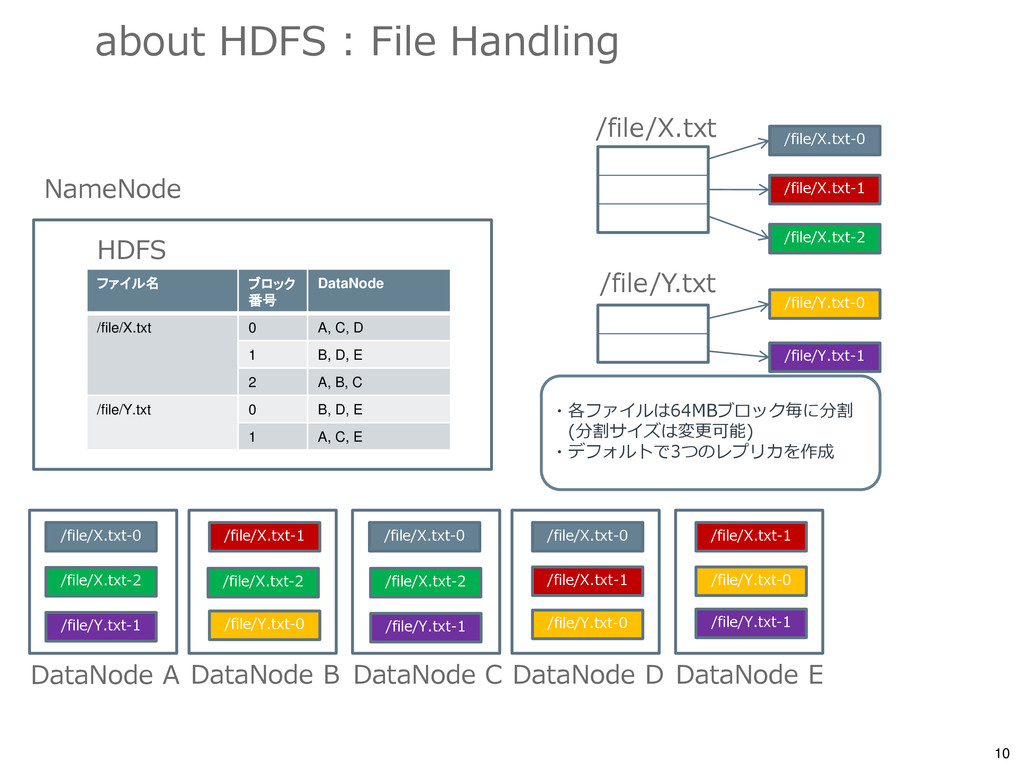
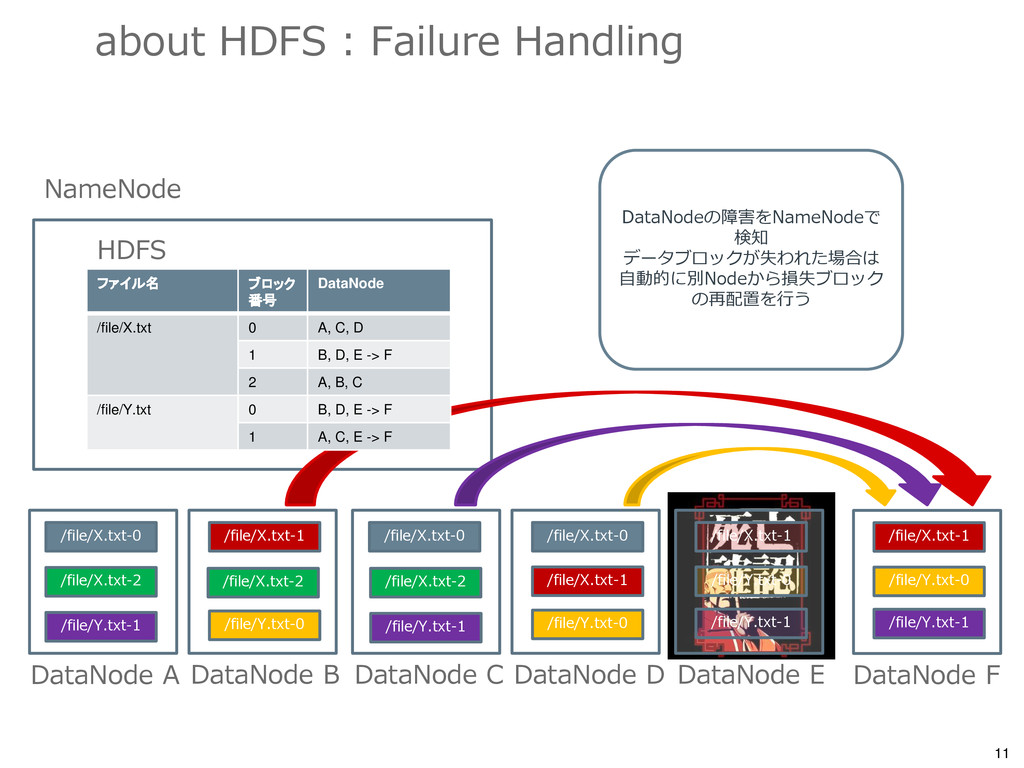
/file/X.txt 0 A, C, D 1 B, D, E 2 A, B, C /file/Y.txt 0 B, D, E 1 A, C, E DataNode A DataNode B DataNode C DataNode D DataNode E /file/X.txt-0 /file/X.txt-0 /file/X.txt-0 /file/X.txt-1 /file/X.txt-1 /file/X.txt-1 /file/X.txt-2 /file/X.txt-2 /file/X.txt-2 /file/Y.txt-0 /file/Y.txt-0 /file/Y.txt-0 /file/Y.txt-1 /file/Y.txt-1 /file/Y.txt-1 NameNode HDFS /file/X.txt-0 /file/X.txt-1 /file/X.txt-2 /file/Y.txt-0 /file/Y.txt-1 /file/X.txt /file/Y.txt ・各ファイルは64MBブロック毎に分割 (分割サイズは変更可能) ・デフォルトで3つのレプリカを作成
DataNode C DataNode D DataNode E /file/X.txt-0 /file/X.txt-0 /file/X.txt-0 /file/X.txt-1 /file/X.txt-1 /file/X.txt-1 /file/X.txt-2 /file/X.txt-2 /file/X.txt-2 /file/Y.txt-0 /file/Y.txt-0 /file/Y.txt-0 /file/Y.txt-1 /file/Y.txt-1 /file/Y.txt-1 NameNode HDFS DataNode F /file/X.txt-1 /file/Y.txt-0 /file/Y.txt-1 ファイル名 ブロック 番号 DataNode /file/X.txt 0 A, C, D 1 B, D, E -> F 2 A, B, C /file/Y.txt 0 B, D, E -> F 1 A, C, E -> F DataNodeの障害をNameNodeで 検知 データブロックが失われた場合は 自動的に別Nodeから損失ブロック の再配置を行う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
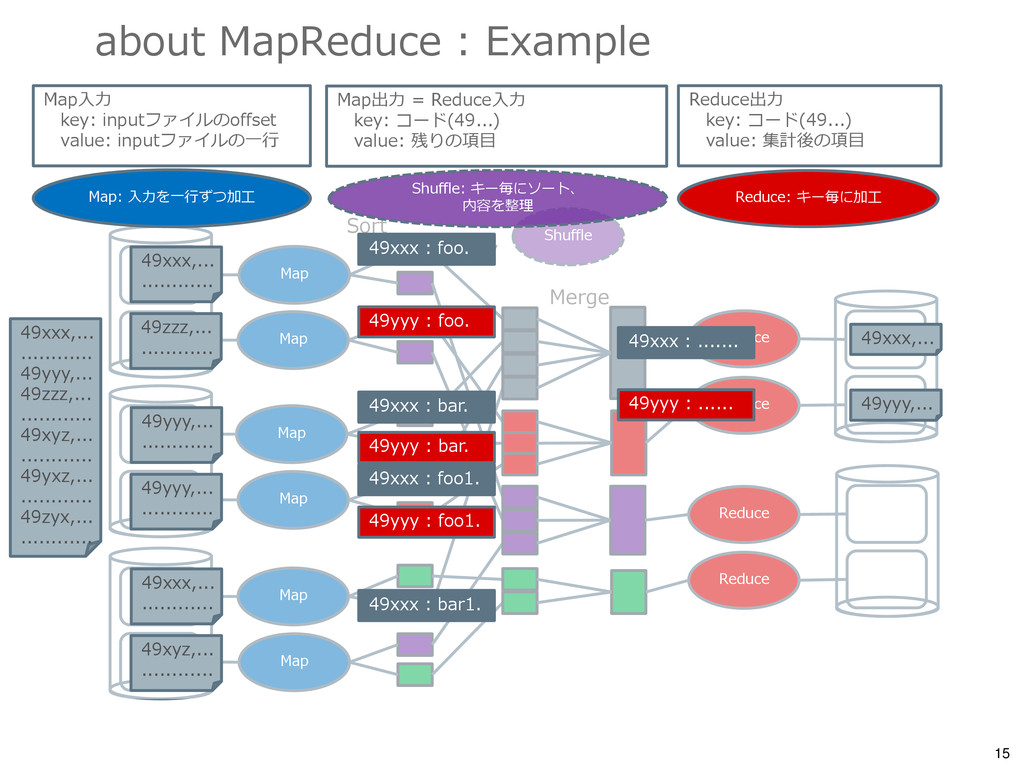{kind=link}
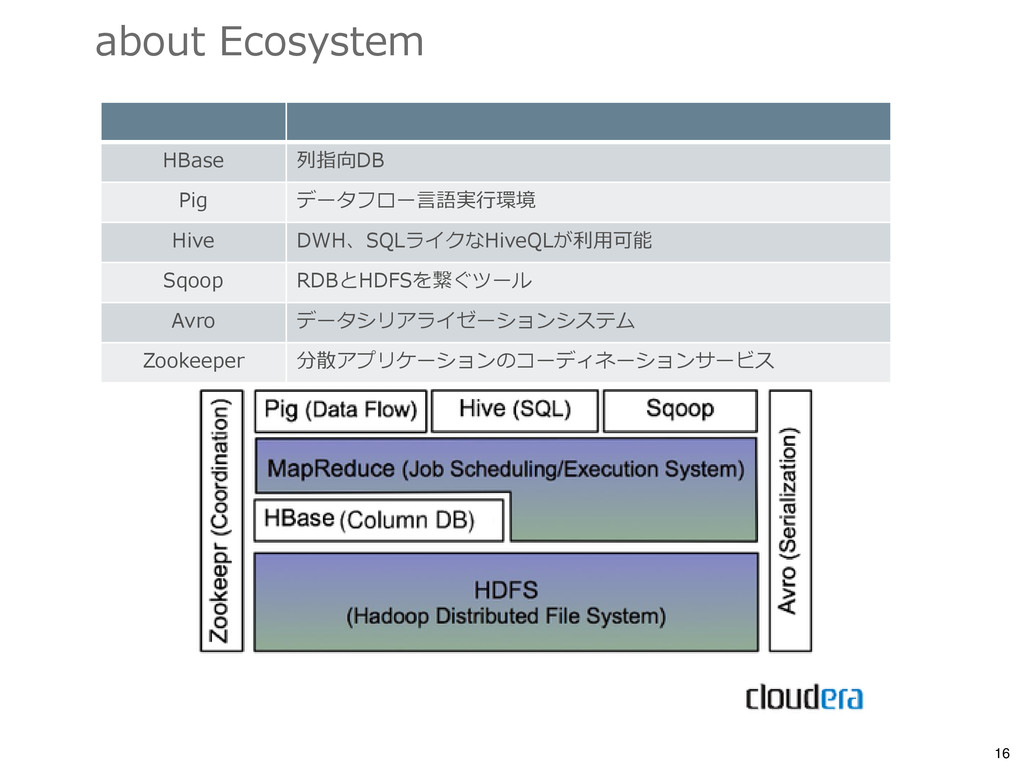{kind=link}
{kind=link}
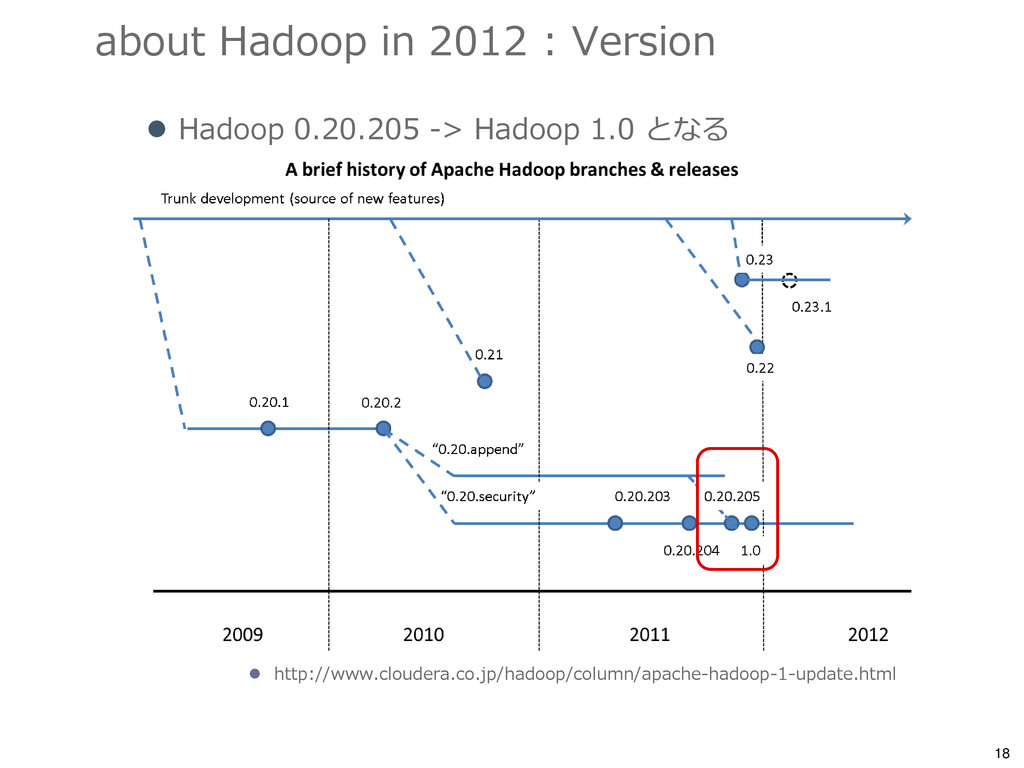{kind=link}
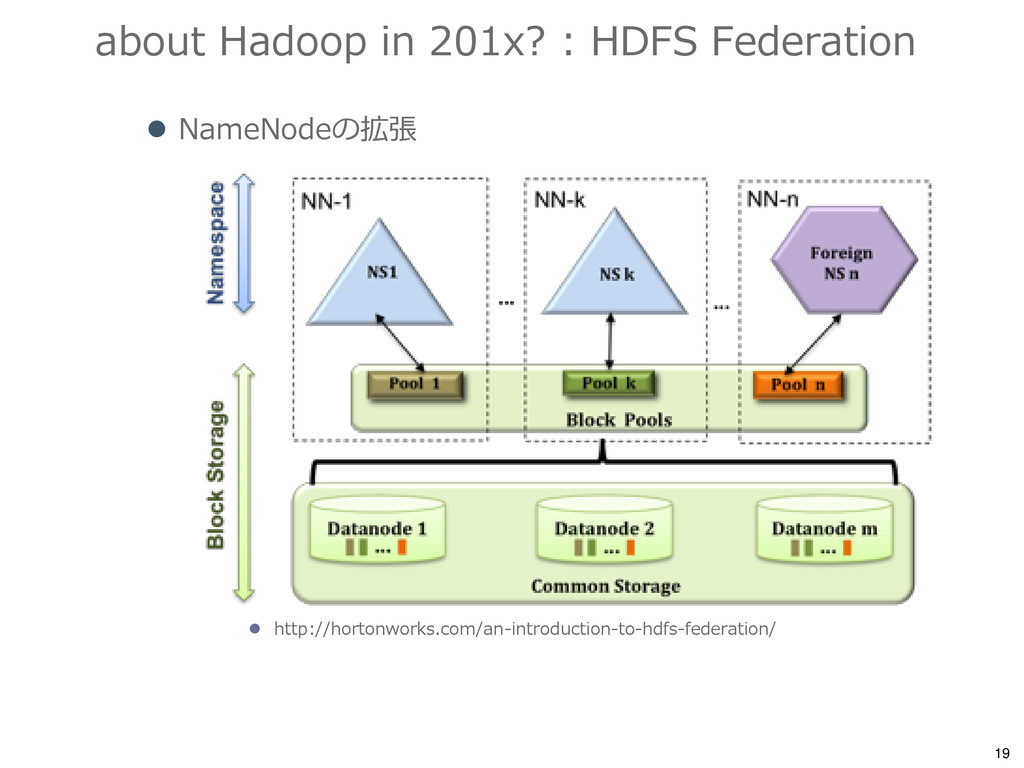{kind=link}
{kind=link}
{kind=link}
{kind=link}