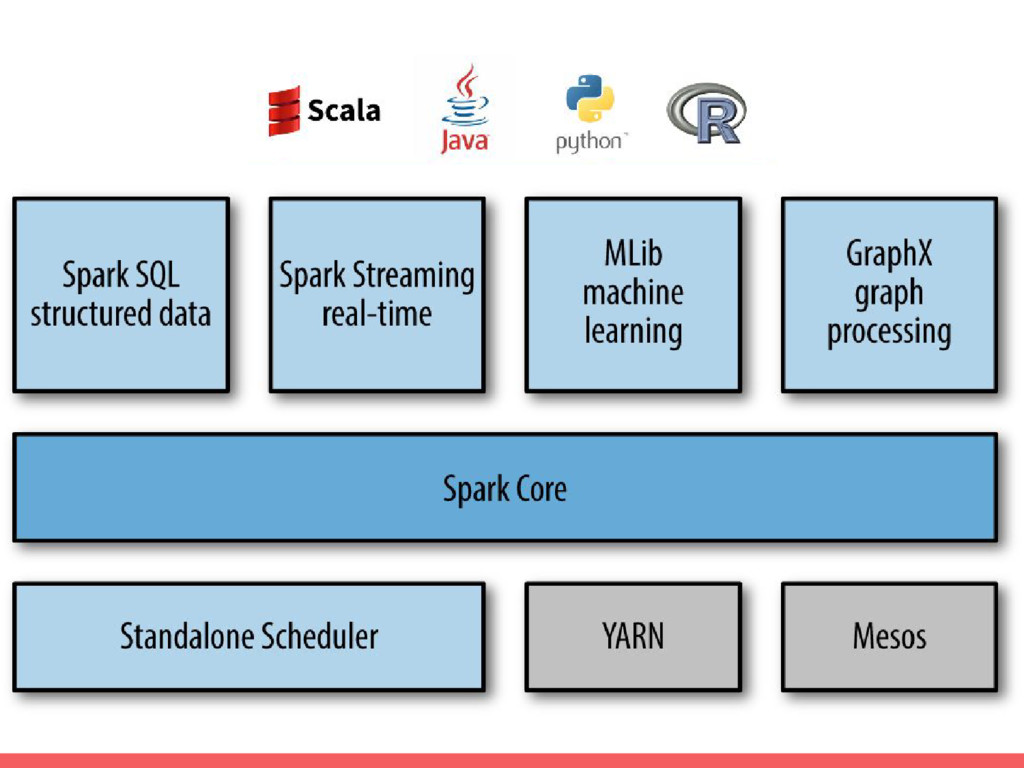
Apache Spark est un framework open source généraliste, conçu pour le traitement distribué de données. C’est une extension du modèle MapReduce avec l’avantage de pouvoir traiter les données en mémoire et de manière interactive. Spark offre un ensemble de composants pour l’analyse de données: Spark SQL, Spark Streaming, MLlib (machine learning) et GraphX (graphes).
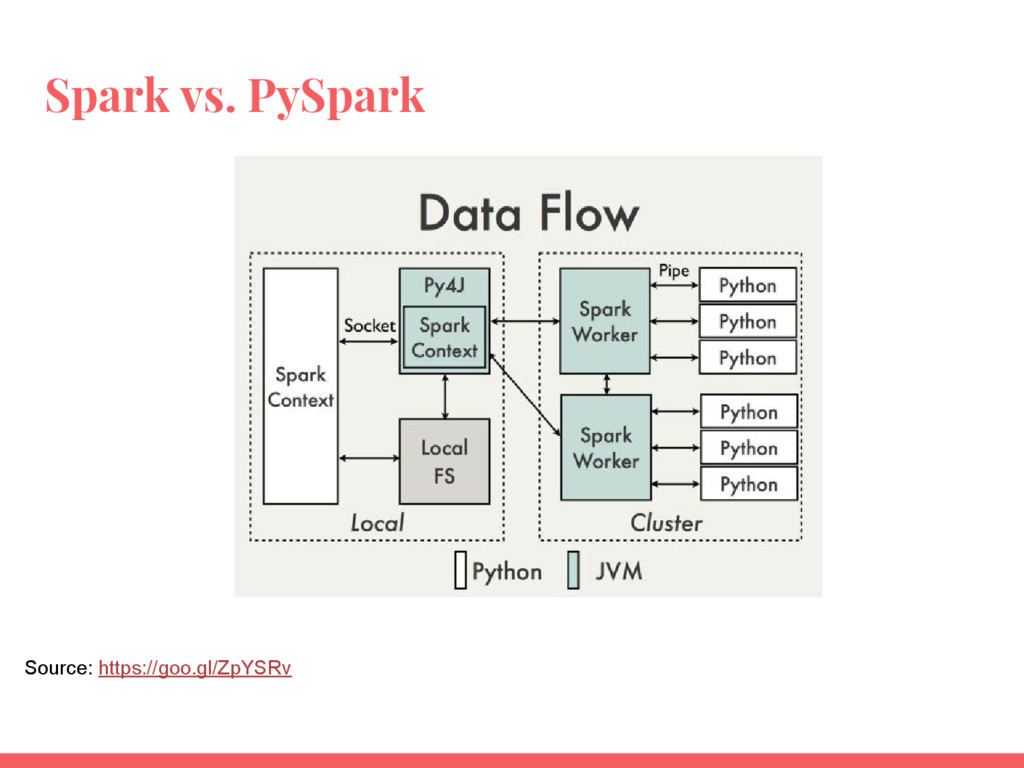
Cet atelier se concentre sur les fondamentaux de Spark et le paradigme de traitement de données avec l’interface de programmation Python (plus précisément PySpark).
L’installation, configuration, traitement sur cluster, Spark Streaming, MLlib et GraphX ne seront pas abordés dans cet atelier.
Objectifs
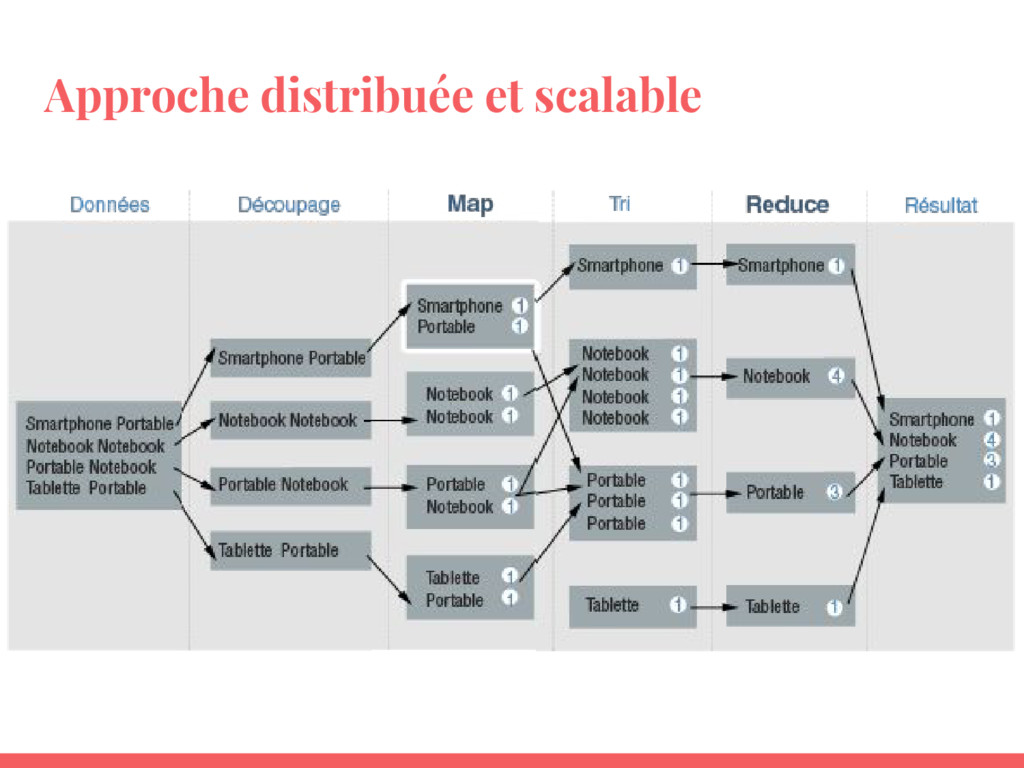
Comprendre les fondamentaux de Spark et le situer dans l'écosystème Big Data ;
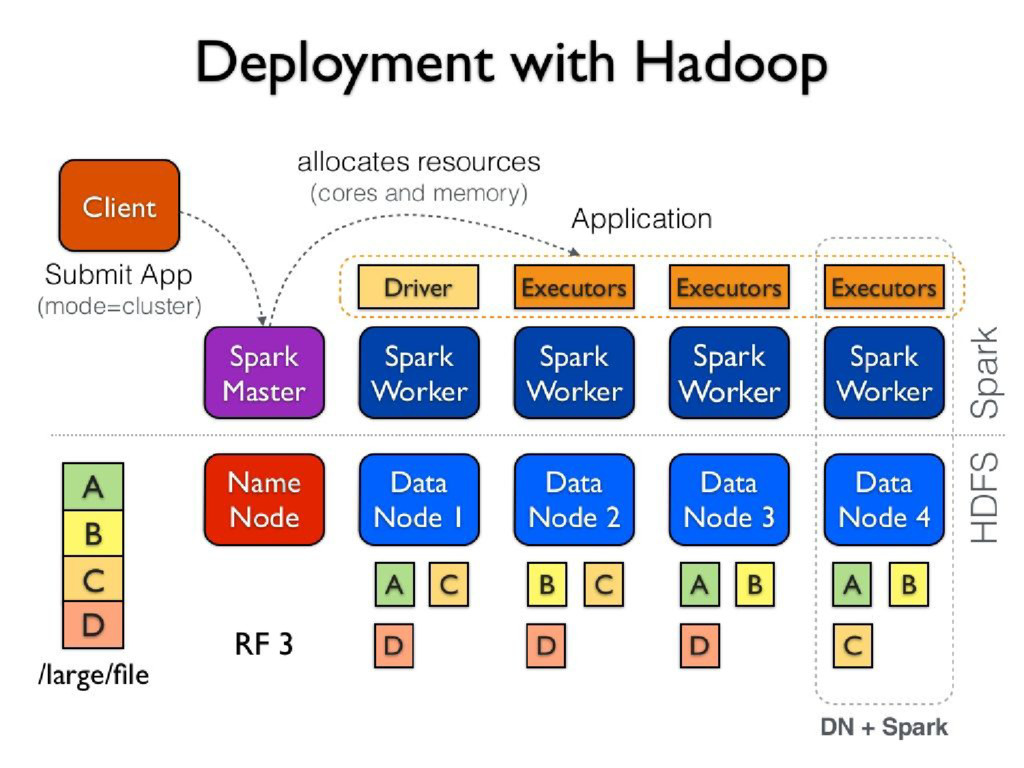
Savoir la différence avec Hadoop MapReduce ;
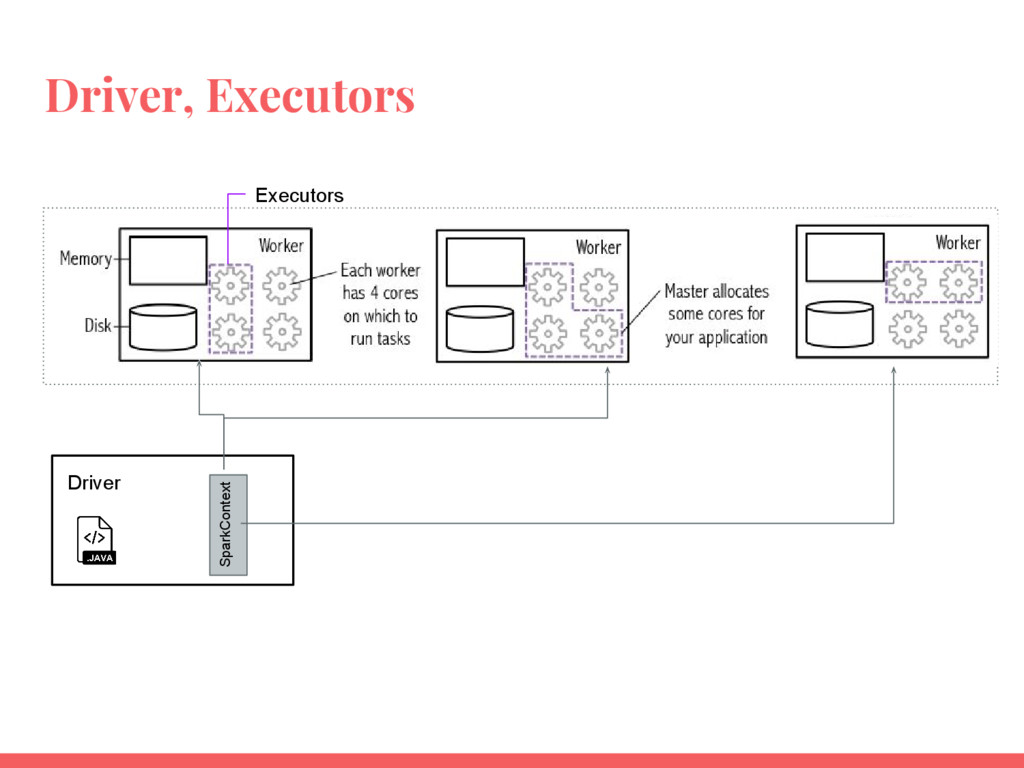
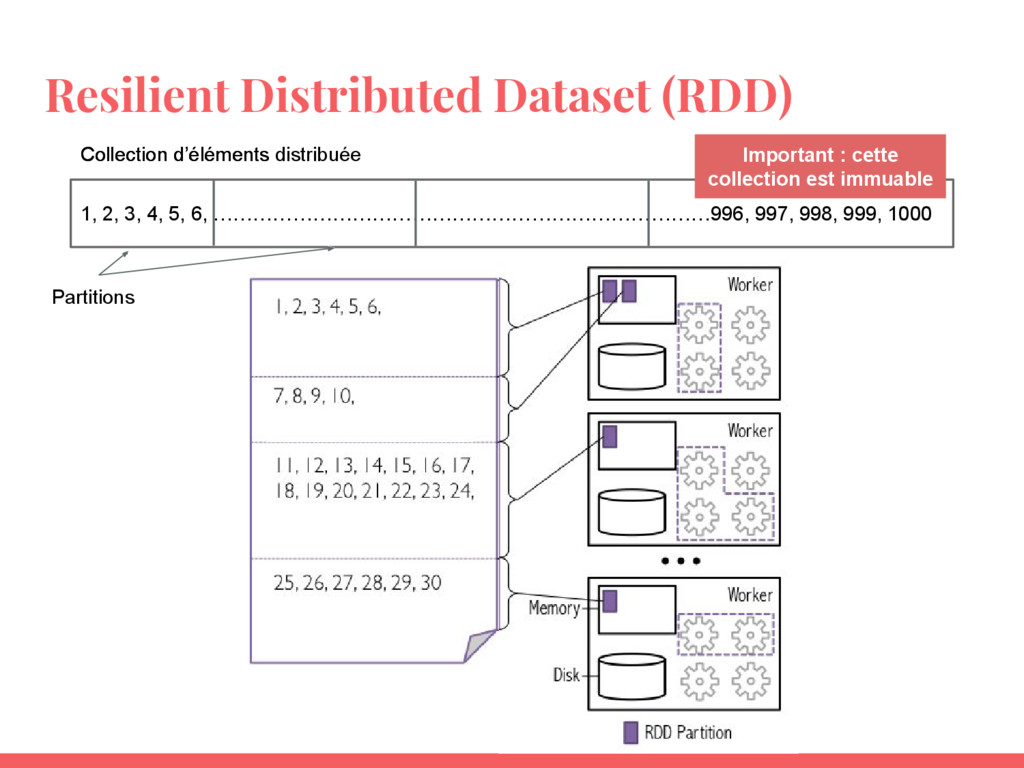
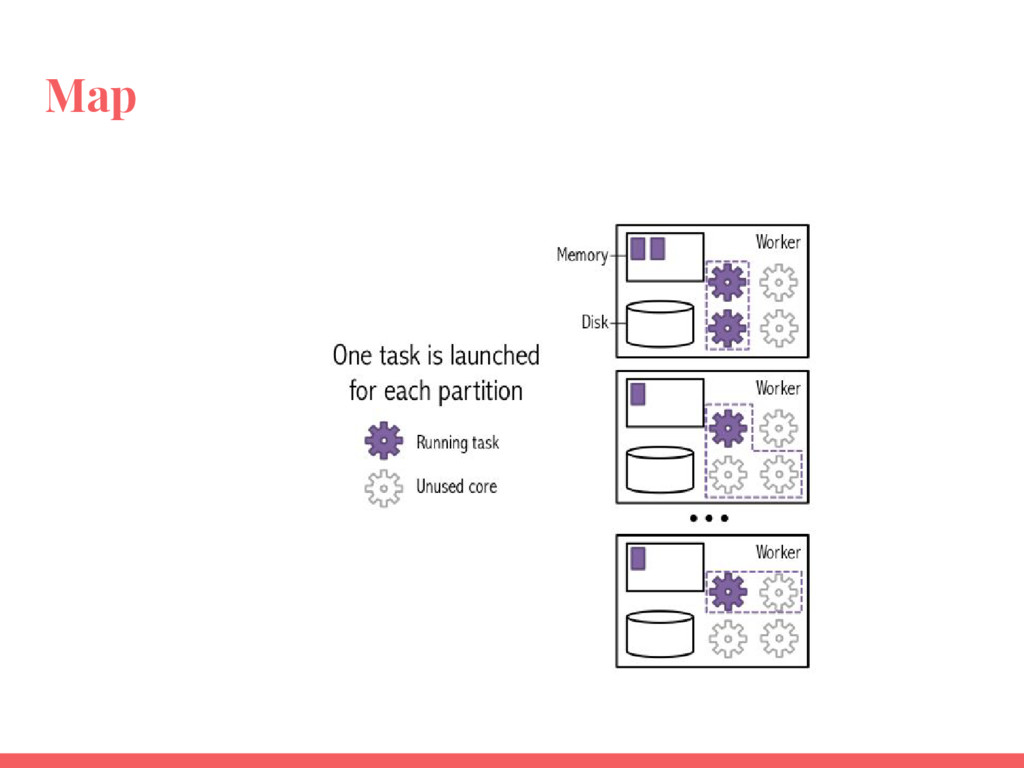
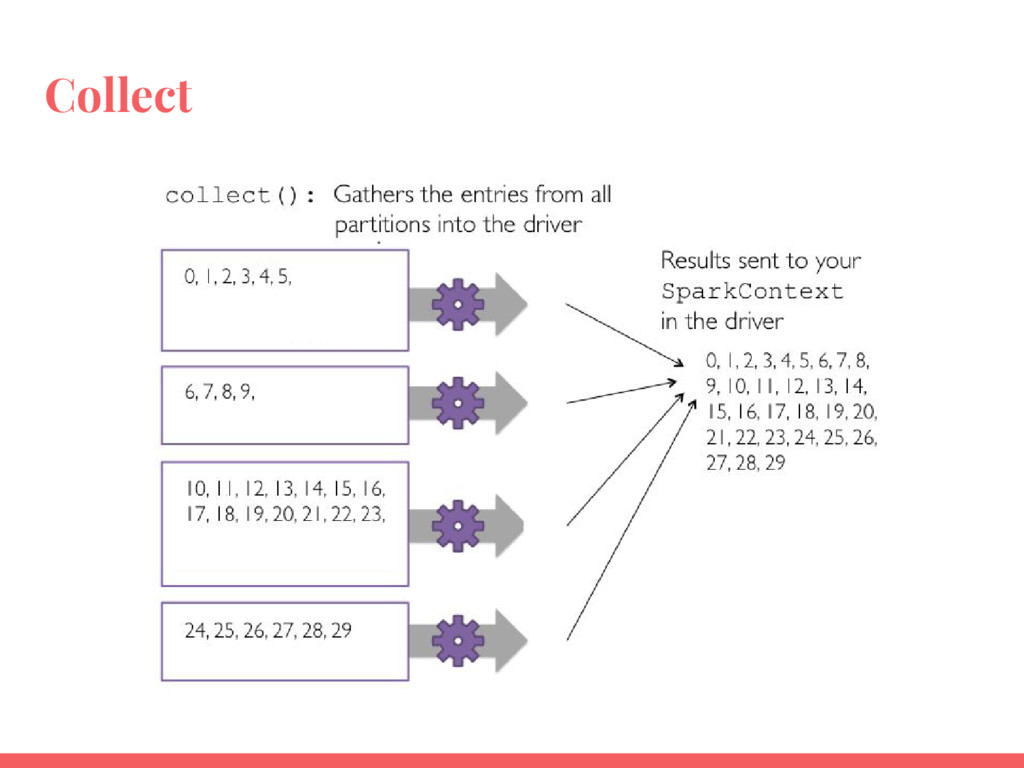
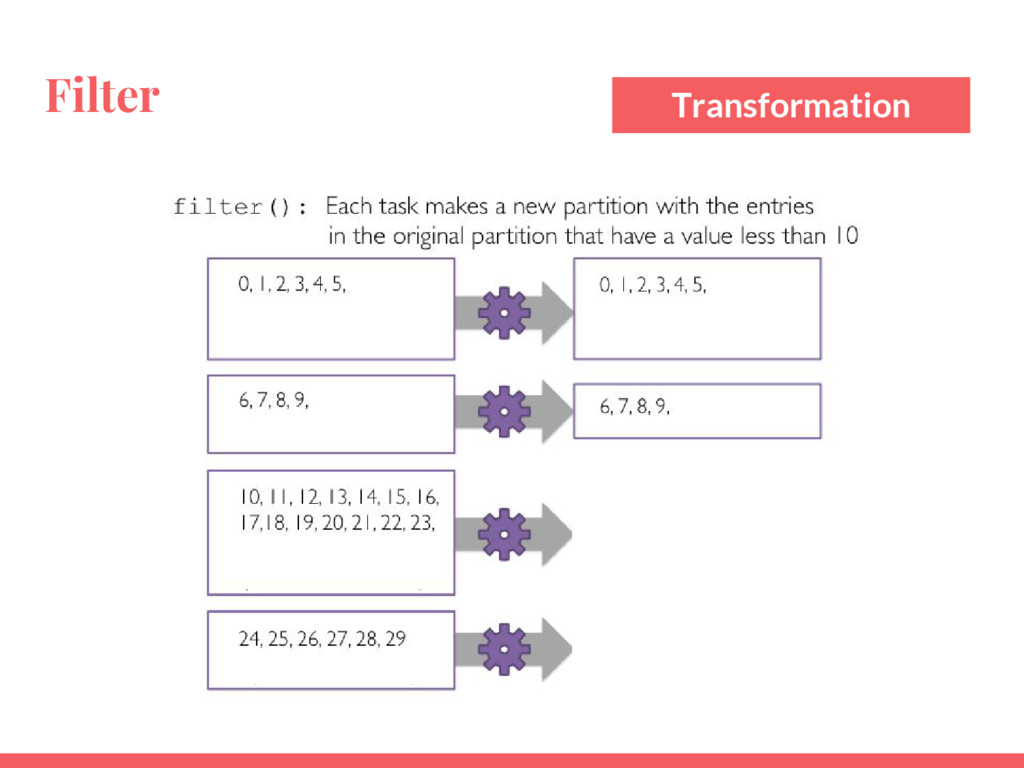
Utiliser les RDD (Resilient Distributed Datasets) ;
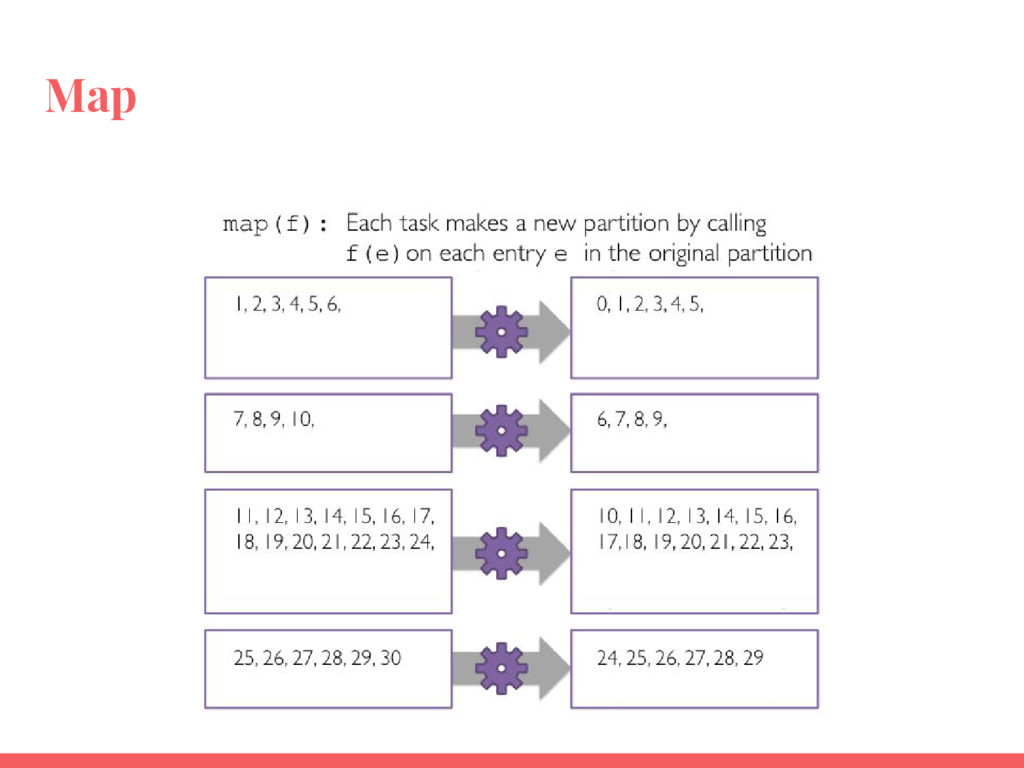
Utiliser les actions et transformations les plus courantes pour manipuler et analyser des données ;
Ecrire un pipeline de transformation de données ;
Utiliser l’API de programmation PySpark.
Cet atelier est le premier d’une série de 2 ateliers avec Apache Spark. Pour suivre les prochains ateliers, vous devez avoir suivi les précédents ou être à l’aise avec les sujets déjà traités.
Quels sont les pré-requis ?
Connaître les base du langage Python (ou apprendre rapidement via ce cours en ligne Python Introduction)
Être sensibilisé au traitement de la donnée avec R, Python ou Bash (why not?)
Aucune connaissance préalable en traitement distribué et Apache Spark n’est demandée. C’est un atelier d’introduction. Les personnes ayant déjà une première expérience avec Spark (en Scala, Java ou R) risquent de s'ennuyer (c’est un atelier pour débuter).
Comment me préparer pour cet atelier ?
Vous devez être muni d’un ordinateur portable relativement moderne et avec minimum 4 Go de mémoire, avec un navigateur internet installé. Vous devez pouvoir vous connecter à Internet via le Wifi.
Suivre les instructions pour vous préparer à l’atelier (installation Docker + image docker de l’atelier).
https://docs.google.com/document/d/1ku757Irz-bv9g1IiUeBUoDaRhSpQXc-RFfTruvjmW3o/edit
Les données à nettoyer sont comprises dans l’image Docker. Les exercices seront fournis lors de l’atelier en format Jupyter notebook.
Lien vers le meetup : https://www.meetup.com/Paris-Machine-learning-applications-group/events/237212885/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}