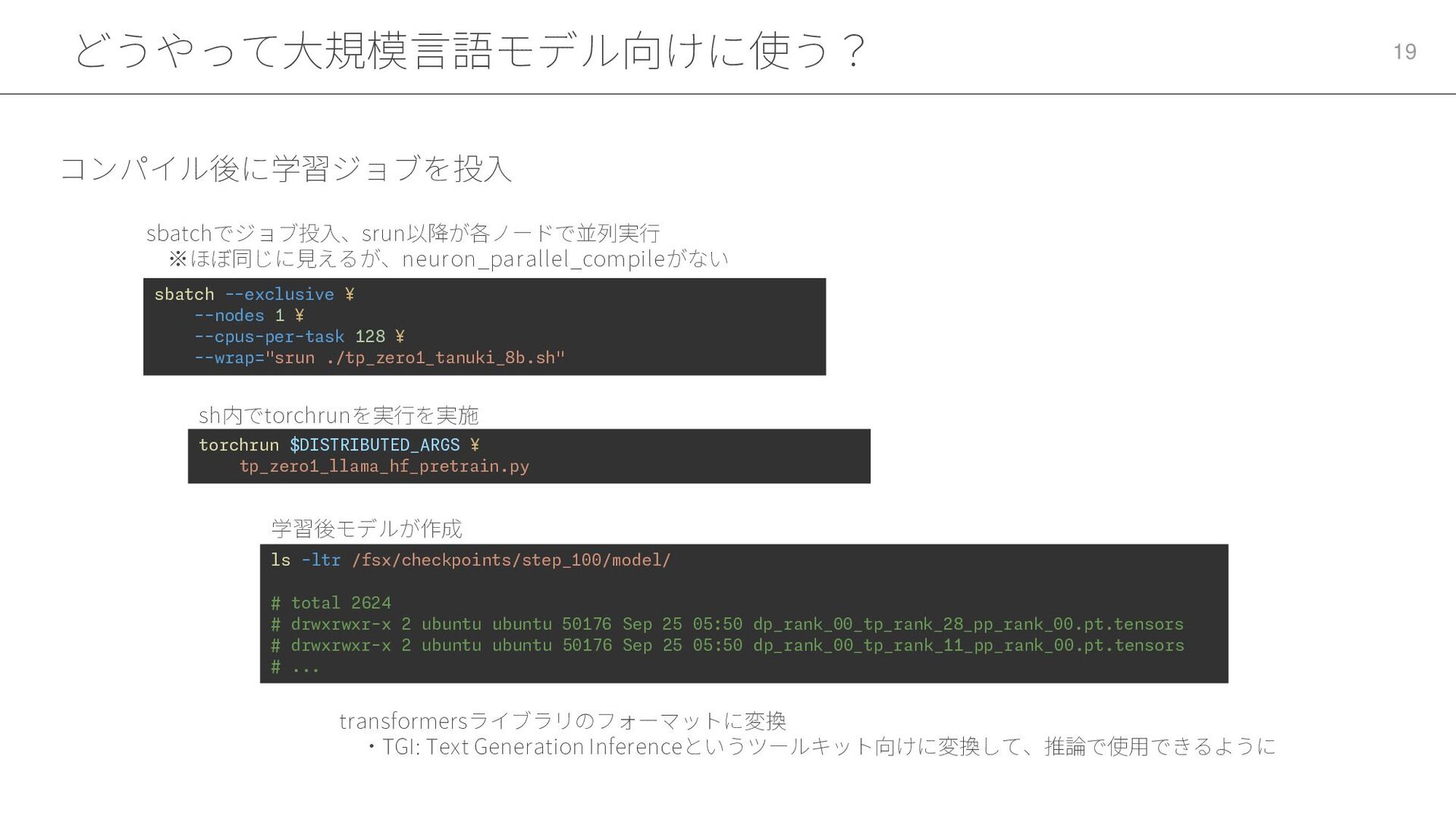
どうやって大規模言語モデル向けに使う? 19 コンパイル後に学習ジョブを投入 sbatch --exclusive ¥ --nodes 1 ¥ --cpus-per-task
128 ¥ --wrap="srun ./tp_zero1_tanuki_8b.sh" torchrun $DISTRIBUTED_ARGS ¥ tp_zero1_llama_hf_pretrain.py sh内でtorchrunを実行を実施 sbatchでジョブ投入、srun以降が各ノードで並列実行 ※ほぼ同じに見えるが、neuron_parallel_compileがない ls -ltr /fsx/checkpoints/step_100/model/ # total 2624 # drwxrwxr-x 2 ubuntu ubuntu 50176 Sep 25 05:50 dp_rank_00_tp_rank_28_pp_rank_00.pt.tensors # drwxrwxr-x 2 ubuntu ubuntu 50176 Sep 25 05:50 dp_rank_00_tp_rank_11_pp_rank_00.pt.tensors # ... 学習後モデルが作成 transformersライブラリのフォーマットに変換 ・TGI: Text Generation Inferenceというツールキット向けに変換して、推論で使用できるように
どうやって大規模言語モデル向けに使う? 20 推論エンドポイントはNeuron対応のTGIコンテナを使ってデプロイ Virtual private cloud (VPC) Internet gateway AWS
Cloud Public subnet Private subnet ALB NATGW Service inf2.xlarge inf2.xlarge ECS Cluster Auto Scaling group neuronx-tgi s3://{モデル置き場} LLM users Request S3 Mount sudo yum install -y https://s3.amazonaws.com/mountpoint-s3-release/latest/x86_64/mount-s3.rpm sudo mkdir /s3 sudo mount-s3 --allow-other ${var.bucket_name} /s3 https://huggingface.co/docs/text-generation-inference/index https://huggingface.co/docs/optimum-neuron/guides/neuronx_tgi
どうやって大規模言語モデル向けに使う? 21 TGIコンテナを使うことによりOpenAI互換APIで実行が可能 import os os.environ["OPENAI_BASE_URL"] = "http://{ロードバランサーのDNS名}/v1" os.environ["OPENAI_API_KEY"] =
"dummy" from openai import OpenAI client = OpenAI() stream = client.chat.completions.create( model="hogehoge", messages=[ {"role": "system", "content": "あなたは親切なアシスタントです。" }, {"role": "user", "content": "今日の献立を考えてください。"} ], max_tokens=1024, temperature=0.3, top_p=0.3, stream=True ) for chunk in stream: print(chunk.choices[0].delta.content or "", end="") 今日の献立は、鶏の照り焼き、ほうれん草のおひたし、味噌汁、白米、フルーツです。 鶏の照り焼きは、鶏もも肉を醤油、みりん、砂糖、酒、生姜で味付けし、フライパンで焼いて、 照り焼きソースを絡めて作ります。 ...
何から始めたら良い?
何から始めたら良い? 23 • 公式:https://www.hpcworkshops.com/ • 弊社ブログ:https://dev.classmethod.jp/articles/parallel-cluster-workshop/ 公式ワークショップでまずはParallelClusterの雰囲気を掴もう
何から始めたら良い? 24 • 弊社ブログ(学習のみ) https://dev.classmethod.jp/articles/parallel-cluster-trainium-neuron-training/ • Karakuri社様ブログ(学習+推論) https://zenn.dev/karakuri_blog/articles/f8d97eee4ee282 Neuron SDKを使った学習・推論も試してみよう
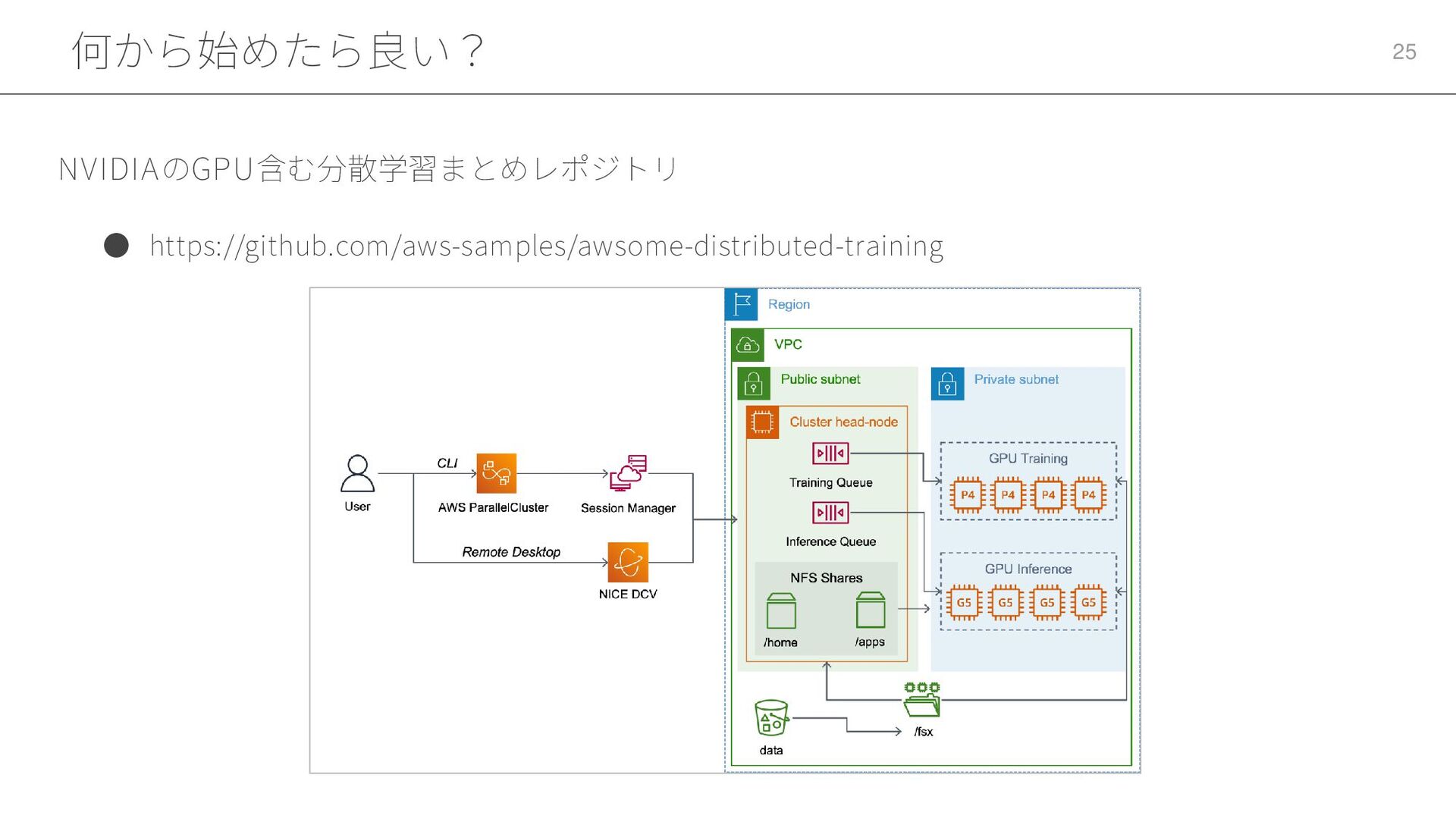
何から始めたら良い? 25 • https://github.com/aws-samples/awsome-distributed-training NVIDIAのGPU含む分散学習まとめレポジトリ
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![どうやって大規模言語モデル向けに使う? 21 TGIコンテナを使うことによりOpenAI互換APIで実行が可能 import os os.environ["OPENAI_BASE_URL"] = "http://{ロードバランサーのDNS名}/v1" os.environ["OPENAI_API_KEY"] =](https://files.speakerdeck.com/presentations/9e7edd322ea64a8281c4b78400f4c582/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}