Transformer (ViT)系 │ │ ├── オリジナルViT (Google, 2021) │ │ ├── DeiT (Data-efficient ViT) │ │ ├── BEiT (BERT Pre-training of Image Transformers) │ │ ├── DINOv2 / DINOv3 (Meta) │ │ ├── MAE (Masked Autoencoder, Meta) │ │ ├── SimMIM (Microsoft) │ │ ├── Swin Transformer (階層的ViT) │ │ ├── CSWin Transformer │ │ ├── CrossViT │ │ ├── PVT (Pyramid Vision Transformer) │ │ ├── CvT (Convolutional vision Transformer) │ │ └── MobileViT (エッジデバイス用) │ │ │ ├── CNNベースモデル(参考:ViT以前の主流) │ │ ├── ResNet │ │ ├── EfficientNet │ │ ├── VGG │ │ ├── Inception │ │ └── DenseNet │ │ │ ├── ハイブリッドモデル(CNN + Transformer) │ │ ├── RT-DETR │ │ ├── CoAtNet │ │ └── LeViT │ │ │ ├── 動画理解モデル │ │ ├── VideoMAE (動画版MAE) │ │ ├── TimeSformer │ │ ├── ViViT (Video Vision Transformer) │ │ ├── MViT (Multiscale Vision Transformer) │ │ └── Uniformer │ │ │ ├── ワールドモデル(理解+予測+プランニング) │ │ ├── V-JEPA 2 (Meta, 2025) │ │ ├── V-JEPA (Meta, 2024) │ │ └── JEPA (Joint Embedding Predictive Architecture) │ │ │ ├── 画像エンコーダー(VLMの構成要素) │ │ ├── CLIP ViT (OpenAI) │ │ ├── SigLIP (Google) │ │ ├── EVA-CLIP │ │ └── OpenCLIP │ │ │ └── 物体検出特化モデル │ ├── YOLO (v5, v7, v8, v11) │ ├── DETR (Detection Transformer) │ ├── Segment Anything (SAM, Meta) │ └── Mask R-CNN │ ├── 【Vision Language Models (VLM)】 │ │ │ ├── 【Vision Language Models (VLM)】 │ │ │ ├── プロプライエタリ(企業提供) │ │ ├── GPT-4V / GPT-4o (OpenAI, 2023/2024) │ │ ├── Claude 3.5 Sonnet (Anthropic) │ │ ├── Claude 4 Opus / Sonnet 4.5 (Anthropic, 2024/2025) │ │ ├── Gemini 1.5 Pro / Flash (Google) │ │ ├── Gemini 2.5 Pro (Google, 2025) │ │ ├── Gemini 2.0 Flash (Google, 2024) │ │ └── Reka (Reka AI) │ │ │ ├── オープンソース - 大規模 │ │ ├── Qwen2.5-VL (7B, 72B) (Alibaba) │ │ ├── Qwen3-VL (Alibaba, 2025) │ │ ├── LLaMA 3.2 Vision (11B, 90B) (Meta) │ │ ├── InternVL 2.5 (OpenGVLab) │ │ ├── CogVLM2 (清華大学) │ │ ├── Yi-VL (01.AI) │ │ └── DeepSeek-VL (DeepSeek) │ │ │ ├── オープンソース - 中小規模 │ │ ├── Phi-4 Vision (Microsoft) │ │ ├── Gemma 3 (4B, 27B) (Google) │ │ ├── MiniCPM-V (OpenBMB) │ │ ├── Molmo (1B, 7B, 72B) (Allen AI) │ │ ├── PaliGemma (Google) │ │ └── LLaVA (各種サイズ) │ │ │ ├── 推論特化VLM │ │ ├── QVQ-72B (Qwen, マルチモーダル推論) │ │ └── Kimi-VL-A3B-Thinking (Moonshot AI) │ │ │ ├── OCR/文書特化VLM │ │ ├── DeepSeek-OCR (DeepSeek, 2025) │ │ ├── Qwen3-VL (32言語OCR対応) │ │ ├── Florence (Microsoft) │ │ └── Donut (Document Understanding Transformer) │ │ │ ├── 動画対応VLM │ │ ├── Qwen2.5-VL (動画理解可能) │ │ ├── Gemini 2.5 Pro (長時間動画対応) │ │ ├── Video-LLaMA │ │ └── VideoChat │ │ │ └── マルチモーダル安全モデル │ ├── ShieldGemma 2 (Google) │ └── Llama Guard 4 (Meta) │ ├── 【Vision-Language-Action Models (VLA)】 │ │(ロボット制御:Vision + Language + Action) │ │ │ ├── シングルシステム(エンドツーエンド) │ │ ├── RT-2 (Robotic Transformer 2, Google DeepMind, 2023) │ │ ├── OpenVLA (Physical Intelligence) │ │ ├── π0 (Pi-Zero, Physical Intelligence) │ │ ├── π0-fast (高速版) │ │ ├── Octo (UC Berkeley) │ │ └── QuartVLA │ │ │ │ │ ├── デュアルシステム(System 1 + System 2) │ │ ├── GR00T N1 (NVIDIA, 2025) - 2.2Bパラメータ │ │ │ ├── System 2: Eagle-2 VLM (理解・推論、10Hz) │ │ │ └── System 1: Diffusion Transformer (行動生成、120Hz) │ │ ├── GR00T N1.5 (NVIDIA, 2025) │ │ └── Helix (Physical Intelligence, 2024) │ │ └── 初のヒューマノイド全身制御VLA │ │ │ ├── クロスエンボディメント対応 │ │ ├── GR00T N1 (卓上ロボット→ヒューマノイド) │ │ └── RT-X (複数ロボット対応) │ │ │ └── 特殊用途VLA │ ├── Mobile ALOHA (モバイル双腕ロボット) │ └── LeRobot (Hugging Face, ロボット学習) │ ├── 【生成モデル】 (コンテンツを作る) │ │ │ ├── 動画生成(Text/Image to Video) │ │ ├── Sora (OpenAI, 2024) │ │ ├── Wan 2.2 (Alibaba, 2025) │ │ │ ├── T2V (Text to Video) │ │ │ ├── I2V (Image to Video) │ │ │ ├── S2V (Speech to Video) │ │ │ └── Animate (キャラクターアニメーション) │ │ ├── Wan 2.1 (Alibaba, 2024) │ │ ├── Pika 2.0 (Pika Labs) │ │ ├── Runway Gen-3 (Runway) │ │ ├── Luma Ray 2 (Luma AI) │ │ ├── Kling 2.0 (快手/Kuaishou) │ │ ├── Veo 2 (Google) │ │ ├── Movie Gen (Meta) │ │ ├── CogVideoX (清華大学) │ │ ├── Hunyuan Video (Tencent) │ │ └── Seedance (Bytedance) │ │ │ ├── 画像生成(Text to Image) │ │ ├── DALL-E 3 (OpenAI) │ │ ├── Midjourney v6 │ │ ├── Stable Diffusion (v1.5, v2, SDXL, SD3) │ │ ├── Imagen 3 (Google) │ │ └── Flux (Black Forest Labs) │ │ │ └── Diffusion Transformer (DiT) │ ├── Stable Diffusion 3 (DiTベース) │ └── Sora (DiTベース) │ └── 【合成データ生成】 (VLA訓練用) ├── NVIDIA Omniverse (物理シミュレーション) ├── NVIDIA Cosmos (合成データ生成) └── DreamGen (GR00T N1.5用、合成行動生成) オ ブ ジ ェ ク ト 検 知 、 セ グ メ ン テ ー シ ョ ン 言 語 を 伴 う 動 画 や 画 像 処 理 ロ ボ ッ ト な ど の 動 作 を 主 体 シ ミ ュ レ ー タ ー な ど に 活 用 、 ワ ー ル ド モ デ ル 物 理 認 識 や 予 測 な ど
{kind=link}
{kind=link}
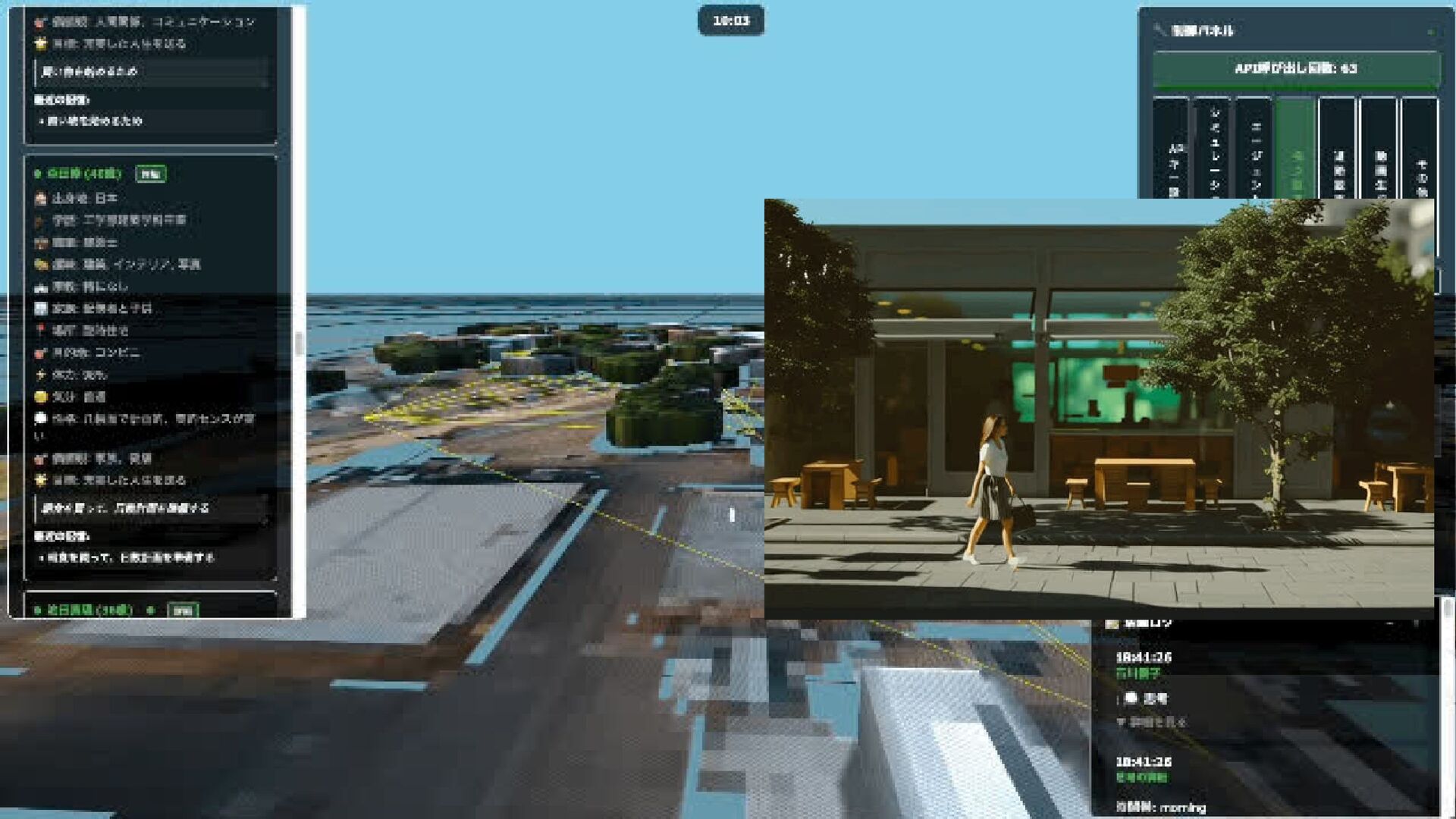
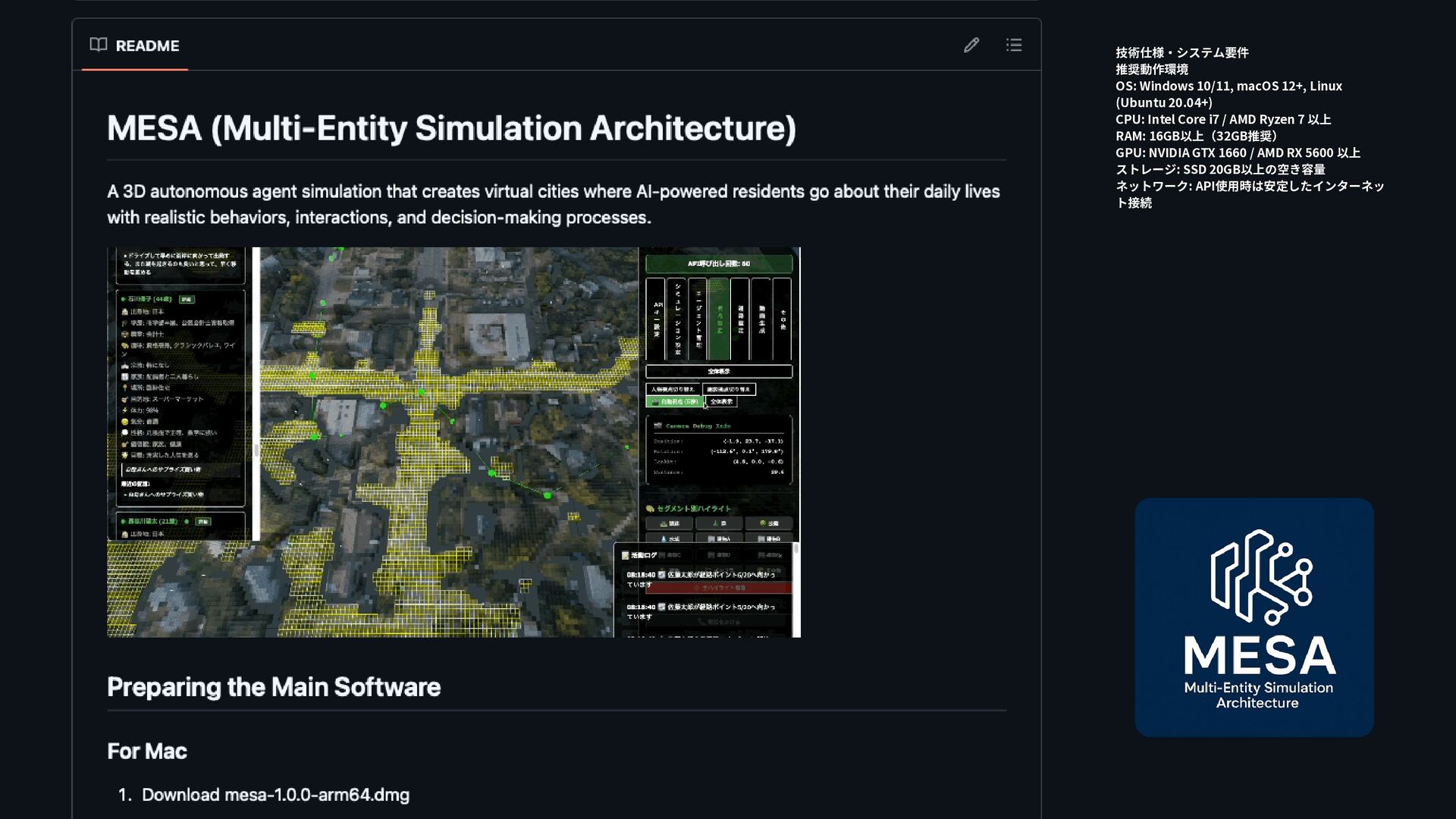
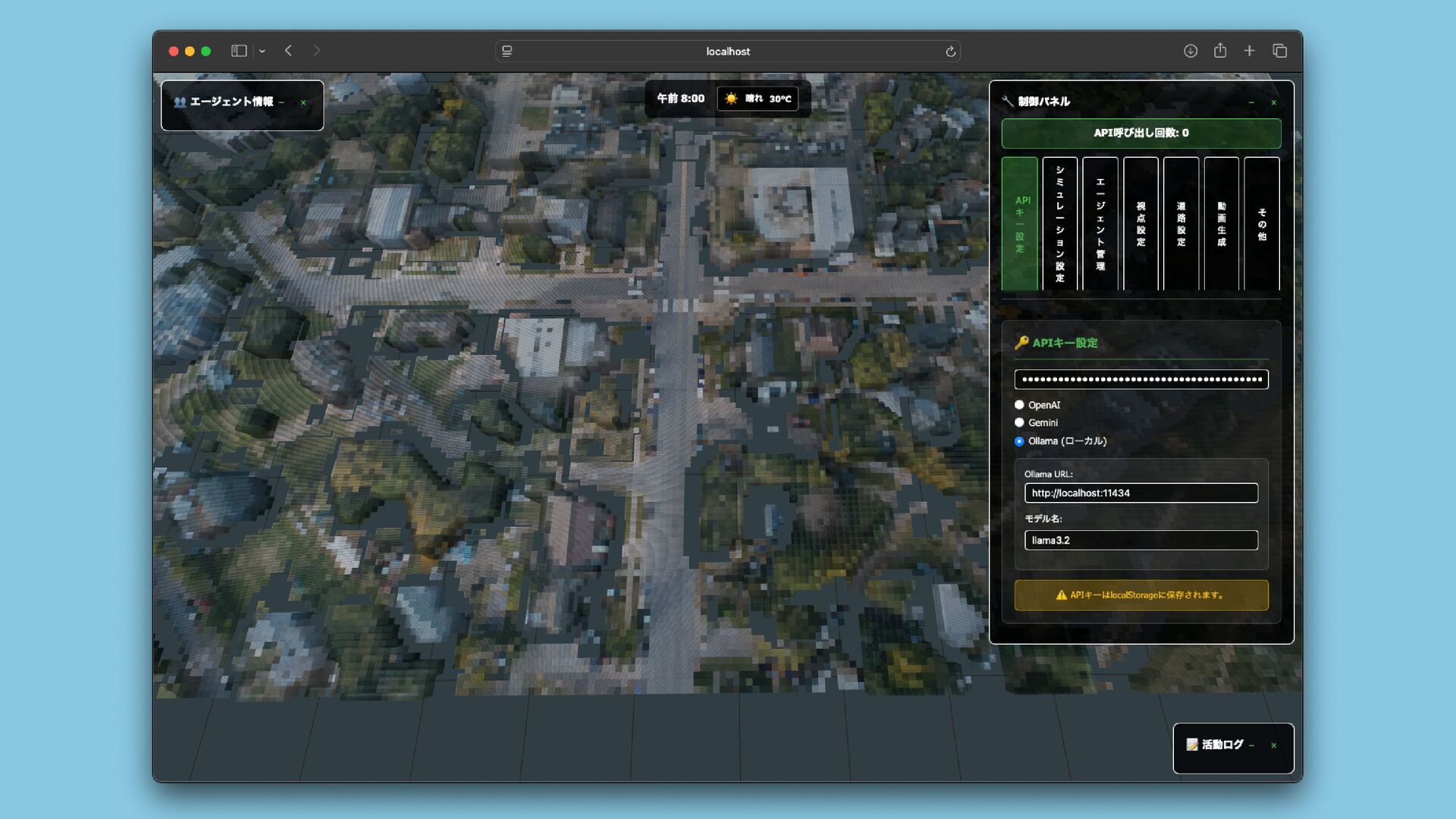
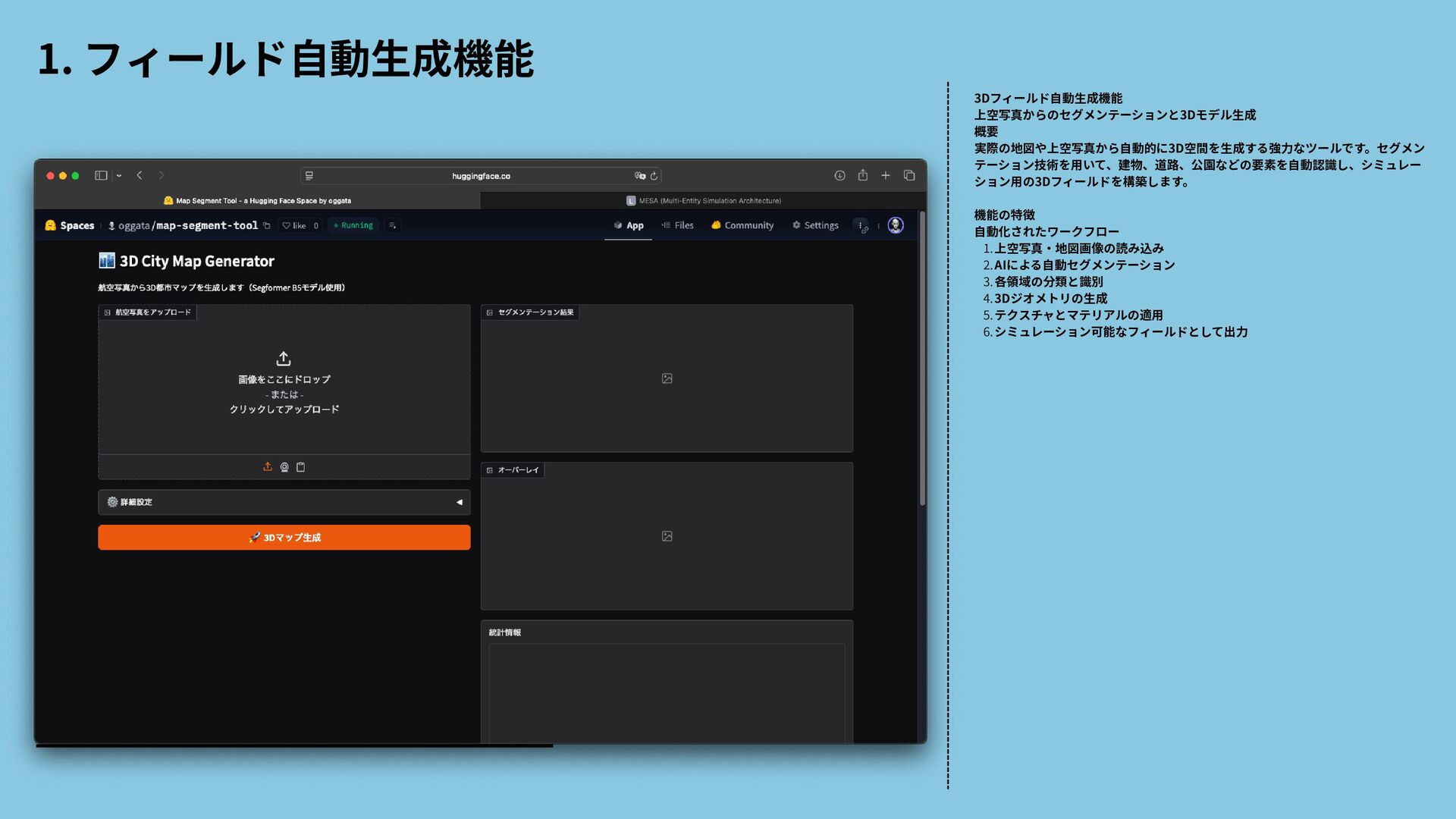
![Radiant AIは、ゲーム内のNPC(ノンプレイヤーキャラクター)の行動を より自然で動的なものにするために開発された人工知能システムです [2]。主にThe Elder Scrollsシリーズで使用されており、NPCに独自の目標 や行動パターンを与えることで、よりリアルな世界観を作り出すことを目 的としています。 Radient AI](https://files.speakerdeck.com/presentations/45f85996ae474b949e3426a6ced21cf5/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
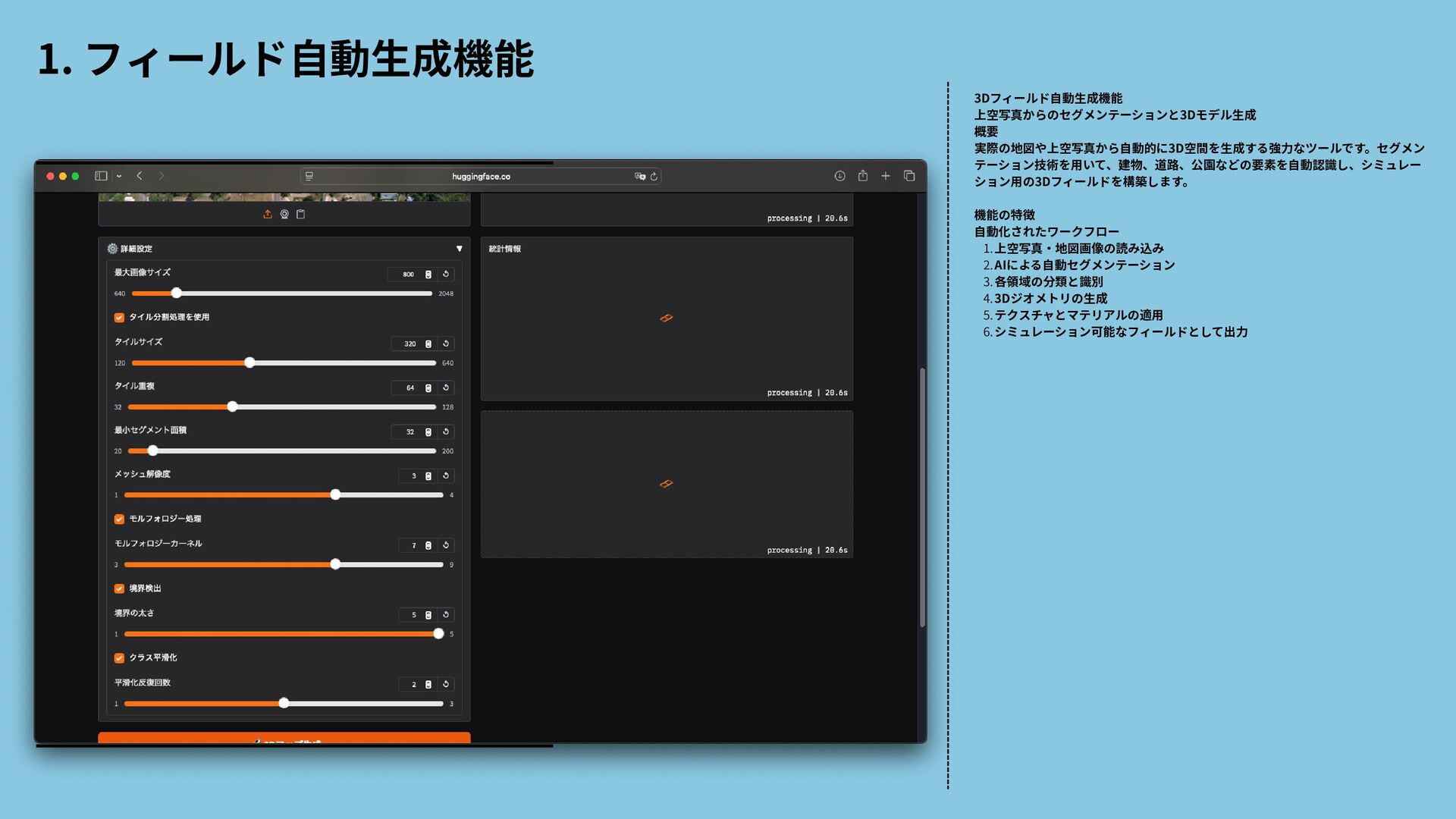{kind=link}
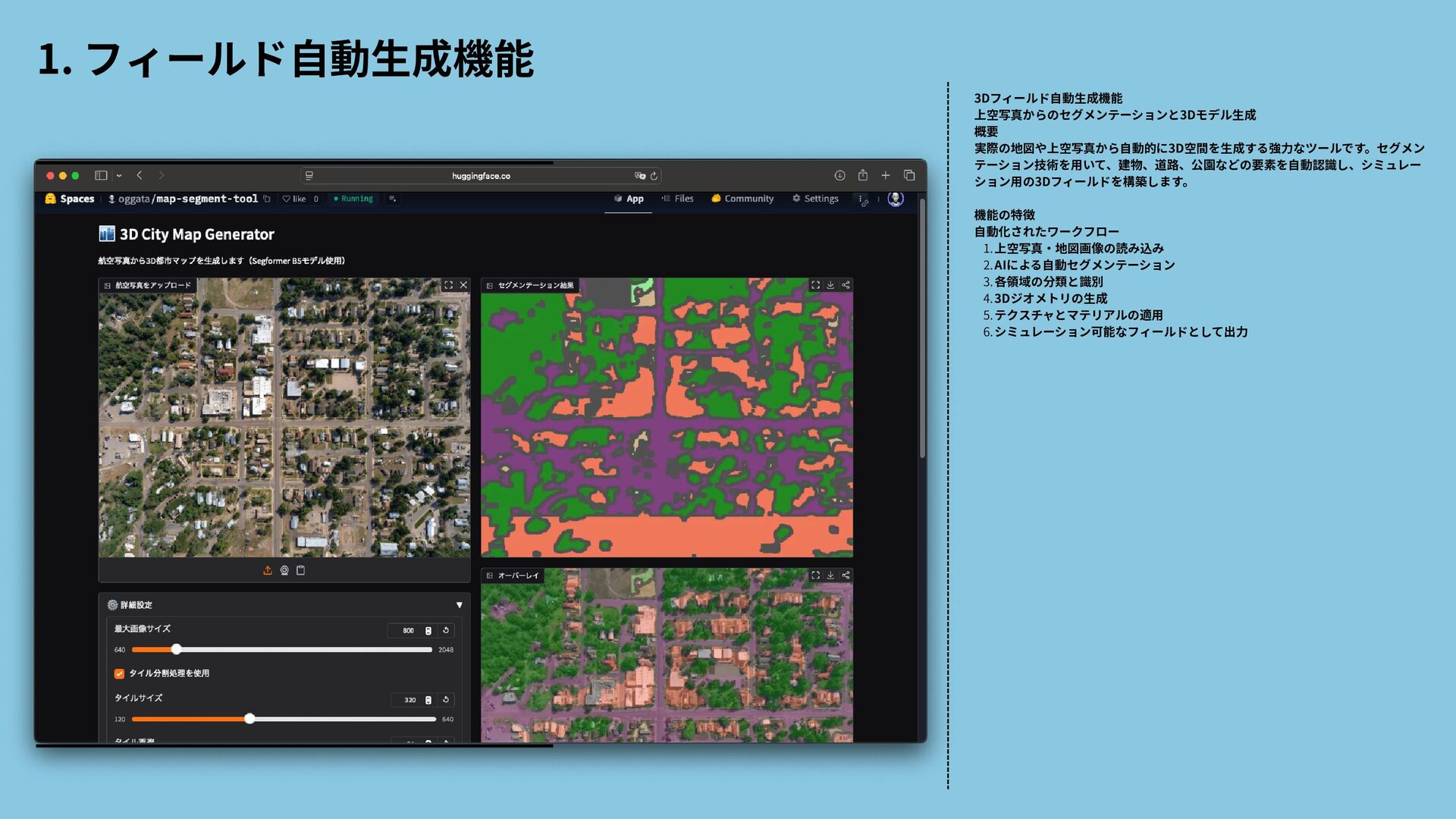{kind=link}
{kind=link}
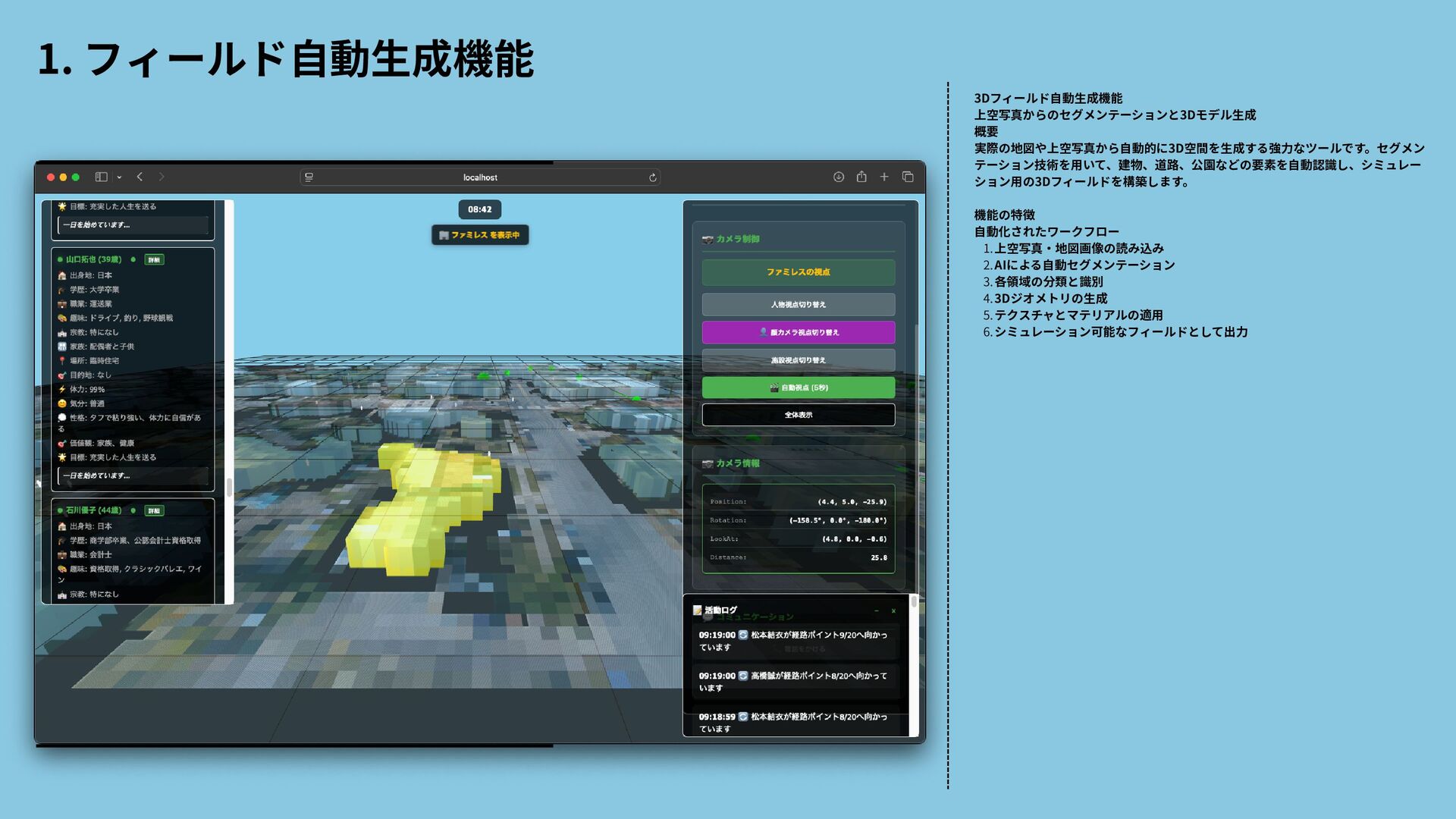{kind=link}
{kind=link}
{kind=link}
{kind=link}
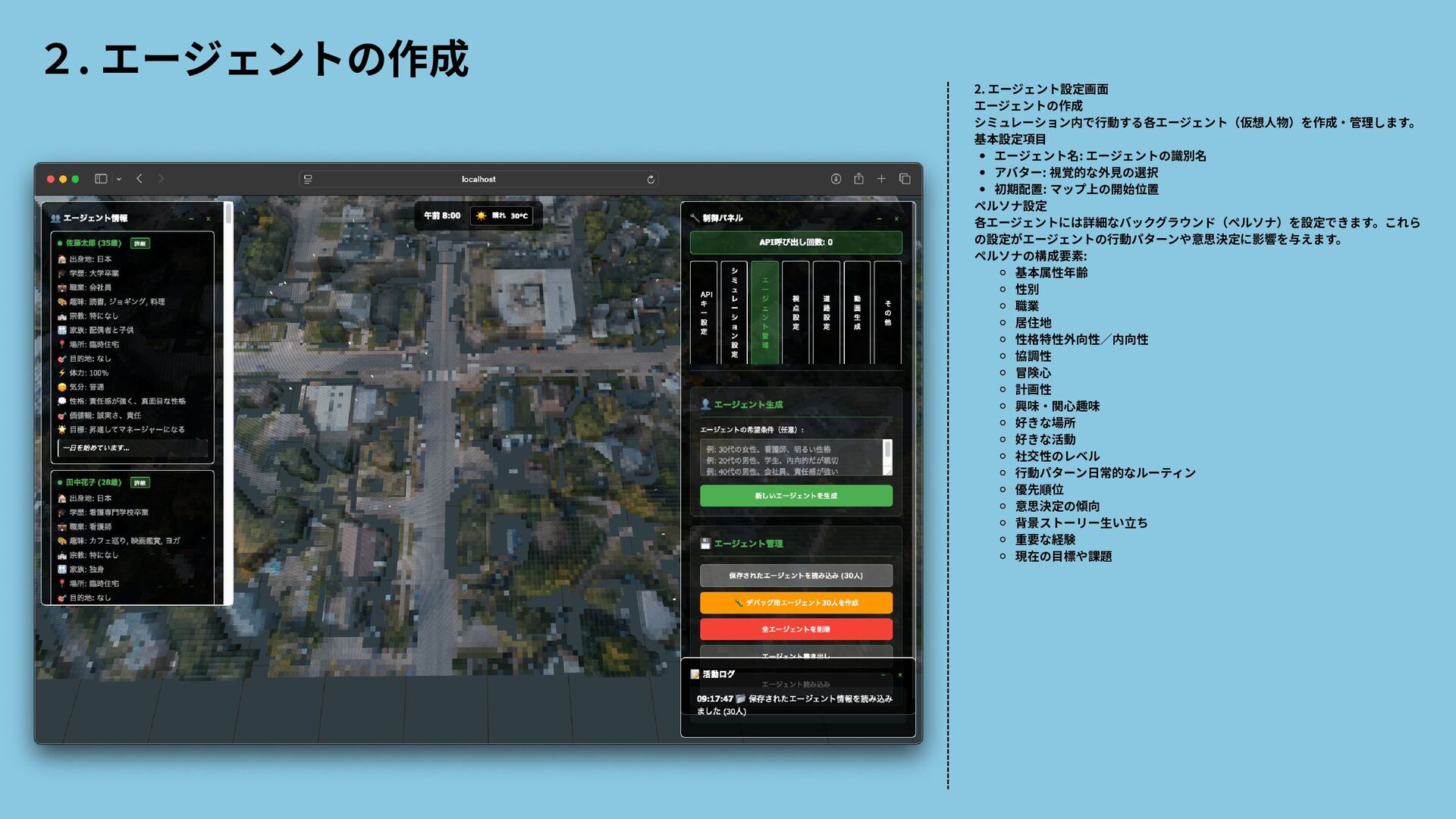{kind=link}
{kind=link}
{kind=link}
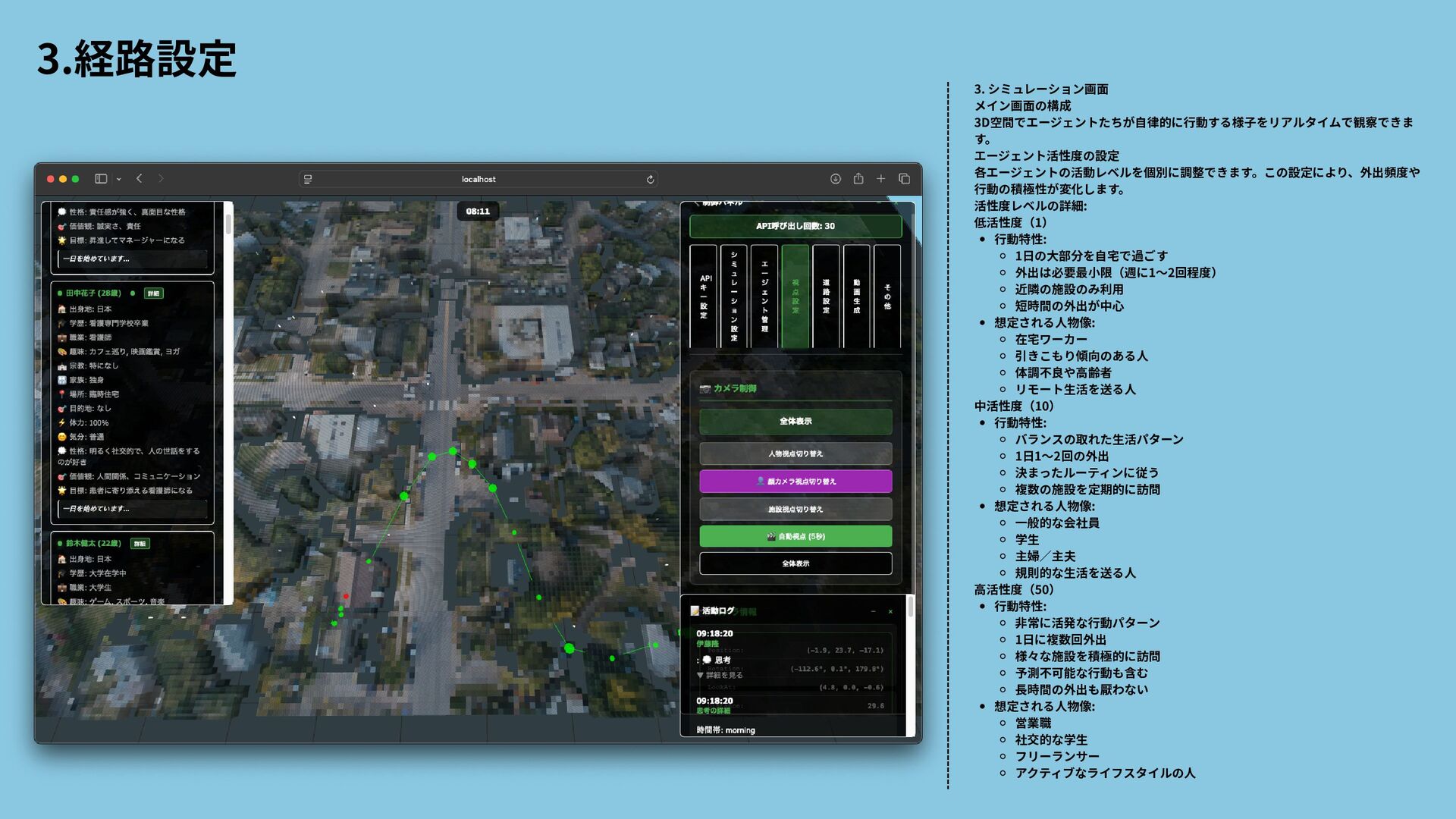{kind=link}
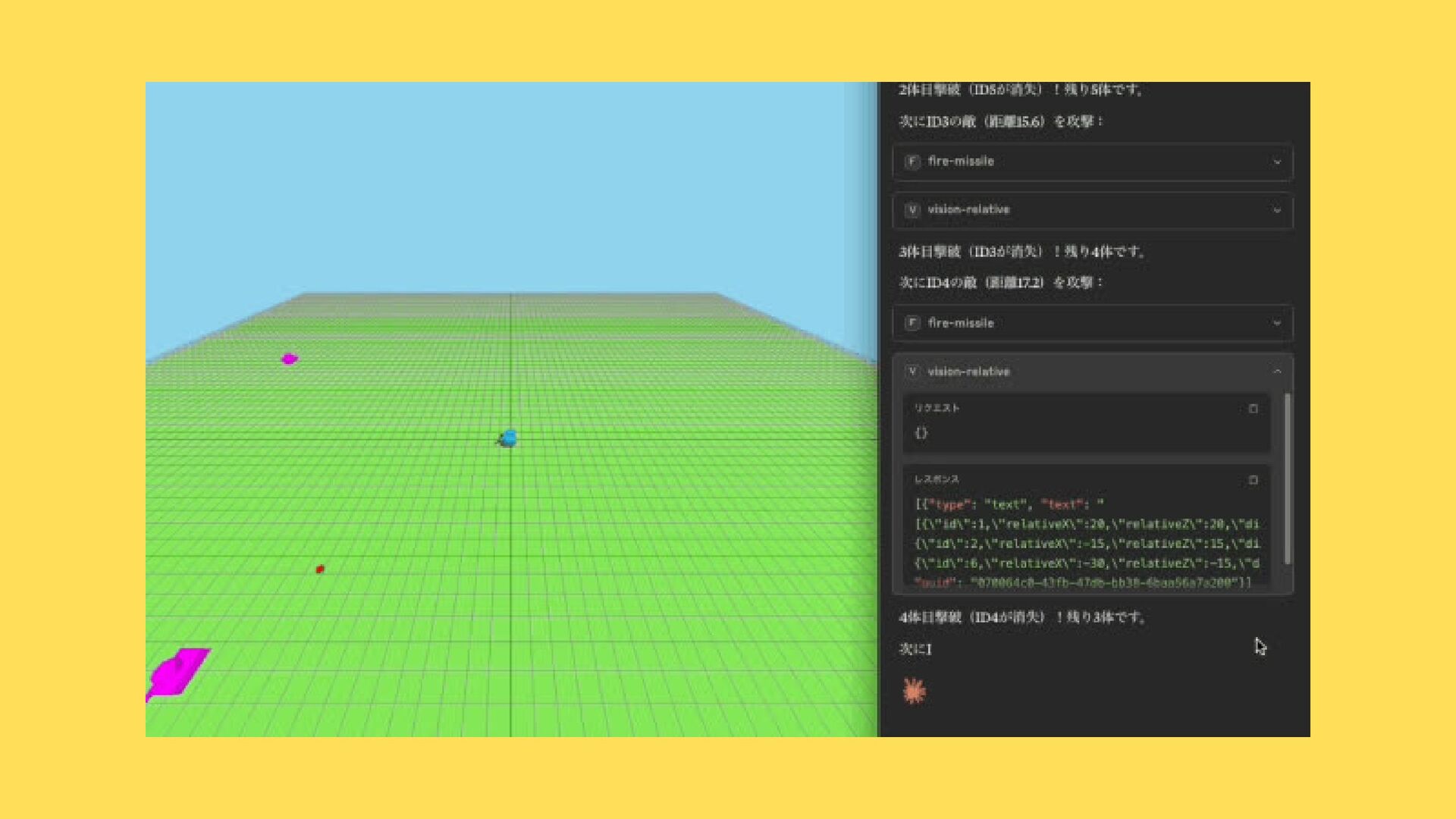{kind=link}
{kind=link}
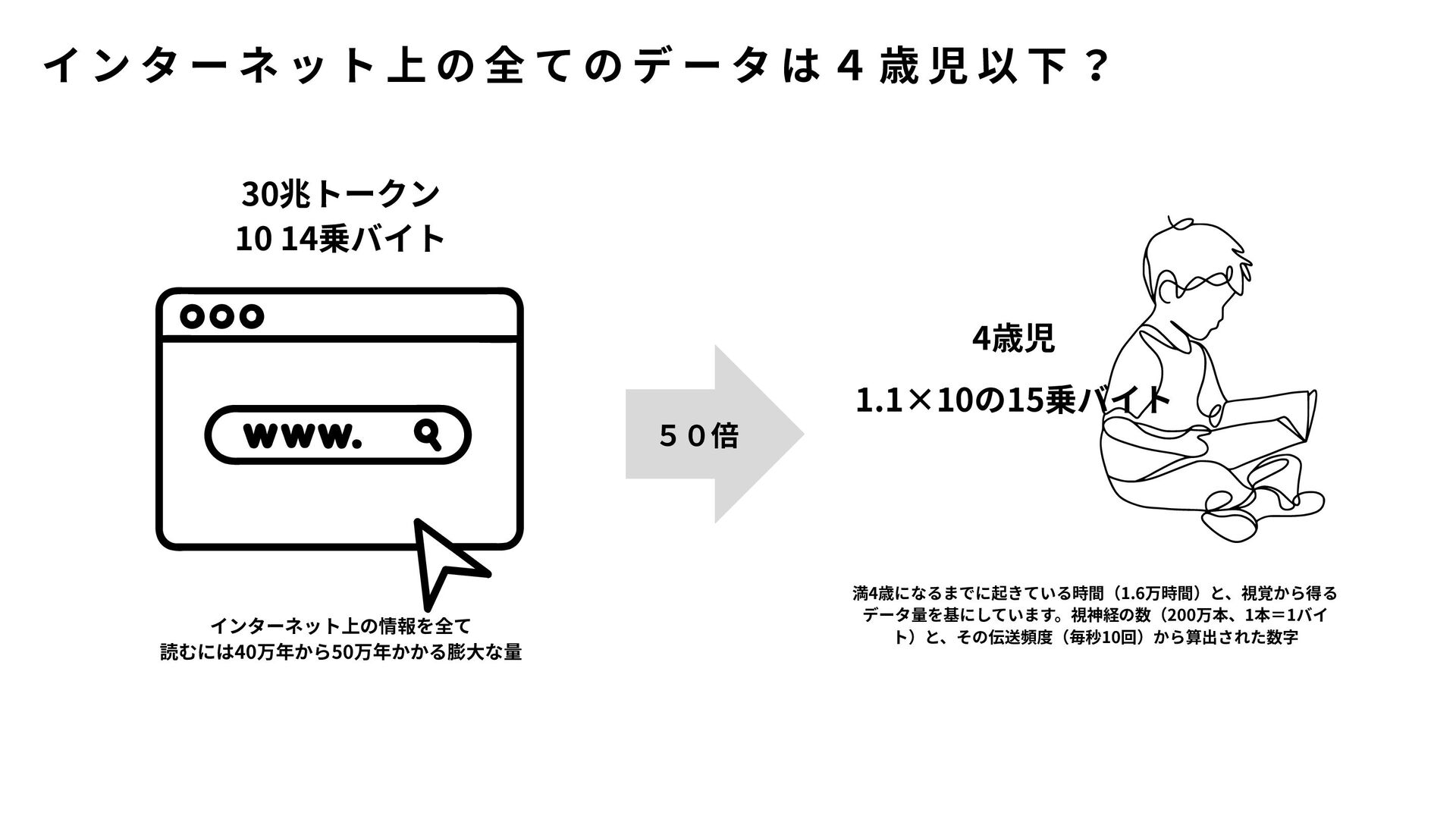{kind=link}
{kind=link}
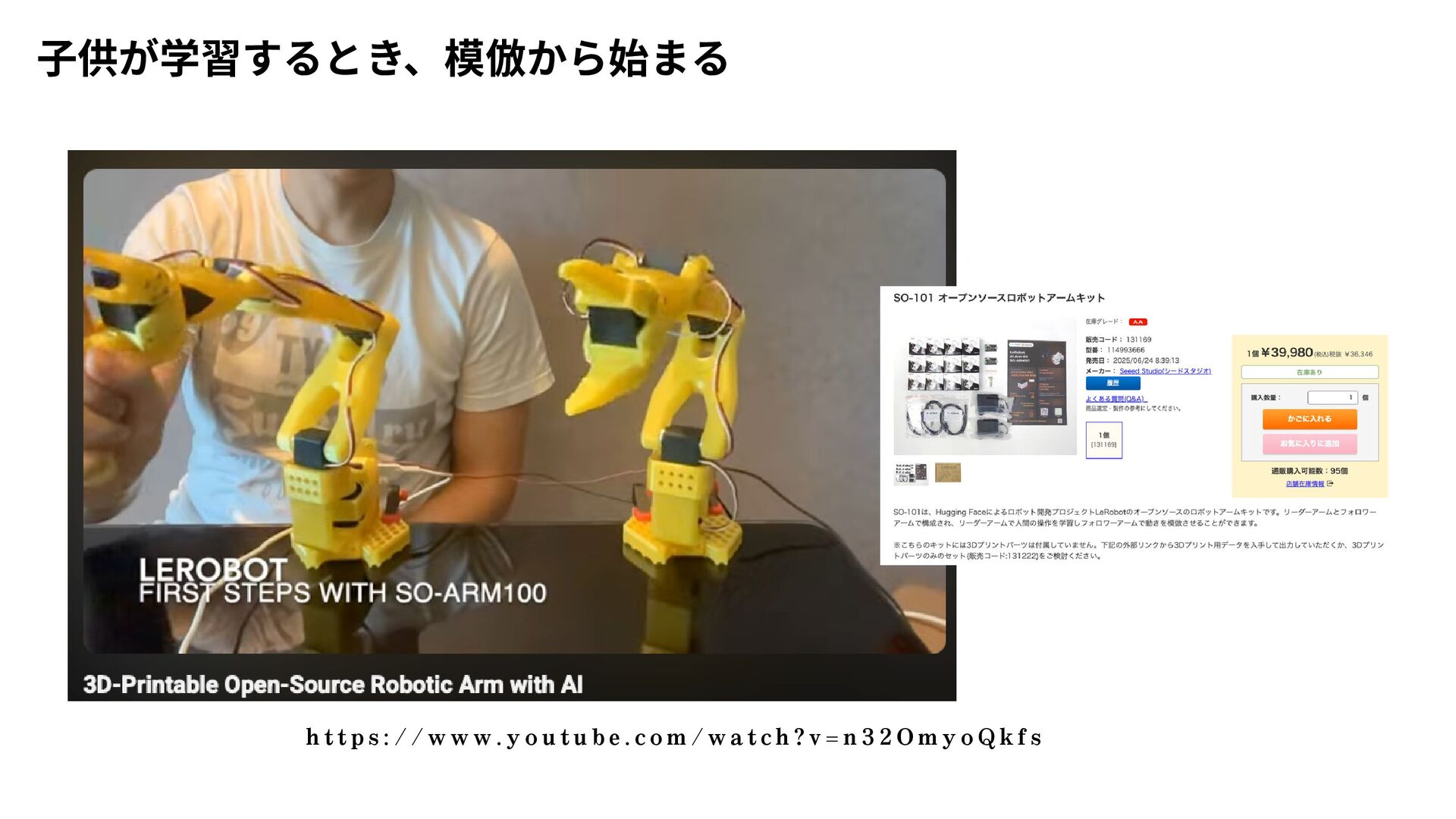{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}