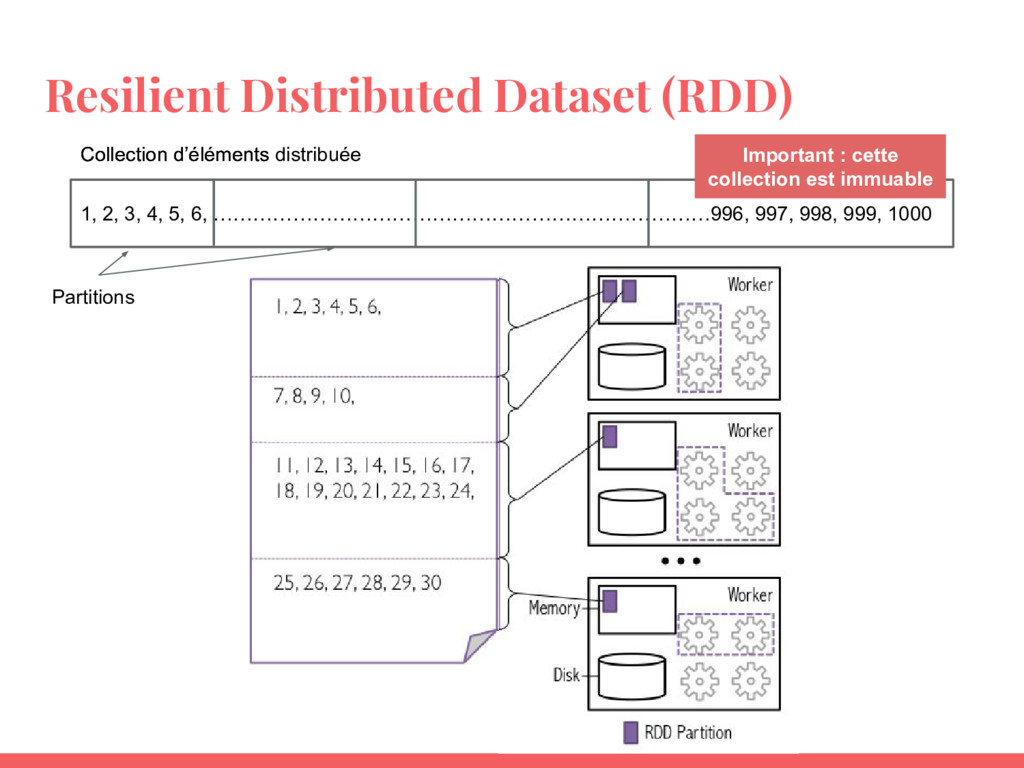
Dans l’atelier précédent, nous avons vu comment Spark fait partie intégrante dans le kit de "ménage" du data scientist moderne. Les bases de Spark et son API (PySpark) ont été abordées. Nous avons vu que le concept de RDDs est assez flexible et puissant pour travailler la donnée de tout type à l’aide d’une multitude de transformations et d’actions proposées.
Nous savons bien que pour commencer à faire une analyse exploratoire et utiliser les méthodes de machine learning il faut d’abord structurer correctement ses données. C’est ce que nous aborderons dans cette deuxième partie de l’atelier.
Le programme :
• Charger et enregistrer des données volumineuses au format CSV sans souffrance
• Utiliser l’API DataFrame pour faire une analyse exploratoire simple
• Analyser la donnée via SQL avec SparkSQL (et oui, le bon et vieux SQL a toujours la côte)
• Utiliser les tableaux croisés dynamique
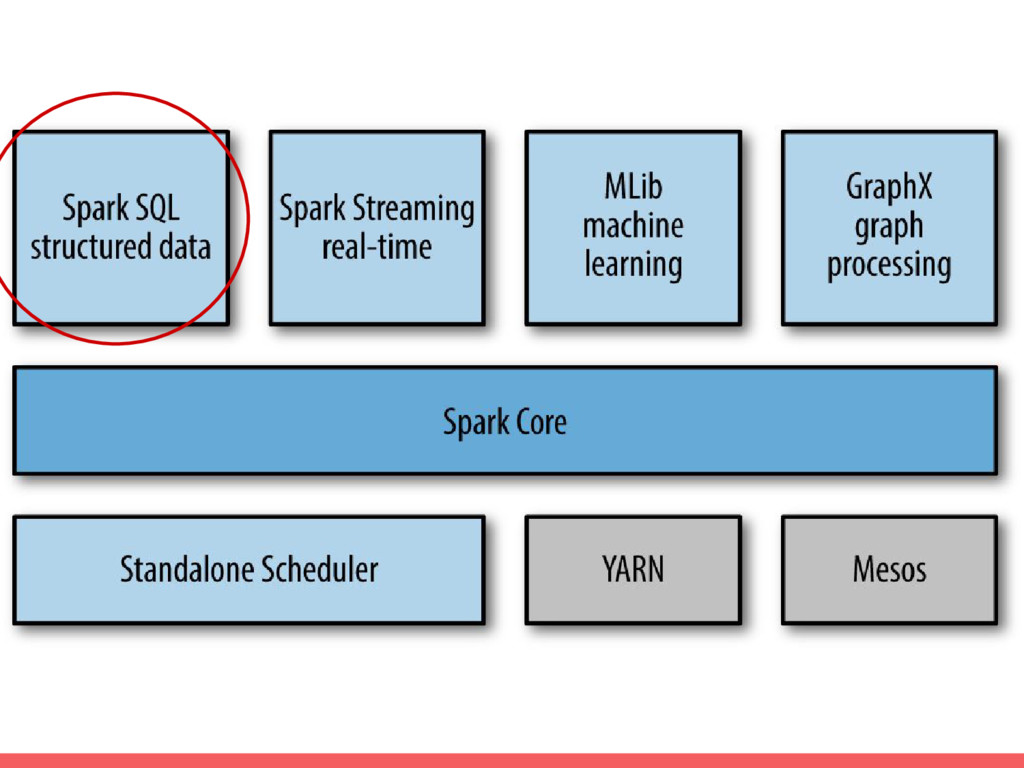
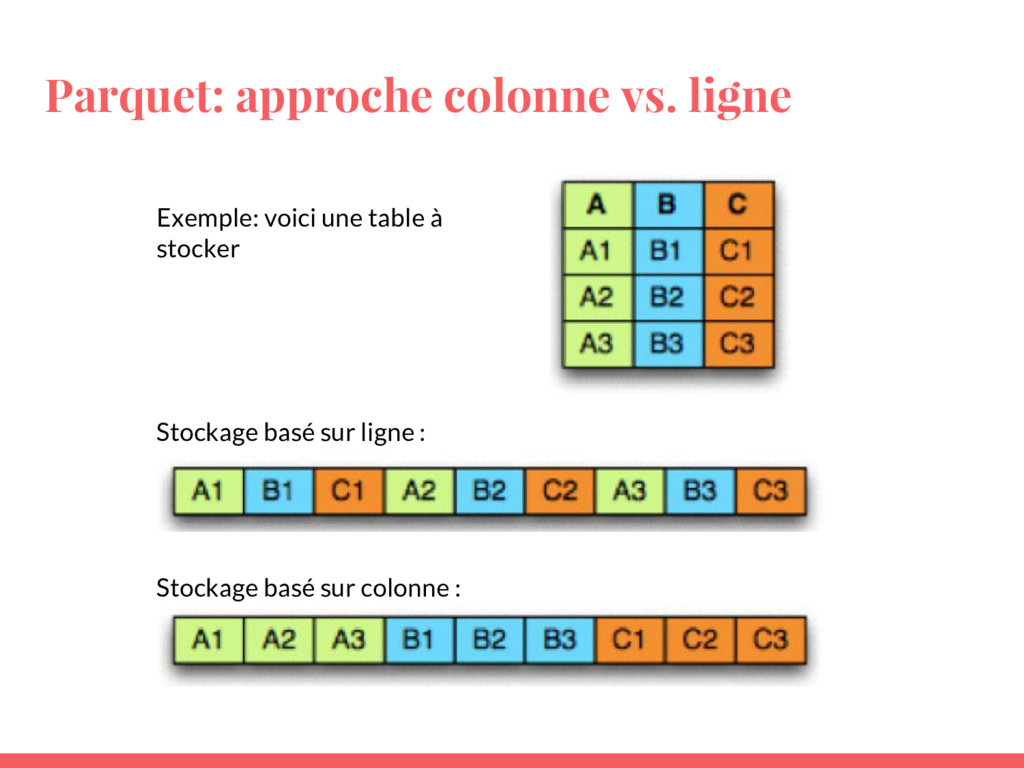
• Utiliser Parquet, un format de stockage performant et structuré de plus en plus utilisé en entreprise
Cette atelier sera animé par Leonardo Noleto, data scientist.
Les TPs en format Jupyter Notebook peuvent être téléchargés ici: https://goo.gl/1C7UOq
Pour installer l'image Docker nécessaire, suivre ce guide : https://docs.google.com/document/d/1ku757Irz-bv9g1IiUeBUoDaRhSpQXc-RFfTruvjmW3o/edit
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}