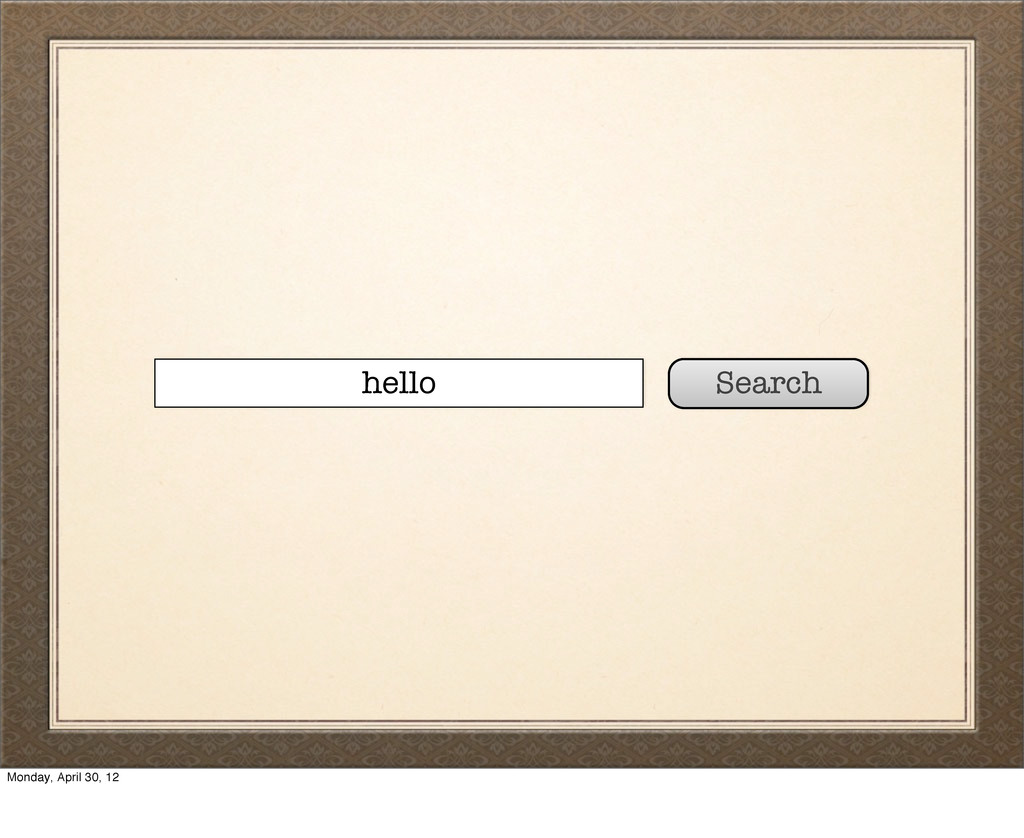
This short presentation at @herokujp on 20 Apr 2012 takes a look at the basics of full-text search. Why is a full-text search index so much faster than searching in SQL?
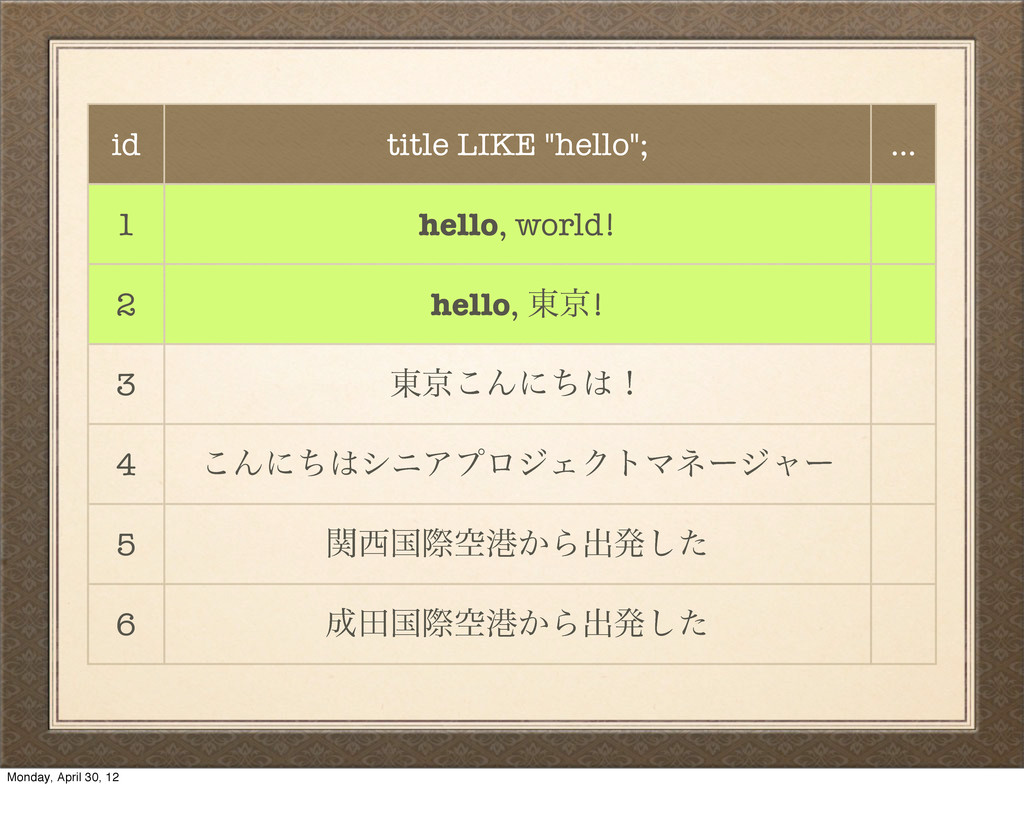
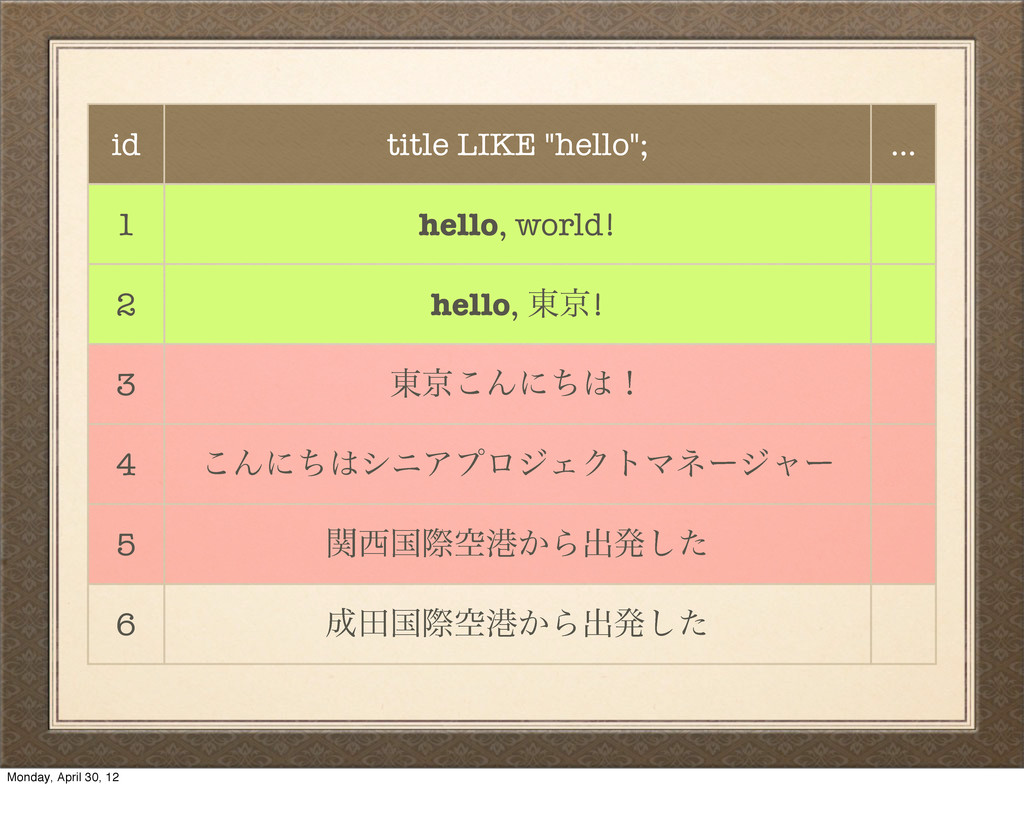
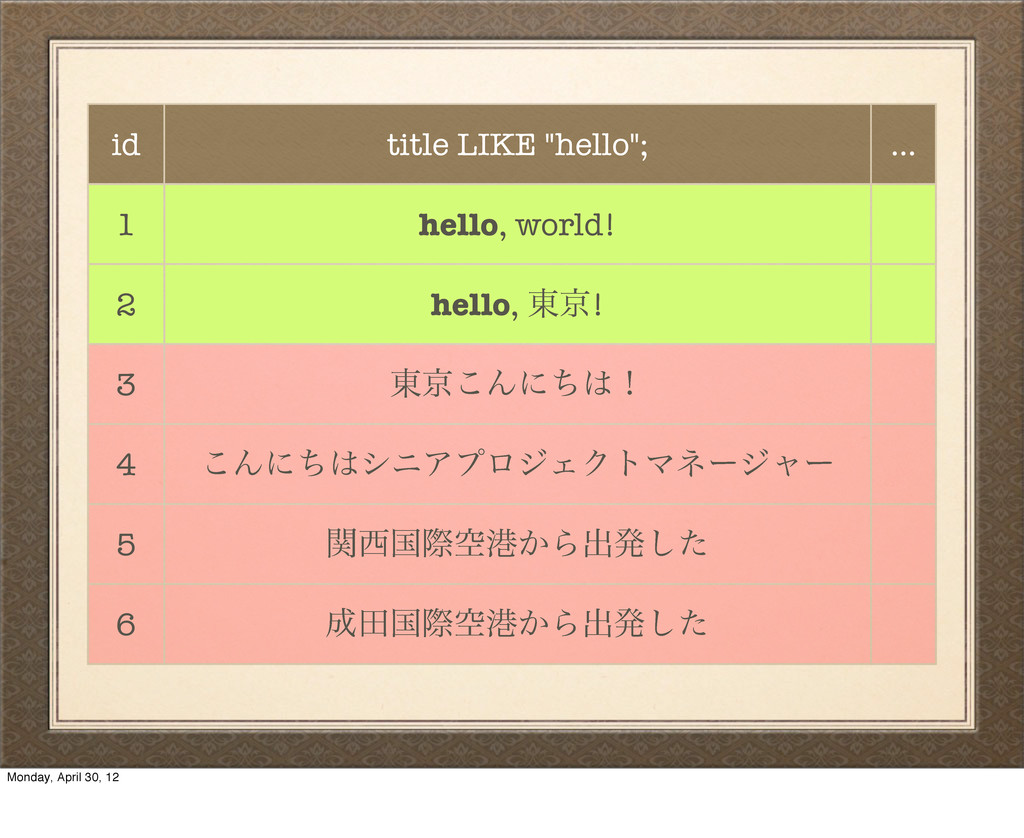
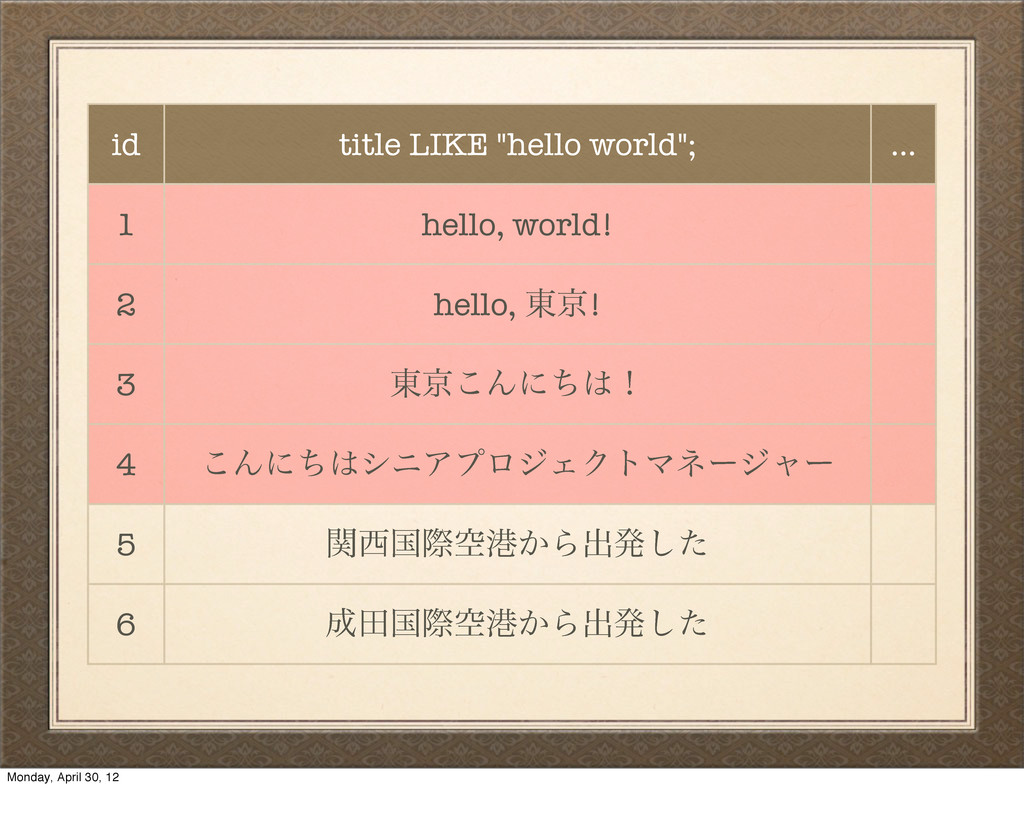
hello, ౦ژ! 3 ౦ژ͜Μʹͪʂ 4 ͜ΜʹͪγχΞϓϩδΣΫτϚωʔδϟʔ 5 ؔࠃࡍۭߓ͔Βग़ൃͨ͠ 6 ాࠃࡍۭߓ͔Βग़ൃͨ͠ uh-oh… That didn't work, because SQL like is basically just testing the exact equality of bytes here. That comma breaks our query. Monday, April 30, 12
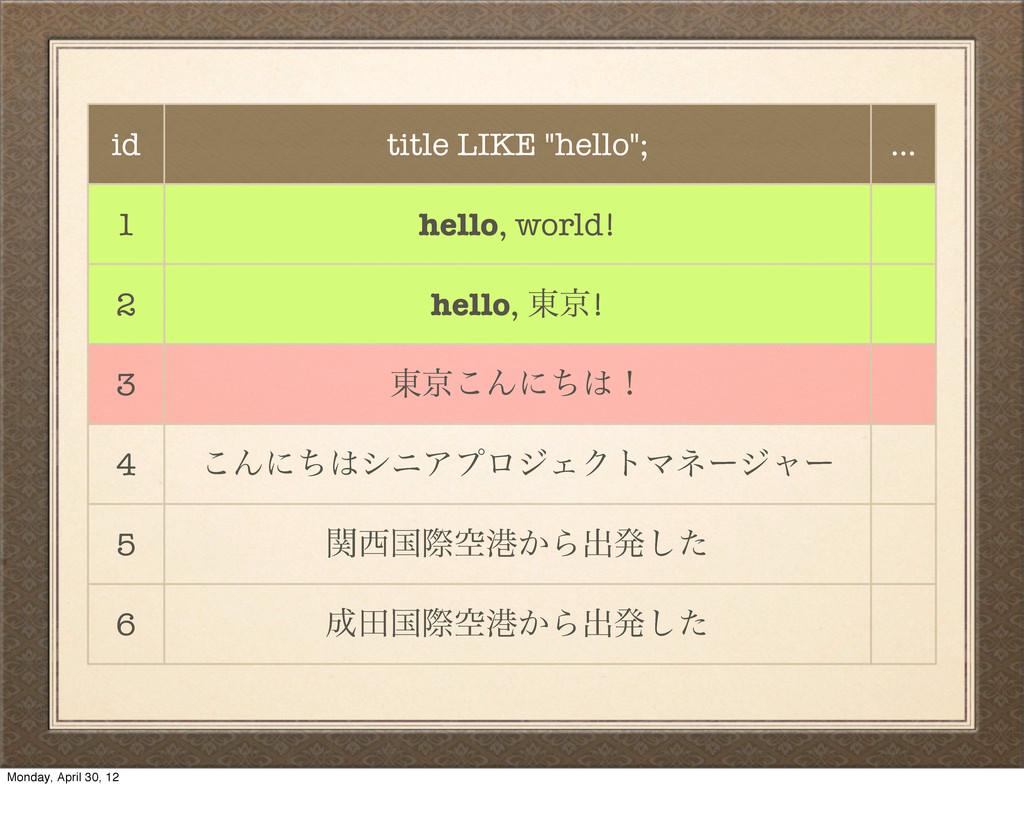
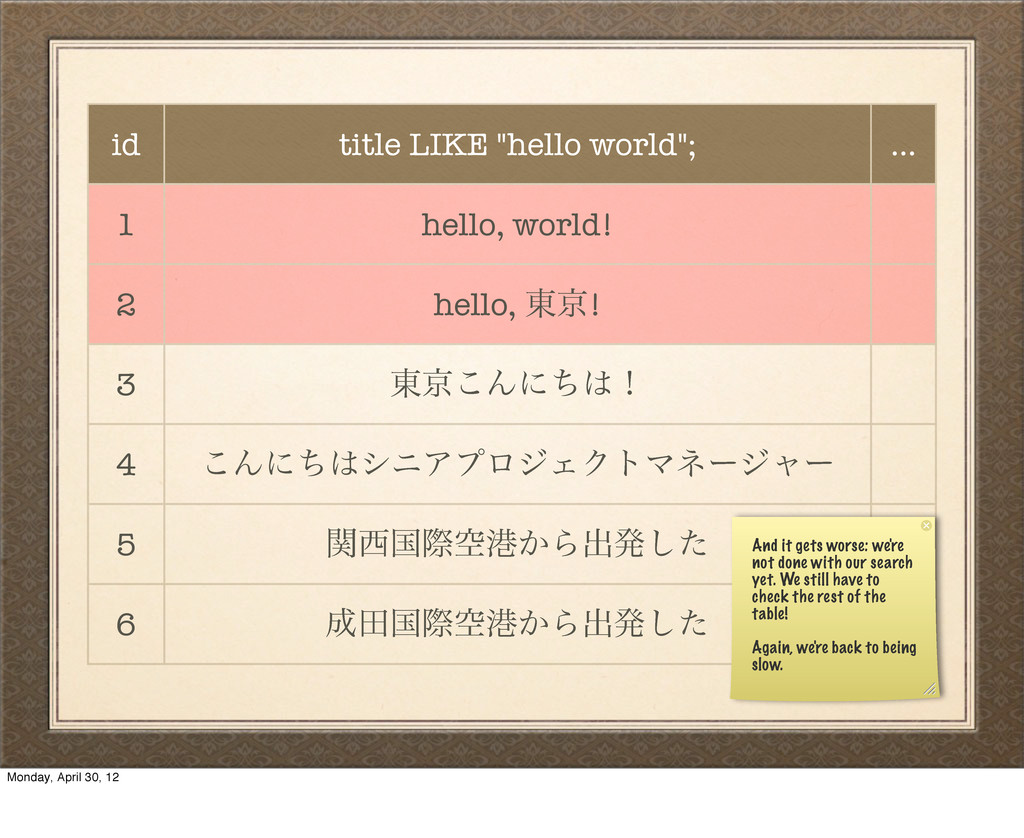
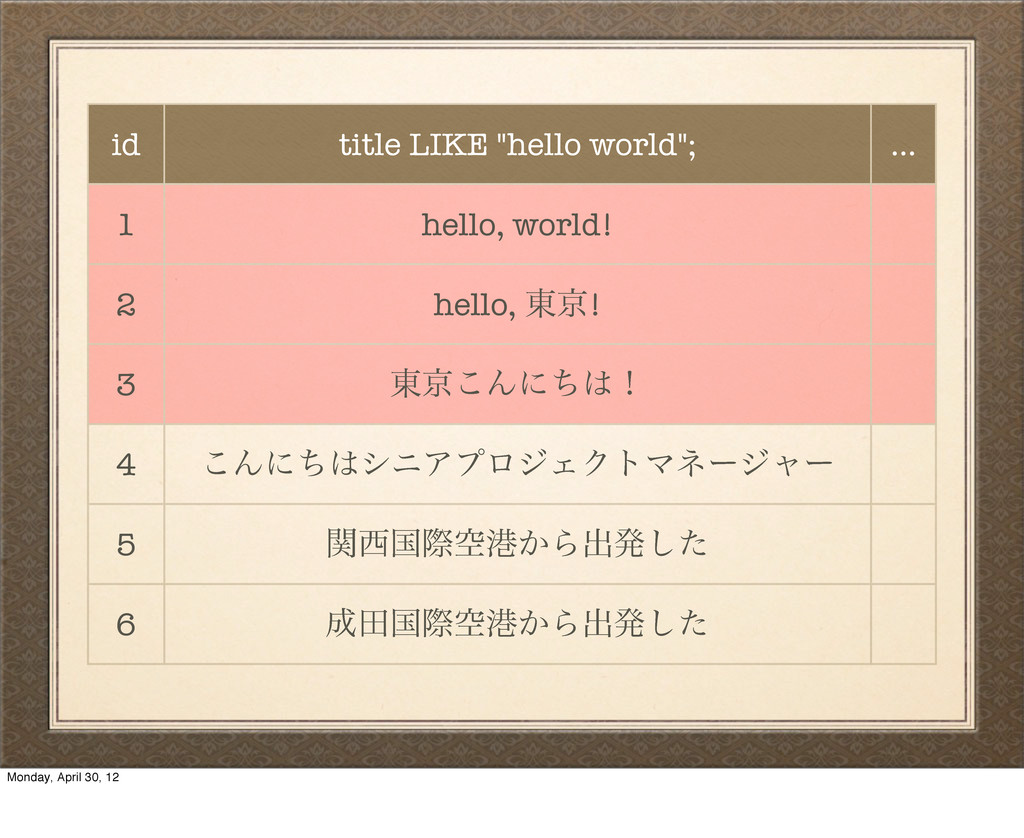
hello, ౦ژ! 3 ౦ژ͜Μʹͪʂ 4 ͜ΜʹͪγχΞϓϩδΣΫτϚωʔδϟʔ 5 ؔࠃࡍۭߓ͔Βग़ൃͨ͠ 6 ాࠃࡍۭߓ͔Βग़ൃͨ͠ And it gets worse: we're not done with our search yet. We still have to check the rest of the table! Again, we're back to being slow. Monday, April 30, 12
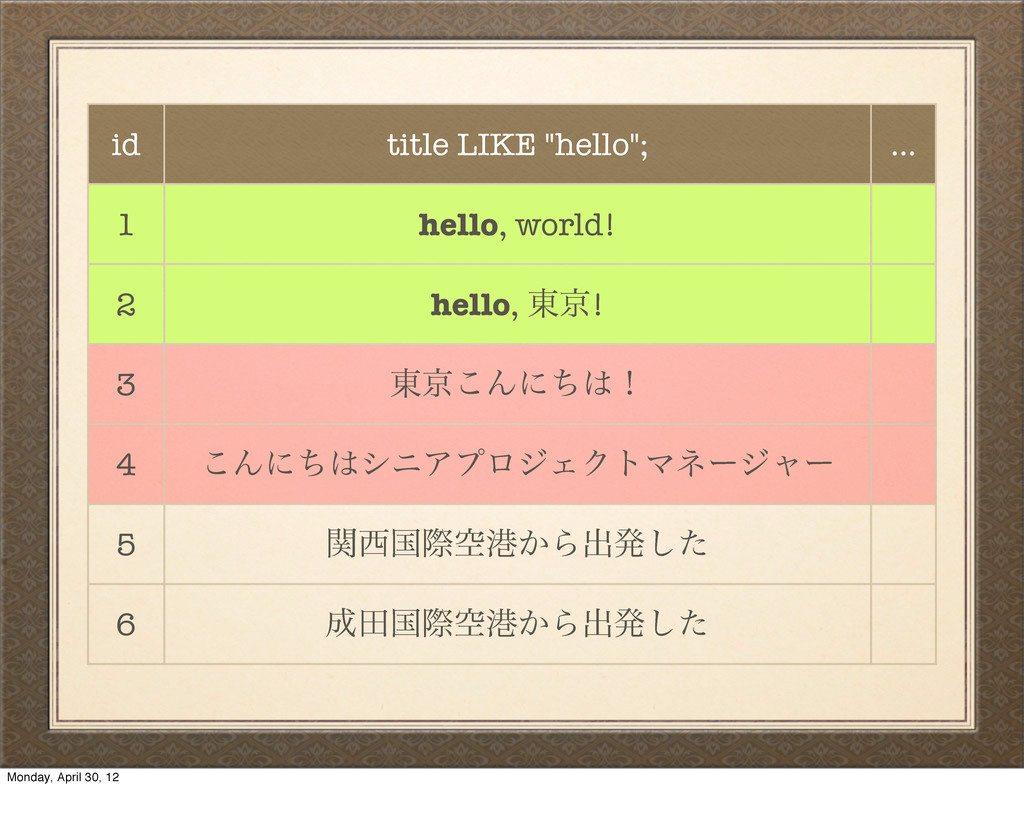
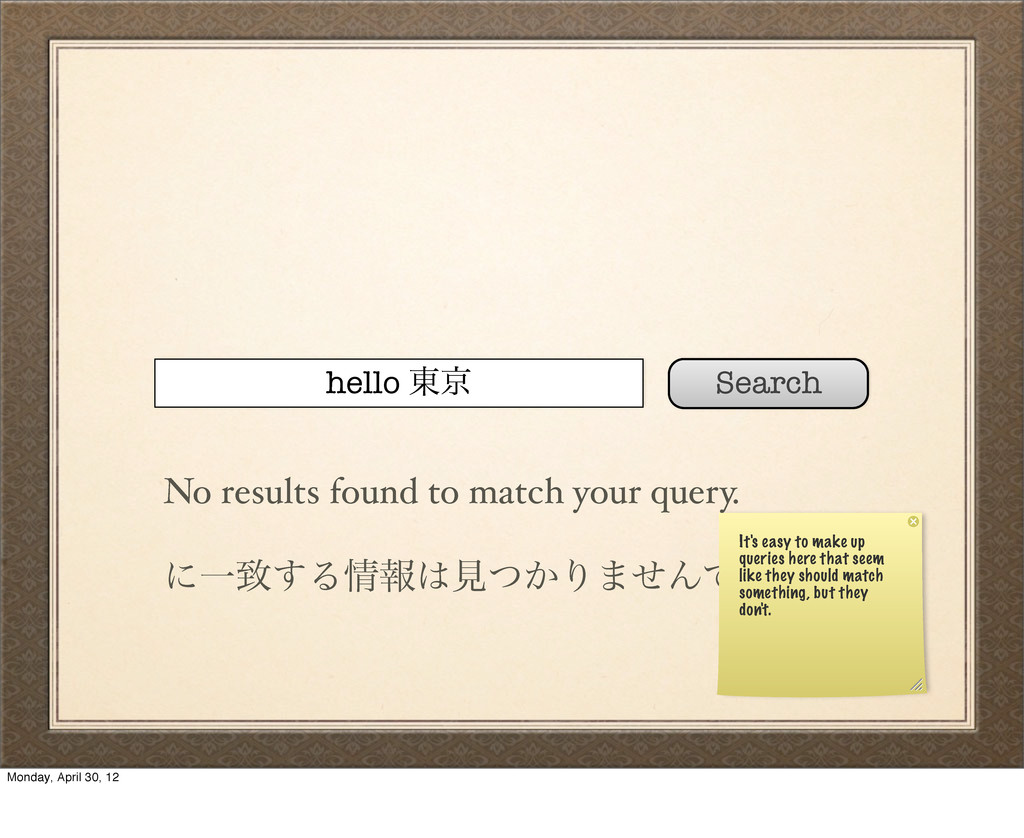
ʹҰக͢Δใݟ͔ͭΓ·ͤΜͰͨ͠ɻ We just scanned through our entire table of data without getting any useful results, and the user has no idea why. And it gets worse. Monday, April 30, 12
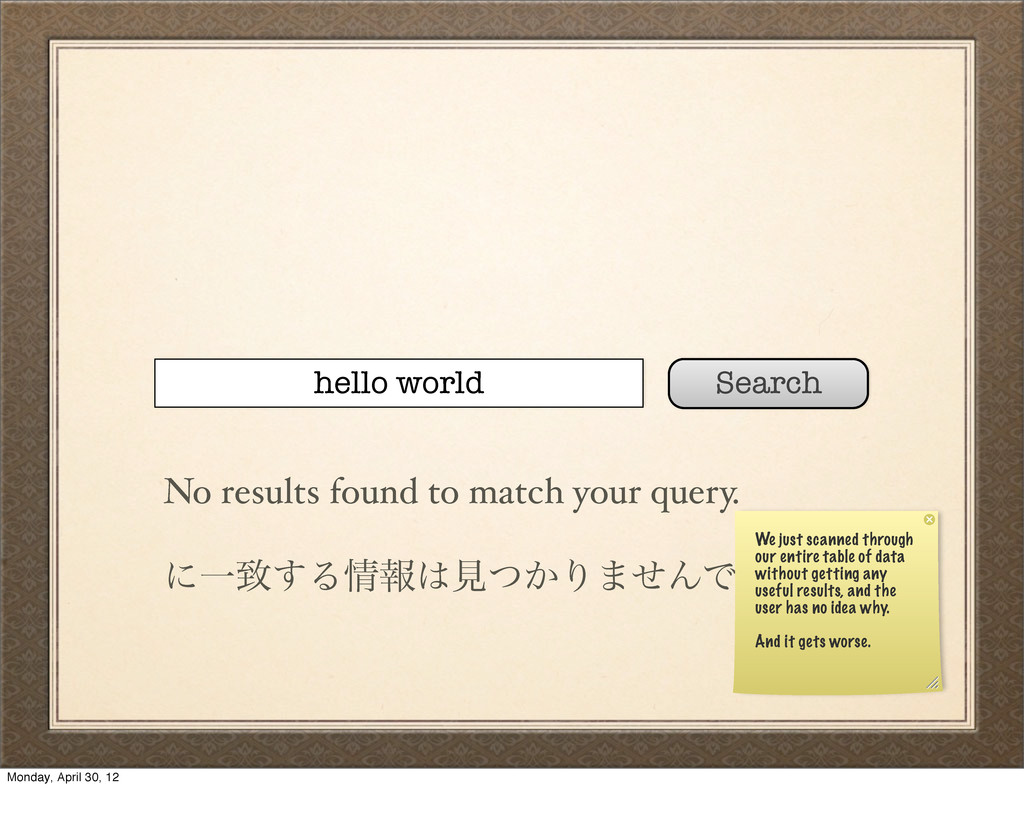
Ultimately, if you want flexible searches, you need to parse your queries and combine the results of multiple searches. But that is slow! Monday, April 30, 12
queries. Required and optional terms Flexible order of terms But many slow searches is even slower! Users expect flexible queries, but making queries flexible will make a slow search much slower. Monday, April 30, 12
౦ژ͜Μʹͪʂ 4 ͜ΜʹͪγχΞϓϩδΣΫτϚωʔδϟʔ 5 ؔࠃࡍۭߓ͔Βग़ൃͨ͠ 6 ాࠃࡍۭߓ͔Βग़ൃͨ͠ This is our original data. It's stored sensibly enough for SQL, but it's not really optimized for searching. Let's improve it. Monday, April 30, 12
This is one step in a better direction. Separate each term, and maintain its association with the original record that it appears in. Monday, April 30, 12
This means we can do something clever, like sort by term instead, which will let us run a faster binary search. This hypothetical index looks a bit like a normal database index. Monday, April 30, 12
How do you decide what makes a "term"? This is easy in English, where words are separated by whitespace and punctuation. But languages like Japanese don't use whitespace, and have relatively little punctuation. Monday, April 30, 12
ؔࠃࡍۭߓ ؔࠃࡍۭߓ ؔࠃࡍۭߓ ؔࠃࡍۭߓ ؔࠃࡍۭߓ ؔ ࠃ ࠃࡍ ࡍۭ ۭߓ The results would look something like this. It's not a very good technique, but it's better than nothing. Monday, April 30, 12
for index size and relevancy We can do better! The problem: 1. it generates a lot of terms 2. many of these "terms" don't have meaning 3. bad for index size and performance 4. bad for relevancy we can do better! Monday, April 30, 12
ࠃࡍ ۭߓ We can see right away—if you read Japanese—that we get much better terms from this kind of analysis. Since we are confident that we can tokenize Japanese, let's continue building our hypothetical index Monday, April 30, 12
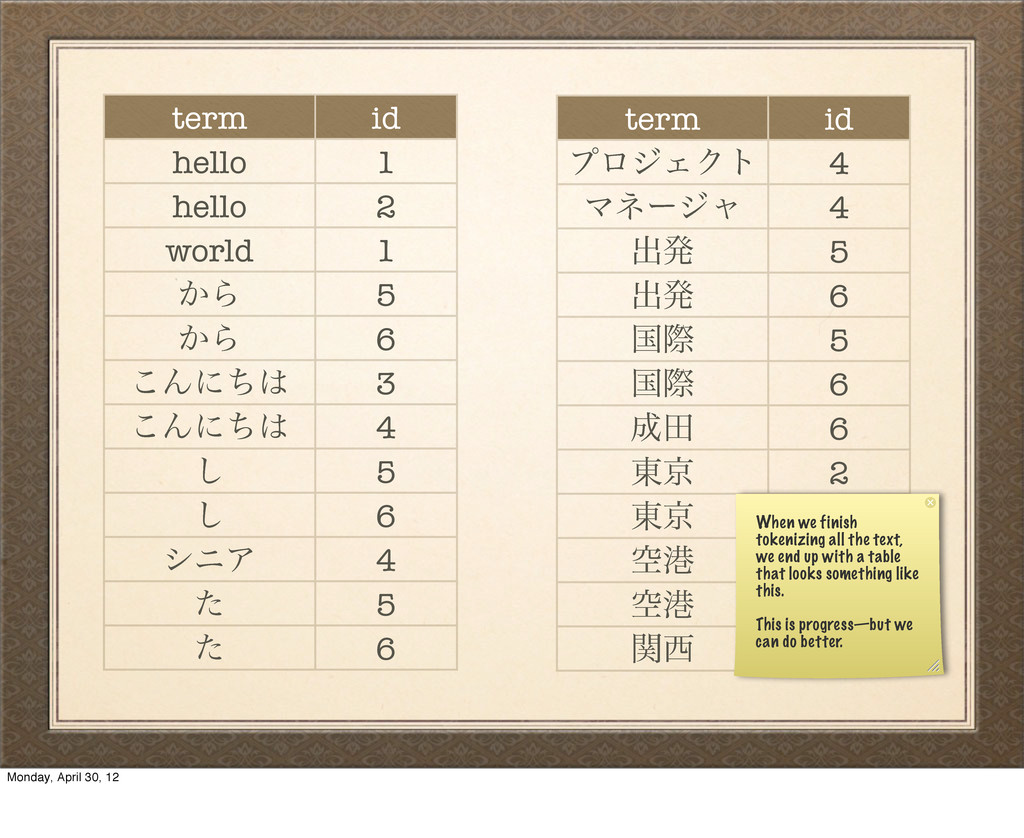
͔Β 6 ͜Μʹͪ 3 ͜Μʹͪ 4 ͠ 5 ͠ 6 γχΞ 4 ͨ 5 ͨ 6 term id ϓϩδΣΫτ 4 Ϛωʔδϟ 4 ग़ൃ 5 ग़ൃ 6 ࠃࡍ 5 ࠃࡍ 6 ా 6 ౦ژ 2 ౦ژ 3 ۭߓ 5 ۭߓ 6 ؔ 5 When we finish tokenizing all the text, we end up with a table that looks something like this. This is progress—but we can do better. Monday, April 30, 12
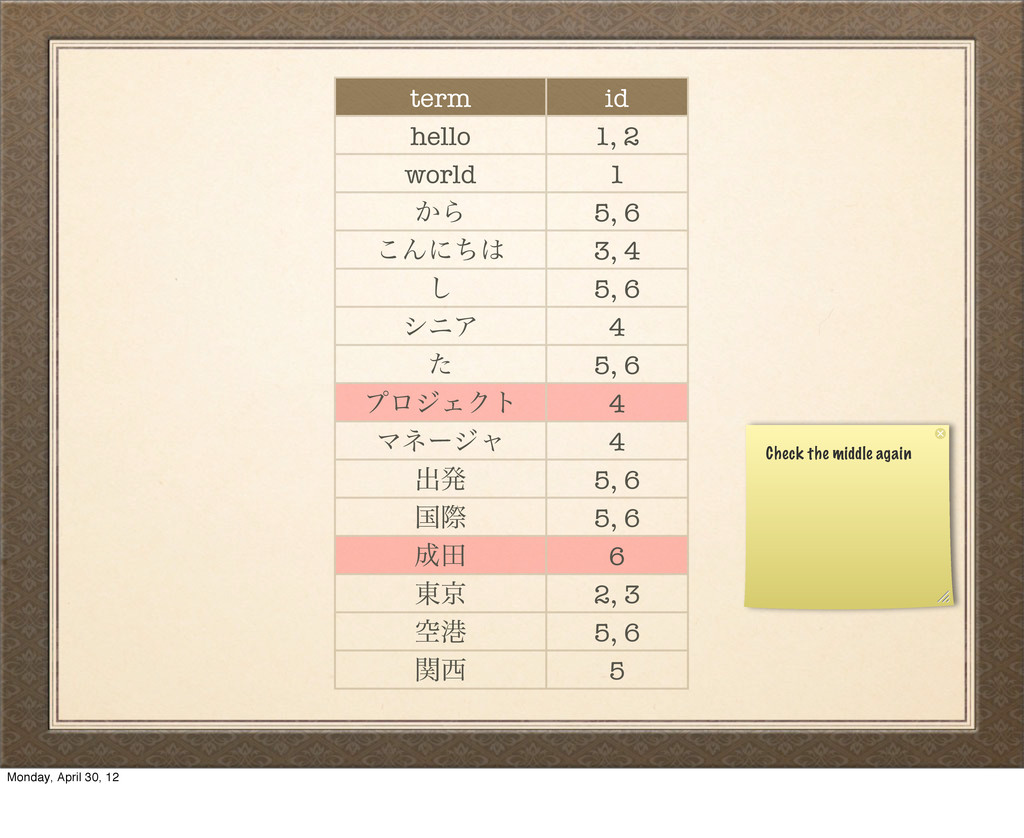
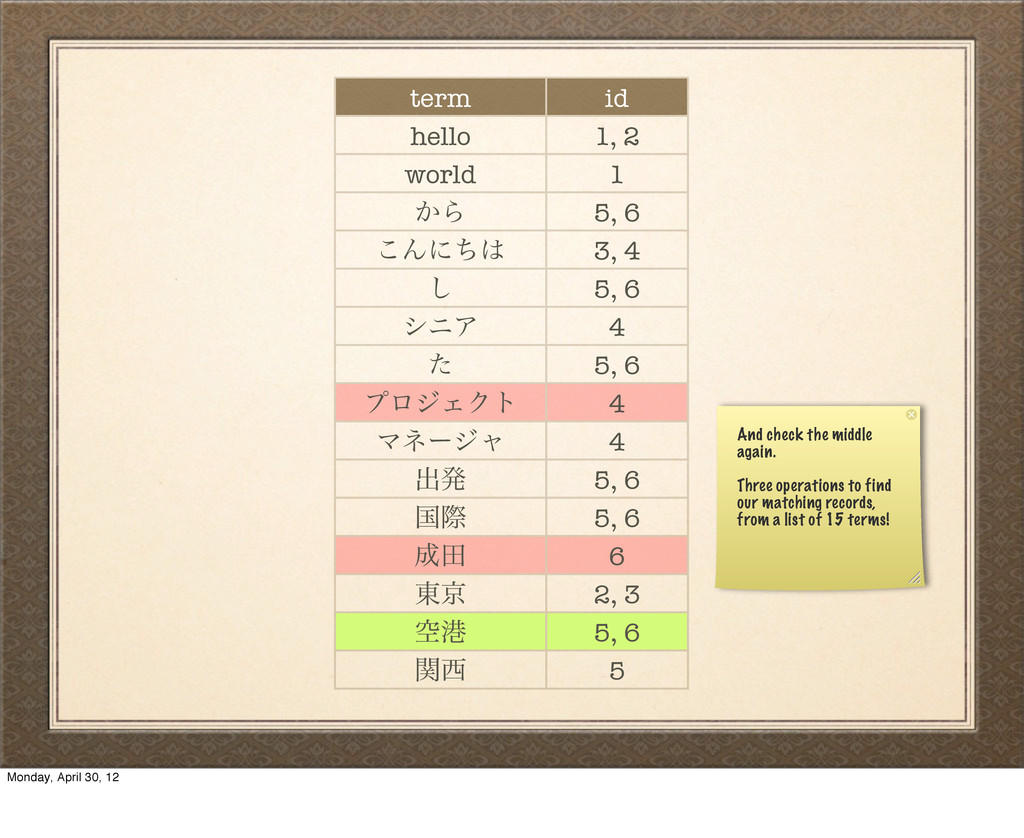
͜Μʹͪ 3, 4 ͠ 5, 6 γχΞ 4 ͨ 5, 6 ϓϩδΣΫτ 4 Ϛωʔδϟ 4 ग़ൃ 5, 6 ࠃࡍ 5, 6 ా 6 ౦ژ 2, 3 ۭߓ 5, 6 ؔ 5 This table here maintains one entry per term, associated with a set of IDs for the records that are included. Monday, April 30, 12
is similar to the "inverse index" built by Lucene. Lucene is a library that specializes in creating and maintaining efficient data structures for your index. Monday, April 30, 12
͜Μʹͪ 3, 4 ͠ 5, 6 γχΞ 4 ͨ 5, 6 ϓϩδΣΫτ 4 Ϛωʔδϟ 4 ग़ൃ 5, 6 ࠃࡍ 5, 6 ా 6 ౦ژ 2, 3 ۭߓ 5, 6 ؔ 5 Because we now have a sorted list of each term, we can perform a binary search. Monday, April 30, 12
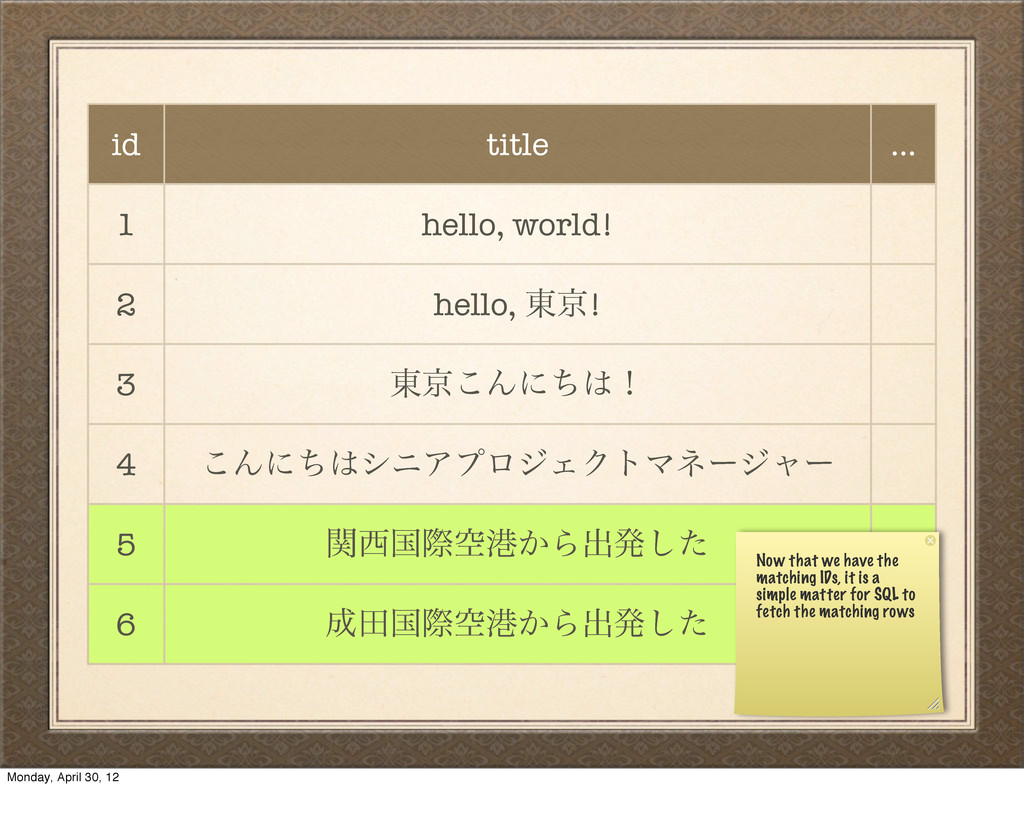
౦ژ͜Μʹͪʂ 4 ͜ΜʹͪγχΞϓϩδΣΫτϚωʔδϟʔ 5 ؔࠃࡍۭߓ͔Βग़ൃͨ͠ 6 ాࠃࡍۭߓ͔Βग़ൃͨ͠ Now that we have the matching IDs, it is a simple matter for SQL to fetch the matching rows Monday, April 30, 12
͜Μʹͪ 3, 4 ͠ 5, 6 γχΞ 4 ͨ 5, 6 ϓϩδΣΫτ 4 Ϛωʔδϟ 4 ग़ൃ 5, 6 ࠃࡍ 5, 6 ా 6 ౦ژ 2, 3 ۭߓ 5, 6 ؔ 5 Ϛωʔδϟ We can combine the matched documents in many different ways using set theory Monday, April 30, 12
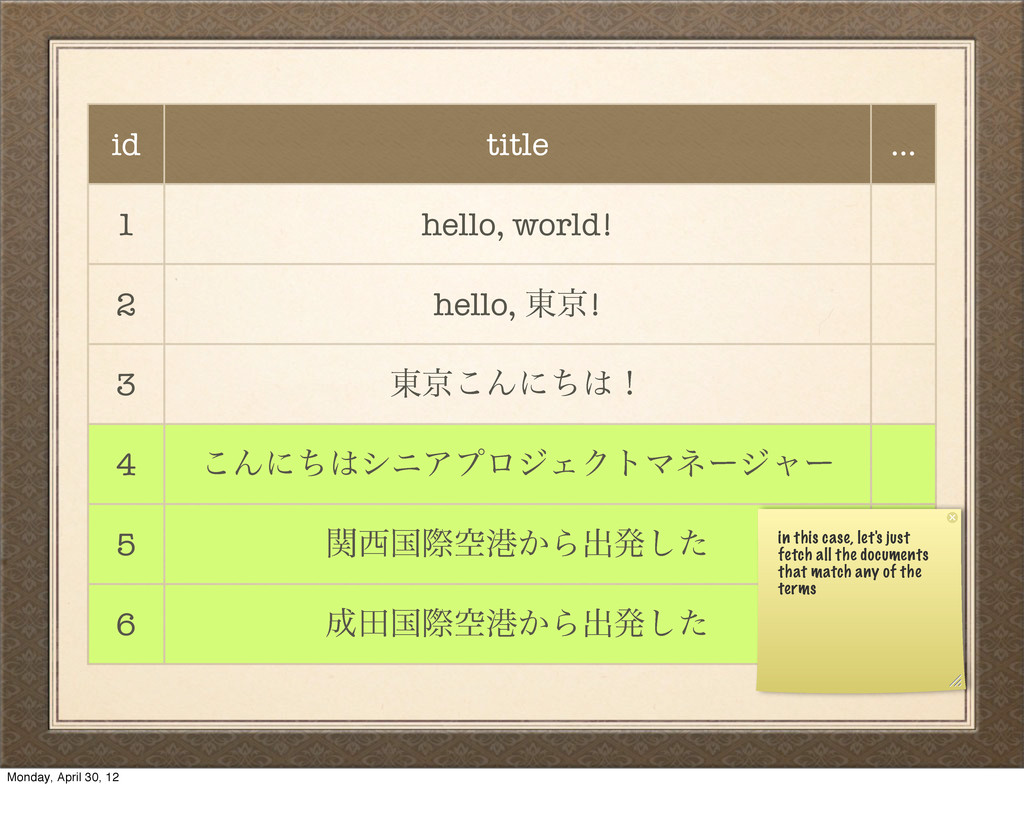
౦ژ͜Μʹͪʂ 4 ͜ΜʹͪγχΞϓϩδΣΫτϚωʔδϟʔ 5 ؔࠃࡍۭߓ͔Βग़ൃͨ͠ 6 ాࠃࡍۭߓ͔Βग़ൃͨ͠ in this case, let's just fetch all the documents that match any of the terms Monday, April 30, 12
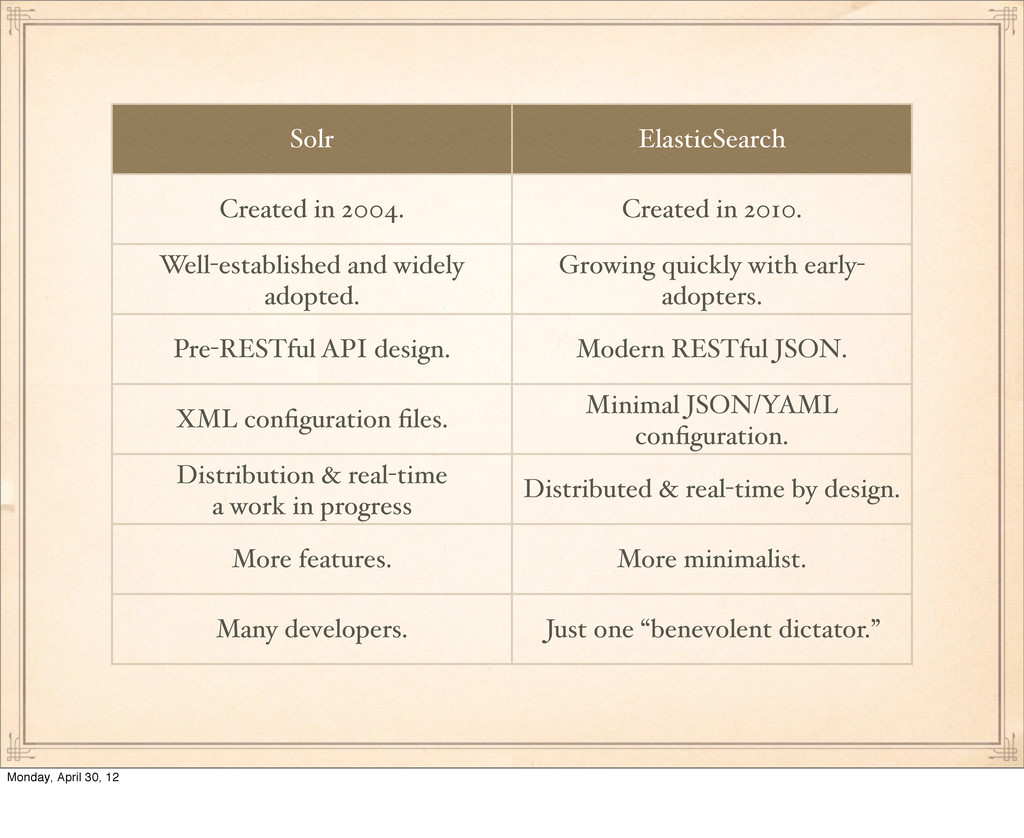
widely adopted. Growing quickly with early- adopters. Pre-RESTful API design. Modern RESTful JSON. XML configuration files. Minimal JSON/YAML configuration. Distribution & real-time a work in progress Distributed & real-time by design. More features. More minimalist. Many developers. Just one “benevolent dictator.” Monday, April 30, 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}