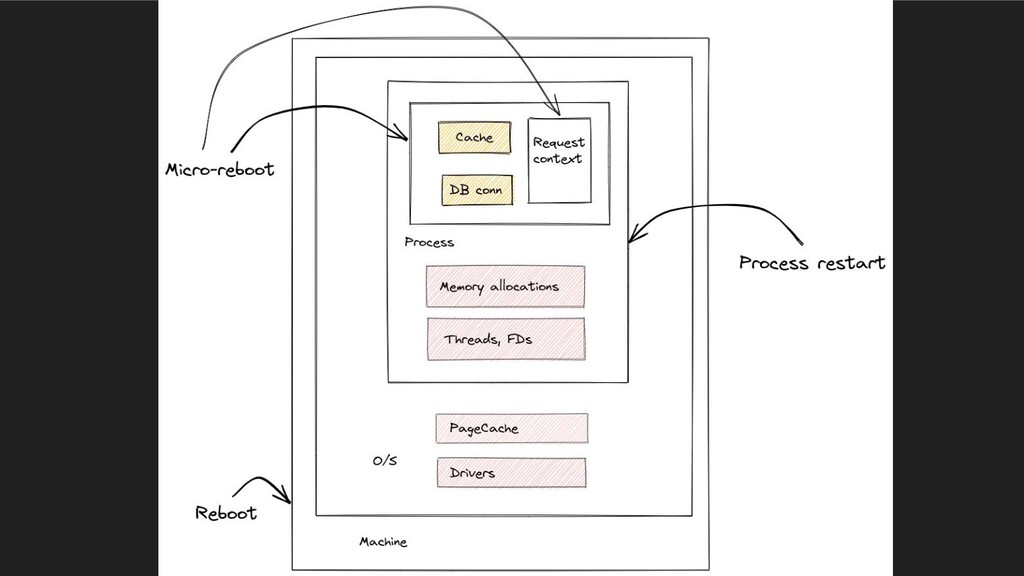
"Have you tried turning it off and on again?" is one of the most common jokes in our industry. However, behind the comical aspect lies a fundamental architectural pattern - state encapsulation and recovery by clearing state data. This pattern is mostly used implicitly, but when used as a design principle unlocks a new paradigm of programming: Recovery Oriented Computing (ROC).
This talks indroduces ROC and fundamental techniques for this paradigm, which can also be applied individually to great effect: seperation of state, crash-only software, micro-reboots, single recovery path, redo logs and checkpoints, pre-emptive
reboots, and more.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}