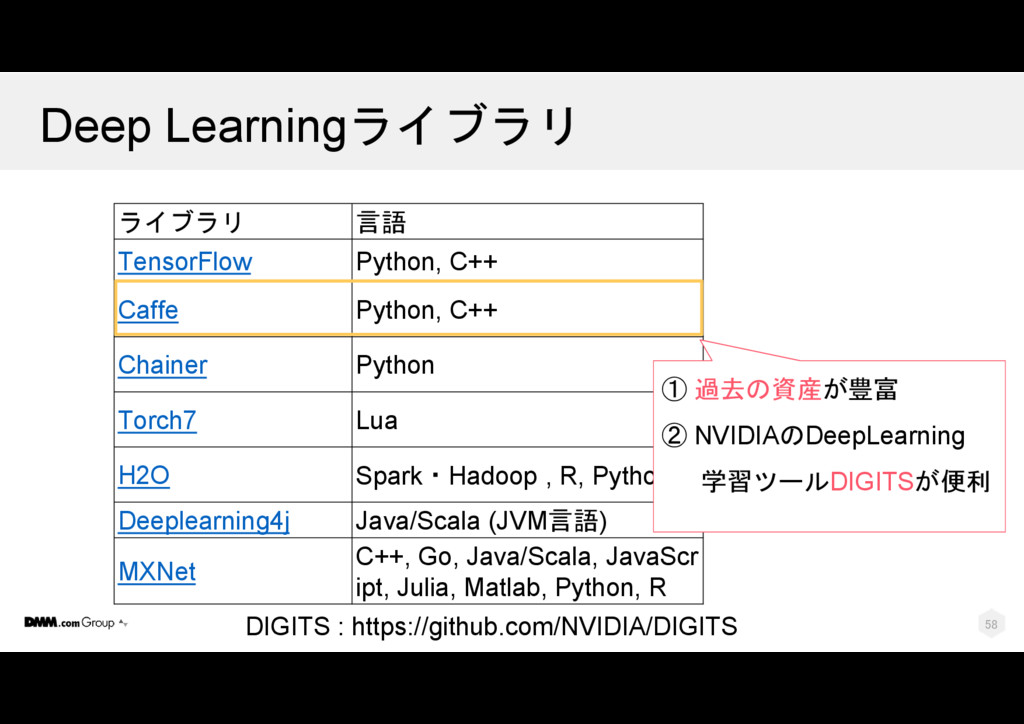
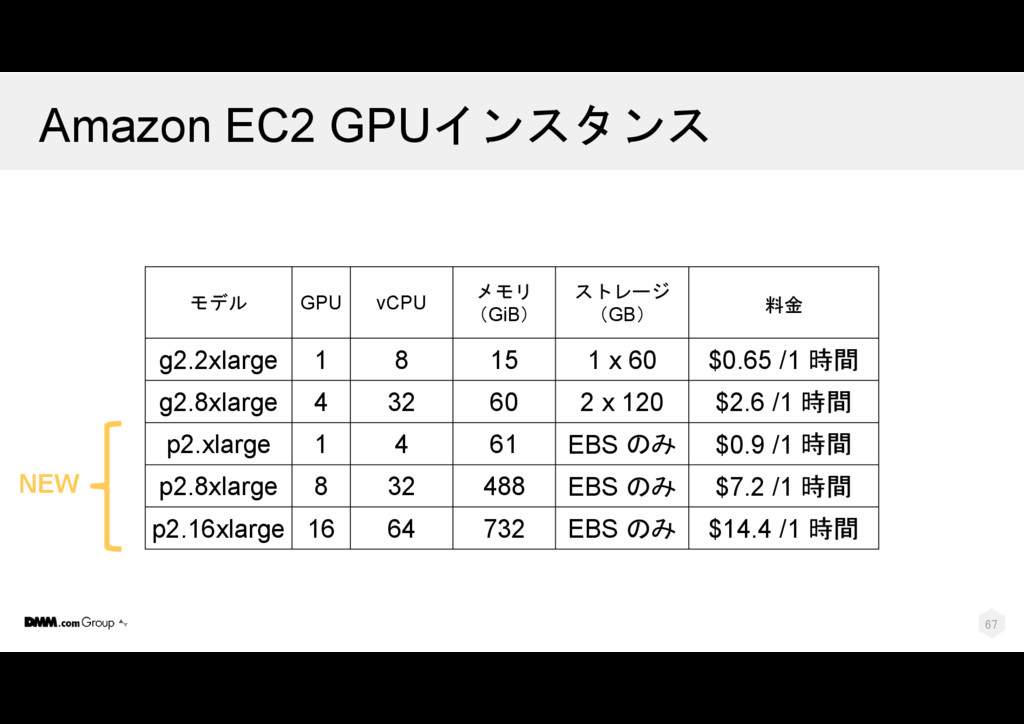
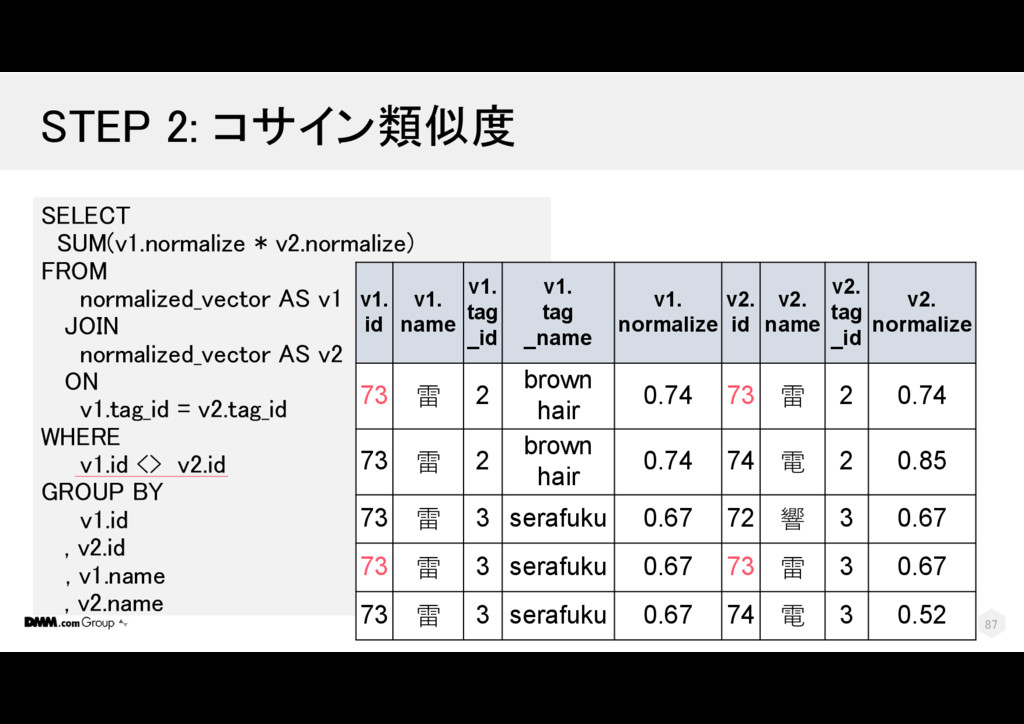
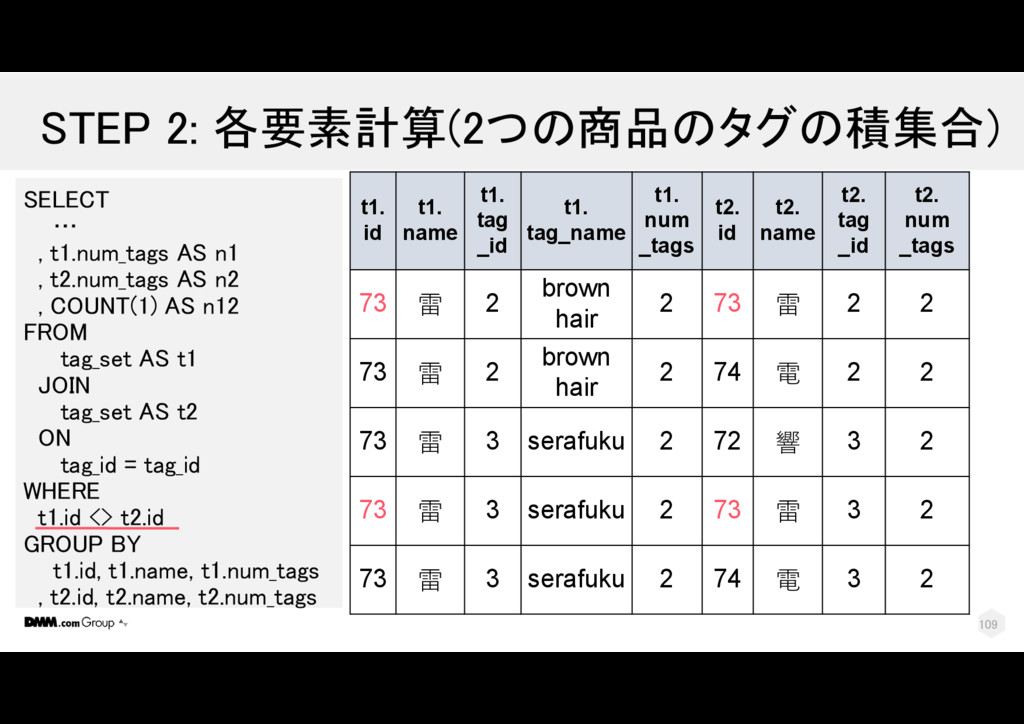
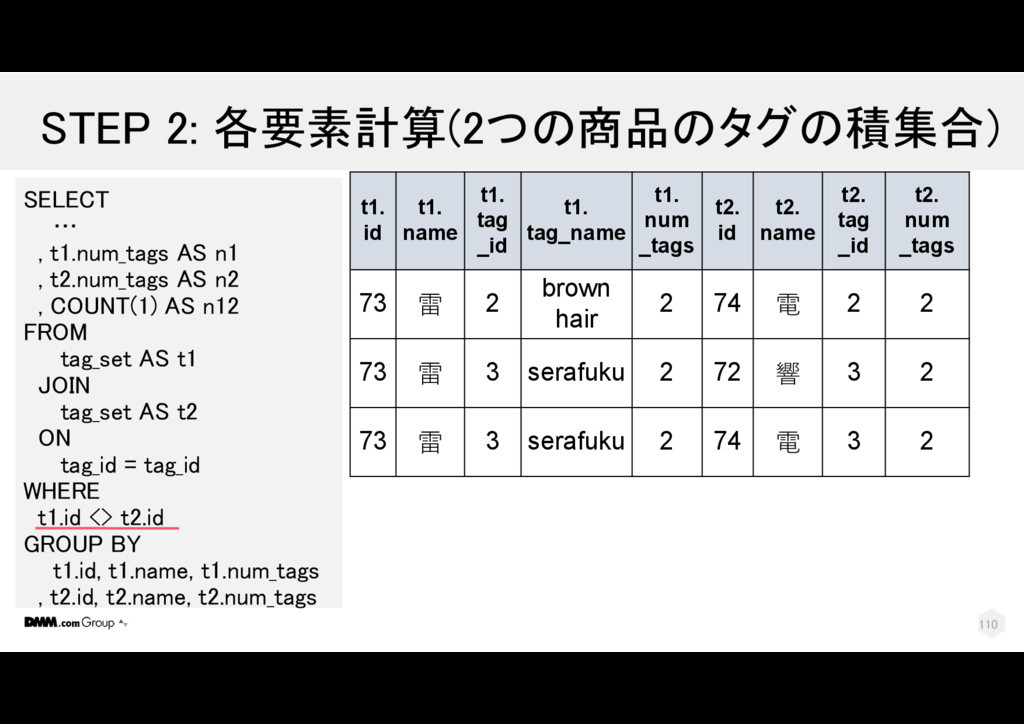
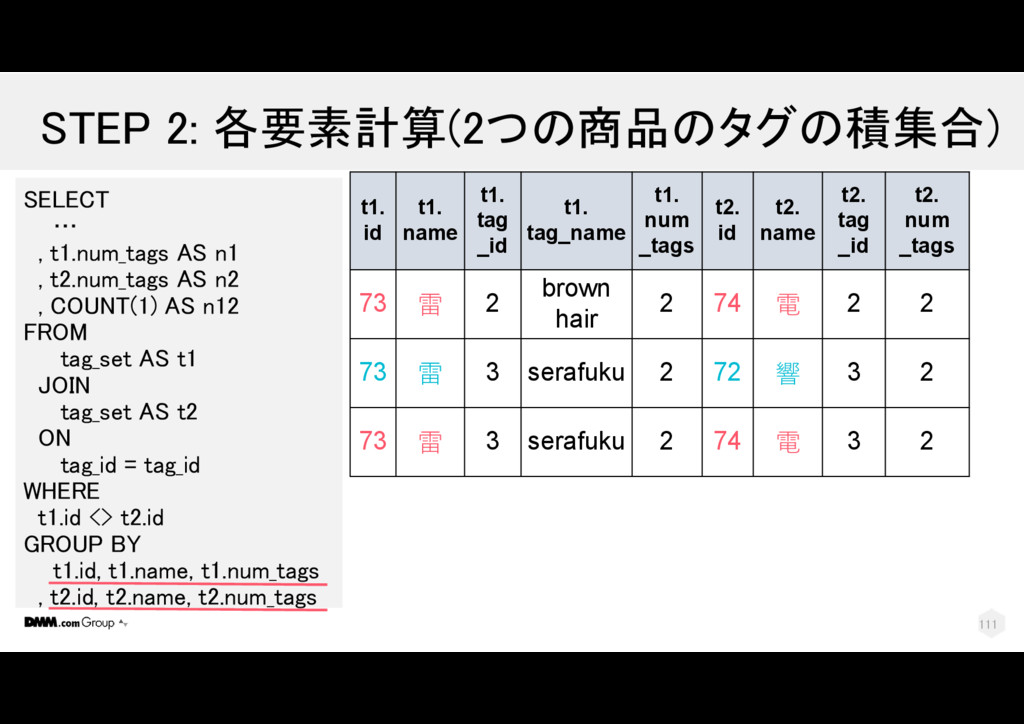
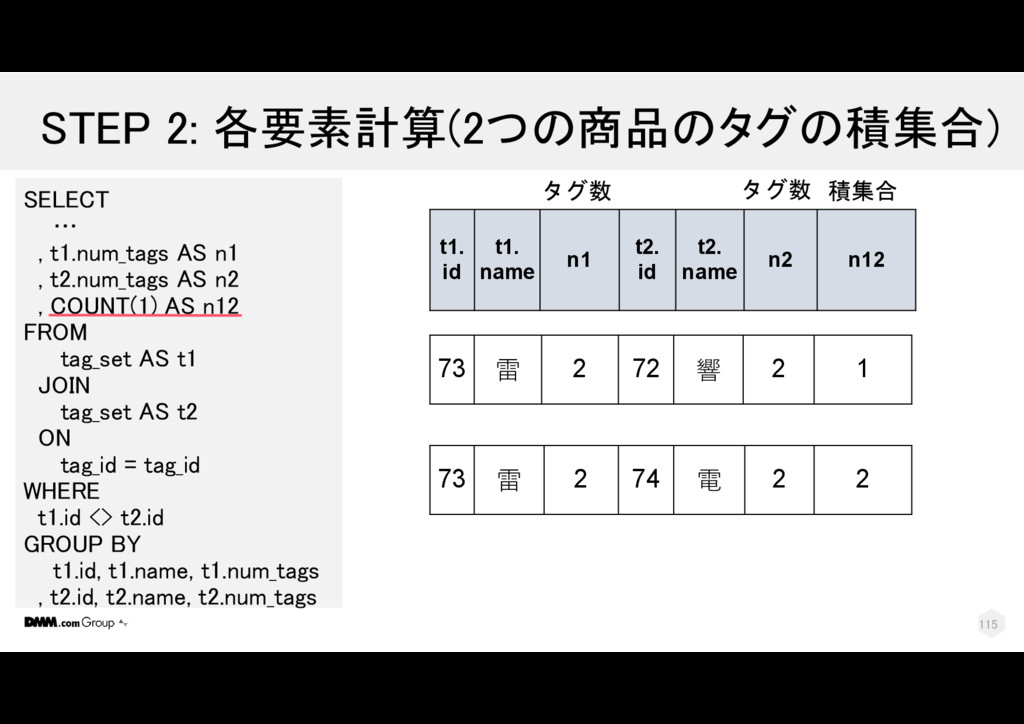
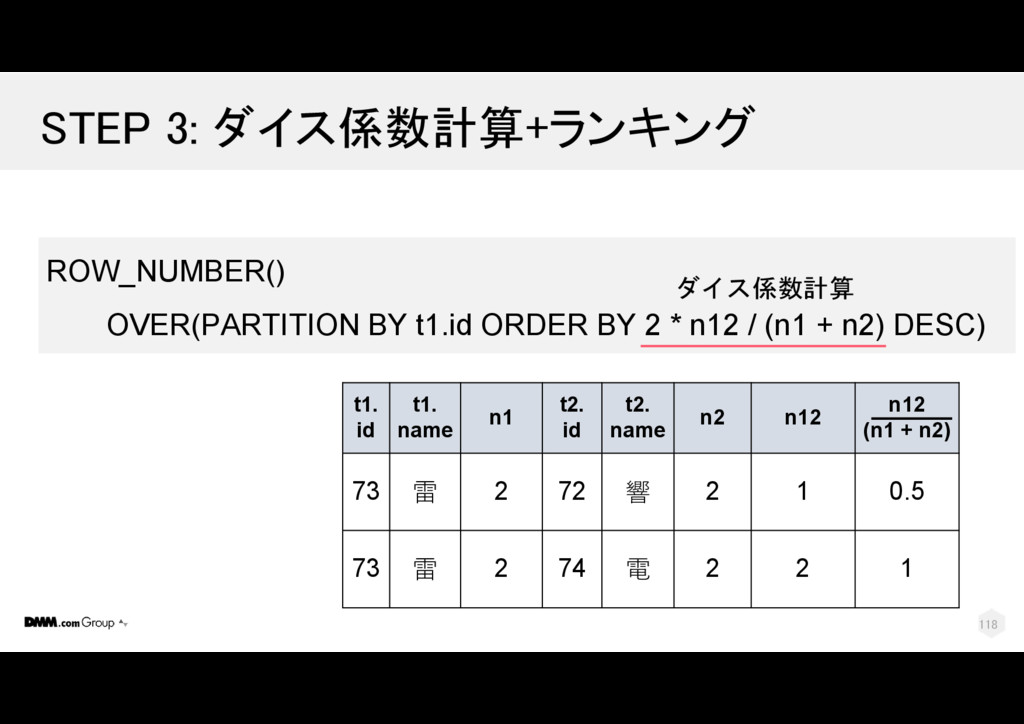
t2.num_tags AS n2 , COUNT(1) AS n12 FROM tag_set AS t1 JOIN tag_set AS t2 ON tag_id = tag_id WHERE t1.id <> t2.id GROUP BY t1.id, t1.name, t1.num_tags , t2.id, t2.name, t2.num_tags t1. id t1. name t1. tag _id t1. tag_name t1. num _tags t2. id t2. name t2. tag _id t2. num _tags 73 雷 2 brown hair 2 74 電 2 2 73 雷 3 serafuku 2 72 響 3 2 73 雷 3 serafuku 2 74 電 3 2 110
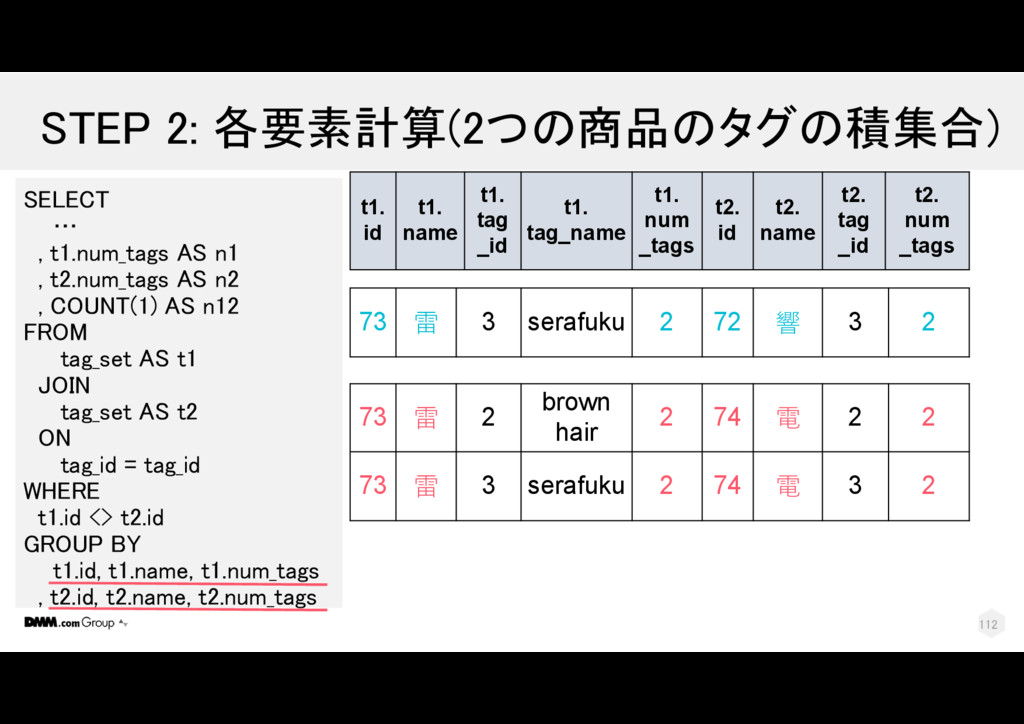
t2.num_tags AS n2 , COUNT(1) AS n12 FROM tag_set AS t1 JOIN tag_set AS t2 ON tag_id = tag_id WHERE t1.id <> t2.id GROUP BY t1.id, t1.name, t1.num_tags , t2.id, t2.name, t2.num_tags t1. id t1. name t1. tag _id t1. tag_name t1. num _tags t2. id t2. name t2. tag _id t2. num _tags 73 雷 2 brown hair 2 74 電 2 2 73 雷 3 serafuku 2 72 響 3 2 73 雷 3 serafuku 2 74 電 3 2 111
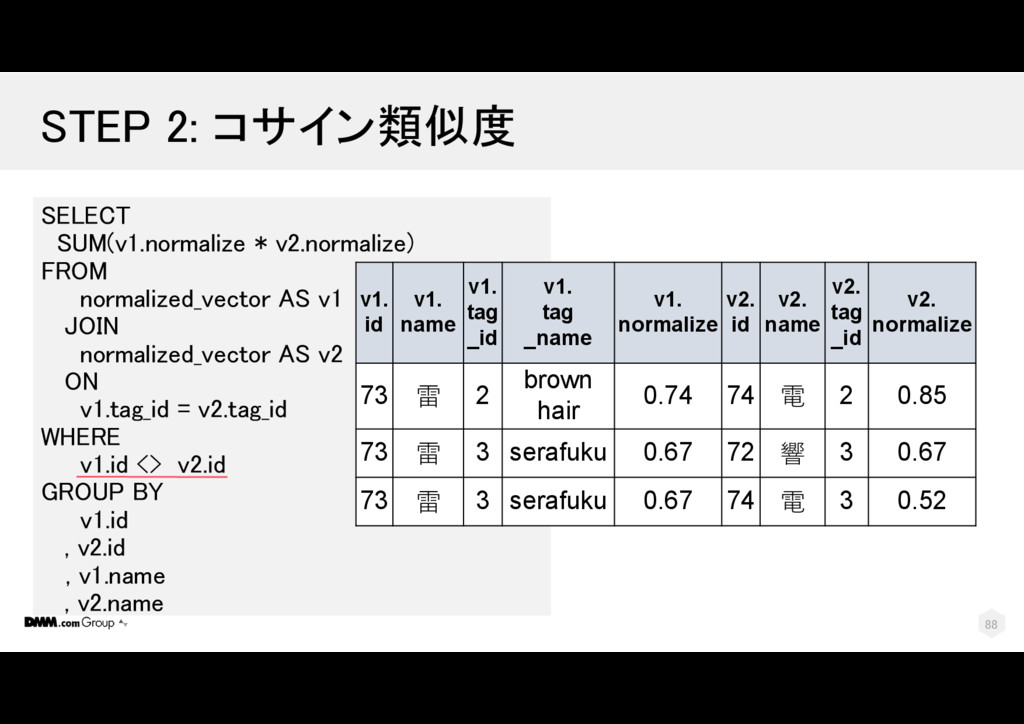
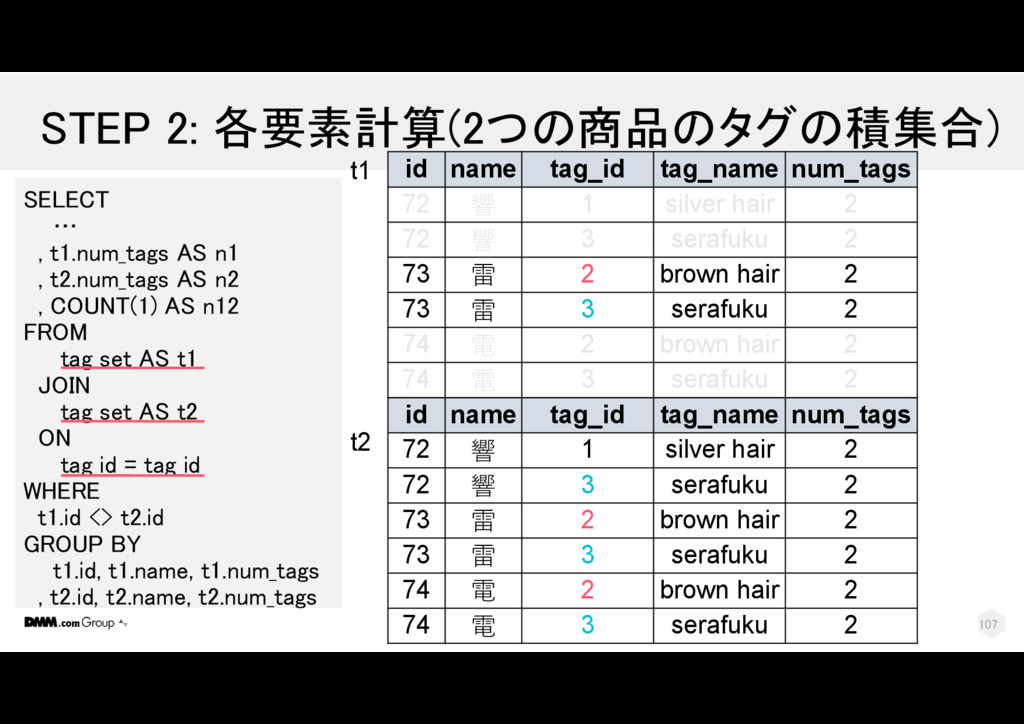
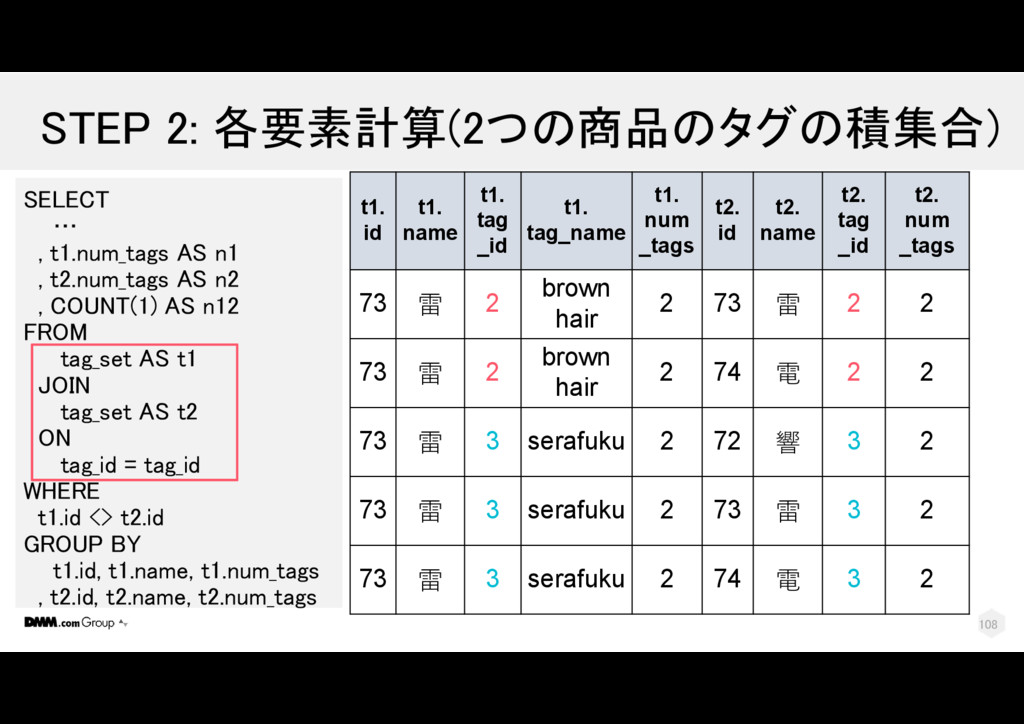
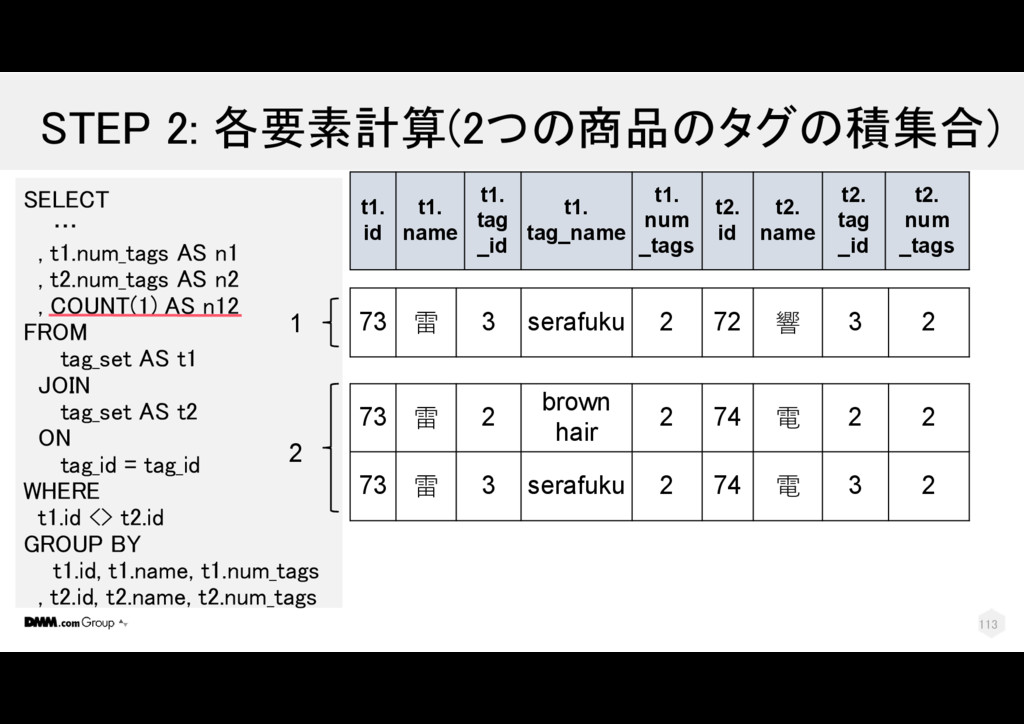
電 2 2 73 雷 3 serafuku 2 74 電 3 2 73 雷 3 serafuku 2 72 響 3 2 SELECT … , t1.num_tags AS n1 , t2.num_tags AS n2 , COUNT(1) AS n12 FROM tag_set AS t1 JOIN tag_set AS t2 ON tag_id = tag_id WHERE t1.id <> t2.id GROUP BY t1.id, t1.name, t1.num_tags , t2.id, t2.name, t2.num_tags t1. id t1. name t1. tag _id t1. tag_name t1. num _tags t2. id t2. name t2. tag _id t2. num _tags 112
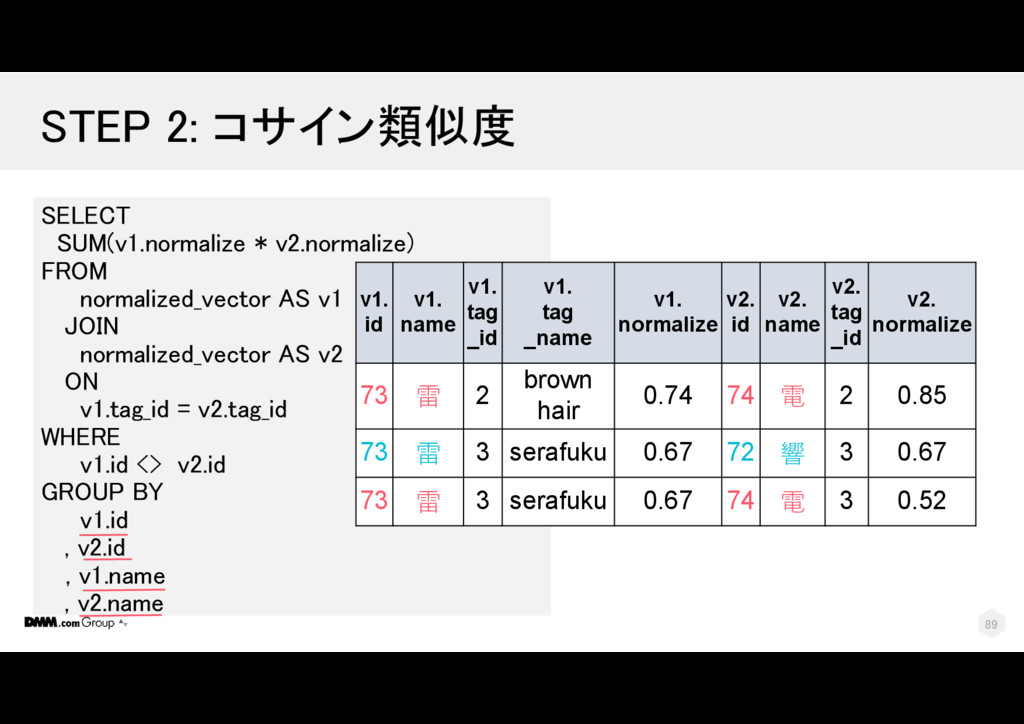
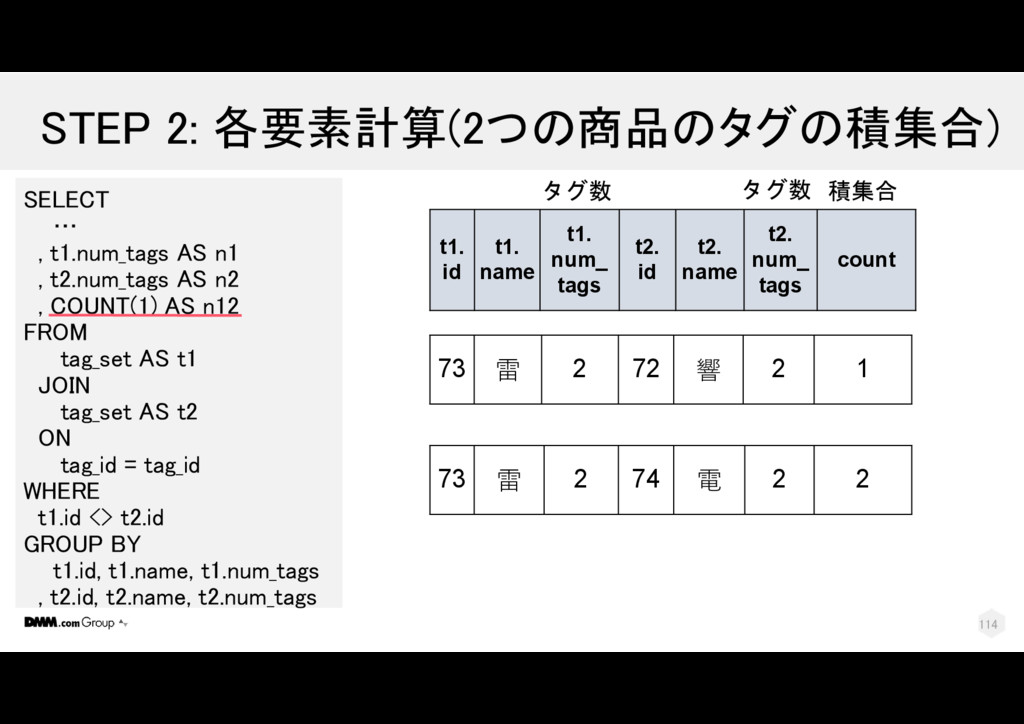
電 2 2 73 雷 3 serafuku 2 74 電 3 2 73 雷 3 serafuku 2 72 響 3 2 SELECT … , t1.num_tags AS n1 , t2.num_tags AS n2 , COUNT(1) AS n12 FROM tag_set AS t1 JOIN tag_set AS t2 ON tag_id = tag_id WHERE t1.id <> t2.id GROUP BY t1.id, t1.name, t1.num_tags , t2.id, t2.name, t2.num_tags t1. id t1. name t1. tag _id t1. tag_name t1. num _tags t2. id t2. name t2. tag _id t2. num _tags 1 2 113
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
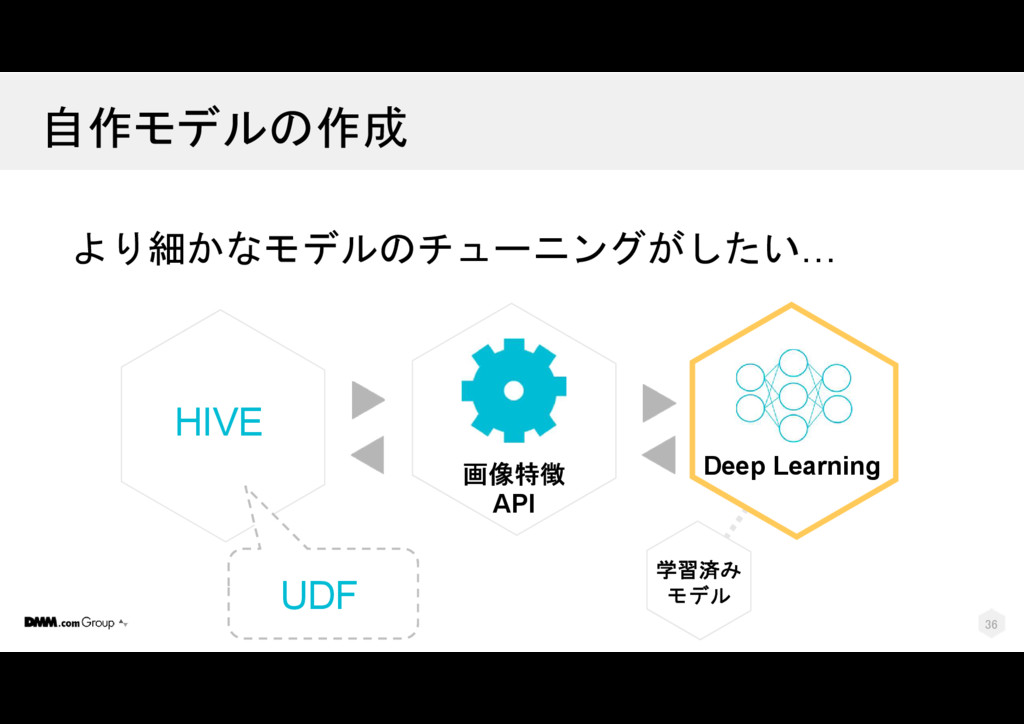{kind=link}
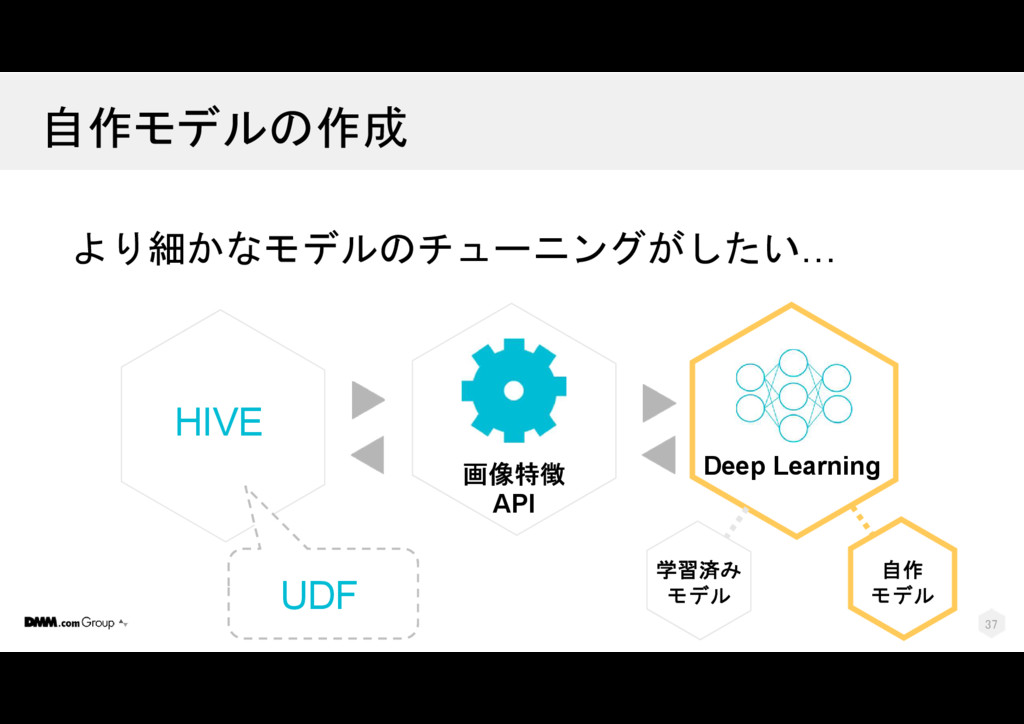{kind=link}
{kind=link}
{kind=link}
{kind=link}
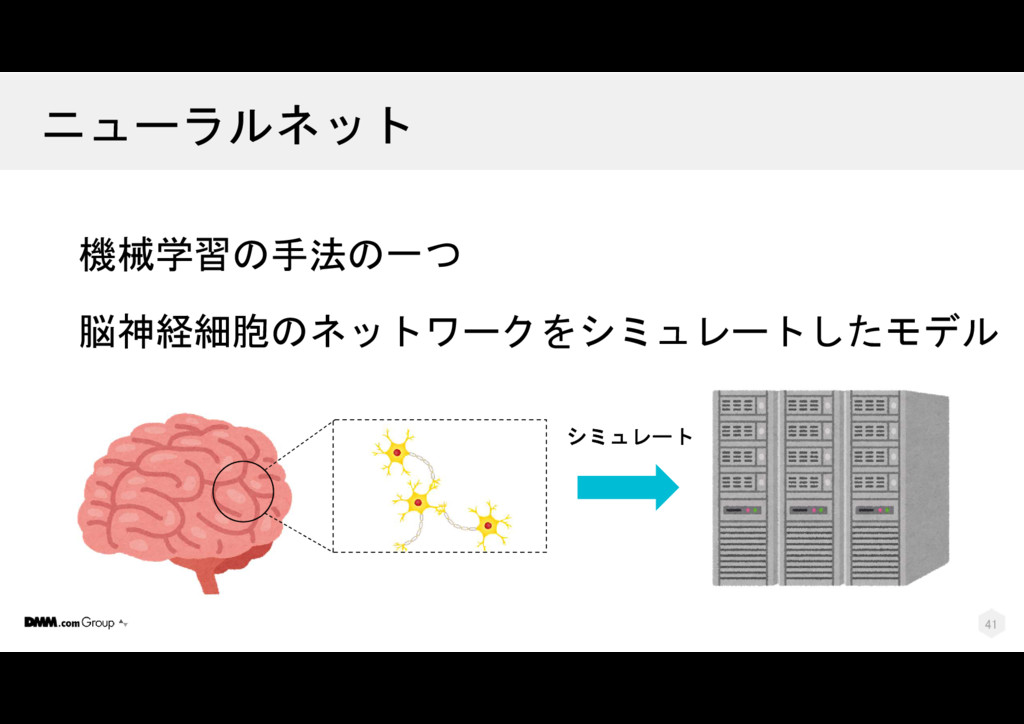{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
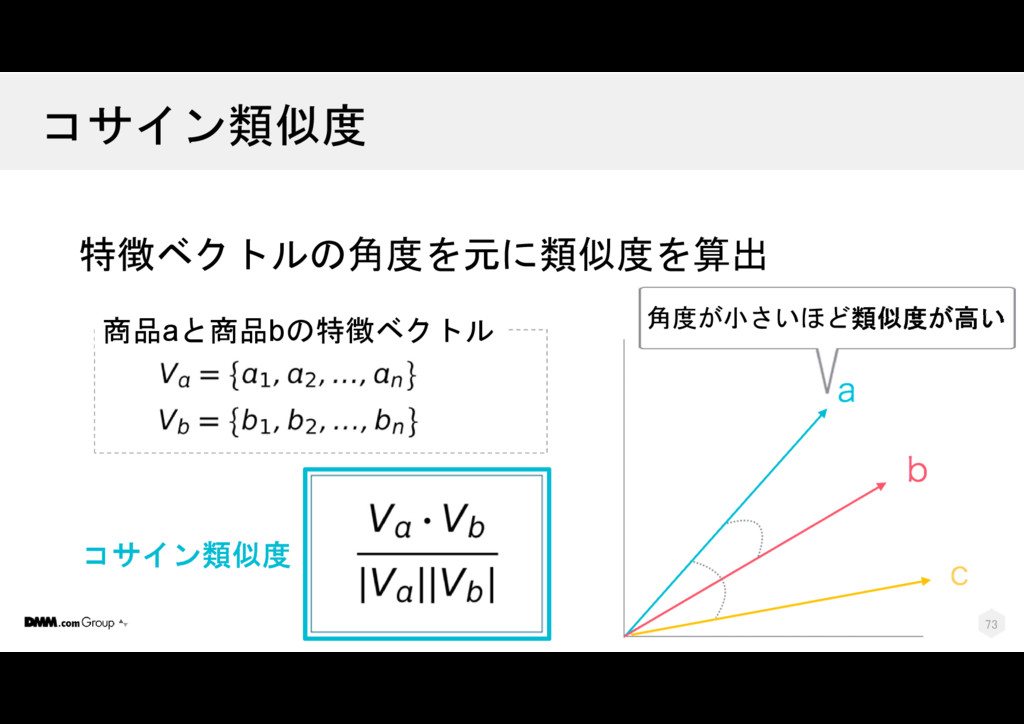{kind=link}
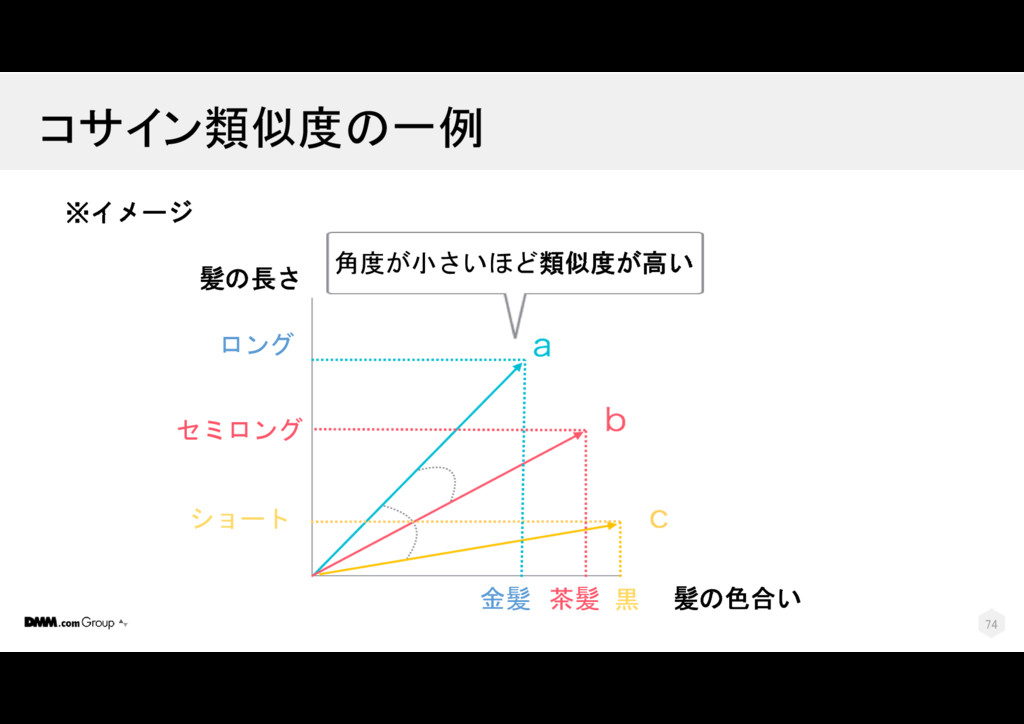{kind=link}
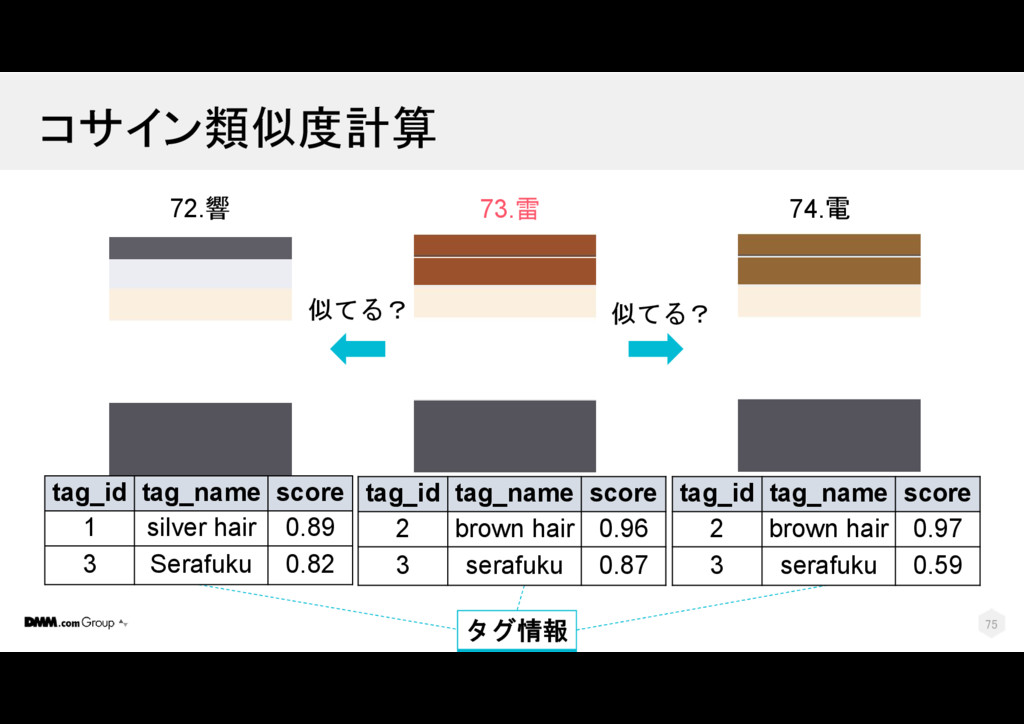{kind=link}
{kind=link}
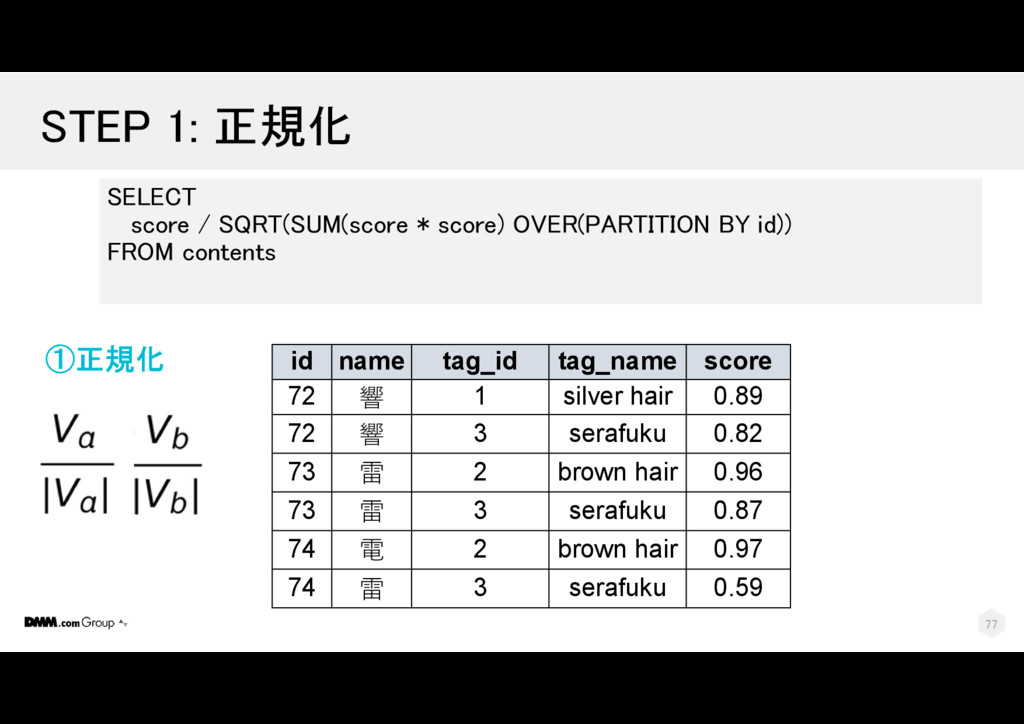{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
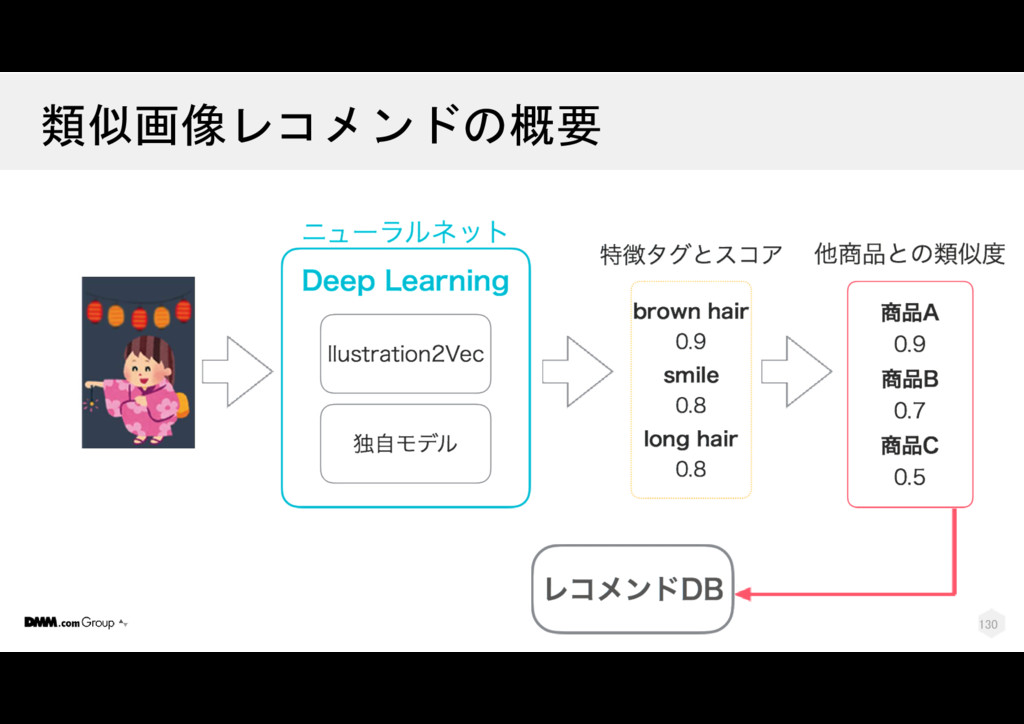{kind=link}
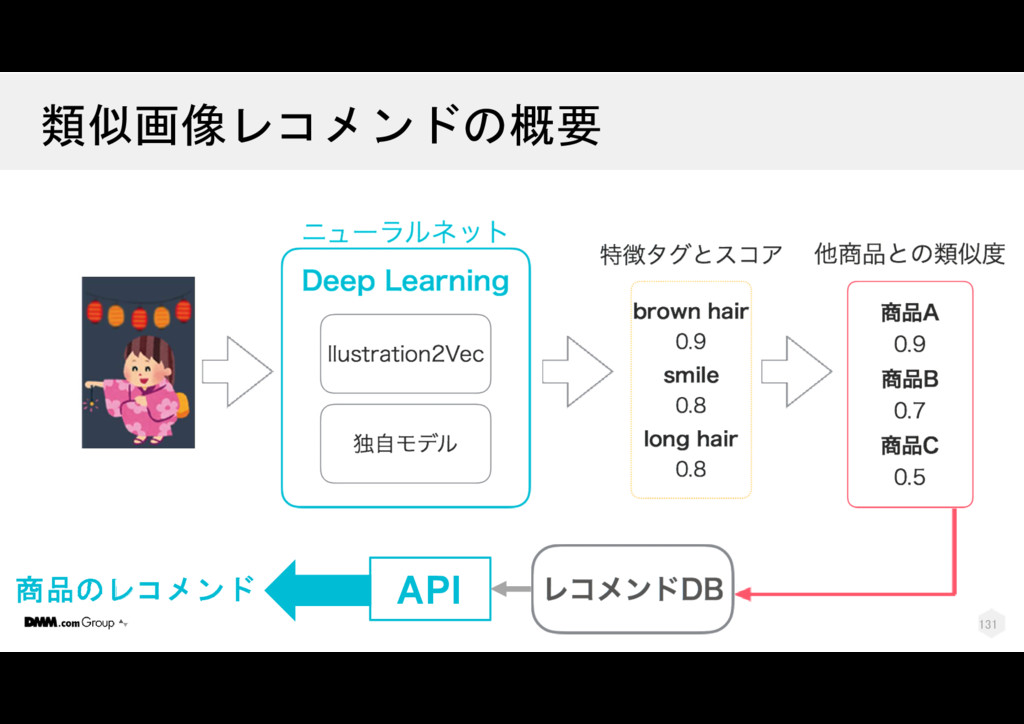{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}