Share
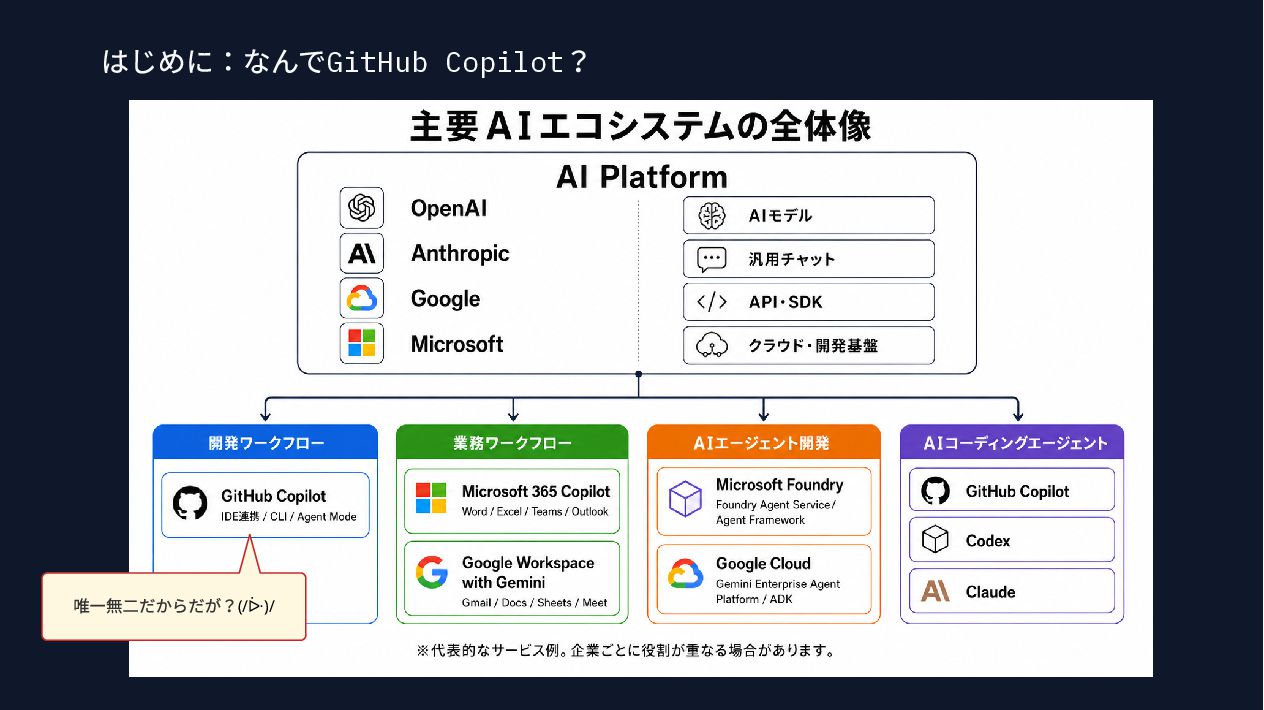
GitHub Copilotを使うほど、課題は「どう質問するか」から「何をAIに読ませるか」へ移ります。本セッションでは、MCP、Skills、AGENTS .md、DESIGN.mdがどのタイミングで読み込まれ、レスポンスでトークンが増えるのかを整理します。自動化による速度向上だけでなく、レビュー有無・設計品質・コストのバランスを取るための判断軸を紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
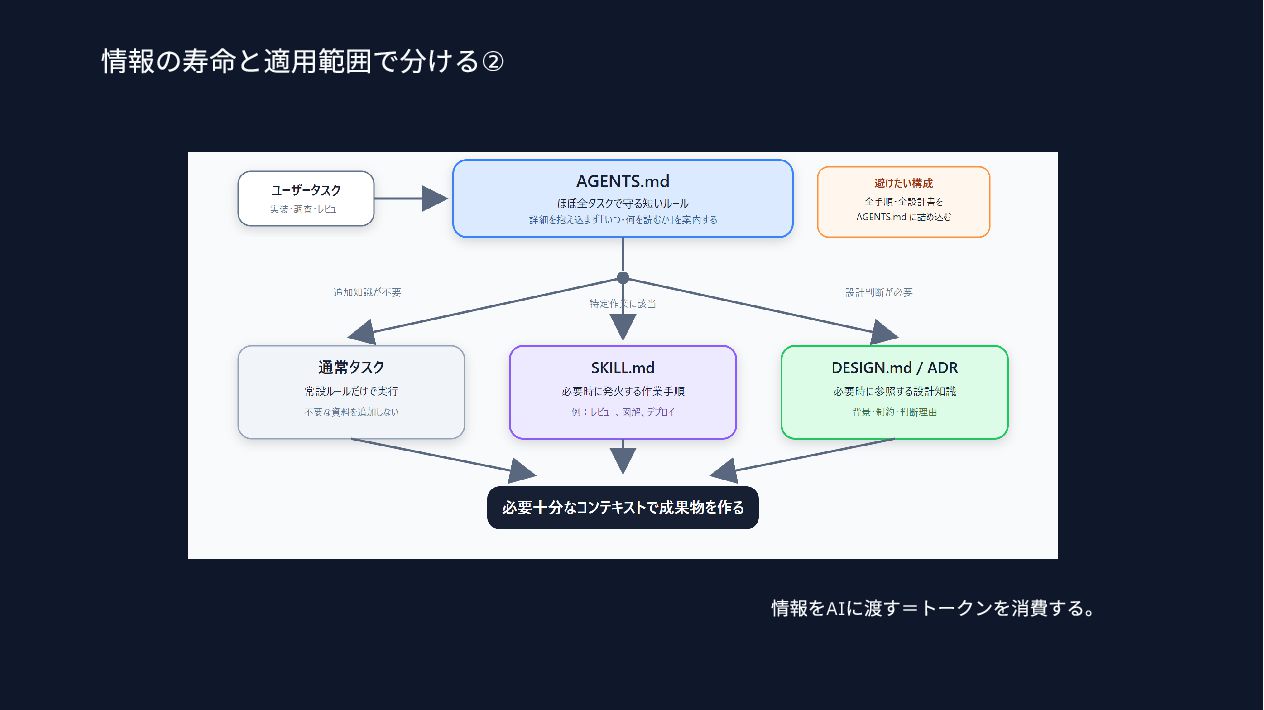{kind=link}
{kind=link}
{kind=link}
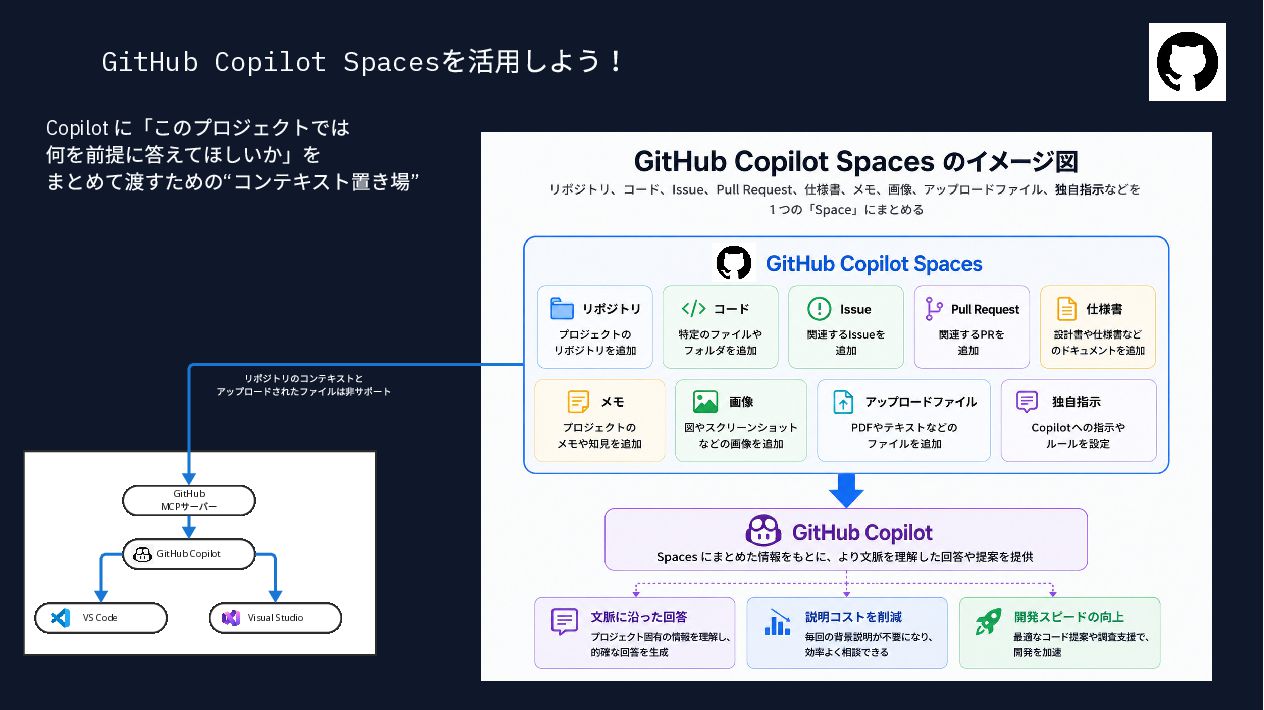{kind=link}
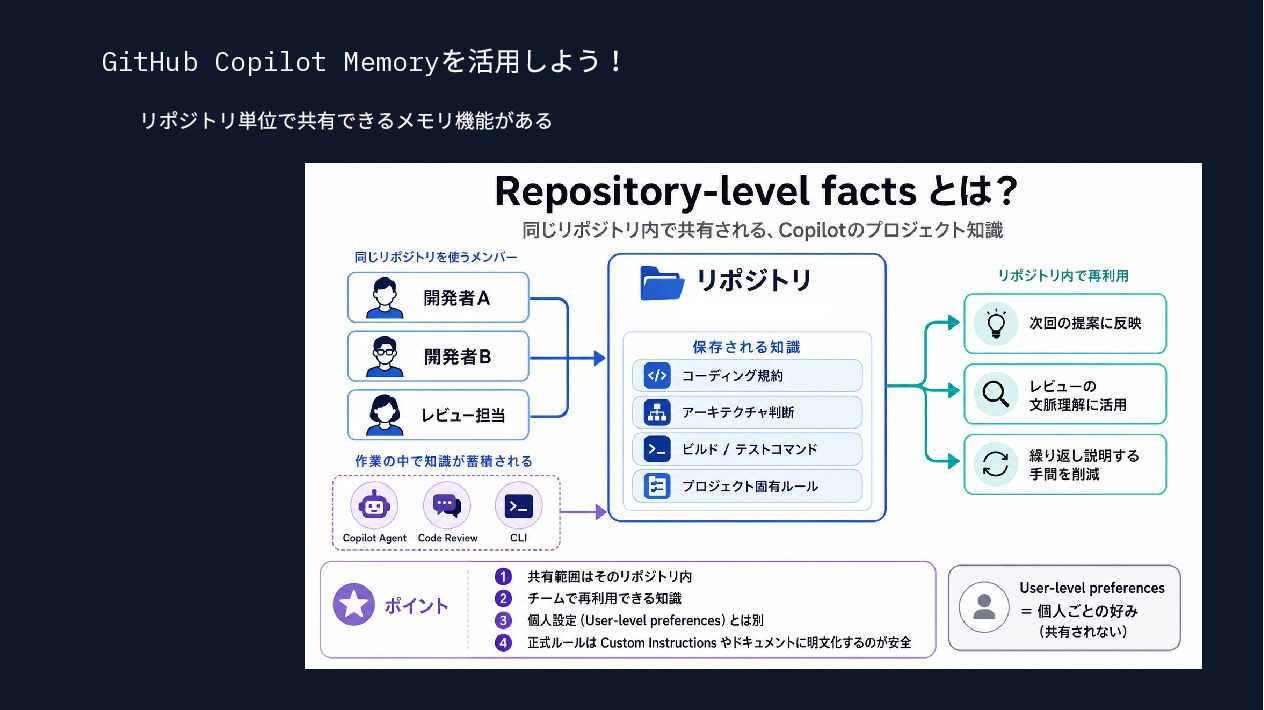{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
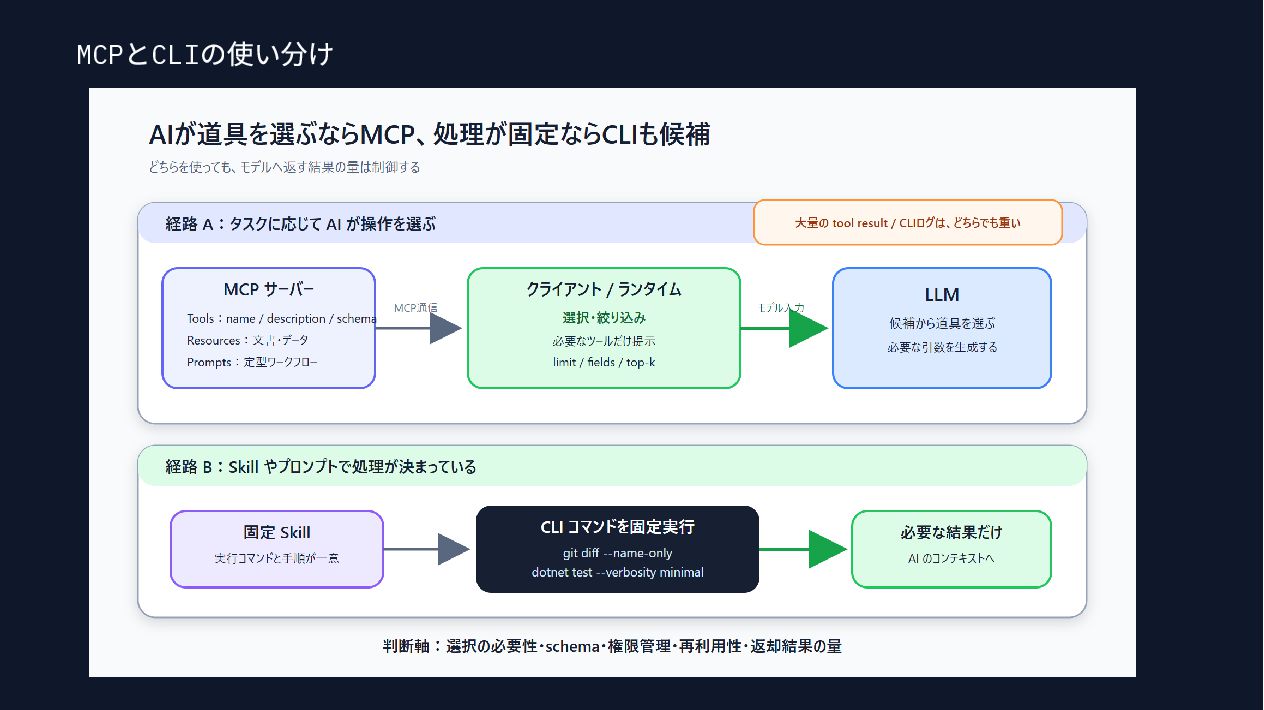{kind=link}
{kind=link}
{kind=link}
![Prompt Caching を 活用する なら 「固定文」は できるだけ前に 書く [system] あなたは〜](https://files.speakerdeck.com/presentations/a07a7da1a7a24f9f994425fbeb4a2e4b/slide_35.jpg){kind=link}
{kind=link}
![状況に 応じて セッション継続を やめよう [system] あなたは〜 [tools] tool1: ... tool2:](https://files.speakerdeck.com/presentations/a07a7da1a7a24f9f994425fbeb4a2e4b/slide_37.jpg){kind=link}
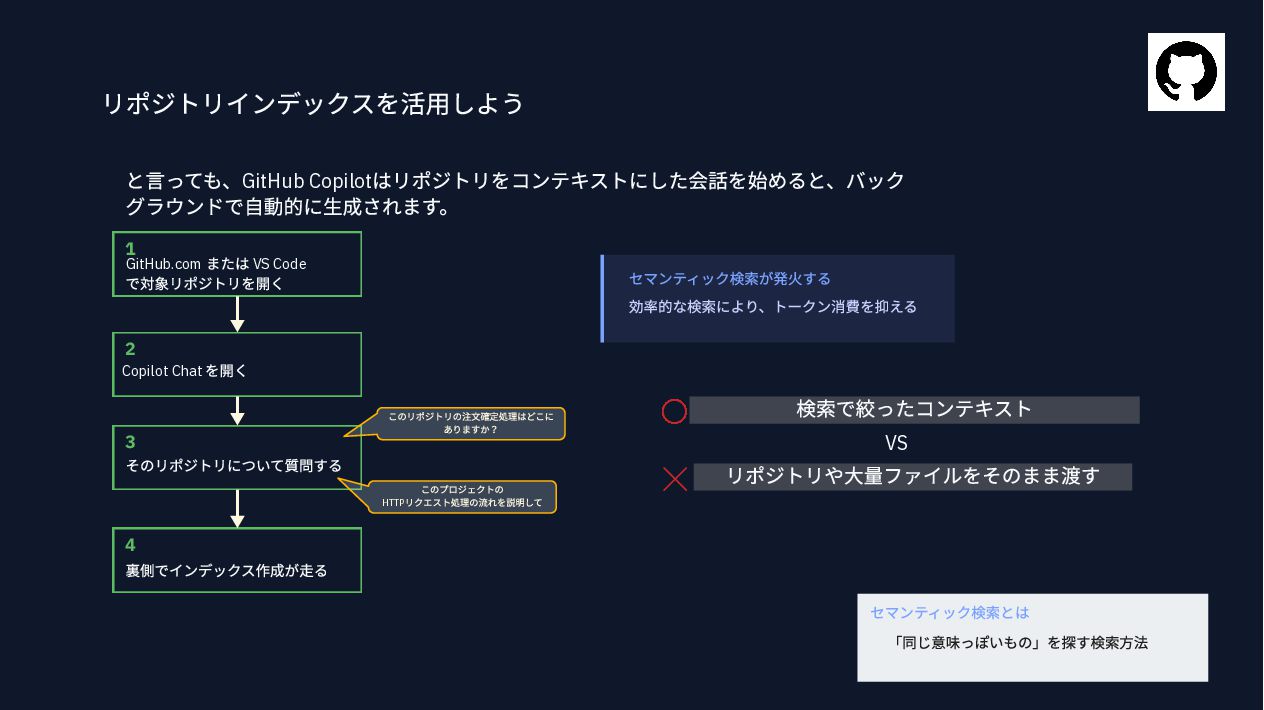{kind=link}
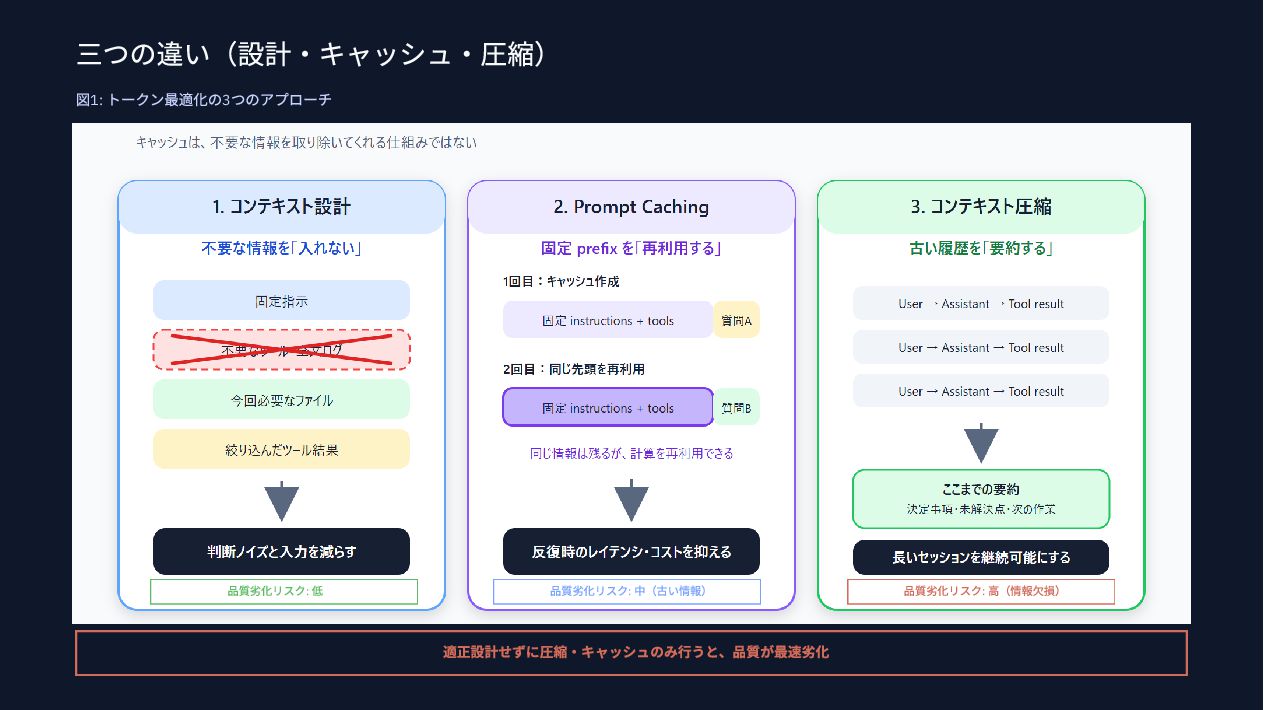{kind=link}
{kind=link}
{kind=link}
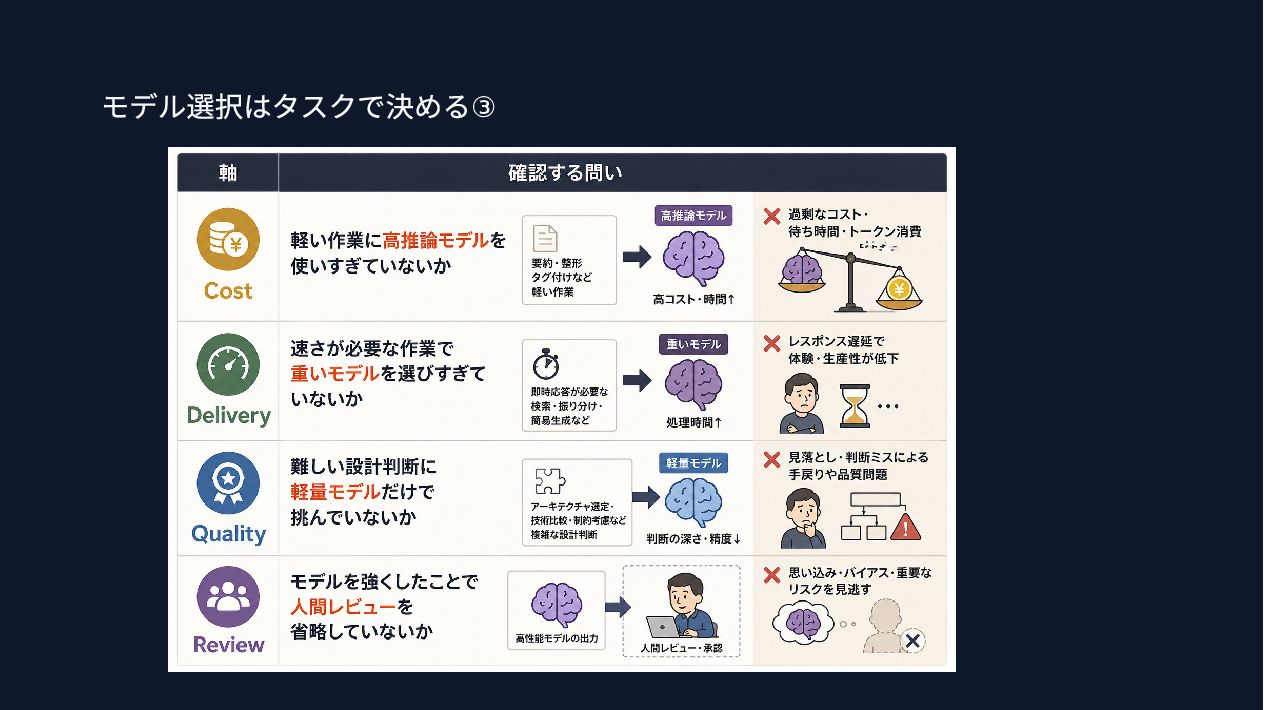{kind=link}
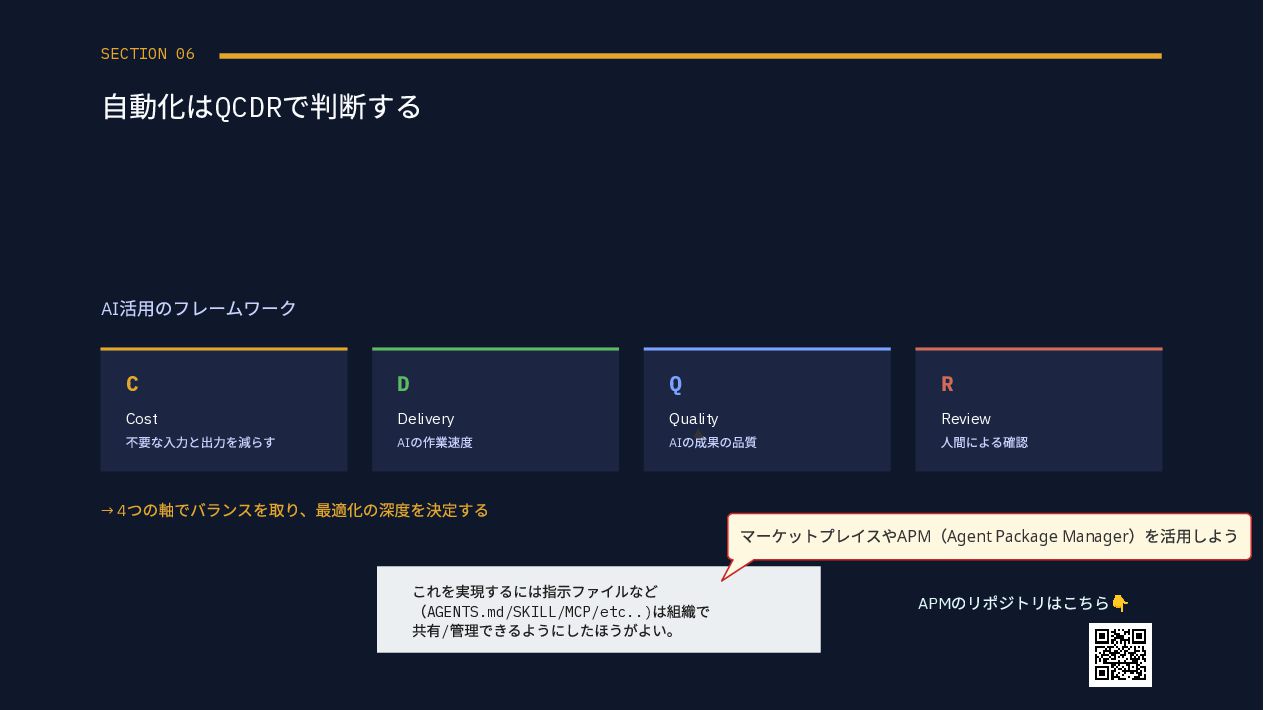{kind=link}
{kind=link}
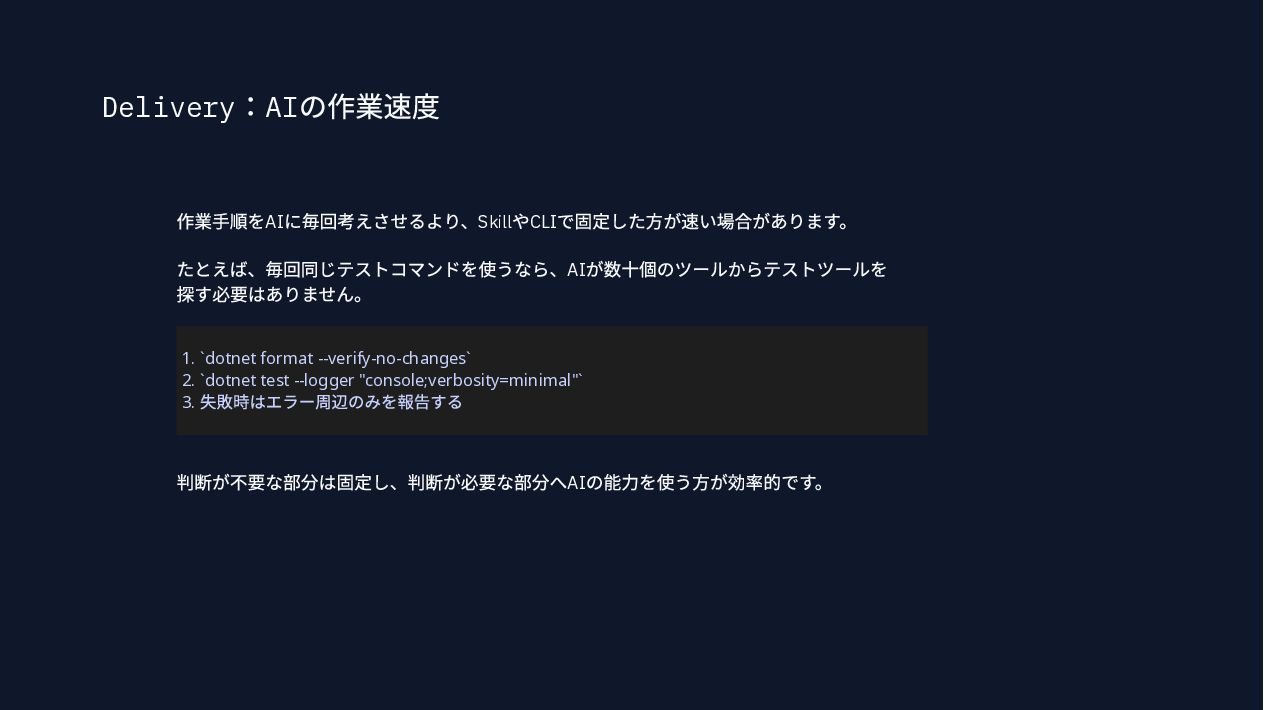{kind=link}
{kind=link}
{kind=link}
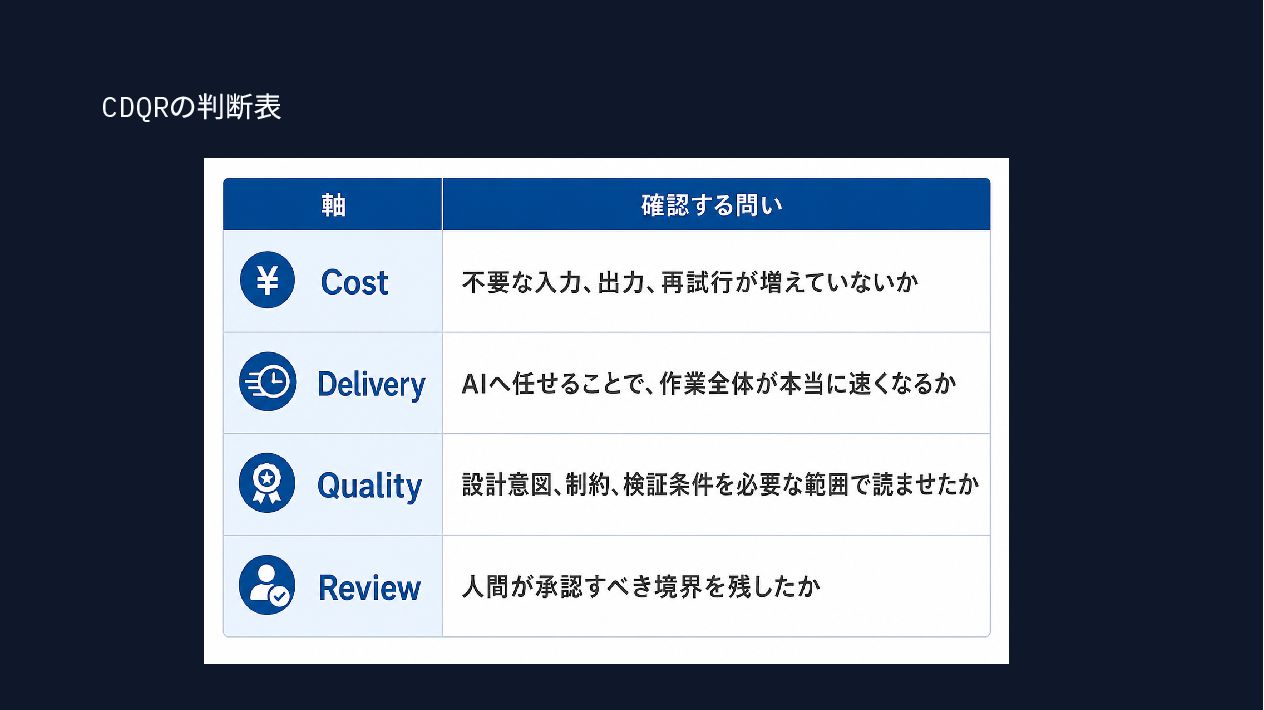{kind=link}
{kind=link}
{kind=link}